本文参考自https://github.com/fastai/course-nlp。
使用NMF and SVD进行主题建模
问题
主题建模是开始学习 NLP 的一种有趣方式。我们将使用两种流行的矩阵分解技术。考虑最极端的情况------使用两个向量的外积重建矩阵。显然,在大多数情况下,我们无法精确地重建矩阵。但是,如果我们有一个向量表示总单词数中每个词汇单词的相对频率,另一个向量表示每个文档的平均单词数,那么外积将尽可能接近。现在考虑将矩阵增加到两列和两行。现在的最佳分解是将文档聚类为两组,每组的单词分布尽可能不同,但聚类中的文档尽可能相似。我们将这两组称为"主题"。我们会根据每个主题中出现频率最高的单词将单词聚类为两组。
开始
我们将获取几个不同类别的文档数据集,并找到它们的主题(由词组组成)。了解实际类别有助于我们评估找到的主题是否有意义。
我们将使用两种不同的矩阵分解来尝试此操作:奇异值分解 (SVD) 和非负矩阵分解 (NMF)。
python
import numpy as np
from sklearn.datasets import fetch_20newsgroups
from sklearn import decomposition
from scipy import linalg
import matplotlib.pyplot as plt
python
%matplotlib inline
np.set_printoptions(suppress=True)数据集
Scikit Learn 附带许多内置数据集,以及用于加载多个标准外部数据集的加载实用程序。这是一个很棒的资源,数据集包括波士顿房价、人脸图像、森林斑块、糖尿病、乳腺癌等。我们将使用新闻组数据集。
新闻组是 Usenet 上的讨论组,在网络真正起飞之前的 80 年代和 90 年代很流行。该数据集包括 18,000 个新闻组帖子和 20 个主题。
python
# 这里直接下载会出现forbidden 403的情况,所以我手动下载了数据集用load_files读取
categories = ['alt.atheism', 'talk.religion.misc', 'comp.graphics', 'sci.space']
remove = ('headers', 'footers', 'quotes')
train_data_folder = './20news-bydate/20news-bydate-train'
test_data_folder = './20news-bydate/20news-bydate-test'
newsgroups_train = load_files(train_data_folder, categories=categories, encoding='utf-8', decode_error='ignore')
newsgroups_test = load_files(test_data_folder, categories=categories, encoding='utf-8', decode_error='ignore')
# newsgroups_train = fetch_20newsgroups(subset='train', categories=categories, remove=remove)
# newsgroups_test = fetch_20newsgroups(subset='test', categories=categories, remove=remove)
python
newsgroups_train.filenames.shape, newsgroups_train.target.shape
python
((2034,), (2034,))我们来看一个数据。你能猜出消息属于哪一类吗?
python
print("\n".join(newsgroups_train.data[:1]))
python
From: fineman@stein2.u.washington.edu (Twixt your toes)
Subject: Anyone know use "rayshade" out there?
Organization: University of Washington
Lines: 12
NNTP-Posting-Host: stein2.u.washington.edu
Keywords: rayshade, uw.
I'm using "rayshade" on the u.w. computers here, and i'd like input
from other users, and perhaps swap some ideas. I could post
uuencoded .gifs here, or .ray code, if anyone's interested. I'm having
trouble coming up with colors that are metallic (i.e. brass, steel)
from the RGB values.
If you're on the u.w. machines, check out "~fineman/rle.files/*.rle" on
stein.u.washington.edu for some of what i've got.
dan
python
np.array(newsgroups_train.target_names)[newsgroups_train.target[:3]]
python
array(['comp.graphics'], dtype='<U18')目标属性是类别的整数索引。
python
newsgroups_train.target[:10]
python
array([1, 2, 2, 2, 2, 2, 2, 1, 2, 1])
python
num_topics, num_top_words = 6, 8停用词、词干提取、词形还原
停用词
一些极其常见的单词似乎对帮助选择符合用户需求的文档没有什么价值,因此被完全排除在词汇表之外。这些单词被称为停用词。
随着时间的推移,IR 系统的总体趋势是从标准使用相当大的停用词表(200-300 个词)到非常小的停用词表(7-12 个词),再到根本不使用停用词表。网络搜索引擎通常不使用停用词表。
NLTK
python
from sklearn.feature_extraction.text import ENGLISH_STOP_WORDS
sorted(list(ENGLISH_STOP_WORDS))[:20]
python
['a',
'about',
'above',
'across',
'after',
'afterwards',
'again',
'against',
'all',
'almost',
'alone',
'along',
'already',
'also',
'although',
'always',
'am',
'among',
'amongst',
'amoungst']不存在单一的通用停用词列表。
词干提取、词形还原
摘自《信息检索》教科书:
以下单词相同吗?
organize, organizes, and organizing
democracy, democratic, and democratization
词干提取和词形还原都生成单词的词根形式。
词形还原使用语言规则。生成的标记都是实际单词
"词干提取是穷人的词形还原。"(Noah Smith,2011)词干提取是一种粗略的启发式方法,它会切断单词的末尾。生成的标记可能不是实际单词。词干提取速度更快。
python
import nltk
nltk.download('wordnet')
python
[nltk_data] Downloading package wordnet to
[nltk_data] C:\Users\wuzhongyanqiu\AppData\Roaming\nltk_data...
