一 动态表与连续查询
1.1 动态表
1.是flink的支持流数据Table API 和SQL的核心概念。动态表随时间的变化而变化
2.在流上面定义的表在内部是没有数据的
1.2 连续查询
1.永远不会停止,结果是一张动态表
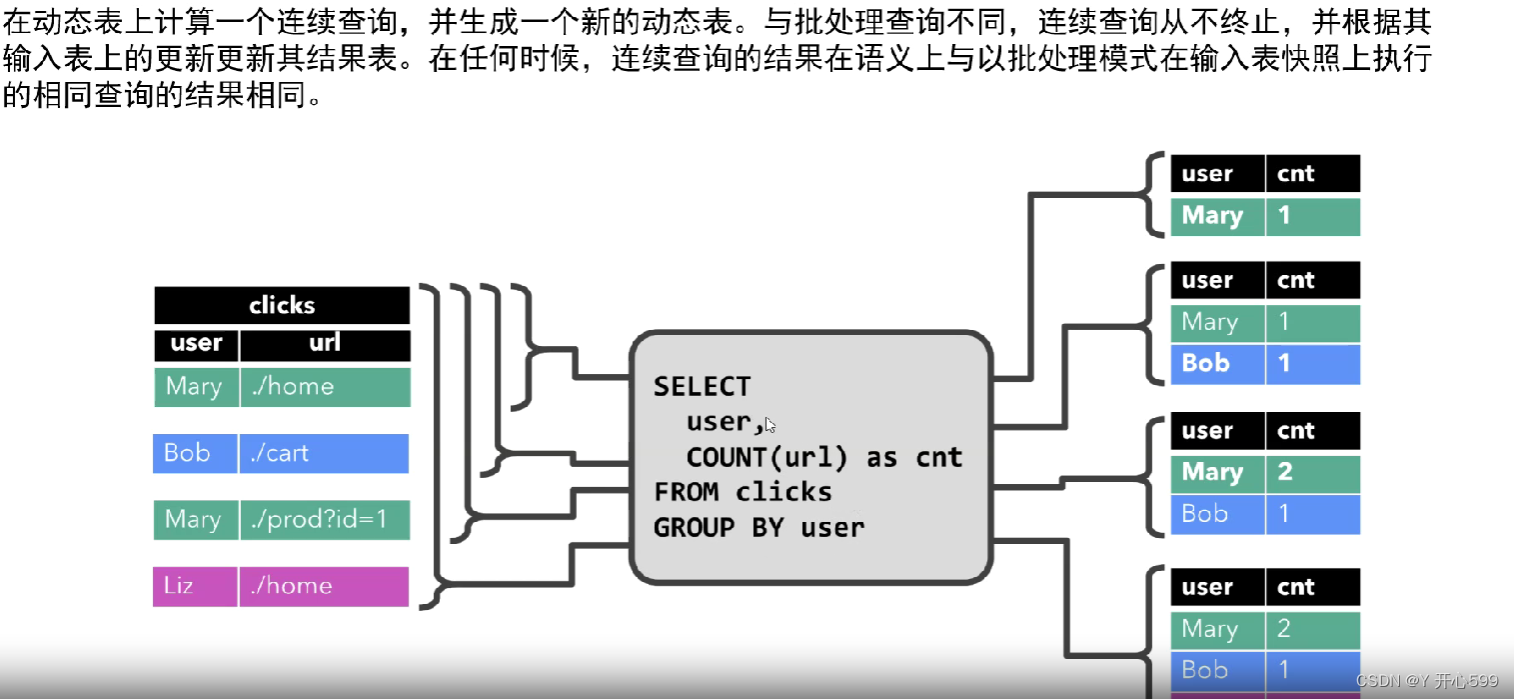
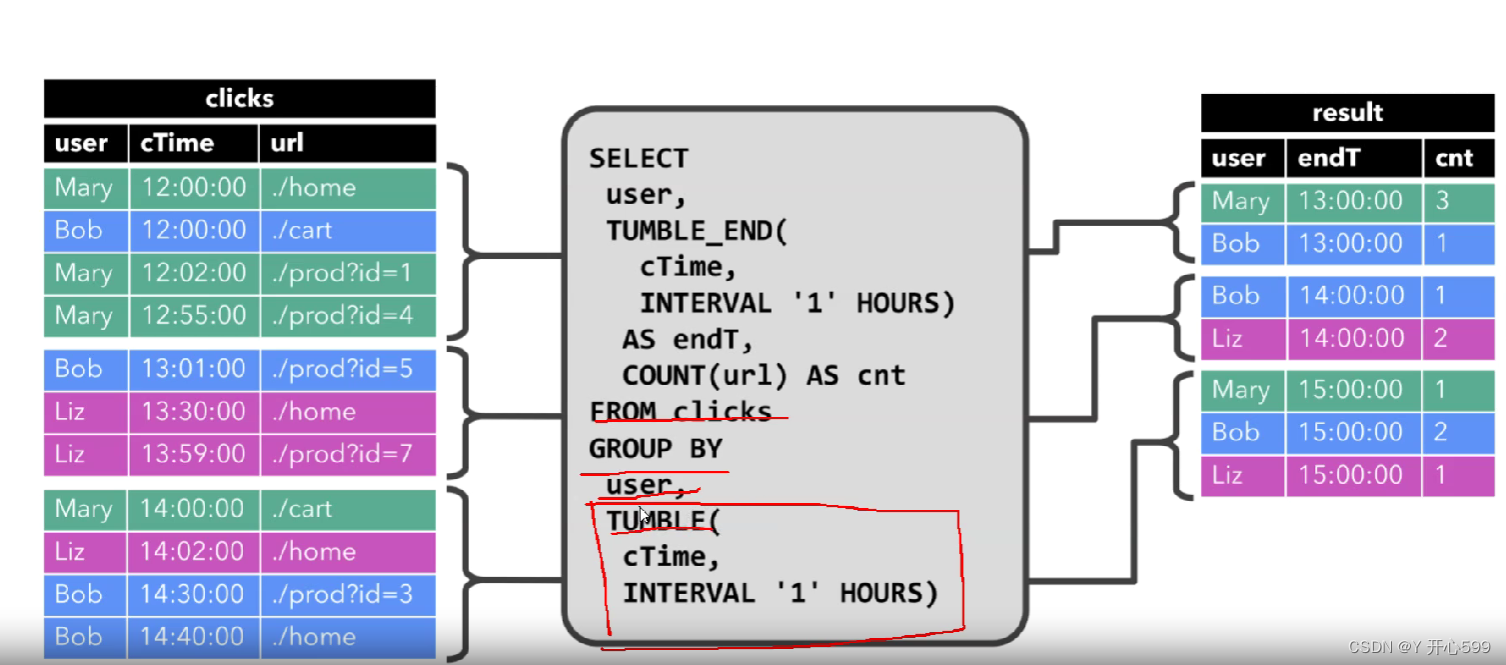


二 Flink SQL
2.1 sql行
1.先启动启动flink集群
2.进入sql命令行
3.创建一张数据源来自于kafka的表
如果退出命令行界面,这个表也不存在了,因为这个表基于内存的
CREATE TABLE students (
id STRING,
name STRING,
age INT,
sex STRING,
clazz STRING
) WITH (
'connector' = 'kafka',
'topic' = 'students', -- 指定topic
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表
'properties.group.id' = 'testGroup', -- 指定消费者组
'scan.startup.mode' = 'earliest-offset', -- 指定读取数据的位置
'format' = 'csv' -- 指定数据的格式
);
4.执行sql语句
select
clazz,count(1)as num
from students
group by clazz;
这个结果也是一张动态表
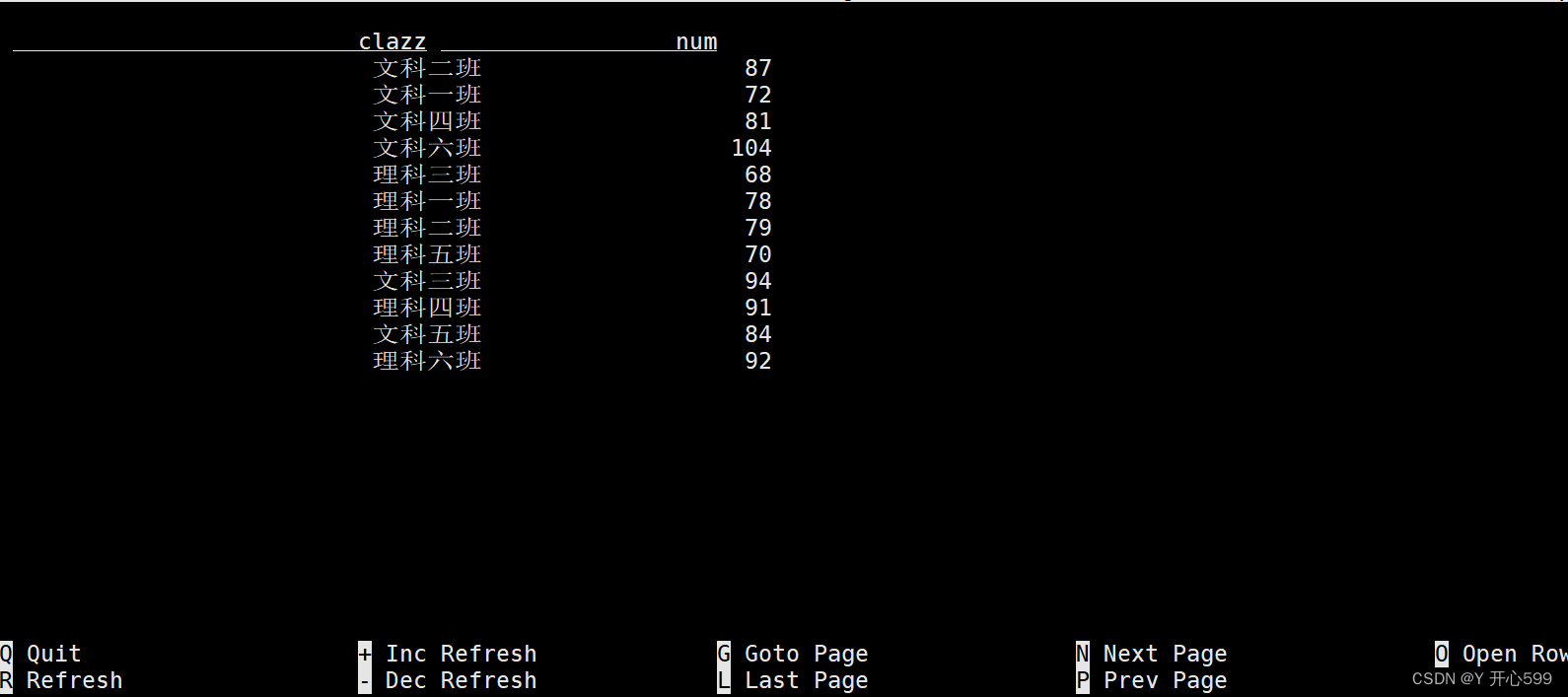 2.2打印结果模式
2.2打印结果模式
2.2.1 表格模式(table mode)默认
在内存中实体化结果,并将结果用规则的分页表格可视化展示出来。执行如下命令启用:
SET 'sql-client.execution.result-mode' = 'table';
这个就是表格模式
2.2.2 变更日志模式(changelog mode)
不会实体化和可视化结果,而是由插入(+)和撤销(-)组成的持续查询产生结果流。开启命令:
SET 'sql-client.execution.result-mode' = 'changelog';
我在kafka生产端添加了一条理科六班的数据,他表的变化是先加后减然后再加,他就是属于update,有之前的数据更新
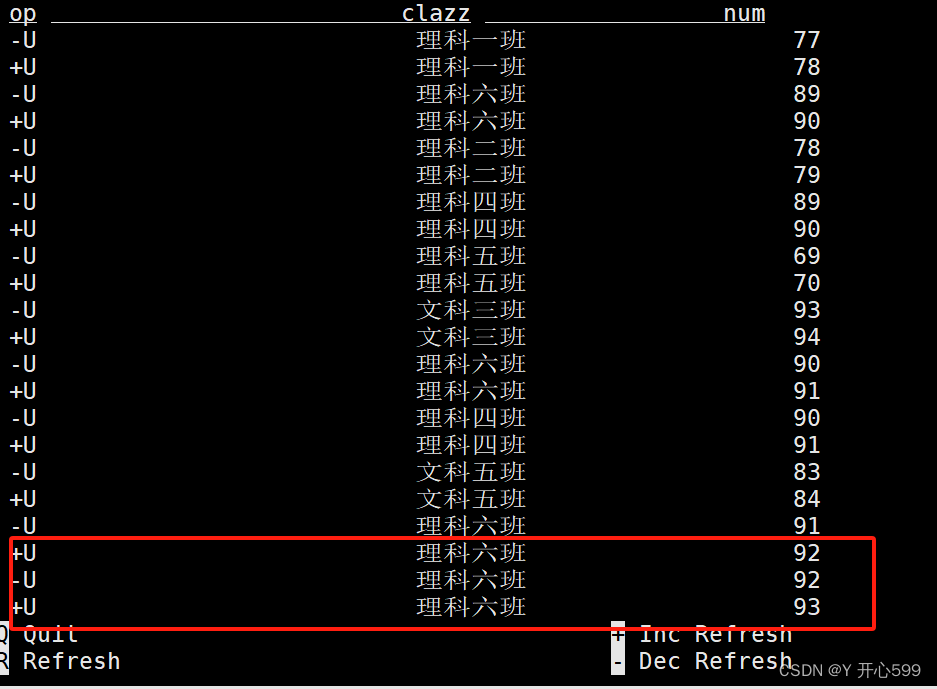
我又在kafka生产端添加了一条理科六班1的数据,这张动态表之前没有这个数据,所以他是insert

2.2.3 Tableau模式(tableau mode)
1.更接近传统的数据库,会将执行的结果以制表的形式直接打在屏幕之上。具体显示的内容会取决于作业 执行模式的不同(execution.type):
2.命令
SET 'sql-client.execution.result-mode' = 'tableau';
类似于日志一样,不会新开一个窗口,数据的添加还是跟变更日志模式一样 ,但是添加已有数据的方法是不一样的他是先减后加,他是Retract流,添加之前没有数据还是insert

2.3 连接器
2.3.1 kafka
1.导入依赖,放到flink的lib目录下
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka</artifactId> <version>1.15.4</version> </dependency>
1.kafka source
1.是无界流,将Kafka的数据->flink-sql
2.建表语句
-- 创建表 --- 无界流
-- TIMESTAMP(3): 时flink总的时间字段
CREATE TABLE students_kafka (
id STRING,
name STRING,
age INT,
sex STRING,
clazz STRING,
`event_time` TIMESTAMP(3) METADATA FROM 'timestamp',-- 获取kafka时间戳
`partition` BIGINT METADATA VIRTUAL, -- 获取kafka数据所在的分区
`offset` BIGINT METADATA VIRTUAL,-- 偏移量
-- 指定时间字段和水位线生成策略
WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'students',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv',
'csv.ignore-parse-errors' ='true' -- 当有脏数据时是否跳过当前行
);
2.查询语句
select id,name,event_time,`partition`,`offset` from students_kafka;
2. kafka sink
非聚合结果
也叫将仅插入的结果
1.建表(非聚合结果的)语句
-- 创建sink表
CREATE TABLE students_kafka_sink (
id STRING,
name STRING
) WITH (
'connector' = 'kafka',
'topic' = 'id_name',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
);
2.将非聚合查询结果插入的结果写入sink表
-- 1、将仅插入的结果写入sink表
insert into students_kafka_sink
select id,name from
students_kafka;
3.查看结果需要用到kafka的消费端,也可以使用sql
1.消费端:
kafka-console-consumer.sh --bootstrap-server master:9092,node1:9092,node2:9092 --from-beginning --topic id_name
select * from students_kafka_sink;
2.sql:
select * from students_kafka_sink;
聚合结果
将更新更改查询结果
指定类型需要指定 'format' = 'canal-json'
1.建表语句
-- 将更新更改的流写入kafka需要使用canal-json格式,
-- canal-json中带上了数据操作的类型
-- {"data":{"clazz":"理科六班","num":377},"type":"INSERT"}
CREATE TABLE clazz_num (
clazz STRING,
num BIGINT
) WITH (
'connector' = 'kafka',
'topic' = 'clazz_num',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'canal-json'
);
2.将更新更改查询结果写入kafka
insert into clazz_num
select
clazz,
count(1) as num
from
students_kafka
group by
clazz;
3.查询结果
1.消费:
kafka-console-consumer.sh --bootstrap-server master:9092,node1:9092,node2:9092 --from-beginning --topic clazz_num
