BPE(Byte-Pair Encoding)算法
【西湖大学 张岳老师|自然语言处理在线课程 第十六章 - 4节】BPE(Byte-Pair Encoding)编码
如果有一个字符串aabaadaab,对其执行BPE算法
因为字符对aa出现频率最高,因此将其替换为码Z,这时原字符串变为ZbZdZb
此时字符对Zb出现频率最高,将其替换为码Y,此时原字符串变为YZdY
此时字符串中所有字符对频率都一样,都是一次。

利用BPE算法做子词切分需要两个步骤:
- 利用一个大的corpus建立一个子词表(subword vocabulary)以及字节对(token pairs)。
- 利用这个子词表和字节对来对新的语料进行子词切分。
首先是第一个任务:

这里首先子词表中应该包含所有的单个字符,随后我们在corpus中寻找出现频率最高的subword pair,这里是st出现了3+4+1=8次。
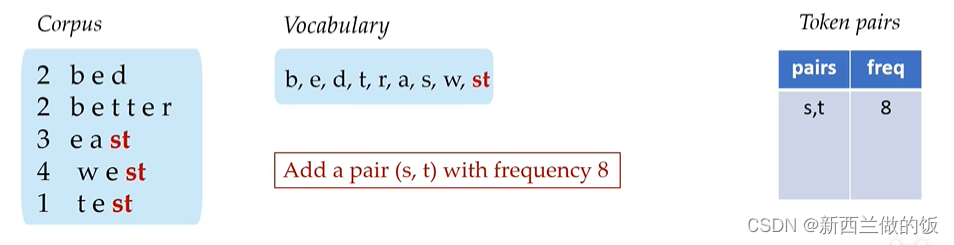
将s,t这个subword pair计入token pair表格中,并将他们组合后添加到子词表中,再次寻找出现频率最高的子词对。

同上,e,st为出现频率最高的subword pair,继续添加出现频率最高的子词对。

在添加过be这个子词对后,剩下在corpus的子词对中的子词频率都是一次,因此结束运算。
我们将subword pair表按照频率降序排序,随后对新词按照表格中频率由高到低进行分词。
如果我们对best这个词进行子词切分:
- 首先得到b,e,s,t四个子词,接着在token pair表格中进行匹配,发现s,t的子词对组合频率最高,因此将其合并。
- 得到了b,e,st这三个子词,我们继续在token pair进行匹配,发现e,st的子词对组合频率最高,因此将其合并。
- 得到了b,est这两个子词,随后token pair中没有可以匹配的对象,切分完成。
为了能够还原子词,我们在b后加两个@@,因此best被切分为b@@ + est这两个子词。每当我们还原时,遇到一个以@@结尾的子词,我们将其与后面的子词合并,并去掉@@符号,最终子词序列中没有@@符号为止,即还原了原词序列。
利用subword-nmt实现bpe算法
使用pip进行安装:pip install subword-nmt
python
:~/nlp/token$ subword-nmt learn-bpe -s 32000 < en.tc > en.cds &
:~/nlp/token$ subword-nmt learn-bpe -s 32000 < zh.tok > zh.cds &-s后是学习的词数量,en.tc、zh.tok分别为上一节处理后的英文、中文文本,en.cds、zh.cds是输出文件。
查看学习到的zh.cds文件:
 之后我们可以用apply-bpe利用规则文件对corpus进行切分:
之后我们可以用apply-bpe利用规则文件对corpus进行切分:
python
:~/nlp/token$ subword-nmt apply-bpe -c zh.cds < zh.tok > zh.bpe运行后我们查看zh.bpe文件:

我们可以看到3377被拆成了33@,77以及横行被拆成了横@行,我们统计拆分前后的词表中词的数量:
python
#vcb.py
#encoding: utf-8
import sys
def count(srcf):
vcb={}#创建一个空字典
with open(srcf,"rb") as frd:
for line in frd:
tmp = line.strip()
if tmp:
for word in tmp.decode("utf-8").split():#利用split()将每行的词提取出来
vcb[word] = vcb.get(word,0) + 1#字典的get方法,如果vcb[word]存在就取值,若不存在返回0
#统计每个子词出现的频次
return vcb
if __name__=="__main__":
print(len(count(*sys.argv[1:])))#len为出现的不同子词的个数在命令行输入:
python
:~/nlp/token$ python vcb.py zh.bpe
43050
:~/nlp/token$ python vcb.py zh.tok
630306可以看到执行bpe算法后,词表大小被大大减少。
进一步缩减bpe算法产生的词表
在zh.bpe文件中,会有很多低频的、只出现一次或两次的词,例如 "非洲统一组织" ,若拆成 "非洲"、"统一"、"组织",则这三个词每个词的频率都会高于拆之前的词。
因此我们需要统计每个子词的频率来决定阈值:
python
:~/nlp/token$ subword-nmt get-vocab < zh.bpe > zh.vcb
:~/nlp/token$ tail zh.vcb
不伦@@ 1
® 1
‹ 1
ƒ 1
布拉柴@@ 1
別@@ 1
煦 1
檀 1
皙 1
堺 1查看文件的尾部,发现很多子词的频率为1,只出现过一次。
python
:~/nlp/token$ subword-nmt apply-bpe -c zh.cds --vocabulary zh.vcb --vocabulary-threshold 8 < zh.tok > zh.bpe对词表设置阈值为8后,重新得到新的bpe算法处理后的文件,再次统计词表的长度:
python
:~/nlp/token$ python vcb.py zh.bpe
42590可以看到,由于词频低于8的词都被过滤掉,词表被进一步缩减。
unigram算法
利用sentencepiece运行unigram算法
sentencepiece安装:pip install sentencepiece github-sentencepiece
unigram算法总结-huggingface
unigram算法原文
在终端输入以下命令:
python
:~/nlp/normalize$ spm_train --input=uni.zh --model_prefix=unizh --vocab_size=32000 ---character_coverage --model_type=unigram --input_sentence_size=1048576 --shuffle_input_sentence --train_extremely_large_corpus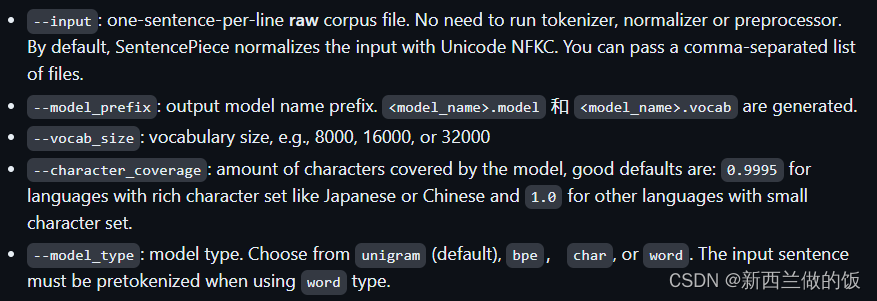
如图所示的参数说明:
--input:输入数据是原始的语料文件,因此我们选择最初的uni.zh未经过处理的文件。
--model_prefix:输出训练后模型文件的前缀名,后缀为.model
--vocab_size:输入模型训练的词数
--character_coverage:我们选用的是联合国的中文语料,推荐中文日文等丰富字(母)语言设置为0.9995,其他设置为1。代表字母的覆盖率,默认为0.9995。
--model_type:指定训练模型的类型,我们欲使用sentencepiece完成unigram算法,因此参数设置为默认(unigram)。
另外,我们添加了其他的帮助提升训练效果的参数:
--input_sentence_size:限制了训练数据中加载的最大句长
--shuffle_input_sentence:将输入每行句子先做乱序处理,再输入训练模型
--train_extremely_large_corpus:针对输入是很大的语料规模做优化,默认为false,但只要在命令行出现就自动设置为true,未出现则为默认值false。
运行完成后,我们查看unizh.vocab文件,存储的是所有的子词以及他们出现概率的负对数:

我们利用训练完成的model进行子词切分,在命令行输入:
python
:~/nlp/normalize$ spm_encode --model=unizh.model < uni.zh > zh.spm传入最初原始的raw text,利用训练好的模型得到分词后的文件,查看zh.spm文件:

这是对原始语料进行处理后的分词文件,可以看到分词后的结果。利用spm_decode可以还原原始数据:
python
:~/nlp/normalize$ spm_decode --model=unizh.model < zh.spm > zh.despm