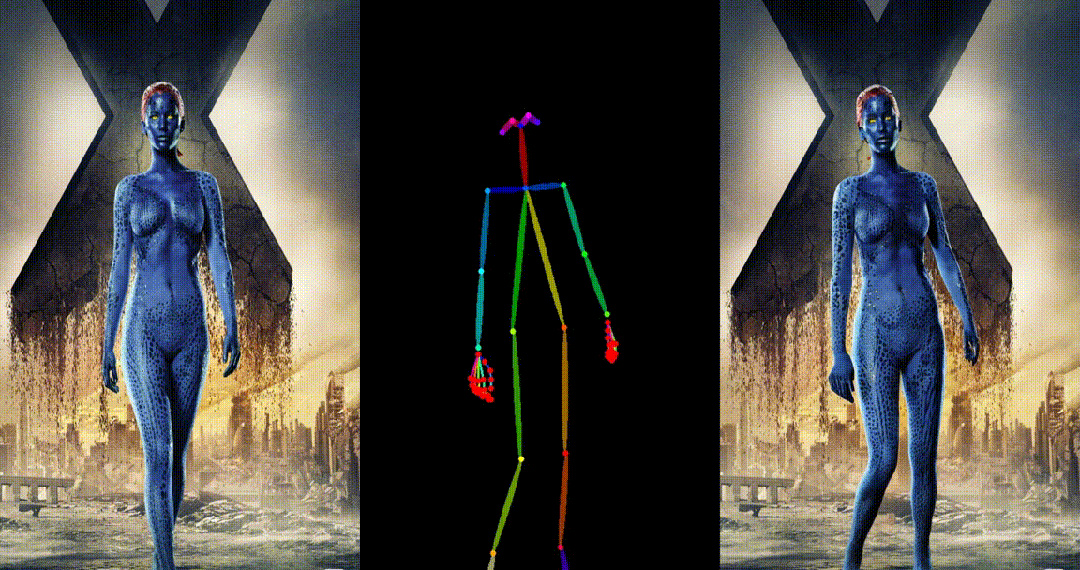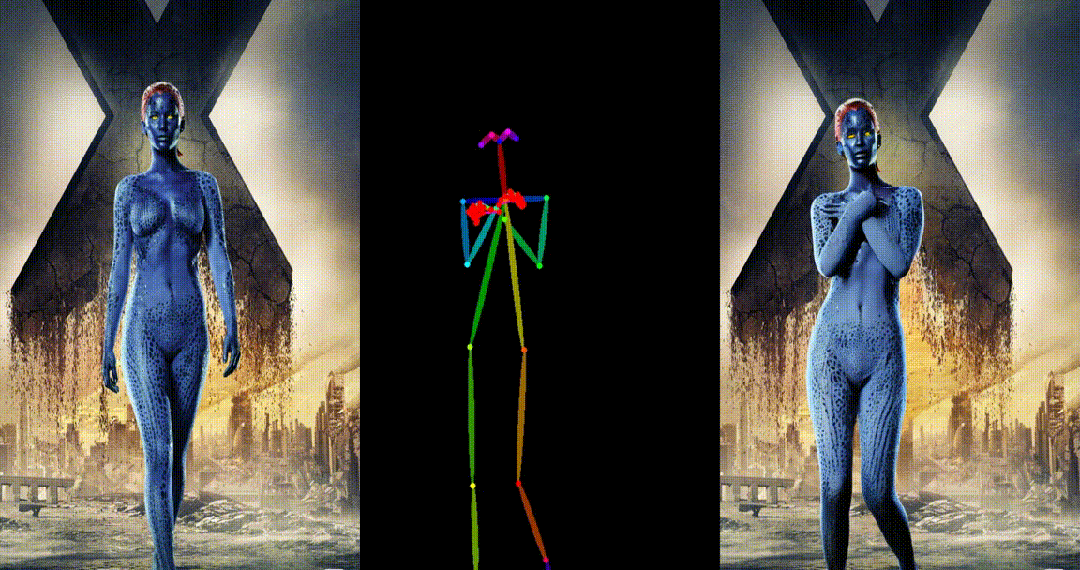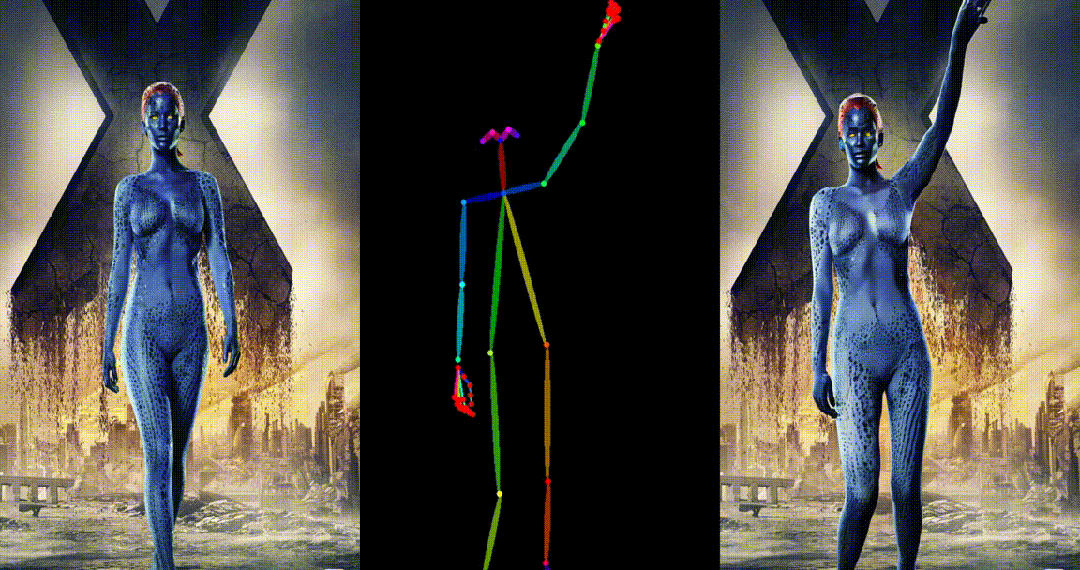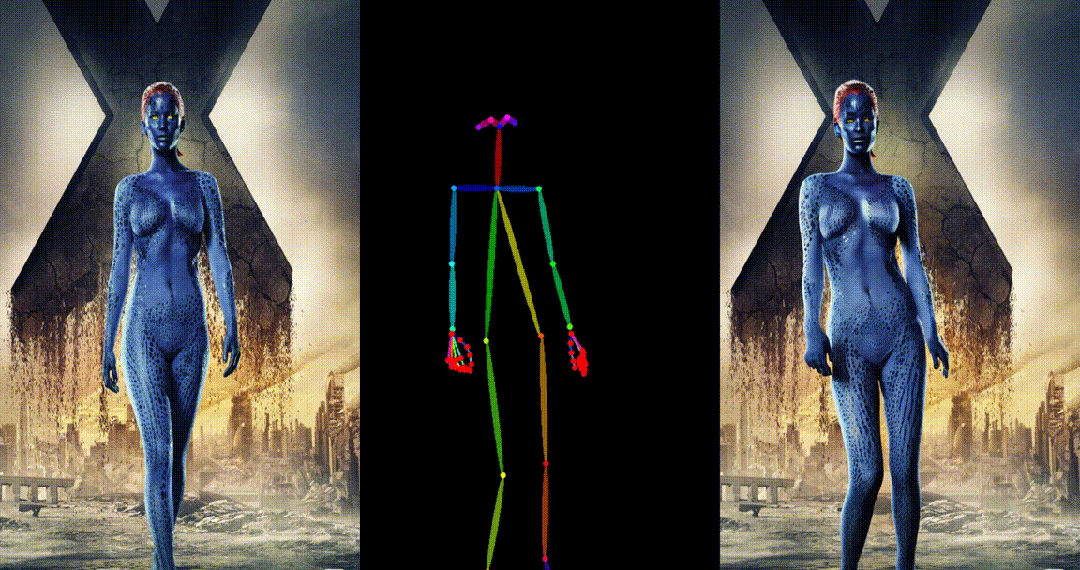节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学。
针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
合集:
人类跳舞视频生成是一项引人注目且具有挑战性的可控视频合成任务,旨在根据输入的参考图像和目标姿势序列生成高质量逼真的连续视频。