True
python
from nltk import stem
wnl = stem.WordNetLemmatizer()
porter = stem.porter.PorterStemmer()
word_list = ['feet', 'foot', 'foots', 'footing']
python
[wnl.lemmatize(word) for word in word_list]
output:['foot', 'foot', 'foot', 'footing']
python
[porter.stem(word) for word in word_list]
output:['feet', 'foot', 'foot', 'foot']这里再试一下其他的单词集合,词干提取、词形还原对于形态很复杂的语言可能有更大的好处。
python
word_list1 = ['fly', 'flies', 'flying']
word_list2 = ['organize', 'organizes', 'organizing']
word_list3 = ['universe', 'university']
word_list = word_list + word_list1 + word_list2 + word_list3
[wnl.lemmatize(word) for word in word_list]
python
['foot',
'foot',
'foot',
'footing',
'fly',
'fly',
'flying',
'organize',
'organizes',
'organizing',
'universe',
'university']
python
[porter.stem(word) for word in word_list]
python
['feet',
'foot',
'foot',
'foot',
'fli',
'fli',
'fli',
'organ',
'organ',
'organ',
'univers',
'univers']Spacy
Spacy 是一个非常现代且快速的 nlp 库。 Spacy 有自己的主见,它通常提供一种高度优化的方式来做某事(而 nltk 提供了各种各样的方法,尽管它们通常没有那么优化)。
python
import spacy
!spacy download en_core_web_smSpacy 不提供词干提取器(因为词形还原被认为更好------这是一个固执己见的例子!)
python
nlp = spacy.load("en_core_web_sm")
sorted(list(nlp.Defaults.stop_words))[:20]
python
["'d",
"'ll",
"'m",
"'re",
"'s",
"'ve",
'a',
'about',
'above',
'across',
'after',
'afterwards',
'again',
'against',
'all',
'almost',
'alone',
'along',
'already',
'also']练习:哪些停用词在 spacy 中出现但在 sklearn 中没有出现?
python
#Exercise:What stop words appear in spacy but not in sklearn?
sklearn_stop_words = set(ENGLISH_STOP_WORDS)
spacy_stop_words = set(nlp.Defaults.stop_words)
unique_to_spacy = spacy_stop_words - sklearn_stop_words
sorted(list(unique_to_spacy))[:20]
python
["'d",
"'ll",
"'m",
"'re",
"'s",
"'ve",
'ca',
'did',
'does',
'doing',
'just',
'make',
"n't",
'n't',
'n't',
'quite',
'really',
'regarding',
'say',
'unless']练习:哪些停用词在 sklearn 中有,但在 spacy 中没有?
python
#Exercise:What stop words appear in sklearn but not in spacy?
unique_to_sklearn = sklearn_stop_words - spacy_stop_words
sorted(list(unique_to_sklearn))[:20]
python
['amoungst',
'bill',
'cant',
'co',
'con',
'couldnt',
'cry',
'de',
'describe',
'detail',
'eg',
'etc',
'fill',
'find',
'fire',
'found',
'hasnt',
'ie',
'inc',
'interest']何时使用这些?