2.sql:
select * from clazz_num;
2.3.2 JDBC
1.整合
将依赖包上传到flink的lib目录下
flink-connector-jdbc-1.15.2.jar
mysql-connector-java-5.1.47.jar
依赖更新后需要重启集群才会生效
yarn application -list
yarn application -kill appid
1.mysql source
1.有界流,将mysql的数据写进flink-sql中
2.字段名称和字段类型需要和数据库中保存一致
3.建表语句
-- 创建soure 表 --- 有界流
-- 字段名称和字段类型需要和数据库中保存一致
CREATE TABLE students_mysql (
id int,
name STRING,
age INT,
gender STRING,
clazz STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://master:3306/bigdata29',
'table-name' = 'students',
'username' ='root',
'password' = '123456'
);
2.mysql sink
1.将flink-sql中的一张表或者查询语句的结果存放在mysql中
2.mysql中表需要提前创建
3.需要增加主键约束,flink会通过主键更新数据
3.mysql中的表也是动态变化的,只要flink中的表变了
4.建表语句
-- 创建mysql sink表。需要增加主键约束,flink会通过主键更新数据
CREATE TABLE clazz_num_mysql (
clazz STRING,
num BIGINT,
PRIMARY KEY (clazz) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://master:3306/bigdata29?useUnicode=true&characterEncoding=UTF-8',
'table-name' = 'clazz_num_flinkToMysql', -- 需要手动创建
'username' ='root',
'password' = '123456'
);
5.查询语句
insert into clazz_num_mysql
select
clazz,
count(1) as num
from
students_kafka
group by
clazz;
2.3.3 hdfs
1.hdfs source
有界流表
1.建表语句
-- 创建hdfs source表 -- 有界流
CREATE TABLE students_hdfs (
id int,
name STRING,
age INT,
gender STRING,
clazz STRING
) WITH (
'connector' = 'filesystem', -- 必选:指定连接器类型
'path' = 'hdfs://master:9000/bigdata29/data/students.csv', -- 必选:指定路径
'format' = 'csv' -- 必选:文件系统连接器指定 format
);
无界表
1.他是定时监控一个文件夹下面的文件,所以是无界流
2.需要配置扫描文件夹的间隔时间
3.建表语句
-- 创建hdfs source表 -- 无界流
CREATE TABLE students_hdfs_stream (
id int,
name STRING,
age INT,
gender STRING,
clazz STRING
) WITH (
'connector' = 'filesystem', -- 必选:指定连接器类型
'path' = 'hdfs://master:9000/data/students', -- 必选:指定路径
'format' = 'csv', -- 必选:文件系统连接器指定 format
'source.monitor-interval' = '5000' -- 指定扫描目录的间隔时间
);

2. hdfs sink
非聚合结果
1.也叫将仅插入的结果
2.建表语句
-- 将仅追加的结果流写入hdfs
CREATE TABLE students_hdfs_sink (
id STRING,
name STRING,
age INT,
sex STRING,
clazz STRING
) WITH (
'connector' = 'filesystem', -- 必选:指定连接器类型
'path' = 'hdfs://master:9000/data/students_sink', -- 必选:指定路径
'format' = 'csv' -- 必选:文件系统连接器指定 format
);
3.插入语句
insert into students_hdfs_sink
select id,name,age,sex,clazz from students_kafka;
集合结果
1.将更新更改查询结果保存到hdfs中
2.指定类型 'format' = 'canal-json'
3.建表语句
CREATE TABLE clazz_num_hdfs (
clazz STRING,
num BIGINT
) WITH (
'connector' = 'filesystem', -- 必选:指定连接器类型
'path' = 'hdfs://master:9000/data/clazz_num', -- 必选:指定路径
'format' = 'canal-json' -- 必选:文件系统连接器指定 format
);
4.查询语句
insert into clazz_num_hdfs
select
clazz,
count(1) as num
from
students_kafka
group by clazz;
2.3.4 hbase
1.整合
将依赖包上传到flink的lib目录下
flink-sql-connector-hbase-2.2-1.15.2.jar
依赖更新后需要重启集群才会生效
yarn application -list
yarn application -kill appid
2.hbase最好在存储数据的地方,因为他查询比较麻烦
3.先创建hbase表
create 'students_flink','info'
4.创建hbase sink表
-- 创建hbase sink表
CREATE TABLE students_hbase (
id STRING,
info ROW<name STRING,age INT,sex STRING,clazz STRING>, -- 指定列簇中的咧
PRIMARY KEY (id) NOT ENFORCED -- 设置hbaserowkey
) WITH (
'connector' = 'hbase-2.2',
'table-name' = 'students_flink',
'zookeeper.quorum' = 'master:2181,node1:2181,node2:2181'
);
5.查看结果
在flink-sql查看:select * from students_hbase;
在hbase查看:scan 'students_flink'
2.3.5 datagen
1.用于生成测试数据,可以用于高性能测试,这个数据是随机生成的
2.建表语句
-- 创建datagen source表