随着视频生成技术的快速发展,特别是生成模型的迭代演化,跳舞视频生成任务取得了前所未有的进展,并展示了广泛的应用潜力。
现有的方法可以大致分为两组。第一组通常基于生成对抗网络(GAN),其利用中间的姿势引导表示来扭曲参考外观,并通过之前扭曲的目标生成合理的视频帧。然而,基于生成对抗网络的方法通常存在训练不稳定和泛化能力差的问题,导致明显的伪影和帧间抖动。
第二组则使用**扩散模型(Diffusion model)**来合成逼真的视频。这些方法兼具稳定训练和强大迁移能力的优势,相较于基于 GAN 的方法表现更好,典型方法如 Disco、MagicAnimate、Animate Anyone、Champ 等。
尽管基于扩散模型的方法取得了显著进展,但现有的方法仍存在两个限制:一是需要额外的参考网络(ReferenceNet)来编码参考图像特征并将其与 3D-UNet 的主干分支进行表观对齐,导致增加了训练难度和模型参数;二是它们通常采用时序 Transformer 来建模视频帧之间时序依赖关系,但 Transformer 的复杂度随生成的时间长度成二次方的计算关系,限制了生成视频的时序长度。典型方法只能生成 24 帧视频,限制了实际部署的可能性。尽管采用了时序重合的滑动窗口策略可以生成更长的视频,但团队作者发现这种方式容易导致片段重合连接处通常存在不流畅的转换和外貌不一致性的问题。
为了解决这些问题,来自华中科技大学、阿里巴巴、中国科学技术大学的研究团队提出了 UniAnimate 框架,以实现高效且长时间的人类视频生成。

方法简介