这些长期以来被认为是标准技术,但如果使用深度学习,它们通常会损害您的表现。词干提取、词形还原和删除停用词都涉及丢弃信息。
但是,在使用较简单的模型时,它们仍然很有用。
数据处理
接下来,scikit learn 有一个方法可以帮我们提取所有单词计数。在下一课中,我们将学习如何编写自己的 CountVectorizer 版本,以了解底层发生了什么。
python
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
import nltk
# 一个CountVectorizer对象,用于将文本转换为特征向量
vectorizer = CountVectorizer(stop_words='english')
vectors = vectorizer.fit_transform(newsgroups_train.data).todense()
vectors.shape
python
(2034, 33809)
python
print(len(newsgroups_train.data), vectors.shape)
python
2034 (2034, 33809)
python
vocab = np.array(vectorizer.get_feature_names_out())
vocab.shape
python
(33809,)
python
vocab[7000:7020]
python
array(['bnn', 'bnn_post', 'bnr', 'bnsc', 'bnsgs195', 'board', 'boarded',
'boards', 'boast', 'boasted', 'boasts', 'boat', 'boats', 'bob',
'bobbe', 'bobbing', 'bobby', 'bobc', 'bobcat', 'bobs'],
dtype=object)奇异值分解 (SVD)
我们显然会期望在一个主题中出现频率最高的单词在另一个主题中出现的频率较低 - 否则该单词就不是区分这两个主题的好选择。因此,我们期望主题是正交的。
SVD 算法将矩阵分解为一个具有正交列的矩阵和一个具有正交行的矩阵(以及一个对角矩阵,其中包含每个因素的相对重要性)。
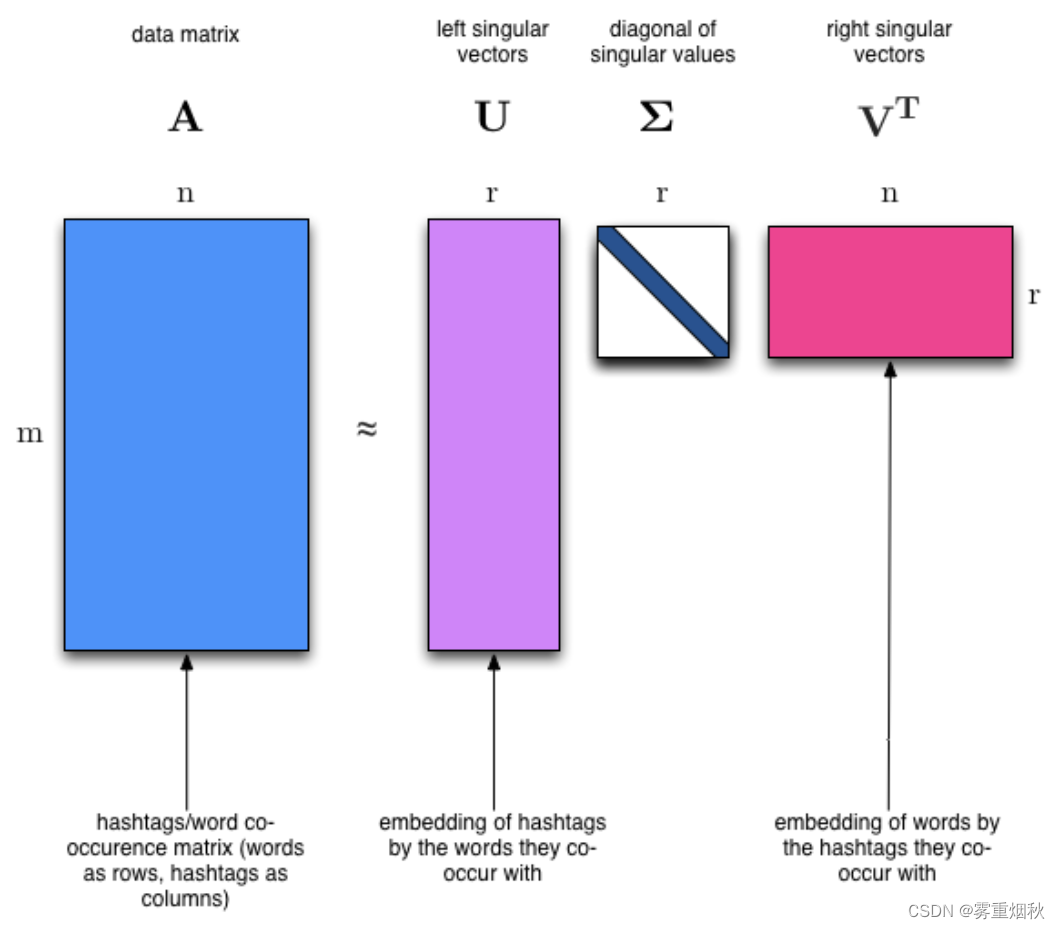
SVD 是一种精确分解,因为它创建的矩阵足够大,可以完全覆盖原始矩阵。SVD 在线性代数中应用极其广泛,特别是在数据科学中,包括:
- 语义分析(潜在语义分析 (LSA) 使用 SVD。您有时会听到将主题建模称为 LSA。)
- 协同过滤/推荐(Netflix 奖获奖作品)
- 计算 Moore-Penrose 伪逆
- 数据压缩
- 主成分分析
python
%time U, s, Vh = linalg.svd(vectors, full_matrices=False)
python
CPU times: total: 1min 57s
Wall time: 15.7 s
python
print(U.shape, s.shape, Vh.shape)
python
(2034, 2034) (2034,) (2034, 33809)确认这是输入的分解。
python
s[:4]
output:
array([449.50641673, 303.09932748, 260.75217804, 233.74189479])
s[:4].shape
output:
(4,)
np.diag(s[:4])
output:
array([[449.50641673, 0. , 0. , 0. ],
[ 0. , 303.09932748, 0. , 0. ],
[ 0. , 0. , 260.75217804, 0. ],
[ 0. , 0. , 0. , 233.74189479]])练习:确认U, s, Vh是向量的分解
python
# Exercise: confrim that U, s, Vh is a decomposition of `vectors`
# allclose()用于匹配两个数组输出为布尔值,默认在1e-05的误差范围内
vectors_check = np.dot(U, np.dot(np.diag(s), Vh))
assert np.allclose(vectors, vectors_check), 'The decomposition is wrong!'
