万方数据库爬虫简单开发(自用)(一)
使用Python爬虫实现万方数据库论文的搜索并获取信息
后续会逐步探索更新万方,谷歌学术的爬虫写法
1.获取url
python
driver = webdriver.Chrome() #加载驱动
driver.get('https://www.wanfangdata.com.cn/')2.输入关键词
python
wait = WebDriverWait(driver, 10)
search_box = wait.until(EC.presence_of_element_located((By.ID, 'search-input'))) #等待搜索框加载完成注意这里的EC是导入的包起的别名
python
from selenium.webdriver.support import expected_conditions as EC
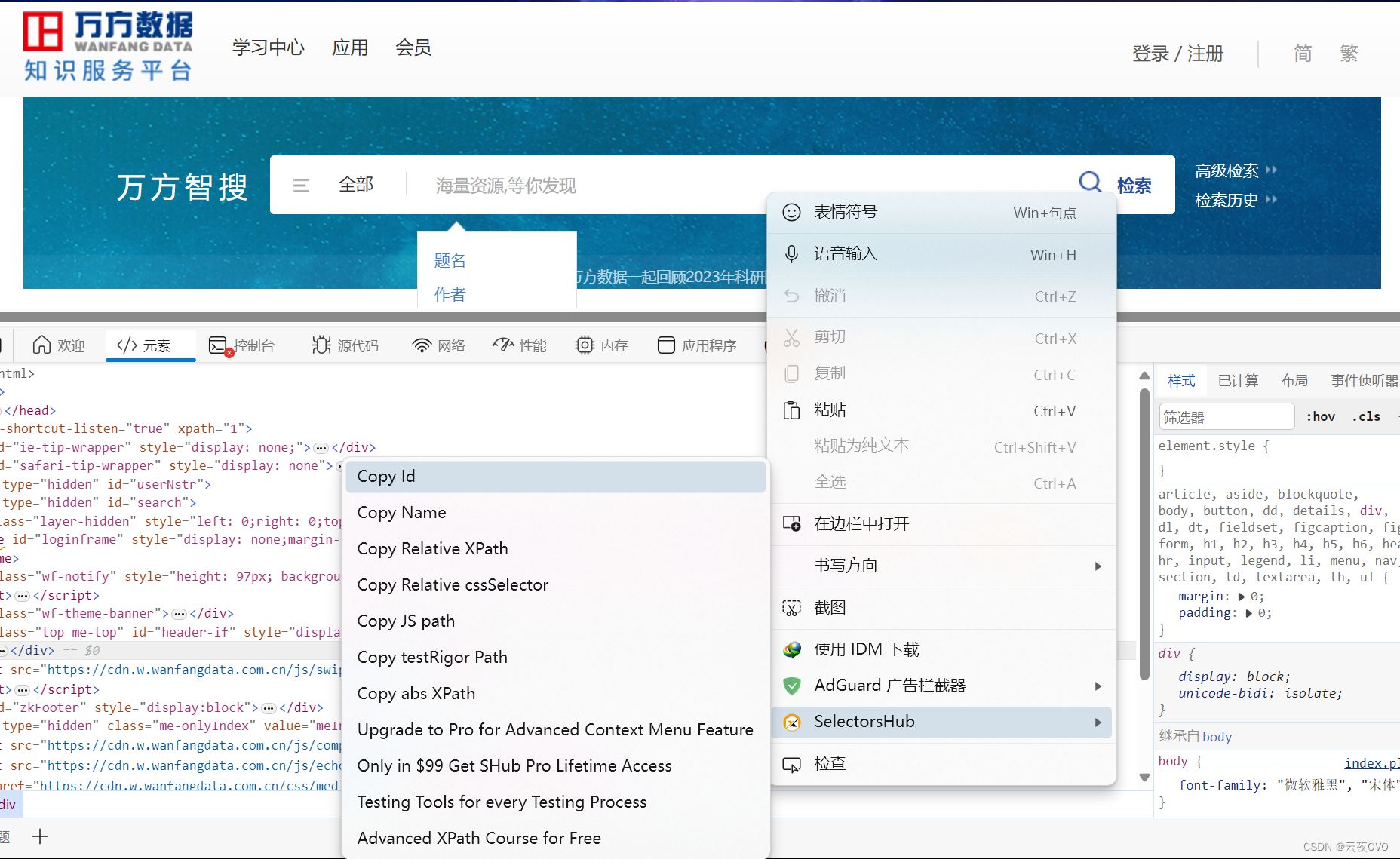
先获取搜索框的id,在搜索框上右键->selectorsHub->copy id.selectorsHub是一个很好用的edge浏览器扩展,功能丰富,直接在edge扩展商店搜索即可。
python
# 输入搜索关键词
search_box.send_keys(keyword)
# 模拟回车按钮
search_box.send_keys(Keys.RETURN)
