解锁LLMs的"思考"能力:Chain-of-Thought(CoT) 技术推动复杂推理的新发展
1.简介
Chain-of-Thought(CoT)是一种改进的Prompt技术,目的在于提升大模型LLMs在复杂推理任务上的表现,如算术推理(arithmetic reasoning)、常识推理(commonsense reasoning)、符号推理(symbolic reasoning)。
-
起源:CoT技术的概念是在Google的论文"Chain-of-Thought Prompting Elicits Reasoning in Large Language Models"中被首次提出。 -
现状:随着大语言模型(LLM)的发展,CoT技术已成为提高LLM在复杂推理任务中性能的重要手段。通过特定的提示(prompt)或训练策略,可以引导模型生成详细的推理过程,从而提高模型的准确性和可解释性。 -
定义:CoT技术指的是一种推理过程,其中模型在生成最终答案之前,先逐步推导出一系列的中间步骤或子目标。这些中间步骤构成了一个"思维链",最终引导模型得到正确的结果。 -
核心思想:模仿人类的推理过程,即人们往往在解决问题时不是直接得出答案,而是通过一系列的思考、分析和推理步骤。 -
特点与优势
- 中间步骤:模型在生成最终答案之前,会先产生一系列的中间推理步骤。
- 可解释性:由于CoT提供了推理过程的可见性,因此它有助于提高模型决策的可解释性。
- 逻辑推理:CoT可以帮助模型进行复杂的逻辑推理,尤其是在需要组合多个事实或信息片段的问题上。
- 上下文利用:在CoT中,模型可以利用上下文信息,通过逐步推理来解决问题,而不是仅仅依赖于直接的答案。
-
拓展技术自动思维链(Auto-CoT):这是一种更高级别的CoT技术,通过简单的提示,促使模型自我思考,自动展示从设置方程到解方程的整个推理过程。这种技术可以在保证每个思维链正确性的同时,实现更精简的提示词设计。 -
思路
ICL的思路是在新测试样本中加入示例(demonstration)来重构prompt。与ICL(In-Context Learning)有所不同,CoT对每个demonstration,会使用中间推理过程(intermediate reasoning steps)来重新构造demonstration,使模型在对新样本预测时,先生成中间推理的思维链,再生成结果,目的是提升LLM在新样本中的表现。
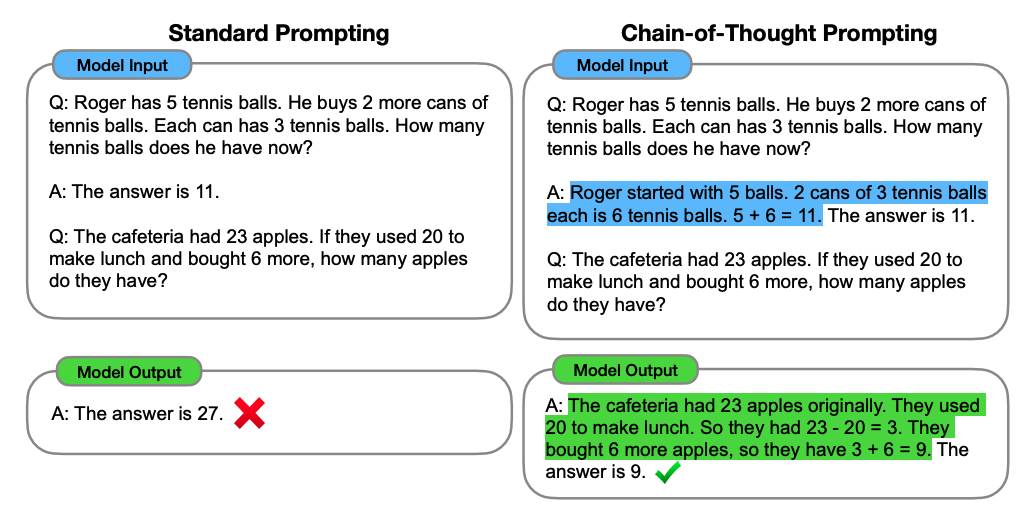
2.CoT方法
一般来说CoT会分为两种:基于人工示例标注的Few-shot CoT和无人工示例标注的Zero-shot CoT。下面将逐一介绍。
1.1 Few-shot CoT
假设基于ICL的测试样本输入表示为\
1.1.1 CoT Prompt设计
我们知道了加入CoT的示例后,能提升LLM的表现。那么我们应该如何构造或使用CoT?