CREATE TABLE students_datagen (
id STRING,
name STRING,
age INT,
sex STRING,
clazz STRING
) WITH (
'connector' = 'datagen',
'rows-per-second'='5', -- 指定每秒生成的数据量
'fields.id.length'='5',
'fields.name.length'='3',
'fields.age.min'='1',
'fields.age.max'='100',
'fields.sex.length'='1',
'fields.clazz.length'='4'
);
2.3.7 print
1.结果在task manager查看
2.建表语句
CREATE TABLE print_table (
id STRING,
name STRING,
age INT,
sex STRING,
clazz STRING
) WITH (
'connector' = 'print'
);
3.插入语句
insert into print_table
select * from students_datagen;
4.结果

2.3.8 BlackHole
1.用于高性能测试
2.建表
CREATE TABLE blackhole_table (
id STRING,
name STRING,
age INT,
sex STRING,
clazz STRING
) WITH (
'connector' = 'blackhole'
);
3.插入数据
insert into blackhole_table
select * from students_datagen;
4.没有结果
2.4 处理模式
2.4.1流处理模式
1、可以用于处理有界流和无界流
2、流处理模式输出连续结果
3、流处理模式底层时持续流模型
设置参数,直接在flink-sql的客户端直接输入
SET 'execution.runtime-mode' = 'streaming';
流处理结果图
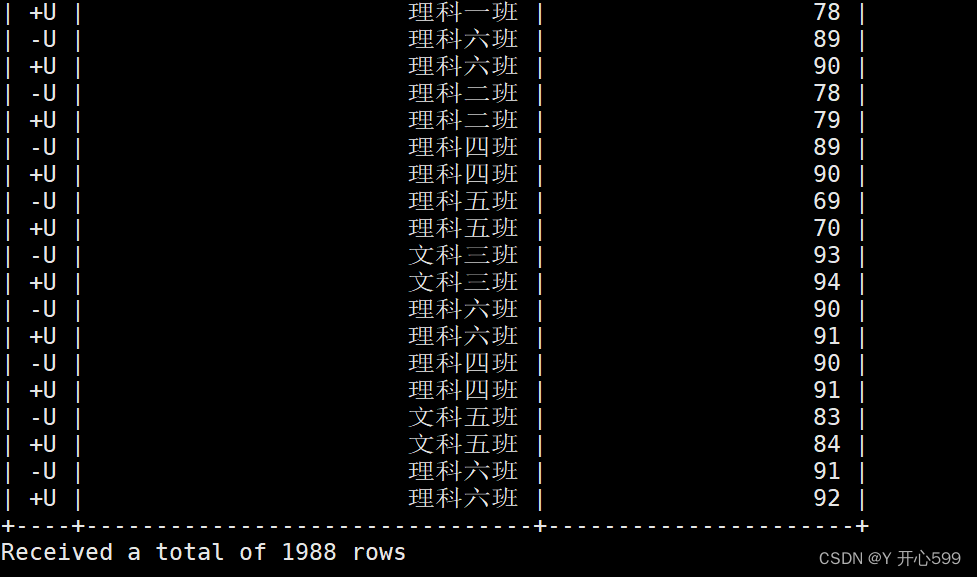
2.4.2 批处理模式
1、批处理模式只能用于处理有界流
2、输出最终结果
3、底层是MapReduce模型
设置直接输入
SET 'execution.runtime-mode' = 'batch';
批处理结果图
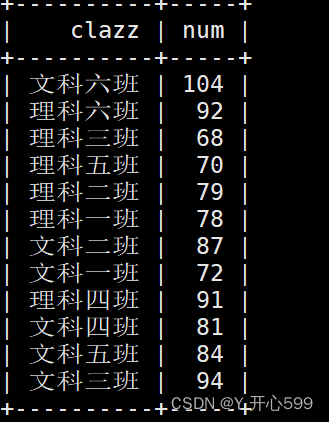
2.5 数据格式
2.5.1 csv
1.默认是以英文逗号为分隔符
2.数据中字段的顺序需要和建表语句字段的顺序保持一致 (顺序映射)
3.建表语句
CREATE TABLE students_csv (
id STRING,
name STRING,
age INT,
sex STRING,
clazz STRING
) WITH (
'connector' = 'kafka',
'topic' = 'students', -- 指定topic
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表
'properties.group.id' = 'testGroup', -- 指定消费者组
'scan.startup.mode' = 'earliest-offset', -- 指定读取数据的位置
'format' = 'csv', -- 指定数据的格式
'csv.field-delimiter' = ',' ,-- 指定分隔符
'csv.ignore-parse-errors' ='true' -- 跳过脏数据
);
2.5.2 json
1.flink表中的字段和类型需要和json中保持一致(同名映射)
2.建表
CREATE TABLE cars (
car STRING,
city_code STRING,
county_code STRING,
card BIGINT,
camera_id STRING,
orientation STRING,
road_id BIGINT,
`time` BIGINT,
speed DOUBLE
) WITH (
'connector' = 'kafka',
'topic' = 'cars', -- 指定topic
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表
'properties.group.id' = 'testGroup', -- 指定消费者组
'scan.startup.mode' = 'earliest-offset', -- 指定读取数据的位置
'format' = 'json', -- 指定数据的格式
'json.ignore-parse-errors' ='true'
);
2.5.3 canal-json
1.用于保存更新更改的结果流(聚合计算的结果保存到其他位置)
2.例子
CREATE TABLE clazz_num (
clazz STRING,
num BIGINT
) WITH (
'connector' = 'kafka',
'topic' = 'clazz_num',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'canal-json'
);
insert into clazz_num
select
clazz,
count(1) as num
from
students_kafka
group by
clazz;
2.6 时间属性
2.6.1 处理时间
1.PROCTIME() 生成处理时间的函数
2.建表语句
CREATE TABLE words (
word STRING,
proctime AS PROCTIME() -- 声明一个额外的列作为处理时间属性
) WITH (
'connector' = 'kafka',
'topic' = 'words',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv',
'csv.ignore-parse-errors' ='true' -- 当有脏数据时是否跳过当前行
);
2.查询结果
select * from words;

- 实时统计每个单词最近5秒单词的数量
select
word,
TUMBLE_START(proctime,INTERVAL '5' SECOND) win_start,
TUMBLE_END(proctime,INTERVAL '5' SECOND) win_end,
count(1) as num
from
words
group by
word,
TUMBLE(proctime,INTERVAL '5' SECOND); --prctime表示处理时间的字段,INTERVAL '5' SECOND表示窗口的大小
2.6.2 事件时间
1.建表语句
注意:这个时间字段一定是时间戳形式,且字段里面有时间的概念。
CREATE TABLE words_event_time (
word STRING,
`event_time` TIMESTAMP(3), -- 时间字段
-- 指定时间字段和水位线生成策略
WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'words_event_time',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv',