print('The decomposition is confirmed.')
python
The decomposition is confirmed.练习:确认U, Vh是正交的
python
# Exercise: Confirm that U, Vh are orthonormal
assert np.allclose(np.dot(U.T, U), np.eye(U.shape[0])), 'U is not orthonormal'
assert np.allclose(np.dot(Vh, Vh.T), np.eye(Vh.shape[0])), 'Vh is not orthonormal'
print('True')
python
True关于奇异值 s 我们能说些什么呢?
python
plt.plot(s)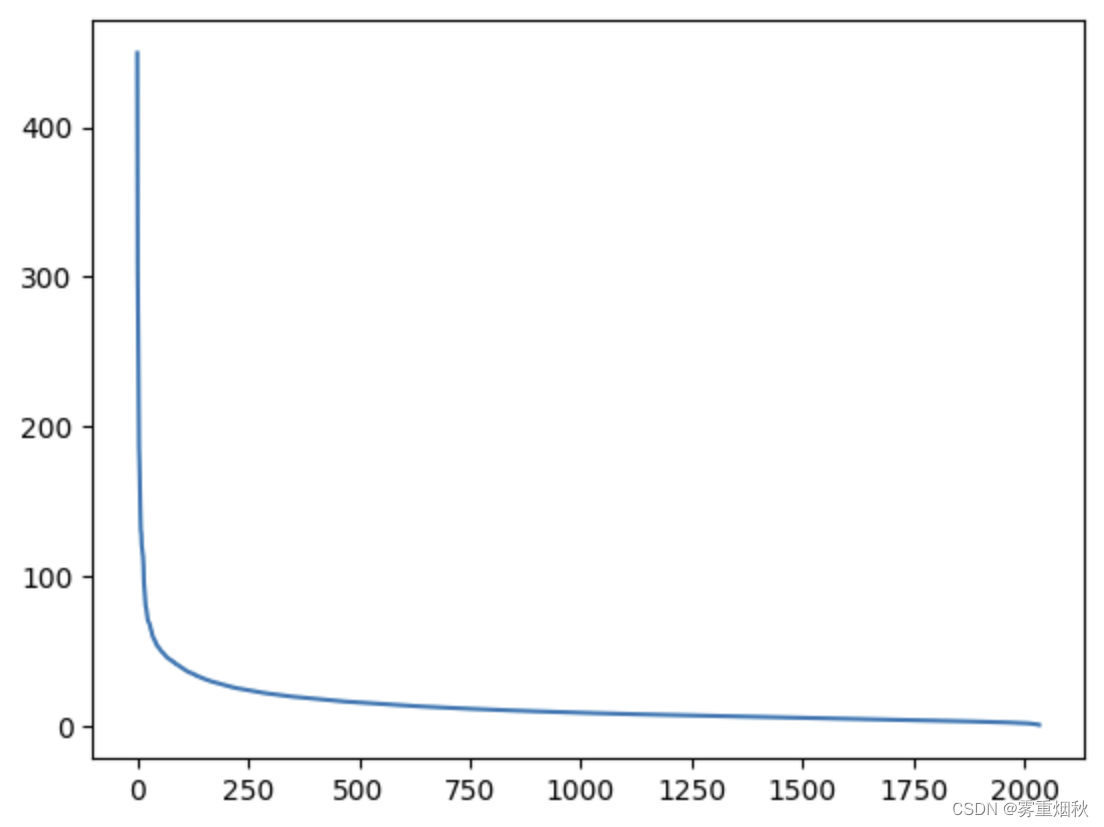
python
plt.plot(s[:10])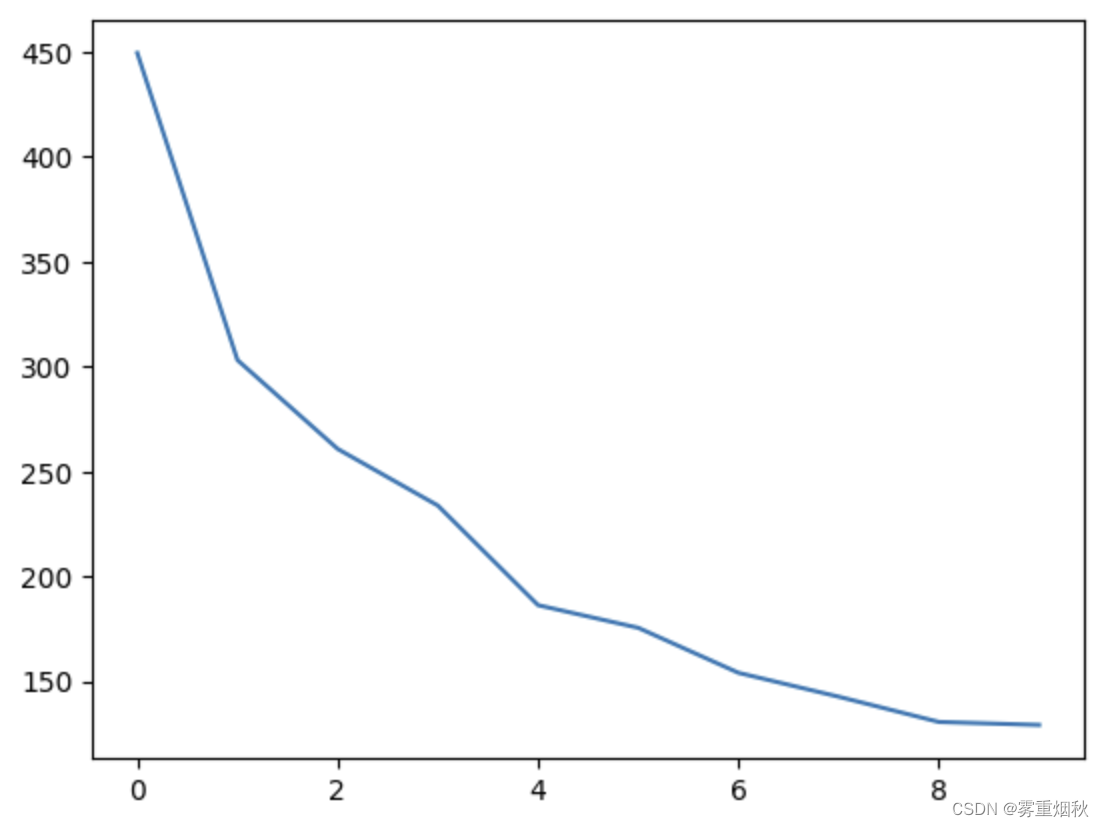
python
num_top_words = 8
# vocab是词汇表,top_words是lambda函数,接收权重向量t,先对t进行排序,然后选取top_words
def show_topics(a):
top_words = lambda t: [vocab[i] for i in np.argsort(t) [:-num_top_words-1:-1]]
topic_words = ([top_words(t) for t in a])
return [' '.join(t) for t in topic_words]
python
show_topics(Vh[:10])
python
['antti siivonen suut imein siberian stint siis tuusniemi',
'jpeg gif file image color quality format jfif',
'god jesus people space atheists does matthew don',
'space launch satellite nasa commercial satellites year market',
'edu jpeg space graphics ray mail pub com',
'jesus matthew prophecy messiah isaiah psalm david said',
'launch satellite commercial market graphics god atheists satellites',
'edu writes lines com organization article launch subject',
'image probe lunar surface mars argument probes moon',
'god atheists image religious atheism jesus probe religion']我们得到的主题与我们预期的集群类型相匹配!尽管这是一个无监督算法,这意味着我们从未真正告诉算法我们的文档是如何分组的。
我们稍后会更详细地介绍 SVD。现在,重要的是我们有一个工具,可以让我们准确地将矩阵分解为正交列和正交行。
非负矩阵分解(NMF)
除了将因子限制为正交之外,另一个想法是将它们限制为非负。NMF 是非负数据集V的因式分解:
V = W H V=WH V=WH
转换为非负矩阵 W , H W, H W,H。通常积极因素会更容易解释(这也是 NMF 受欢迎的原因)。
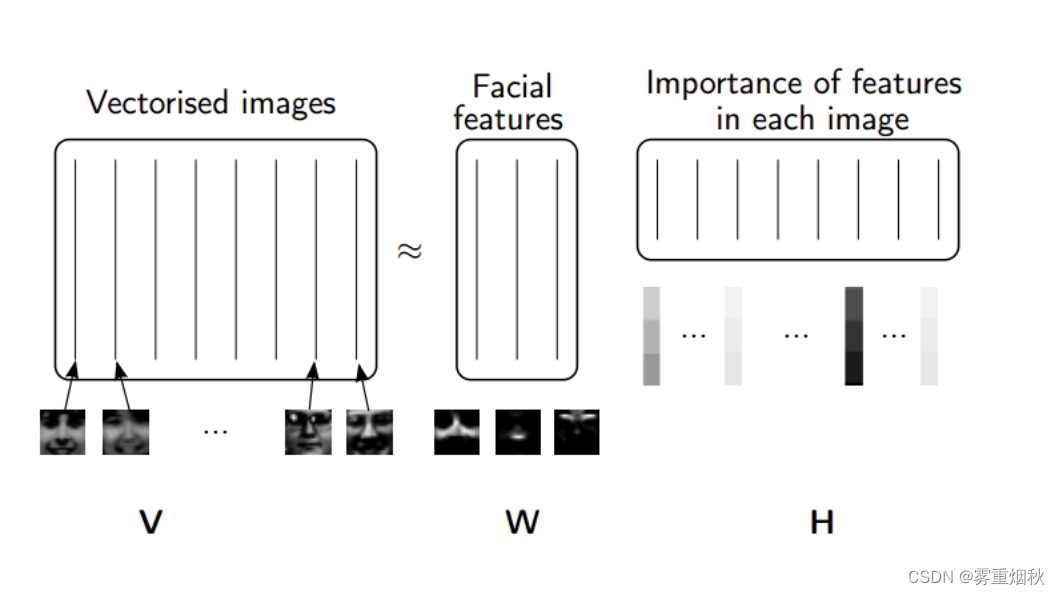
