文章目录
-
- [第十五章 && 第十六章:](#第十五章 && 第十六章:)
-
- 15.优化
-
- [15.1 查询SQL执行效率](#15.1 查询SQL执行效率)
- [15.2 定位低效率执行SQL](#15.2 定位低效率执行SQL)
- [15.3 explain分析执行计划 - 基本使用](#15.3 explain分析执行计划 - 基本使用)
- [15.4 explain分析执行计划 - id](#15.4 explain分析执行计划 - id)
- [15.5 explain分析执行计划 - select_type](#15.5 explain分析执行计划 - select_type)
- [15.6 explain分析执行计划 - type](#15.6 explain分析执行计划 - type)
- [15.7 explain分析执行计划 -其他指标字段](#15.7 explain分析执行计划 -其他指标字段)
- [15.8 show profile分析SQL](#15.8 show profile分析SQL)
- [15.9 trace分析优化器执行计划](#15.9 trace分析优化器执行计划)
- [15.10 使用索引优化](#15.10 使用索引优化)
-
- [15.10.1 数据](#15.10.1 数据)
- [15.10.2 避免索引失效应用 - 权值匹配](#15.10.2 避免索引失效应用 - 权值匹配)
- [15.10.3 避免索引失效应用 - 最左前缀法则](#15.10.3 避免索引失效应用 - 最左前缀法则)
- [15.10.4 避免索引失效应用 - 其他匹配](#15.10.4 避免索引失效应用 - 其他匹配)
- [15.11 SQL优化](#15.11 SQL优化)
-
- [15.11.1 大批量数据加载优化](#15.11.1 大批量数据加载优化)
- [15.11.2 insert优化](#15.11.2 insert优化)
- [15.11.3 order by优化](#15.11.3 order by优化)
- [15.11.4 子查询优化](#15.11.4 子查询优化)
- [15.11.5 limit优化](#15.11.5 limit优化)
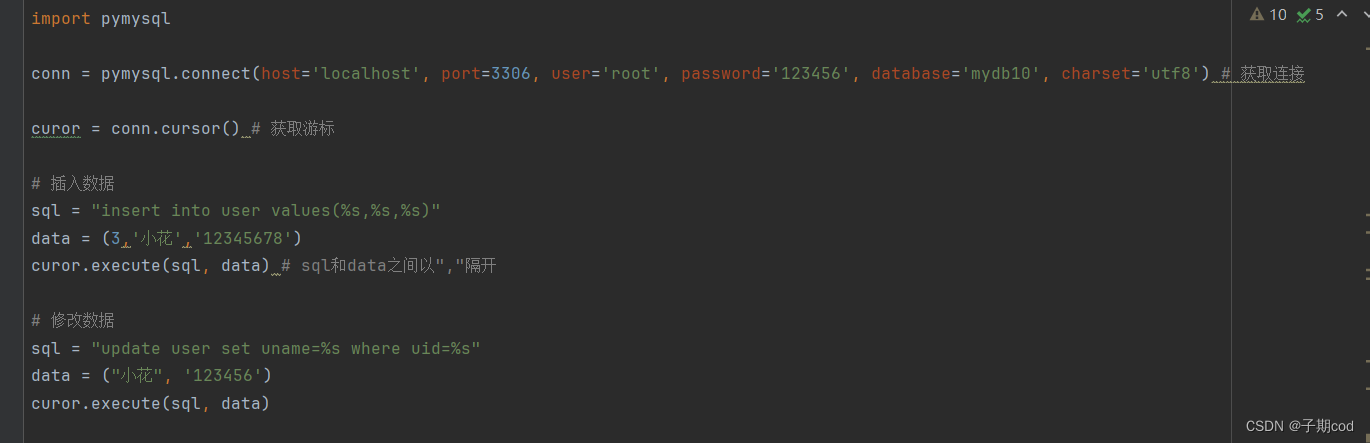
- 16.pymysql
-