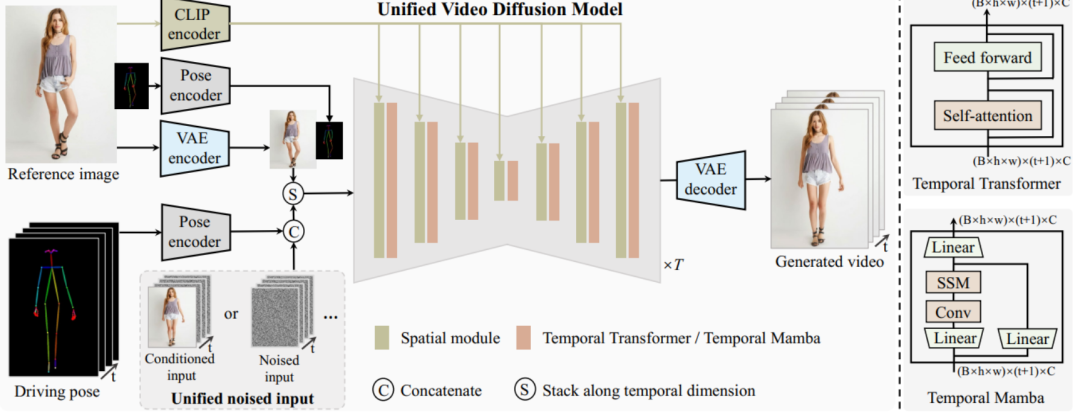
UniAnimate 框架首先将参考图像、姿势指导和噪声视频映射到特征空间中,然后利用**统一的视频扩散模型(Unified Video Diffusion Model)**同时处理参考图像与视频主干分支表观对齐和视频去噪任务,实现高效特征对齐和连贯的视频生成。
其次,研究团队还提出了一种统一的噪声输入,其支持随机噪声输入和基于第一帧的条件噪声输入,随机噪声输入可以配合参考图像和姿态序列生成一段视频,而基于第一帧的条件噪声输入(First Frame Conditioning)则以视频第一帧作为条件输入延续生成后续的视频。通过这种方式,推理时可以通过把前一个视频片段(segment)的最后一帧当作后一个片段的第一帧来进行生成,并以此类推在一个框架中实现长视频生成。