'csv.ignore-parse-errors' ='true' -- 当有脏数据时是否跳过当前行
);
2.7 sql语法
2.7.1 hints
1.动态表选择:可以在查询表的时候动态修改表的参数配置
2.查询语句
select * from students /*+ OPTIONS('csv.ignore-parse-errors' ='true') */;
students动态表的参数
WITH (
'connector' = 'kafka',
'topic' = 'students', -- 指定topic
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表
'properties.group.id' = 'testGroup', -- 指定消费者组
'scan.startup.mode' = 'earliest-offset', -- 指定读取数据的位置
'format' = 'csv' -- 指定数据的格式
);
2.7.2 with
1.当有一段sql逻辑重复时,可以定义在with语句中,减少代码量
2.sql
with tmp as (
select
id,name,age,clazz
from
students_hdfs_stream
where age > 22 --括号里面的逻辑是多次出现的
)
select * from tmp
union all
select * from tmp;

2.7.3 SELECT WHERE
1.简单的语句,不必多说
2.7.4 SELECT DISTINCT
对于流处理的问题
1、flink会将之前的数据保存在状态中,用于判断是否重复
2、如果表的数据量很大,随着时间的推移状态会越来越大,状态的数据时先保存在TM的内存中的,时间长了可能会出问题
注意:distinct后面加字段
2.7.5 窗口函数
1.滚动窗口函数
1.建表语句
CREATE TABLE bid (
item STRING,
price DECIMAL(10, 2),
bidtime TIMESTAMP(3),
WATERMARK FOR bidtime AS bidtime - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'bid',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv',
'csv.ignore-parse-errors' ='true' -- 当有脏数据时是否跳过当前行
);
2.添加数据
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic bid
C,4.00,2020-04-15 08:05:01
A,2.00,2020-04-15 08:07:01
D,5.00,2020-04-15 08:09:01
B,3.00,2020-04-15 08:11:01
E,1.00,2020-04-15 08:13:01
F,6.00,2020-04-15 08:17:01
3.查询语句
SELECT item,price,bidtime,window_start,window_end,window_time FROM TABLE(
TUMBLE(TABLE bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES)
);
其中TUMBLE:滚动窗口函数,在原表的基础上增加窗口开始时间,窗口结束时间,窗口时间,重新组成一张表
DESCRIPTOR(bidtime)里面传入的是事件时间,INTERVAL '10' MINUTES:窗口的大小

2.滑动窗口函数
1.建表语句
CREATE TABLE bid_proctime (
item STRING,
price DECIMAL(10, 2),
proctime AS PROCTIME()
) WITH (
'connector' = 'kafka',
'topic' = 'bid_proctime',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv',
'csv.ignore-parse-errors' ='true' -- 当有脏数据时是否跳过当前行
);
PROCTIME() 生成处理时间的函数
2.添加数据
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic bid_proctime
C,4.00
A,2.00
D,5.00
B,3.00
E,1.00
F,6.00
3.查询语句
SELECT item,price,proctime,window_start,window_end,window_time FROM TABLE(
HOP(TABLE bid_proctime, DESCRIPTOR(proctime), INTERVAL '5' SECOND, INTERVAL '10' SECOND)
);
HOP:滑动窗口函数,在原表的基础上增加窗口开始时间,窗口结束时间,窗口时间,重新组成一张表
DESCRIPTOR:里面是时间
INTERVAL '5' SECOND, INTERVAL '10' SECOND:每五秒计算窗口为10秒里的数据
3.会话窗口
1.查询语句
select
item,
SESSION_START(proctime,INTERVAL '5' SECOND) as session_start,
SESSION_END(proctime,INTERVAL '5' SECOND) as session_end,
sum(price) as sum_price
from
bid_proctime
group by
item,
SESSION(proctime,INTERVAL '5' SECOND);
再5秒里面,窗口没有数据开始计算
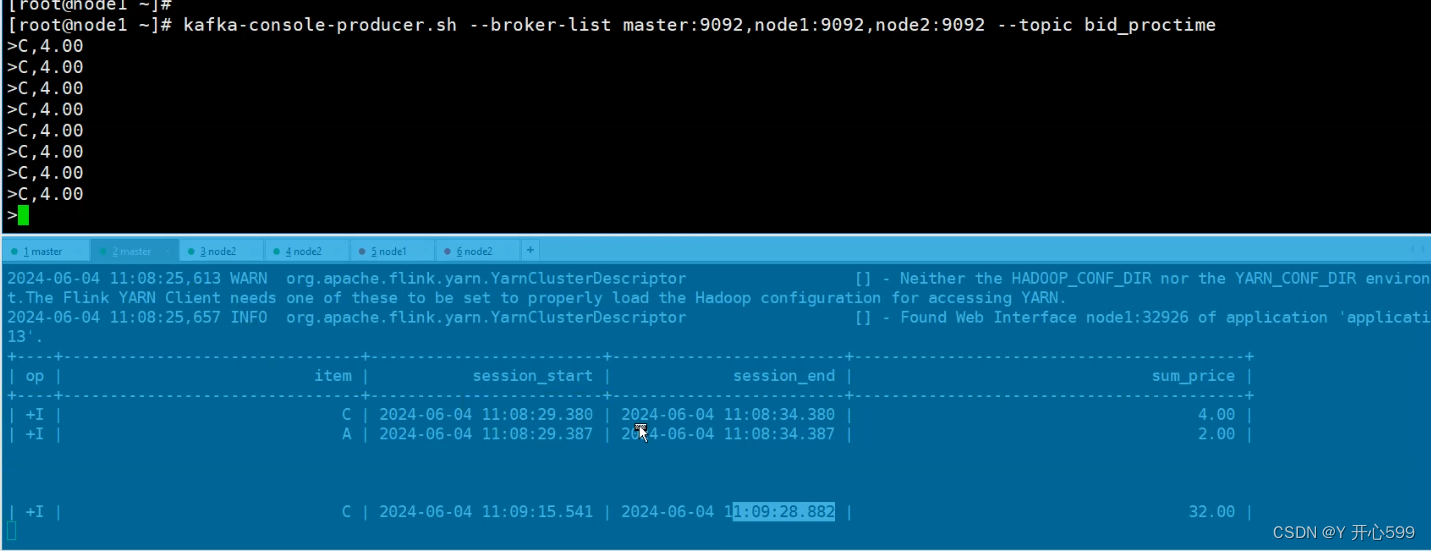
2.7.6 group by
1.分组聚合需要将之前的计算结果保存在状态中,
如果状态无限增长,会导致checkpoint时间拉长,如果checkpoint超时失败了,也会导致任务失败
2.需要在表的参数后面加一个参数 /*+ OPTIONS('fields.word.length'='7') */,可以将这个数字变小一点,状态会变小一点
insert into blackhole_table
select
word,
count(1)as num
from
words_datagen /*+ OPTIONS('fields.word.length'='7') */
group by
word;
2.7.7 over
1.sum开窗
1.只能做累加,不能做全局(要有order by)
2.只能按照时间字段升序
3.建表语句
CREATE TABLE `order` (
order_id STRING,
amount DECIMAL(10, 2),
product STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'order',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv',
'csv.ignore-parse-errors' ='true' -- 当有脏数据时是否跳过当前行
);
4.插入语句
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic order