- [16.1 查询操作](#16.1 查询操作)
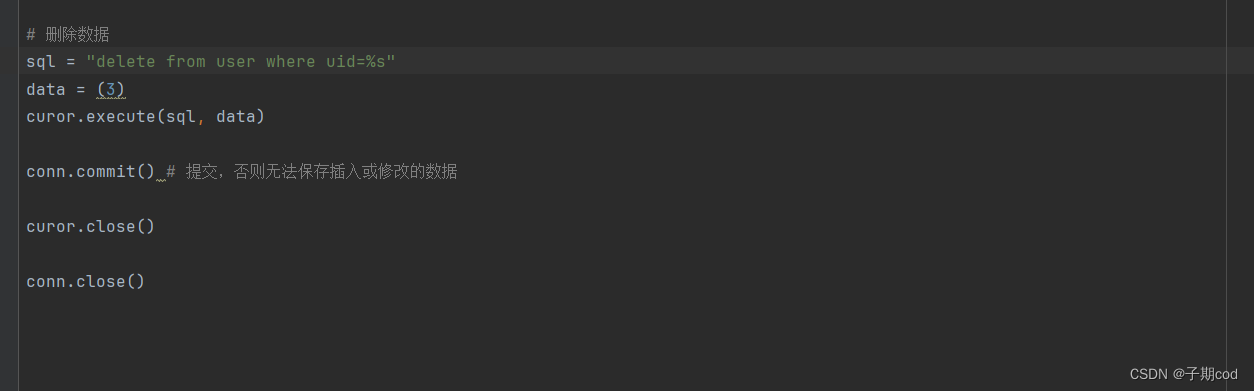
- [16.2 增删改操作](#16.2 增删改操作)
第十五章 && 第十六章:
15.优化
优化方式:
-
从设计上
-
从查询上
-
从索引上
-
从存储上
15.1 查询SQL执行效率
语法:show session \| global \| status
- 查看服务器状态信息

| 参数 | 意义 |
|---|---|
| Com_select | 执行select操作数次,一次查询只累加1 |
| Com_insert | 执行insert操作数次,对批量插入的insert操作,只累加1次 |
| Com_update | 执行update操作数次 |
| Com_delete | 执行delete操作数次 |
| Innodb_rows_read | select查询返回的行数 |
| Innodb_rows_inserted | 执行insert操作插入的行数 |
| Innodb_rows_updated | 执行update操作更新的行数 |
| Innodb_rows_deleted | 执行delete操作删除的行数 |
| Connections | 试图连接MySQL服务器的次数 |
| Uptime | 服务器工作时间 |
| Slow_queries | 慢查询的次数 |
15.2 定位低效率执行SQL
两种方式:
-
慢查询日志:定位执行效率较低的SQL语句
-
show processlist:该指令查看当前MySQL在进行的线程,包括线程的状态、是否锁表等,可实时查看SQL执行情况,同时对一些锁表操作进行优化

15.2.1 show processlist

-
id:用户登录mysqld时,系统分配的"connection_id",可用函数connection_id()查询
-
user:显示当前用户。若不是root,该命令只显示用户权限范围的SQL语句
-
host:显示语句从哪个ip端口上发的,可用来跟踪出现问题语句的用户
-
db:显示进程目前连接的数据库
-
command:显示当前连接执行的命令,一般取值为休眠(sleep),查询(query),连接(connect)等
-
time:显示状态持续的时间,单位是秒
-
state:显示使用当前连接的SQL语句状态。描述的是语句执行中的某一个状态