最后,为了进一步高效处理长序列,研究团队探索了基于状态空间模型(Mamba)的时间建模架构,作为原始的计算密集型时序 Transformer 的一种替代。实验发现基于时序 Mamba 的架构可以取得和时序 Transformer 类似的效果,但是需要的显存开销更小。
通过 UniAnimate 框架,用户可以生成高质量的时序连续人类跳舞视频。值得一提的是,通过多次使用 First Frame Conditioning 策略,可以生成持续一分钟的高清视频。与传统方法相比,UniAnimate 具有以下优势:
-
无需额外的参考网络:UniAnimate 框架通过统一的视频扩散模型,消除了对额外参考网络的依赖,降低了训练难度和模型参数的数量。
-
引入了参考图像的姿态图作为额外的参考条件,促进网络学习参考姿态和目标姿态之间的对应关系,实现良好的表观对齐。
-
统一框架内生成长序列视频:通过增加统一的噪声输入,UniAnimate 能够在一个框架内生成长时间的视频,不再受到传统方法的时间限制。
-
具备高度一致性:UniAnimate 框架通过迭代利用第一帧作为条件生成后续帧的策略,保证了生成视频的平滑过渡效果,使得视频在外观上更加一致和连贯。这一策略也使得用户可以生成多个视频片段,并选取生成结果好的片段的最后一帧作为下一个生成片段的第一帧,方便了用户与模型交互和按需调整生成结果。而利用之前时序重合的滑动窗口策略生成长视频,则无法进行分段选择,因为每一段视频在每一步扩散过程中都相互耦合。