非负矩阵分解 (NMF) 是一种非精确分解,可分解为一个细正矩阵和一个短正矩阵。NMF 是 NP-hard 且非唯一的。它有许多变体,可通过添加不同的约束来创建。
NMF from sklearn
我们将使用 scikit-learn 的 NMF 实现:
python
m, n = vectors.shape
d = 5 # num topics
clf = decomposition.NMF(n_components=d, random_state=1)
W1 = clf.fit_transform(np.asarray(vectors))
H1 = clf.components_
show_topics(H1)
python
['edu graphics pub mail ray 128 send ftp',
'jpeg image gif file color images format quality',
'god jesus people does atheists matthew atheism just',
'space launch satellite nasa commercial year satellites data',
'image data available software processing ftp analysis images']TF-IDF
主题频率-逆文档频率 (TF-IDF) 是一种通过考虑术语在文档中出现的频率、文档的长度以及术语的常见/罕见程度来规范化术语计数的方法。
TF = (文档中术语 t 的出现次数) / (文档中的单词数量)
IDF = log(文档数量/包含术语 t 的文档数量)
python
vectorizer_tfidf = TfidfVectorizer(stop_words='english')
vectors_tfidf = vectorizer_tfidf.fit_transform(newsgroups_train.data) # (documents, vocab)
newsgroups_train.data[10:20]
python
['From: jbrandt@NeoSoft.com (J Brandt)\nSubject: Beta Testers Wanted for Graphics Libraries\nOrganization: NeoSoft Communications Services -- (713) 684-5900\nKeywords: xeg ceg beta imsl vni x graphics\nLines: 48\n\n\n Visual Numerics Inc. (formerly IMSL and Precision Visuals) is in the\nprocess of securing sites for beta testing X Exponent Graphics 1.0 \nand C Exponent Graphics 2.0. (Both X Exponent Graphics and C Exponent\nGraphics are 3GL products). The beta period is from April 26 through \nJune 18. The platform is HP9000/700 running under OS 8.07 with \nansi C 8.71 compiler. The media will be sent on 4mm DAT cartridge \ntape. Here are some of the key facts about the two products.