投票式CoT
《Self-Consistency Improves Chain of Thought Reasoning in Language Models》
论文基于一个思想:一个复杂的推理任务,其可以有多种推理路径(即解题思路),最终都能够得到正确的答案。故Self-Consistency在解码过程中,抛弃了greedy decoding的策略,而是使用采样的方式,选择生成不同的推理路径,每个路径对应一个最终答案。
具体做法为:
- 对于单一的测试数据,通过多次的解码采样,会生成多条推理路径和答案。
- 基于投票的策略,选择最一致的答案。
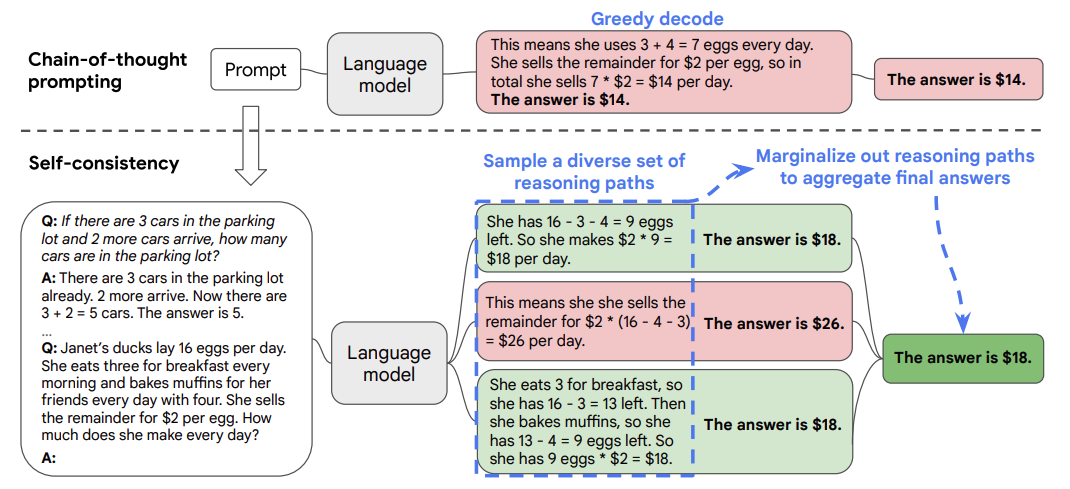
实验表明,对于同一问题生成更多的推理链以供投票往往能取得更好的效果。当推理链数量足够多时,这种方法效果能够胜过使用greedy decoding的CoT方法。
《On the advance of making language models better reasoners》
论文在Self-Consistency的基础上,进一步做了优化。
- 1.Diverse Prompts
- 对于每个测试问题,构造了M_1种不同的prompt(即由不同demonstration构造的prompt)
- 对于每种不同的prompt,让LLM生成M_2条推理路径。
- 则对于同一个测试问题,共生成了M_1\*M_2条结果
- 2.Verifier
- 训练了一个Verifier,用于判断当前推理路径得出的答案正确与否。
- 关于样本构建,使用LLM生成的推理路径和答案,与grandtruth进行对比,一致的即视为正样本,否则负样本。
- 3.Vote
- 训练好Verifier后,对与一个测试问题与LLM生成的多条推理路径,Verifier进行二元判别
- 结合判别结果和投票结果,得出模型的最终预测。
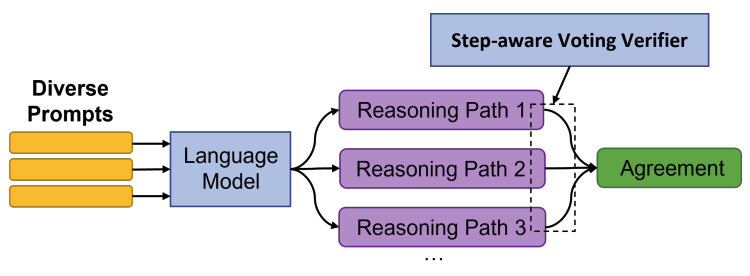
实验结果显示,本论文的方法相对基于Greedy Decode和Self-Consistency能得到更优的效果。
使用复杂的CoT
《Complexity-based prompting for multi-step reasoning》
面对这么多可选的CoT,简单的CoT示例和复杂的CoT示例,对新的样本推理结果会不会产生影响?答案是Yes。
论文探讨了一个问题,在包含简单推理路径的demonstrations和复杂推理路径的demonstrations下,哪个效果会表现较好?(这里的简单和复杂是指 推理链/推理步骤的长度)