1,4.00,001,2020-04-15 08:05:01
2,2.00,001,2020-04-15 08:07:01
3,5.00,001,2020-04-15 08:09:01
4,3.00,001,2020-04-15 08:11:01
5,1.00,001,2020-04-15 08:13:01
6,6.00,001,2020-04-15 08:17:01
6,6.00,001,2020-04-15 08:20:01
6,6.00,001,2020-04-15 08:21:01
6,10.00,001,2020-04-15 08:21:02
6,11.00,001,2020-04-15 08:21:03
6,12.00,001,2020-04-15 08:21:04
5.查询语句
--实时统计每个商品的累计总金额,将总金额放在每一条数据的后面
select
order_id,
amount,
product,
order_time,
sum(amount) over(
partition by product
order by order_time
)
from
`order`
;

-- 2、实时统计每个商品的累计总金额,将总金额放在每一条数据的后面,只统计最近10分钟的数据
select
order_id,
amount,
product,
order_time,
sum(amount) over(
partition by product
order by order_time
-- 统计10分钟前到当前行的数据
RANGE BETWEEN INTERVAL '10' MINUTES PRECEDING AND CURRENT ROW
)
from
`order`
;

-- 2、实时统计每个商品的累计总金额,将总金额放在每一条数据的后面,计算最近5条数据
select
order_id,
amount,
product,
order_time,
sum(amount) over(
partition by product
order by order_time
-- 从前4条数据到当前行
ROWS BETWEEN 4 PRECEDING AND CURRENT ROW
)
from
`order`
;

2.max,min,avg,count
-- 2、实时统计每个商品的最大金额,将总金额放在每一条数据的后面,计算最近5条数据
select
order_id,
amount,
product,
order_time,
max(amount) over(
partition by product
order by order_time
-- 从前4条数据到当前行
ROWS BETWEEN 4 PRECEDING AND CURRENT ROW
)
from
`order`
;
3. row_number
1.如果只是增加排名,只能按照时间字段升序排序
select
order_id,
amount,
product,
order_time,
row_number() over(partition by product order by order_time) as r
from
`order`
;
2.本来开窗的字段只能是时间字段,如果外面接一个子查询,那么就没有限制了
-- 实时统计每个商品金额最高的前两个商品 -- TOPN
-- 去完topn之后需要计算的排名的数据较少了,计算代价降低了
select *
from (
select
order_id,
amount,
product,
order_time,
row_number() over(partition by product order by amount desc) as r
from
`order`
)
where r <= 2
2.7.8 order by
1.考虑计算代价,只能按照时间字段来进行升序(第一个字段必须是时间字段,后面可以是非时间字段)
select * from
`order`
order by
order_time,amount
- 不考虑计算代价,加上子查询或者limit限制,那么可以是非时间字段
select * from
`order`
order by
amount
limit 2;
2.7.9 模式监测
1.建表语句
CREATE TABLE tran (
id STRING,
amount DECIMAL(10, 2),
proctime as PROCTIME()
) WITH (
'connector' = 'kafka',
'topic' = 'tran',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'csv',
'csv.ignore-parse-errors' ='true' -- 当有脏数据时是否跳过当前行
);
2.插入语句
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic tran
1,4.00
1,2.00
1,5.00
1,0.90
1,600.00
1,4.00
1,2.00
1,0.10
1,200.00
1,700.00
3.查询语句
定义单个
-- 我们先实现第一版报警程序,对于一个账户,如果出现小于 1 美元的交易后紧跟着一个大于 500 的交易,就输出一个报警信息。
SELECT *
FROM tran
MATCH_RECOGNIZE (
PARTITION BY id -- 分组字段
ORDER BY proctime -- 排序字段,只能按照时间字段升序排序
MEASURES -- 相当于select
A.amount as min_amount,
A.proctime as min_proctime,
B.amount as max_amount,
B.proctime as max_proctime
PATTERN (A B) -- WITHIN INTERVAL '5' SECOND -- 定义规则,增加事件约束,需要在5秒内匹配出结果
DEFINE -- 定义条件
A as amount < 1,
B as amount > 500
) AS T
定义多个,可以使用正则表达式
SELECT *
FROM tran
MATCH_RECOGNIZE (
PARTITION BY id -- 分组字段
ORDER BY proctime -- 排序字段,只能按照时间字段升序排序
MEASURES -- 相当于select
A.amount as a_amount, -- 获取最后一条
min(A.amount) as min_a_amount, -- 取最小的
max(A.amount) as max_a_amount, -- 取最大的
sum(A.amount) as sum_a_amount, -- 求和
avg(A.amount) as avg_a_amount, -- 平均
FIRST(A.amount) AS first_a_amount, -- 取前面第一条
LAST(A.amount) AS LAST_a_amount, -- 取后面第一条
B.amount as b_amount
PATTERN (A{3} B) -- 定义规则,这里定义了3个A,一个B
DEFINE -- 定义条件
A as amount < 1,
B as amount > 500
) AS T;
注意他默认的是匹配策略是SKIP TO NEXT ROW,如果想要修改,直接加参数AFTER MATCH SKIP PAST LAST ROW -- 从当前匹配成功之后的下一行开始匹配

另一个例题