\n \nX Exponent Graphics 1.0 key facts:\n \n1. Complete collection of high-level 2D and 3D application plot types\n available through a large collection of X resources.\n2. Cstom widget for OSF/Motif developers.\n3. Built-in interactive GUI for plot customization.\n4. Easily-implemented callbacks for customized application feedback.\n5. XEG 1.0, being built on the Xt Toolkit provides the user a widget \n library that conforms to the expected syntax and standards familar \n to X programmers.\n6. XEG will also be sold as a bundle with Visual Edge\'s UIM/X product.\n This will enable user to use a GUI builder to create the graphical\n layout of an application.\n \nC Exponent Graphics 2.0 key facts:\n \n1. Written in C for C application programmers/developers. The library\n is 100% written in C, and the programming interface conforms to C\n standards, taking advantage fo the most desirable features of C.\n2. Build-in GUI for interactive plot customization. Through mouse \n interaction, the user has complete interactive graph output control\n with over 200 graphics attributes for plot customization.\n3. Large collection of high-level application functions for "two-call"\n graph creation. A wide variety of 2D and 3D plot types are available\n with minimal programming effort.\n4. User ability to interrupt and control the X event. By controlling\n the X event loop, when the user use the mouse to manipulate the plot\n the user can allow CEG to control the event loop or the user can \n control the event loop.\n \nIf anyone is interested in beta testing either of the products, please\ncontact Wendy Hou at Visual Numerics via email at hou@imsl.com or call\n713-279-1066.\n \n \n-- \nJaclyn Brandt\njbrandt@NeoSoft.com\n--\n',......