本论文继承了Self-Consistency的思想,具体方法:
- 1.对于同一个测试问题,使用功能LLM(GPT-3)生成N条不同的推理链+答案;
- 2.对于生成的推理链+答案,按照推理链的长度进行倒序排序;
- 3.保留TopK条推理链+答案,并使用投票的方式,选取最终预测。
实验结果表明,本论文的方法效果优于以下方法: (1)人工构建Cot、(2)random Cot、(2)Complex CoT(数据集中最长的多个思维链作为demonstrations)。

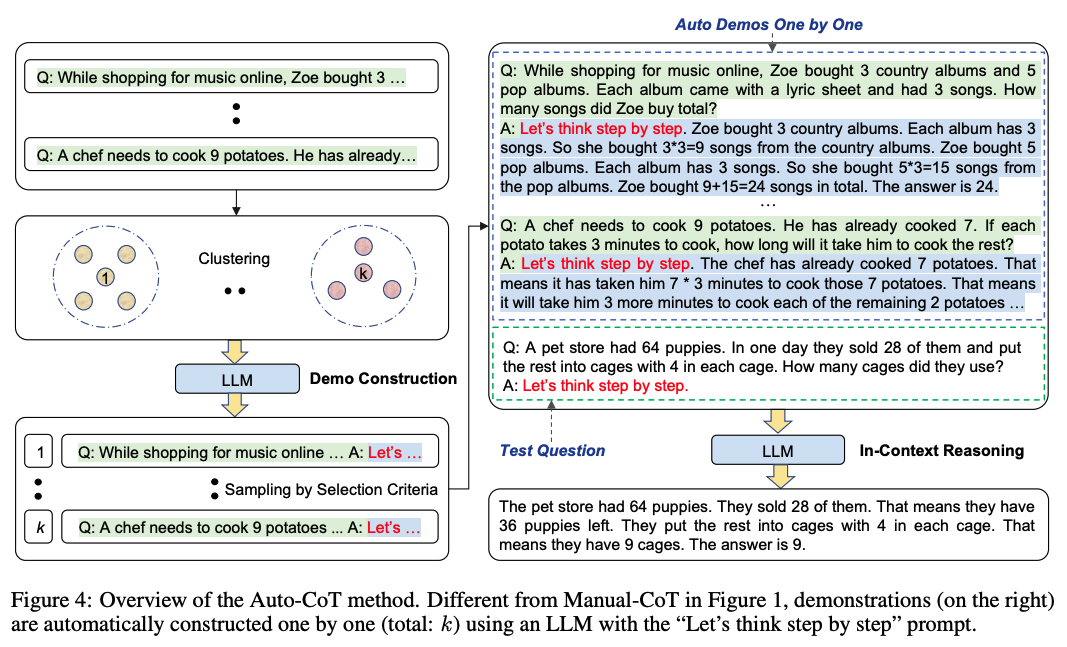
自动构建CoT
《Automatic chain of thought prompting in large language models》
上面提到的方法是基于人工构造CoT,那我们能否让模型自己来生成CoT?本论文就提供了这样一种自动生成CoT的思路。
本论文提到的Manual-CoT,可以等同于Few-shot CoT来理解。
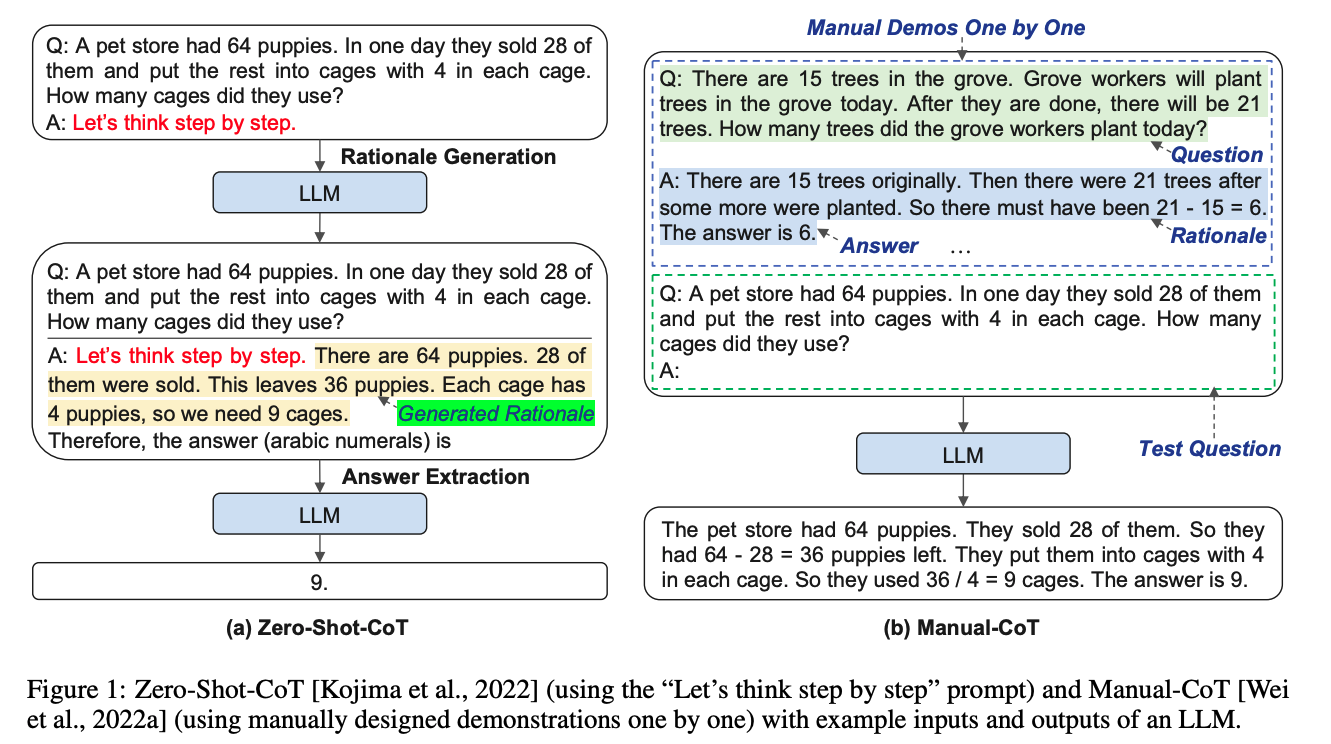
由于Zero-Shot-CoT方法存在不稳定性,而Manual-CoT方法需要大量人工成本投入。作者提出了一种基于Auto-CoT的方法,自动构建包含问题和推理链的说明样例(demonstrations)。
整个过程分了两个阶段:
1.question cluster: 目的是将数据集中的question划分到不同簇中。
- 使用Sentence-Bert计算每个question的向量表示;
- 使用k-means方法将question记性簇划分;
- 最后对每个簇中的question,根据距离中心点距离,升序排序。
2.demostration sampling: 目的是从每个簇中选取一个代表性的question,基于LLMs,使用Zero-Shot-CoT生成推理链。
-
对于每一个簇i里的每一个问题q^{(i)}_j,使用Zero-Shot-CoT的方法,将\[Q:q^_j,A:\[P\]\](其中\[P\]表示"Let's think step by step")输入到LLMs,LLMs生成该问题的推理链r^{(i)}_j和答案a^_j;
-
若问题q^{(i)}_j不超过60个tokens,且推理链r^_j不超过5个推理步骤,则将问题+推理链+答案,加入到demostrations列表中:\[Q:q^{(i)}_j,A:r^_j。a\^{(i)}_j\];
