OpenCV单词轮廓检测
-
- [0. 前言](#0. 前言)
- [1. 策略分析](#1. 策略分析)
- [2. 检测字符轮廓](#2. 检测字符轮廓)
- [3. 检测单词轮廓](#3. 检测单词轮廓)
- 相关链接
0. 前言
在根据文档图像执行单词转录时,通常第一步是识别图像中单词的位置。我们可以使用两种不同的方法识别图像中的单词:
- 使用
CRAFT、EAST等深度学习技术 - 使用基于
OpenCV的技术
在本节中,我们将学习如何在不利用深度学习的情况下识别机器打印的单词。由于打印单词的背景和前景之间的对比度很高,因此不需要像YOLO之类的模型来识别单个单词的位置,在这种情况下,使用 OpenCV 可以在计算资源非常有限的情况下获得解决方案,唯一的缺点是准确率可能并非 100%,准确率取决于扫描图像的质量,如果扫描图像非常清晰,则准确率可以接近 100%。
1. 策略分析
利用 OpenCV 识别图像中的单词策略如下所示:
- 将图像转换为灰度图像
- 放大图像中的内容,膨胀操作可以将黑色像素扩散到相邻区域,因此将同一单词的字符连接起来,有助于确保同一个单词的字符之间的连接;需要注意的是,不能过度膨胀,以至于将属于不同相邻单词的字符也连接起来
- 连接字符后,利用
cv2.findContours在每个单词周围绘制一个边界框
2. 检测字符轮廓
(1) 加载图像,并查看图像样本:
python
import cv2, numpy as np
img = cv2.imread('1.png')
img1 = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
import matplotlib.pyplot as plt,cv2
plt.imshow(img1)
plt.show()
(2) 将输入图像转换为灰度图像:
python
img_gray = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)(3) 随机裁剪原始图像:
python
crop = img_gray[250:300,50:200]
plt.imshow(crop,cmap='gray')
plt.show()
(5) 二值化输入灰度图像:
python
_img_gray = np.uint8(img_gray < 200)*255将小于 200 的像素的值置为 0,而像素强度大于 200 的值置为 255。
(6) 查找图像中的字符轮廓:
python
contours,hierarchy = cv2.findContours(_img_gray,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)使用 cv2.findContours 函数可以通过将一组连续的像素创建为对象的单个区域来查找轮廓。
(7) 将阈值图像转换为三通道图像,以便在字符周围绘制彩色边界框:
python
thresh1 = np.stack([_img_gray]*3,axis=2)(8) 创建空白图像,以便将 thresh1 中的相关内容复制到新图像中:
python
thresh2 = np.zeros((thresh1.shape[0],thresh1.shape[1]))(9) 获取轮廓并在轮廓所在的位置绘制一个矩形边界框,同时,将 thresh1 图像中与矩形边界框对应的内容复制到 thresh2 中:
python
for cnt in contours:
if cv2.contourArea(cnt)>0:
[x,y,w,h] = cv2.boundingRect(cnt)
if ((h>5) & (h<100)):
thresh2[y:(y+h),x:(x+w)] = thresh1[y:(y+h),x:(x+w),0].copy()
cv2.rectangle(thresh1,(x,y),(x+w,y+h),(255,0,0),2)在以上代码中,只获取面积大于 5 像素的轮廓,并且只获取边界框高度在 5 到 100 像素之间的那些轮廓,这样可以排除可能是噪声的较小边界框,并排除可能包含整个图像的大边界框。
(10) 绘制结果图像:
python
fig = plt.figure()
fig.set_size_inches(20,20)
plt.imshow(img1)
plt.show()
我们已经可以在字符周围绘制边界框,但是如果想在单词周围绘制框,则需要将单词中的像素组合成一个连续的单元。接下来,我们利用膨胀技术在单词周围绘制边界框。
3. 检测单词轮廓
(1) 检查图像 thresh2:
python
fig = plt.figure()
fig.set_size_inches(20,20)
plt.imshow(thresh2)
plt.show()
接下来,需要将不同字符的像素连接成一个集合,使一个连续的像素集合构成一个单词。使用膨胀函数 cv2.dilate,将白色像素扩散周围的像素中,扩散程度由核大小决定。如果核大小为 5,则白色区域的所有边界向外移动 5 个像素。
(2) 使用尺寸为 1x2 的核执行膨胀操作:
python
dilated = cv2.dilate(thresh2, np.ones((1,2),np.uint8), iterations=1)将核大小指定为 1x2 (np.ones((1,2),np.uint8)),以便相邻字符会出现交集,cv2.findContours 可以包含彼此接近的字符。但是,如果核大小过大,膨胀后的单词可能会有一些交集,导致一个边界框中包含多个单词。
(3) 获取膨胀图像的轮廓:
python
contours,hierarchy = cv2.findContours(np.uint8(dilated),cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)(5) 在原始图像上绘制膨胀后的图像轮廓:
python
for cnt in contours:
if cv2.contourArea(cnt)>5:
[x,y,w,h] = cv2.boundingRect(cnt)
if ((h>5) & (h<100)):
cv2.rectangle(img1,(x,y),(x+w,y+h),(255,0,0),2)(6) 绘制带有轮廓的原始图像:
python
fig = plt.figure()
fig.set_size_inches(20,20)
plt.imshow(img1)
plt.show()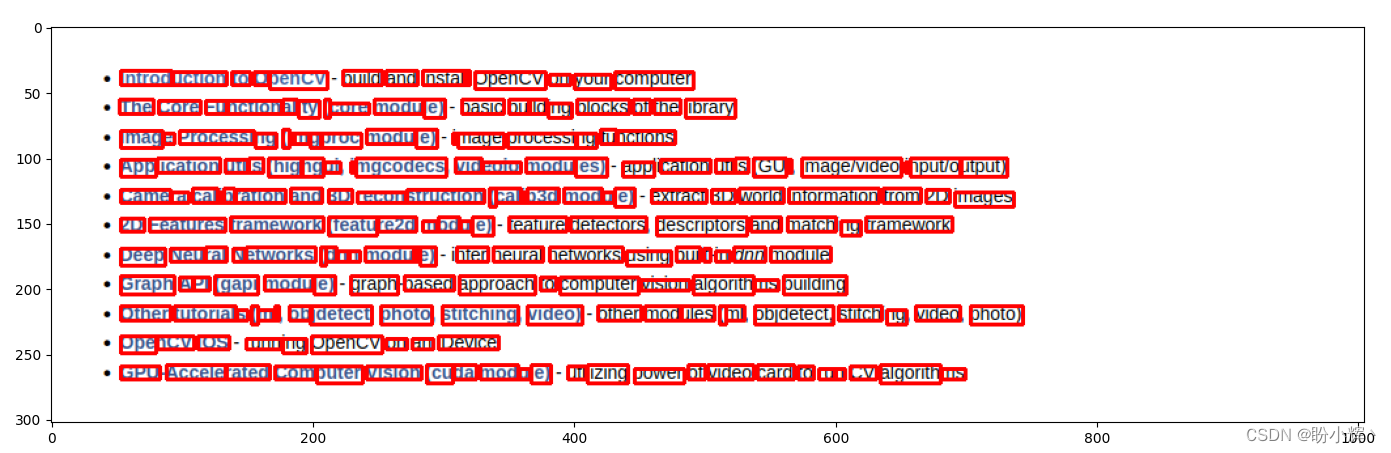
从上图中可以看出,我们获取了每个单词对应的边界框。本节的关键在于如何确定一组像素是否形成一个连通的单元,如果一组像素没有形成一个单元,使用膨胀进行处理,膨胀会扩散黑色像素,而侵蚀 (erode) 函数会扩散白色像素。