CREATE TABLE ticker (
symbol STRING,
rowtime TIMESTAMP(3), -- 时间字段
price DECIMAL(10, 2) ,
tax DECIMAL(10, 2),
-- 指定时间字段和水位线生成策略
WATERMARK FOR rowtime AS rowtime
) WITH (
'connector' = 'kafka',
'topic' = 'ticker',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'csv',
'csv.ignore-parse-errors' ='true' -- 当有脏数据时是否跳过当前行
);
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic ticker
ACME,2024-06-04 10:00:00,12,1
ACME,2024-06-04 10:00:01,17,2
ACME,2024-06-04 10:00:02,19,1
ACME,2024-06-04 10:00:03,21,3
ACME,2024-06-04 10:00:04,25,2
ACME,2024-06-04 10:00:05,18,1
ACME,2024-06-04 10:00:06,15,1
ACME,2024-06-04 10:00:07,14,2
ACME,2024-06-04 10:00:08,24,2
ACME,2024-06-04 10:00:09,25,2
ACME,2024-06-04 10:00:10,19,1
-- 找出一个单一股票价格不断下降的时期
select * from
ticker
MATCH_RECOGNIZE (
PARTITION BY symbol -- 分组字段
ORDER BY rowtime -- 排序字段,只能按照时间字段升序排序
MEASURES -- 相当于select
A.price as a_price,
FIRST(B.price) as FIRST_b_price,
LAST(B.price) as last_b_price,
C.price as c_price
AFTER MATCH SKIP PAST LAST ROW -- 从当前匹配成功之后的下一行开始匹配
PATTERN (A B+ C) -- 定义规则
DEFINE -- 定义条件
-- 如果时第一个B,就和A比较,如果时后面的B,就和前一个B比较
B as (LAST(B.price,1)is null and B.price < A.price) or B.price < LAST(B.price,1),
C as C.price > LAST(B.price)
) AS T;
2.7.10 join
1 Regular Joins
1.和hive sql中的join是一样的
inner join 内连接:两张表都有的数据
left join 左连接 :左表有数据显示,右表没有为null
right join 右连接:显示右表有的数据,左表没有的为null
full join:全连接:只显示左右表共有的数据
-- 常规的关联方式,会将两个表的数据一直保存在状态中,时间长了,状态会越来越大,导致任务执行失败
-- 状态有效期,状态在flink中保存的事件,状态保留多久需要根据实际业务分析
如果是流表的话需要输入:
SET 'table.exec.state.ttl' = '10000'; --这个代码直接在命令行提前输入
2. Interval Joins
1.在一段时间内关联,字段必须要有时间戳的时间字段,两张表都是流式的。
proctime这个就是时间字段
select a.id,a.name,b.sid,b.score from
students_proctime a, scores_proctime b
where a.id=b.sid
-- a表的时间需要在b表时间10秒内或者b表的时间需要在a表时间10秒内
and (
a.proctime BETWEEN b.proctime - INTERVAL '10' SECOND AND b.proctime
or b.proctime BETWEEN a.proctime - INTERVAL '10' SECOND AND a.proctime
);
3. Temporal Joins
流表关联时态表
1.建表语句
CREATE TABLE orders (
order_id STRING,
price DECIMAL(32,2),
currency STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time
) WITH (
'connector' = 'kafka',
'topic' = 'orders', -- 指定topic
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表
'properties.group.id' = 'testGroup', -- 指定消费者组
'scan.startup.mode' = 'latest-offset', -- 指定读取数据的位置
'format' = 'csv' -- 指定数据的格式
);
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic orders
o_001,1,EUR,2024-06-06 12:00:00
o_002,100,EUR,2024-06-06 12:00:07
o_003,200,EUR,2024-06-06 12:00:16
o_004,10,EUR,2024-06-06 12:00:21
o_005,20,EUR,2024-06-06 12:00:25
-- 汇率表
CREATE TABLE currency_rates (
currency STRING,
conversion_rate DECIMAL(32, 2),
update_time TIMESTAMP(3),
WATERMARK FOR update_time AS update_time,
PRIMARY KEY(currency) NOT ENFORCED -- 主键,区分不同的汇率
) WITH (
'connector' = 'kafka',
'topic' = 'currency_rates1', -- 指定topic
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表
'properties.group.id' = 'testGroup', -- 指定消费者组
'scan.startup.mode' = 'earliest-offset', -- 指定读取数据的位置
'format' = 'canal-json' -- 指定数据的格式
);
insert into currency_rates
values
('EUR',0.12,TIMESTAMP'2024-06-06 12:00:00'),
('EUR',0.11,TIMESTAMP'2024-06-06 12:00:09'),
('EUR',0.15,TIMESTAMP'2024-06-06 12:00:17'),
('EUR',0.14,TIMESTAMP'2024-06-06 12:00:23');
kafka-console-consumer.sh --bootstrap-server master:9092,node1:9092,node2:9092 --from-beginning --topic currency_rates1