-
遍历完所有簇,将得到k个demostrations,将其拼接上测试question,构造成新的Prompt,输入LLMs便可得到生成结果。
值得一提的是,Auto-CoT在多个开源推理任务的数据集上,效果与Manual-CoT相当,甚至某些任务表现得更好。
CoT中示例顺序的影响
《Chain of thought prompting elicits reasoning in large language models》
尽管CoT是ICL的一种特殊形式,但是与ICL有所不同的是,CoT中demonstrations的排序对其在新测试样本中的生成结果影响较小,论文对demonstrations进行重排序,在多数推理任务上仅导致小于2%的性能变化。(demonstrations顺序对ICL影响较大)
1.1.2 CoT的增强策略
COT(Chain-of-Thought)的增强策略主要包括以下几种:
-
结合验证和细化:
- 思维链推理过程中可能会出现误差,产生错误的推理步骤。为了减少这种现象,可以结合验证来获取反馈,并根据反馈改进推理过程。这与人类的反思过程类似。
- 例如,VerifyCoT设计了一种自然程序(NaturalProgram),允许模型产生精确的推理步骤,每个后续步骤都严格基于之前的步骤。
-
问题分解:
- COT通过将多步骤推理问题分解成多个中间步骤,分配给更多的计算量,生成更多的token,再进行求解。这种策略有助于更好地推理问题的每个部分。
-
利用外部知识:
- 在某些情况下,为了促进知识密集型任务,可以结合外部知识对不确定的例子进行重新推理,从而减少再分析中的事实错误。
-
投票排序:
- DIVERSE等策略利用投票机制消除错误答案,然后对每个推理步骤进行独立的细粒度验证,从而提高推理的准确性。
-
提高效率:
- 通过优化模型结构和算法,减少不必要的计算量,提高推理的效率。
-
偏差增强一致性训练(BCT):
- 针对COT可能产生的系统性偏见问题,引入了BCT无监督微调方案。这种方法可以训练模型在包含和不包含偏见特征的提示下给出一致的推理,减少偏见推理。实验表明,BCT可以显著降低偏差推理率,提高模型解释的可信度。
-
Zero-shot-COT:
- 引入了一种简单的零样本提示方法,通过在问题的结尾附加"Let's think step by step"等词语,使大语言模型能够生成一个回答问题的思维链。这种方法无需额外的训练数据,可以直接应用于各种推理任务。
1.2 Zero-shot CoT