python
W1 = clf.fit_transform(vector_tfidf)
H1 = clf.components_
show_topics(H1)
python
['god edu people jesus bible believe say don',
'space nasa edu gov access com graphics digex',
'sandvik kent apple newton com alink ksand private',
'keith caltech livesey sgi morality solntze wpd jon',
'henry toronto zoo spencer zoology edu work utzoo']
python
plt.plot(clf.components_[0])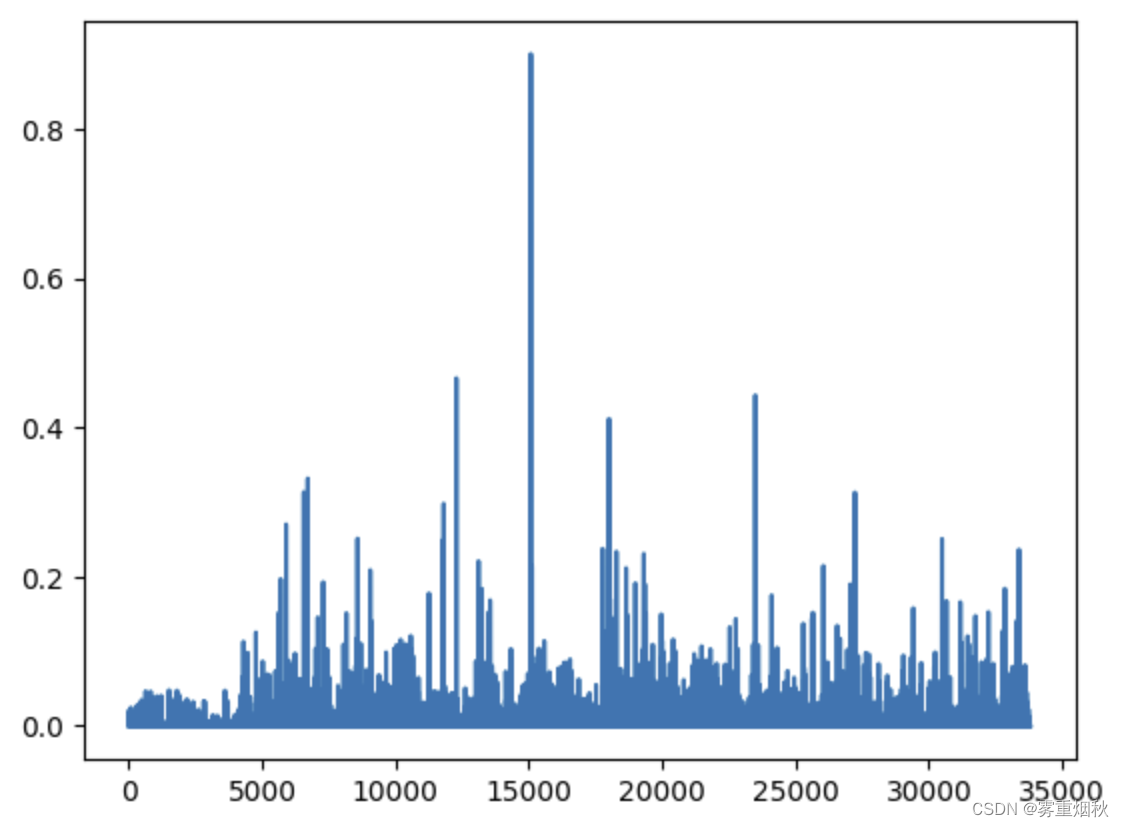
python
# 模型对象clf在使用训练数据进行拟合后,重建数据与原始数据之间的误差
clf.reconstruction_err_
python
44.03858988389047截断 SVD
通过仅计算我们感兴趣的列子集,我们在计算 NMF 时节省了大量时间。有没有办法用 SVD 获得这种好处?有!这叫做截断 SVD。我们只对与最大奇异值相对应的向量感兴趣。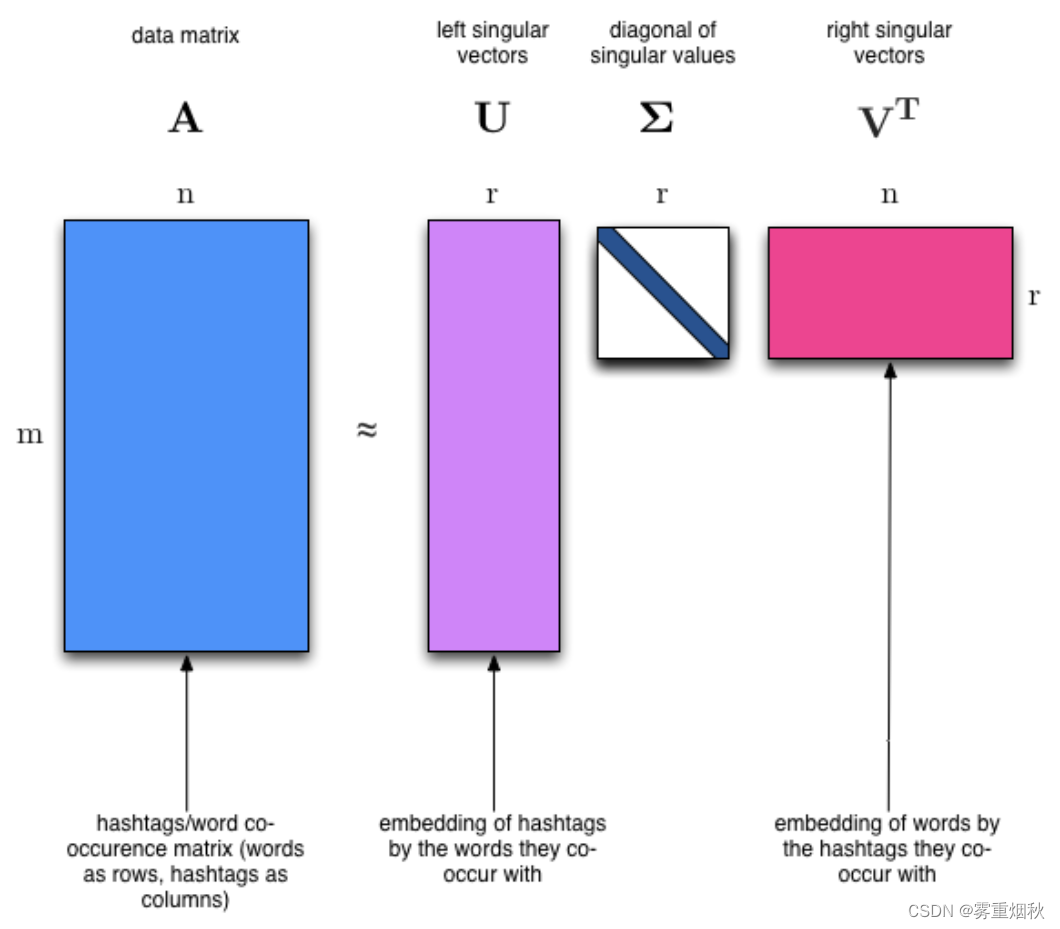
经典分解算法的缺点:
- 矩阵"非常大"
- 数据经常缺失或不准确。当输入的不精确性限制了输出的精度时,为什么要花费额外的计算资源?
- 数据传输现在在算法时间中起着重要作用。需要较少数据传递的技术可能会快得多,即使它们需要更多的浮点运算(浮点运算 = 浮点运算)。
- 充分利用 GPU 很重要。
随机算法的优点:
- 固有稳定性
- 性能保证不依赖于微妙的光谱特性
- 所需的矩阵向量积可以并行完成
时间比较
python
%time u, s, v = np.linalg.svd(vectors, full_matrices=False)
python
CPU times: total: 43.2 s
Wall time: 36.3 s
python
from sklearn import decomposition
import fbpca
%time u, s, v = decomposition.randomized_svd(vectors, 10)
python
CPU times: total: 2.7 s
Wall time: 4.18 s来自 Facebook 库 fbpca 的随机 SVD:
python
%time u, s, v = fbpca.pca(vectors, 10)
python
CPU times: total: 953 ms
Wall time: 1.23 s很明显,随机算法大大减少了时间,fbpca的随机SVD更快。