time.sleep(5)
windows = driver.window_handles
# 切换到当前最新打开的窗口
driver.switch_to.window(windows[-1])driver.switch_to.window(windows-1)这句话是为了保证后面的BeautifulSoup获取到的信息来自当前页面而不是网站首页。
3.使用BeautifulSoup解析
python
content = driver.page_source.encode('utf-8')
soup = BeautifulSoup(content, 'lxml')4.获取文章标题信息
这里打开F12并分析页面结构:
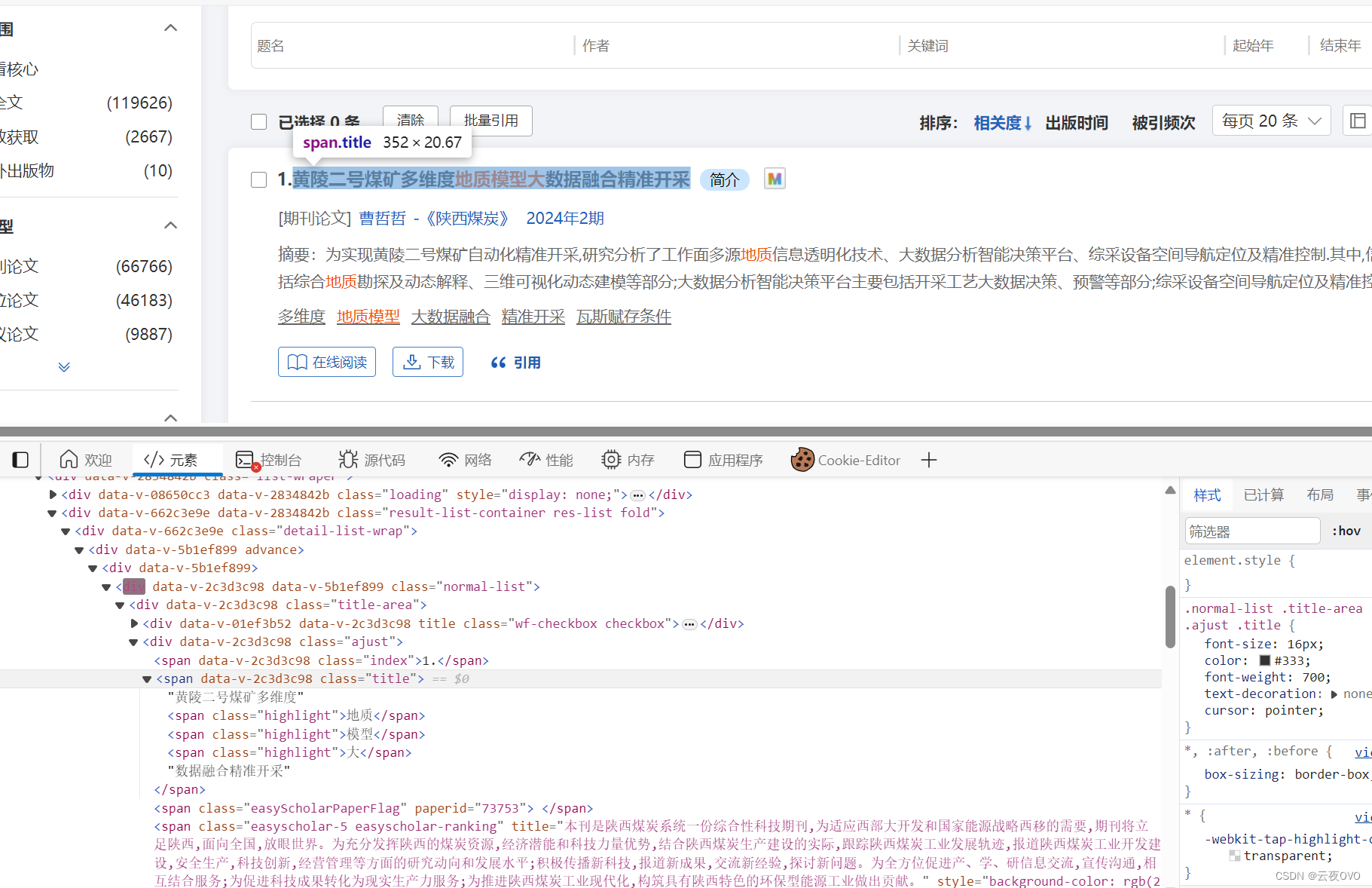
可以看到文章标题在class='adjust'下的span标签里边。
python
titles_bf=soup.find_all('span',{'class':'title'})
titles=BeautifulSoup(str(titles_bf),'lxml')
papers=titles.get_text().strip().split(',')
for paper in papers:
print(paper)这样我们就获取到文章的标题信息了。各位可以根据自己的需要再稍作修改即可。