与Few-shot CoT不同,Zero-shot CoT并不需要人为构造demonstrations,只需要在prompt中加入一个特定的指令,即可驱动LLMs以思维链的方式生成结果。
当然这种不需要人工构造demonstrations的方式,效果相对Few-shot CoT会表现稍微差一点点。但是相对Zero-shot和Few-shot的方法而言,Zero-shot CoT在复杂任务推理上却能带来巨大的效果提升。

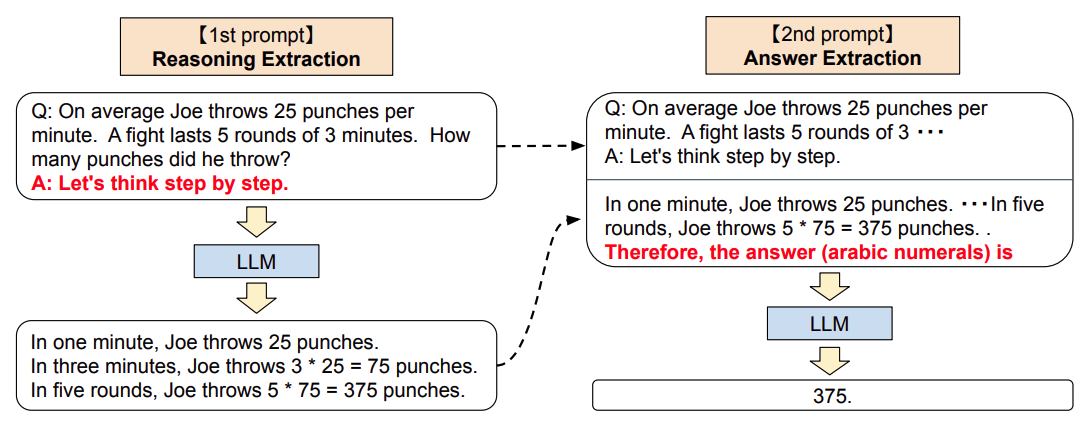
《Large language models are zero-shot reasoners》
论文首先提出了Zero-shot CoT的方法,整个流程包含两部分:
- 1.Reasoning Extraction
- 使用一个特定的"reasoning" prompt,是语言模型LLM生成原始问题的思维链,如"Let's think step by step."(让我们一步步来思考)
- 2.Answer Extraction
- 基于第一步的结果,添加一个"answer" prompt,要求LLM生成正确的结果。
- 这一个步骤中,LLM的输入格式为:quesiton + "reasoning" prompt + result(CoT) + "answer" prompt,输出为:result(answer)
值得一提的是,论文同时发现了,当模型LLM变得越来越大,对于使用Zero-shot的结果带来的增益不大,但是对使用Zero-shot CoT的结果带来的增益较大。
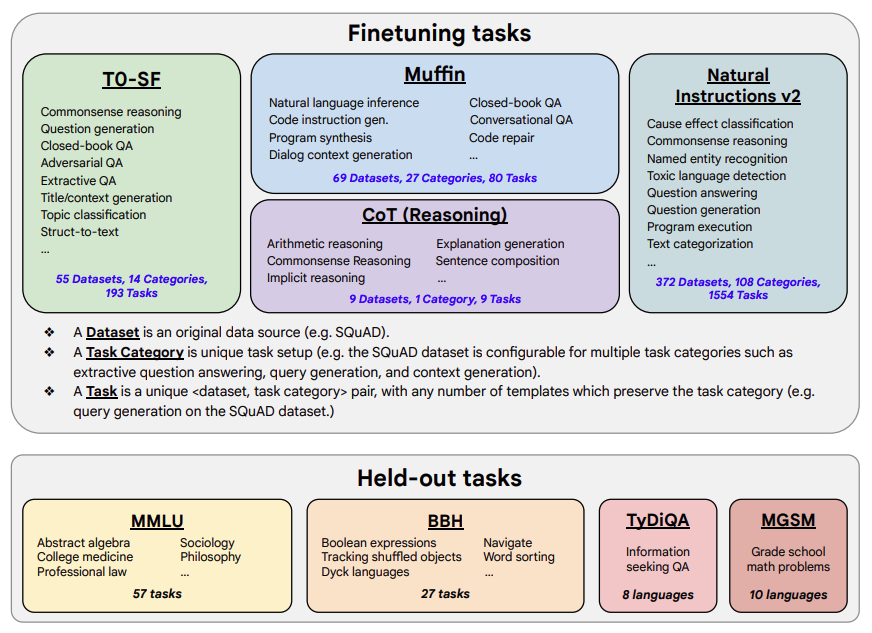
《Scaling Instruction-Finetuned Language Models》
既然在上一篇论文中,已经发现了LLM存在Zero-shot CoT的能力,那如果事先对LLM进行基于CoT的instruction tuning,那模型使用Zero-shot CoT方式在对unseen样本进行预测时,效果会不会更好?本论文给出了肯定的答案。
论文探索了以下可能影响LLM在unseen task上表现的因素:
- 1.任务数量
- 2.模型大小
- 3.指令微调(instruction tuning)
论文微调数据集包含了1836种指令任务,473个数据集和146种任务类型构成,数据集中包含了9个人工标注的CoT数据集。同时保留一个没出现过的held-out数据集作为模型评估数据集。