-
info:显示SQl语句,判断问题语句的重要依据
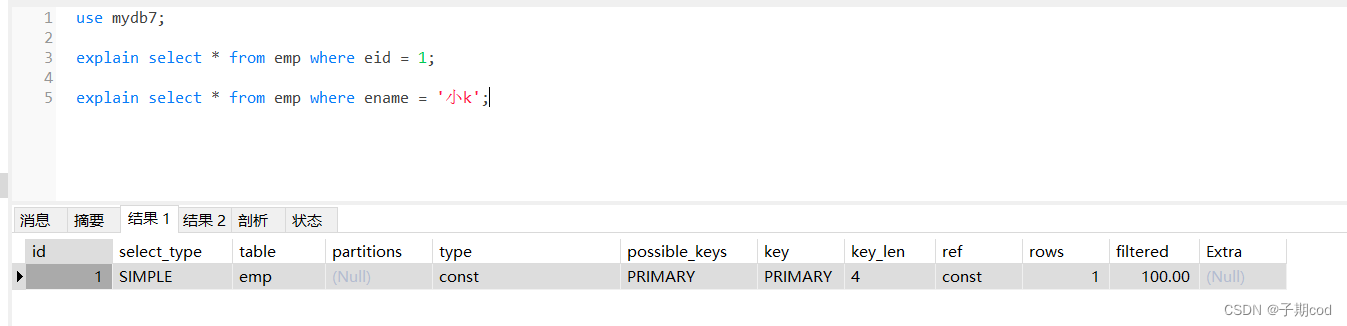
15.3 explain分析执行计划 - 基本使用
-
id:序列号,查询中执行select子句或者是操作表的顺序
-
select_type:SELECT的类型
-
table:输出结果集的表
-
type:表的连接类型
-
possible_keys:查询时,可能使用的索引
-
key:实际使用的索引
-
key_len:索引字段的长度
-
rows:扫描行的数量
-
extra:执行情况的说明和描述
15.4 explain分析执行计划 - id
-
相同id表示加载表的顺序是从上到下
-
不同id值越大,优先级越高,越先被执行
-
id有相同,也有不同,同时存在。id相同可认为是一组,从上往下顺序执行;在所有组中,id值越大,优先级越高,越先被执行
15.5 explain分析执行计划 - select_type
- 表示SELECT类型
| select_type | 意义 |
|---|---|
| SIMPLE | select查询,查询中不包含子查询或UNION |
| PRIMARY | 查询中包含任何复杂的子查询,最外层查询标记为该标识 |
| SUBQUERY | SELECT或WHERE列表中包含了子查询 |
| DERIVED | FROM列表中包含的子查询,被标记为DERIVED,MySQL会递归执行子查询,将结果放入临时表中 |
| UNION | 若第二个SELECT出现在UNION后,则标记为UNION;若UNION包含在FROM子句的子查询中,外层SELECT将被标记DERIVED |
| UNION RESULT | UNION表获取结果的SELECT |
15.6 explain分析执行计划 - type
- 显示访问类型
| type | 意义 |
|---|---|
| NULL | 不访问任何表,索引,直接返回结果 |
| system | 系统表,少量数据,通常不需要进行磁盘IO |
| const | 命中主键或唯一索引 |
| eq_ref | 对于前表的每一行,后表只有一行被扫描 |
| ref | 非唯一性索引扫描,返回匹配某个单独值的所有行 |
| range | 只检索给定返回的行,使用一个索引来选择行 |
| index | 需要扫描索引上的全部数据 |