2.常规关联查询
-- 使用常规关联方式关联时态表只能关联到最新的数据
select
a.price,a.order_time,b.conversion_rate,b.update_time
from
orders as a
join
currency_rates as b
on a.currency=b.currency;
只能取出最新的结果,因为表是动态的
3.动态join
FOR SYSTEM_TIME AS OF a.order_time: 使用a表的时间到b表中查询对应时间段的数据
select
a.price,a.order_time,b.conversion_rate,b.update_time
from
orders as a
join
currency_rates FOR SYSTEM_TIME AS OF a.order_time as b
on a.currency=b.currency;

4. lookup join
1用于流表关联维度表
流表:动态表
维度表:不怎么变化的变,维度表的数据一般可以放在hdfs或者mysql
2.建表语句
CREATE TABLE scores (
sid INT,
cid STRING,
score INT,
proctime AS PROCTIME()
) WITH (
'connector' = 'kafka',
'topic' = 'scores', -- 指定topic
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表
'properties.group.id' = 'testGroup', -- 指定消费者组
'scan.startup.mode' = 'latest-offset', -- 指定读取数据的位置
'format' = 'csv' -- 指定数据的格式
);
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic scores
1500100001,1000001,98
1500100002,1000002,5
1500100001,1000003,137
CREATE TABLE students --这里的学生表只有一条数据(id INT,
name STRING,
age INT,
gender STRING,
clazz STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://master:3306/bigdata29',
'table-name' = 'student',
'username' ='root',
'password' = '123456',
'lookup.cache.max-rows' = '1000', -- 最大缓存行数
'lookup.cache.ttl' ='10000' -- 缓存过期时间
);
3.使用常规关联查询
-- 维表的数据只在任务启动的时候读取一次,后面不再实时读取,
-- 只能关联到任务启动时读取的数据
select a.sid,a.score,b.id,b.name from
scores as a
left join
students as b
on a.sid=b.id;
如果mysql表里面的数据增加的话,刚刚好增加的部分数据能与流表数据关联,但是查询不到
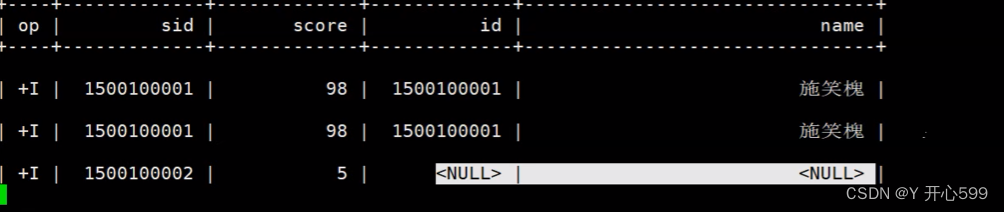
4.lookup join
使用这个的前提是流表得是时间字段,
-- lookup join
-- 当流表每来一条数据时,使用关联字段到维表的数据源中查询
-- 每一次都需要查询数据库,性能会降低
select a.sid,a.score,b.id,b.name from
scores as a
left join
students FOR SYSTEM_TIME AS OF a.proctime as b
on a.sid=b.id;
5.解决 每一次都需要查询数据库,性能会降低的方案
在创建维度表史加2个参数
'lookup.cache.max-rows' = '1000', -- 最大缓存行数
'lookup.cache.ttl' ='10000' -- 缓存过期时间,这个时间可以根据更新的时间来定义
2.8 整合hive
2.8.1 整合
1.整合
上传依赖到flink的lib目录下
flink-sql-connector-hive-3.1.2_2.12-1.15.2.jar
重启flink集群
yarn application -list
yarn application -kill XXX
2.8.2 hive catalog
1.catalog--->database--->table---->字段---->数据
catalog是数据库上面的一个概念,一个cataloglog中可以有多个database, catalog就是flink抽象的元数据层
2.default_catalog:是flink默认的元数据,将元数据保存在jobmanager的内存中
3.使用
-- 1、启动hive的元数据服务
nohup hive --service metastore &
-- 2、创建hive catalog
CREATE CATALOG hive_catalog WITH (
'type' = 'hive',
'hive-conf-dir' = '/usr/local/soft/hive-3.1.2/conf' --这个是hive配置文件的路径
);
show catalogs;
--3、切换catalog
use catalog hive_catalog;
-- 查询hive中的表
select * from hive_catalog.bigdata29.students;
-- 创建数据库create database flink;
-- flink可以查询hive的表,hive不能查询flink创建的动态表
-- 在hive cagalog 中保存flink的动态表
CREATE TABLE students_csv (
id STRING,
name STRING,
age INT,
sex STRING,
clazz STRING
) WITH (
'connector' = 'kafka',
'topic' = 'students', -- 指定topic
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表
'properties.group.id' = 'testGroup', -- 指定消费者组
'scan.startup.mode' = 'earliest-offset', -- 指定读取数据的位置
'format' = 'csv', -- 指定数据的格式
'csv.field-delimiter' = ',' ,-- 指定分隔符
'csv.ignore-parse-errors' ='true' -- 跳过脏数据
);
2.8.3 hive functions
-- 加载hive函数
LOAD MODULE hive WITH ('hive-version' = '3.1.2');select split('java,flink',',');
CREATE TABLE lines (
line STRING
) WITH (
'connector' = 'kafka',
'topic' = 'lines', -- 指定topic