使用的模型是PaLM,而经过instruction tuning的模型,称为FlanPaLM(Finetuned Language PaLM)。
得到了以下结论:
- 1.增加微调任务数量,可以提高LLM表现。但任务数量超过一定值后,不管模型尺寸是否增大,受益都不大。推测原因有:
- (1) 额外的任务多样化不足,没有为LLM提供新的知识;
- (2) 多任务指令微调只是更好地激发了模型从预训练任务中学习到知识的表达能力,而微调任务超过一定值后,对表达能力没有太大帮助。
- 2.微调和未微调的PaLM,从8B增大到540B,在unseen任务上效果越来越好;
- 3.微调数据与CoT数据的关系
- (1) 微调数据中删除CoT数据,会降低PaLM的推理能力
- (2) 微调数据包含CoT数据,会全面提高所有评测任务的表现
3.总结
对于大模型LLM涌现的CoT能力,业界目前的共识是:当模型参数超过100B后,在复杂推理任务中使用CoT是能带来增益的;而当模型小于这个尺寸,CoT并不会带来效果增益。
还记得在Pretrain+Fine-tuning时代下,对于复杂数学推理任务,如MultiArith、GSM8K下,效果还是不太理想,而短短几年时间,LLM+CoT的模式已经大大提升了该领域的解决能力。随着LLM的继续发展,未来必定会发现更多LLM隐藏的能力和使用方法,让我们拭目以待。
4.Reference
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Large language models are zero-shot reasoners
Scaling Instruction-Finetuned Language Models
Self-Consistency Improves Chain of Thought Reasoning in Language Models
On the advance of making language models better reasoners
Chain of thought prompting elicits reasoning in large language models
Complexity-based prompting for multi-step reasoning
Chain of thought prompting elicits reasoning in large language models
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。