以上这些特点使得 UniAnimate 框架在合成高质量、长时间的人类跳舞视频方面表现出色,为实现更广泛的应用提供了新的可能性。
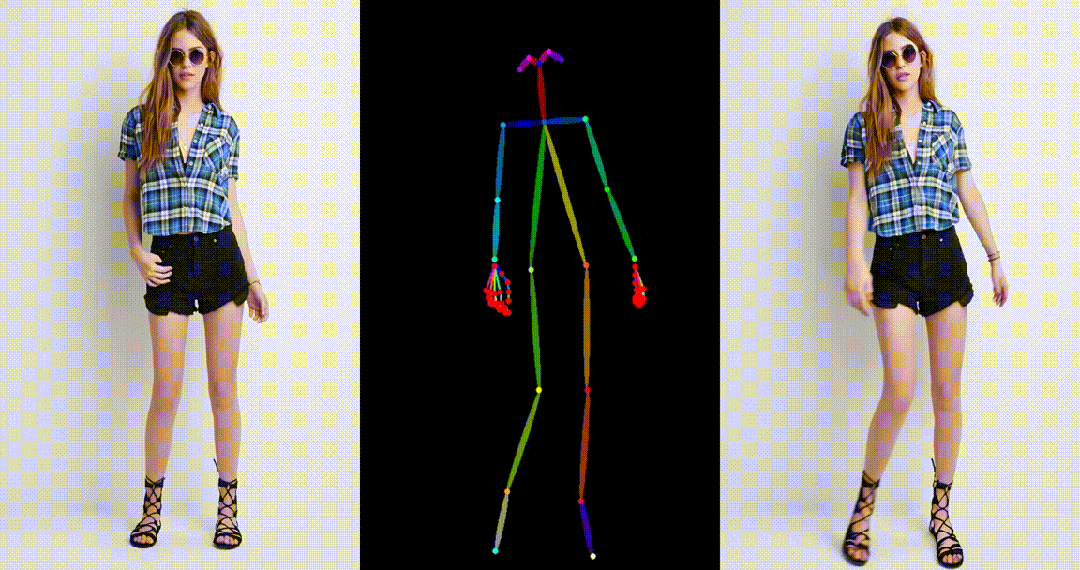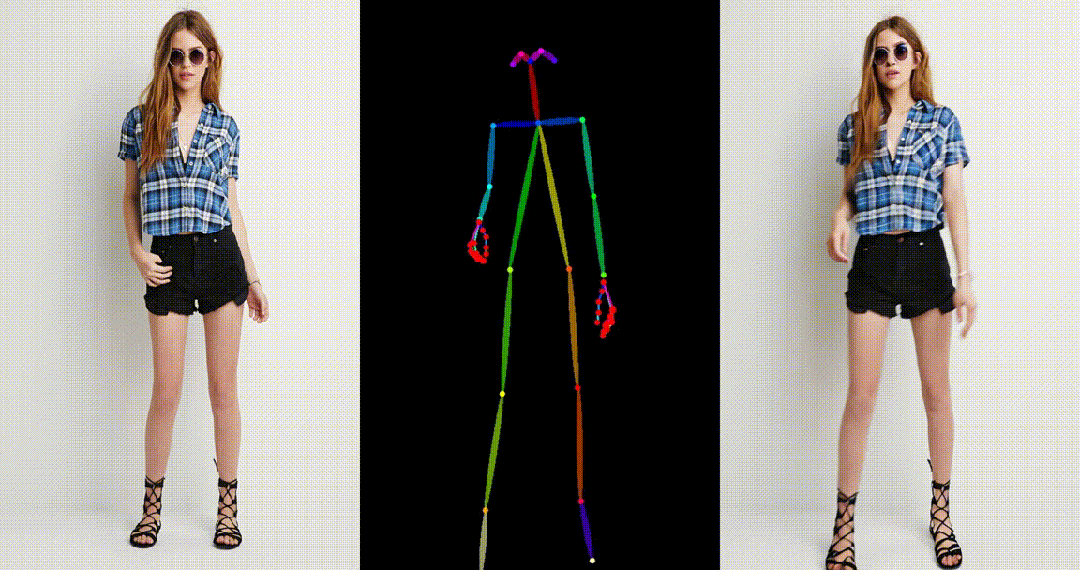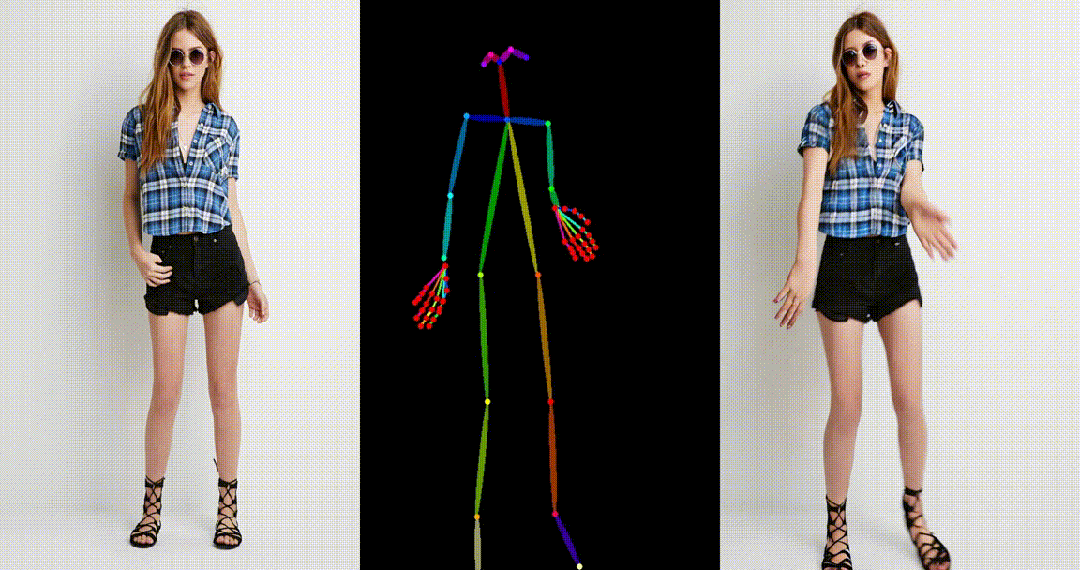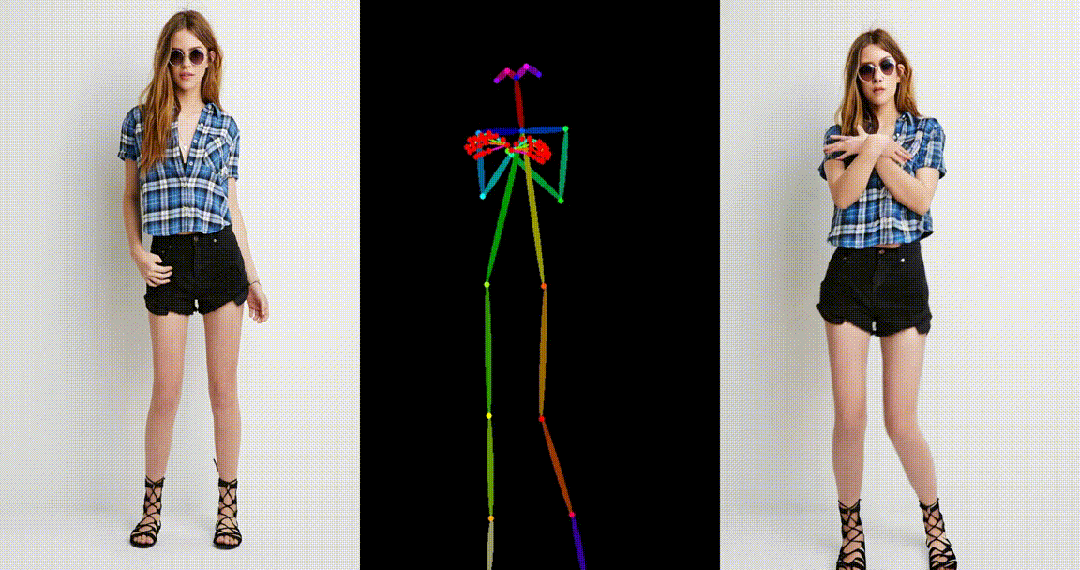
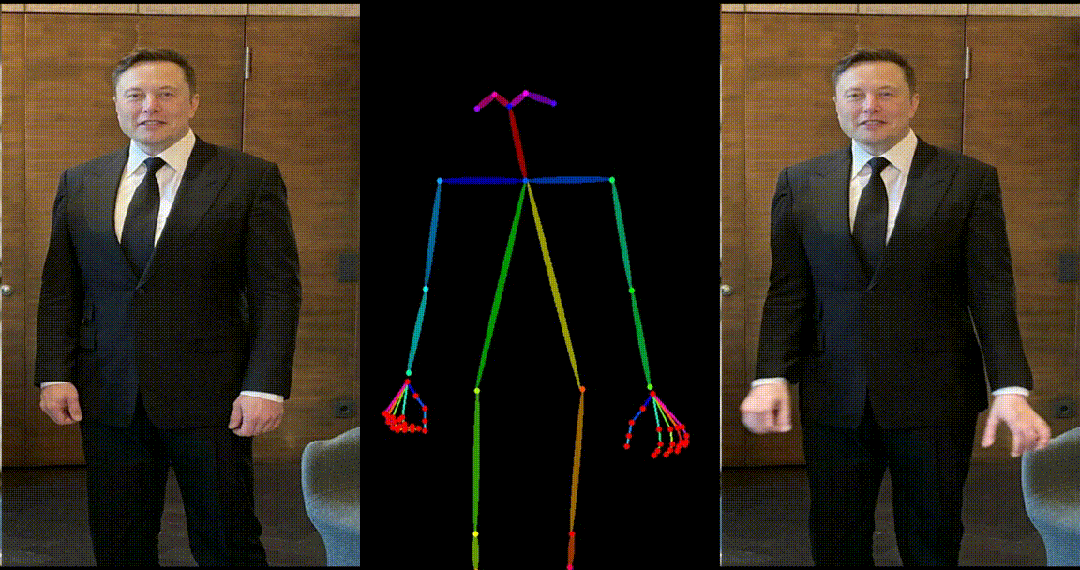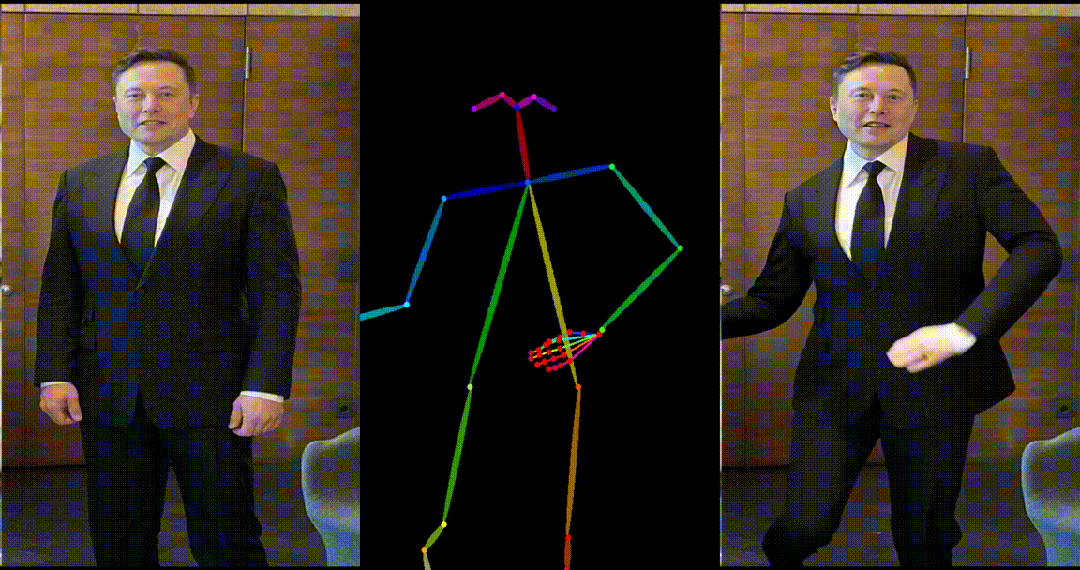