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表
'properties.group.id' = 'testGroup', -- 指定消费者组
'scan.startup.mode' = 'earliest-offset', -- 指定读取数据的位置
'format' = 'csv', -- 指定数据的格式
'csv.field-delimiter' = '|' ,-- 指定分隔符
'csv.ignore-parse-errors' ='true' -- 跳过脏数据
);
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic lines
java,java,flink
select
word,count(1) as num
from
lines,
lateral table(explode(split(line,','))) t(word) --hive中是lateral view
group by
word;
2.9 checkpoint
2.9.1 编写sql文件
1.vim word_count.sql
-- 1、创建source表
CREATE TABLE lines (
line STRING
) WITH (
'connector' = 'kafka',
'topic' = 'lines', -- 指定topic
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表
'properties.group.id' = 'testGroup', -- 指定消费者组
'scan.startup.mode' = 'earliest-offset', -- 指定读取数据的位置
'format' = 'csv', -- 指定数据的格式
'csv.field-delimiter' = '|' ,-- 指定分隔符
'csv.ignore-parse-errors' ='true' -- 跳过脏数据
);
-- 创建sink表
CREATE TABLE print_table (
word STRING,
num BIGINT
) WITH (
'connector' = 'print'
);
-- 加载hive函数
LOAD MODULE hive WITH ('hive-version' = '3.1.2');
-- 执行sql
insert into print_table
select
word,count(1) as num
from
lines,
lateral table(explode(split(line,','))) t(word)
group by
word;
2.9.2第一次提交
sql-client.sh -f word_count.sql
2.9.3 任务失败或者重启
1.基于之前的checkpoint重启任务
2.在inert into 语句的前面增加
SET 'execution.savepoint.path' = 'hdfs://master:9000/flink/checkpoint/d915e6278f156a9278156e67105f914e/chk-36';
3.重新提交
sql-client.sh -f word_count.sql
2.10 多次使用同一张表
1.编写sql文件
CREATE TABLE students_csv (
id STRING,
name STRING,
age INT,
sex STRING,
clazz STRING
) WITH (
'connector' = 'kafka',
'topic' = 'students', -- 指定topic
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表
'properties.group.id' = 'testGroup', -- 指定消费者组
'scan.startup.mode' = 'earliest-offset', -- 指定读取数据的位置
'format' = 'csv', -- 指定数据的格式
'csv.field-delimiter' = ',' ,-- 指定分隔符
'csv.ignore-parse-errors' ='true' -- 跳过脏数据
);
-- 创建sink表
CREATE TABLE clazz_num (
clazz STRING,
num BIGINT
) WITH (
'connector' = 'print'
);
CREATE TABLE sex_num (
sex STRING,
num BIGINT
) WITH (
'connector' = 'print'
);
-- 执行一组sql,如果多个sql中使用了同一张表,flink只会读取一次
EXECUTE STATEMENT SET
BEGIN
insert into clazz_num
select
clazz,
count(1) as num
from
students_csv
group by
clazz;
insert into sex_num
select
sex,
count(1) as num
from
students_csv
group by
sex;
END;
2.将查询或者插入的语句放在 EXECUTE STATEMENT SET里面
2.11 反压
2.11.1 测试反压
-- 创建datagen source表
CREATE TABLE words_datagen (
word STRING
) WITH (
'connector' = 'datagen',
'rows-per-second'='50000', -- 指定每秒生成的数据量
'fields.word.length'='5'
);
CREATE TABLE blackhole_table (
word STRING,
num BIGINT
) WITH (
'connector' = 'blackhole'
);
-- 反压发生情况
--1、单词太多,状态太大导致反压
insert into blackhole_table
select
word,
count(1)as num
from
words_datagen /*+ OPTIONS('fields.word.length'='6') */
group by
word;
--2、数据量太大导致反压
insert into blackhole_table
select
word,
count(1)as num
from
words_datagen /*+ OPTIONS('fields.word.length'='5','rows-per-second'='400000') */
group by
word;
2.11.2 解决反压
1.增加资源
-- 1、增加Taskmanager的内存
-- 启动汲取设置tm的内存
yarn-session.sh -tm 6G -d
-- 2、增加并行度
SET 'parallelism.default' = '8';
2.预聚合
-- 开启微批处理
set 'table.exec.mini-batch.enabled' ='true';
set 'table.exec.mini-batch.allow-latency' = '5 s';
set 'table.exec.mini-batch.size' ='100000';
-- 开启预聚合
set 'table.optimizer.agg-phase-strategy' ='TWO_PHASE';