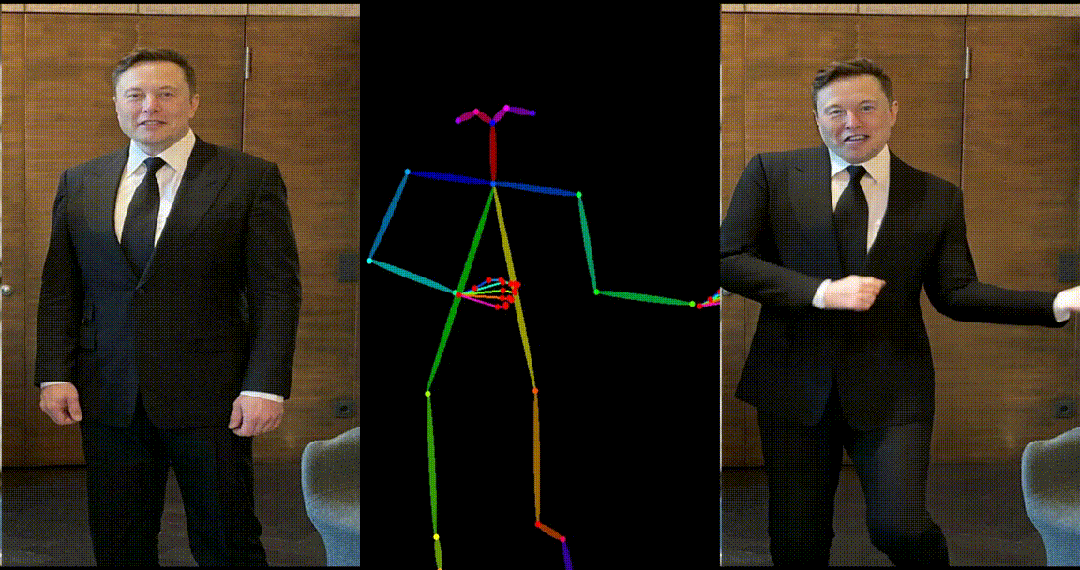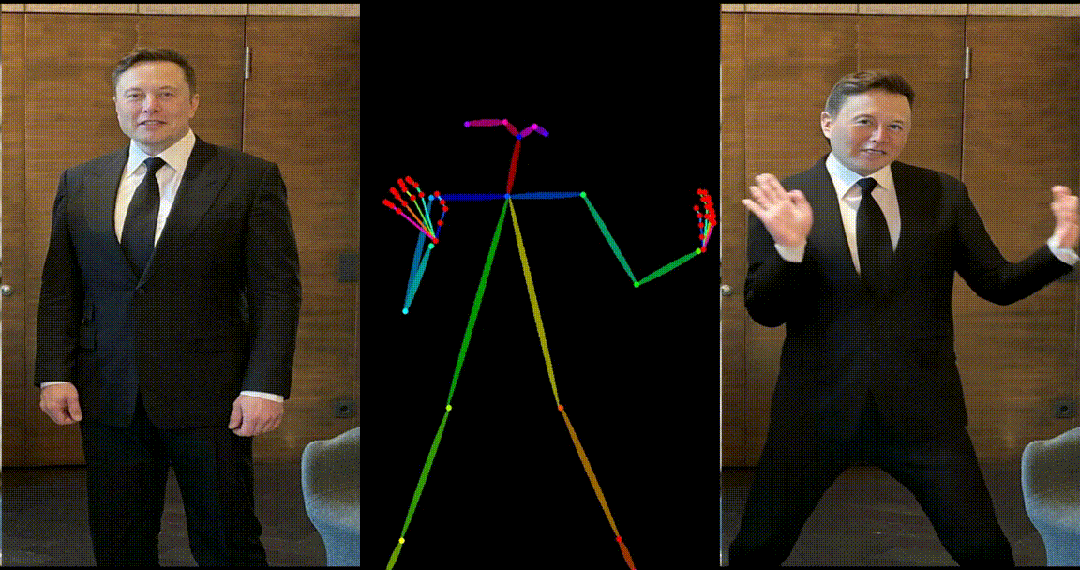
生成结果示例
- 基于合成图片进行跳舞视频生成。


- 基于真实图片进行跳舞视频生成。

- 基于粘土风格图片进行跳舞视频生成。


- 马斯克跳舞。
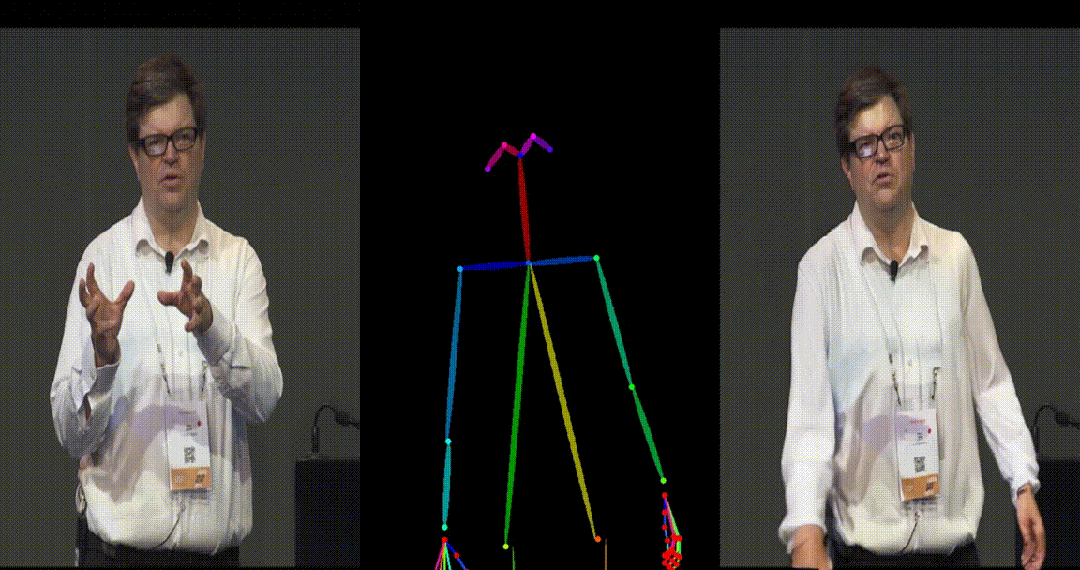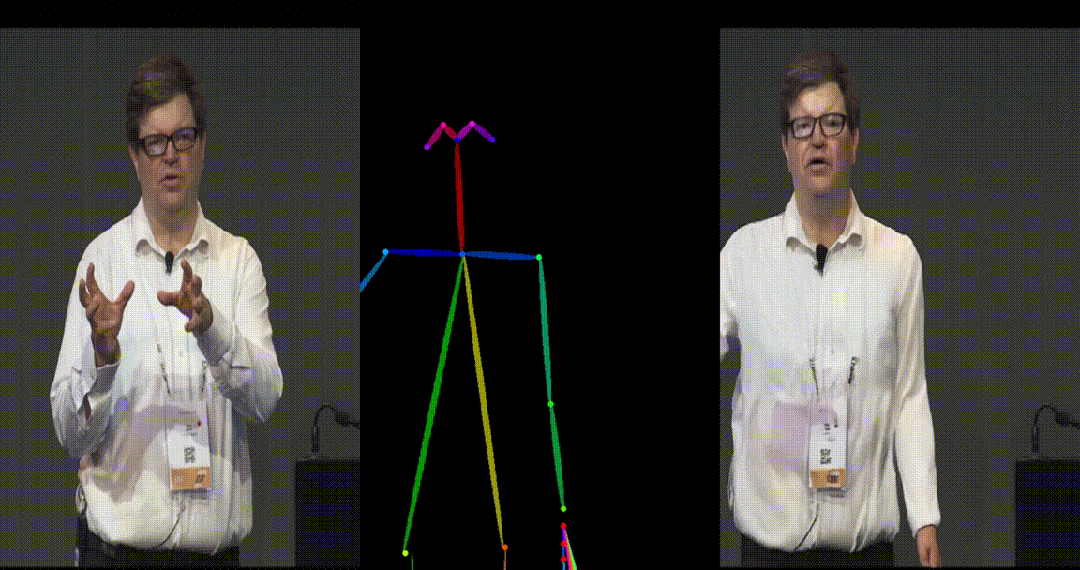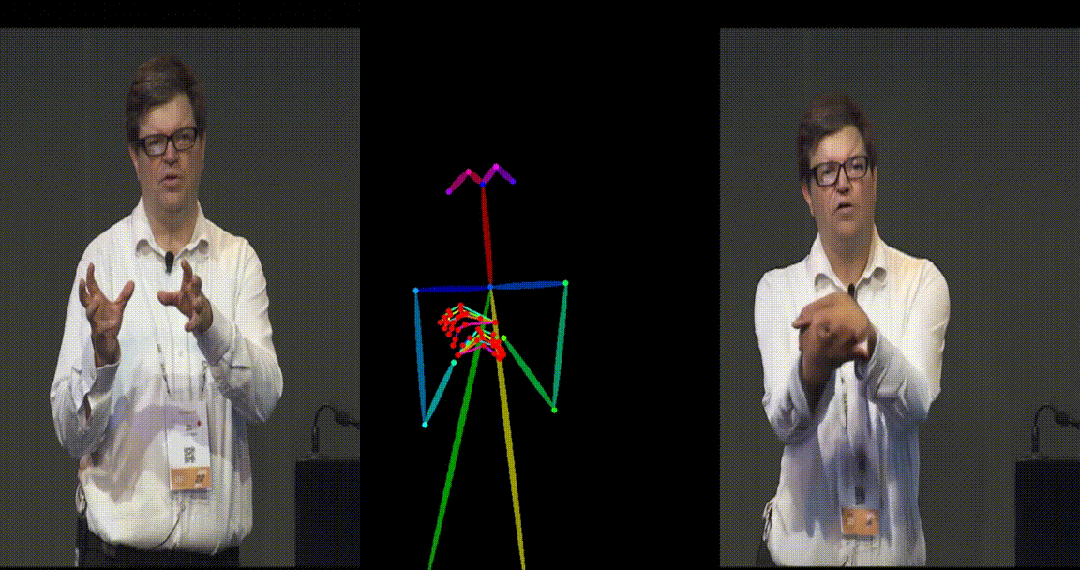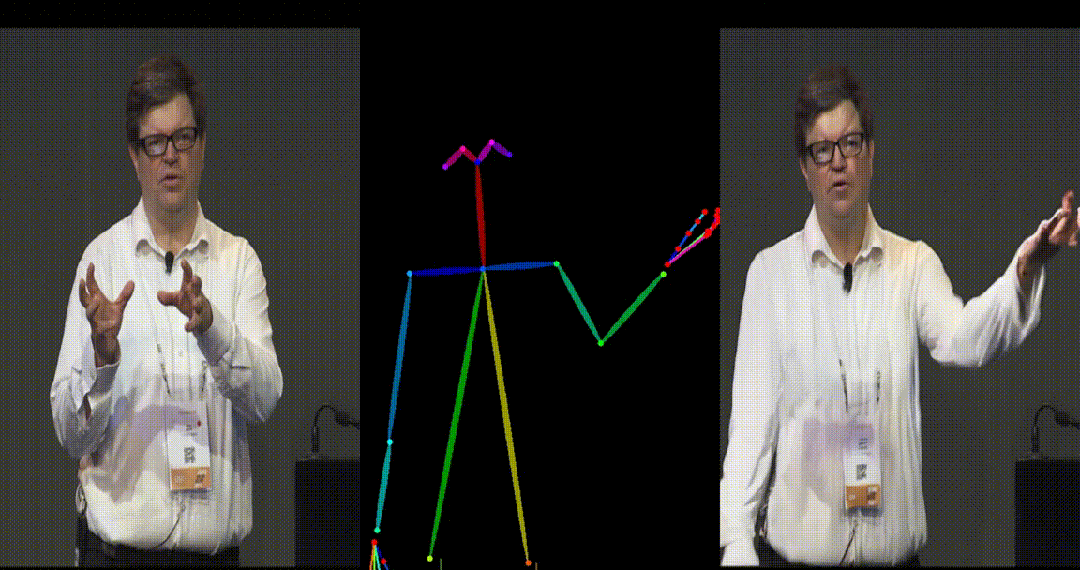
- Yann LeCun 跳舞。
- 基于其他跨域图片进行跳舞视频生成。