| all | 全表扫描,此时id上无索引 |
结果值从最好到最坏:system->const->eq_ref->ref->range->index->all
15.7 explain分析执行计划 -其他指标字段
-
table:显示所访问数据库中表名称有时不是真实的表名字,可能是简称
-
rows:扫描行的数量
-
possible_keys:显示可能应用在该表的索引,一个或多个
-
key:实际使用的索引,若为NULL,则没有使用索引
-
key_len:索引中使用的字节数,该值为索引字段最大可能长度,不是实际使用长度,在不损失精度的情况下,长度越短越好
-
extra:
| extra | 意义 |
|---|---|
| using filesort | 说明数据库会对数据使用一个外部的索引排序,不按照表内的索引顺序进行读取,效率较低 |
| using temporary | 需建立临时表来暂存中间结果,效率较低 |
| using index | SQL所需返回的所有列数据均在一颗索引树上,避免访问表的数据行,效率可观 |
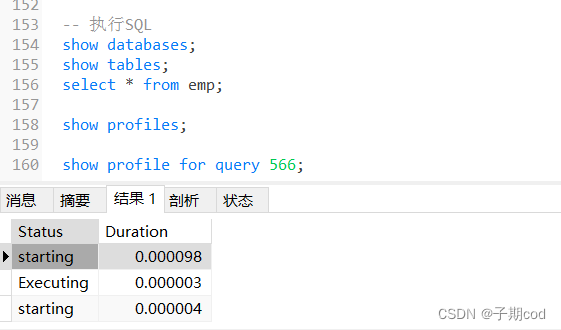
15.8 show profile分析SQL
通过have_profiling参数,可看到当前MySQL是否支持profile
sql
select @@have_profiling;
set profiling=1 -- 开启profiling开关show profile for query query_id 可查看到该SQL执行过程中每个线程的状态和消耗时间
15.9 trace分析优化器执行计划
sql
set optimizer_trace="enabled=on",end_markers_in_json=on;
set optimizer_trace_max_mem_size=1000000;- 打开trace,设置格式为json,并设置trace最大能用的内存大小,避免解析过程中默认内存太小而不能完整展示
通过information_schema.optimizer_trace可知道MySQL如何执行SQL
sql
-- 执行SQL
select * from emp;
select * from information_schema.optimizer_trace \G;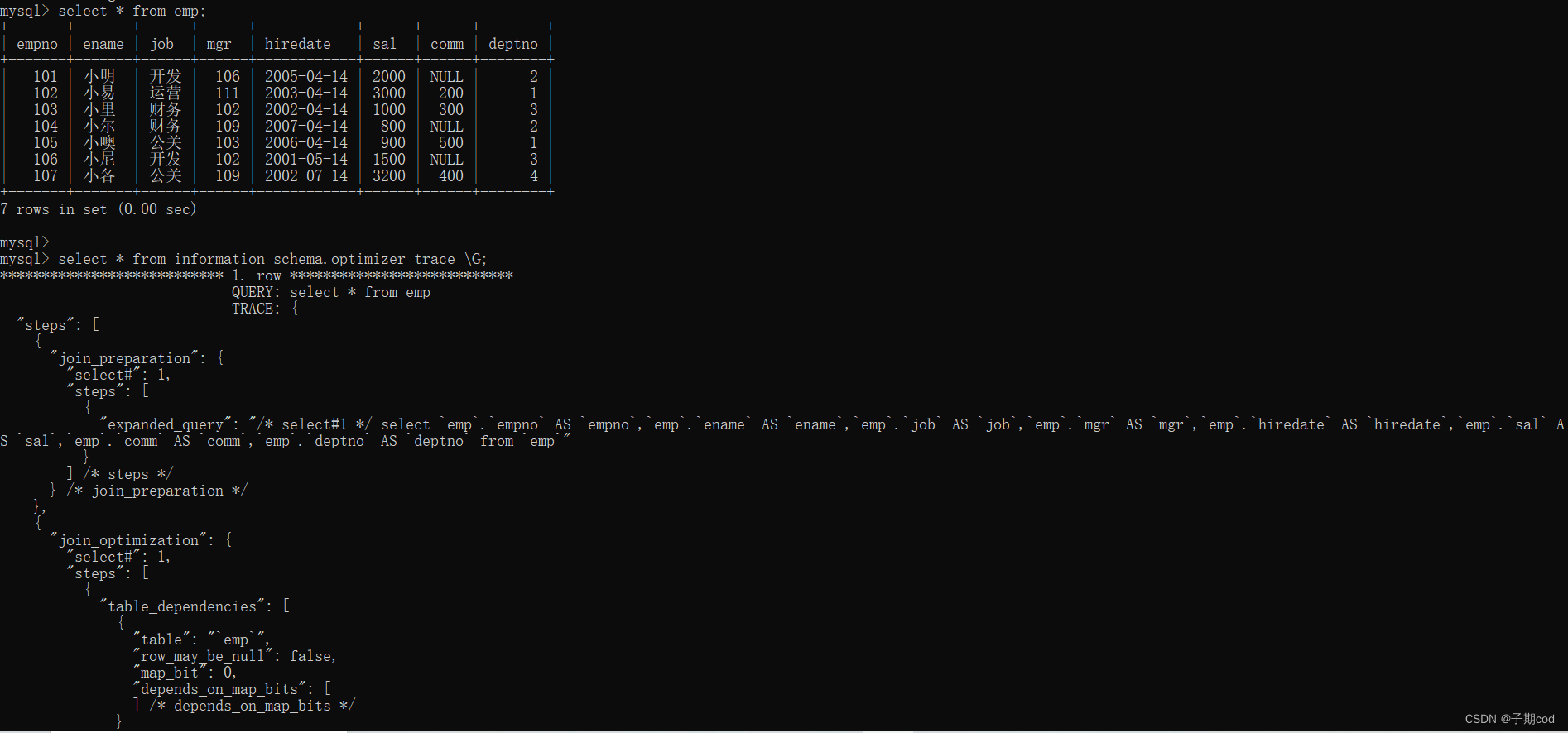
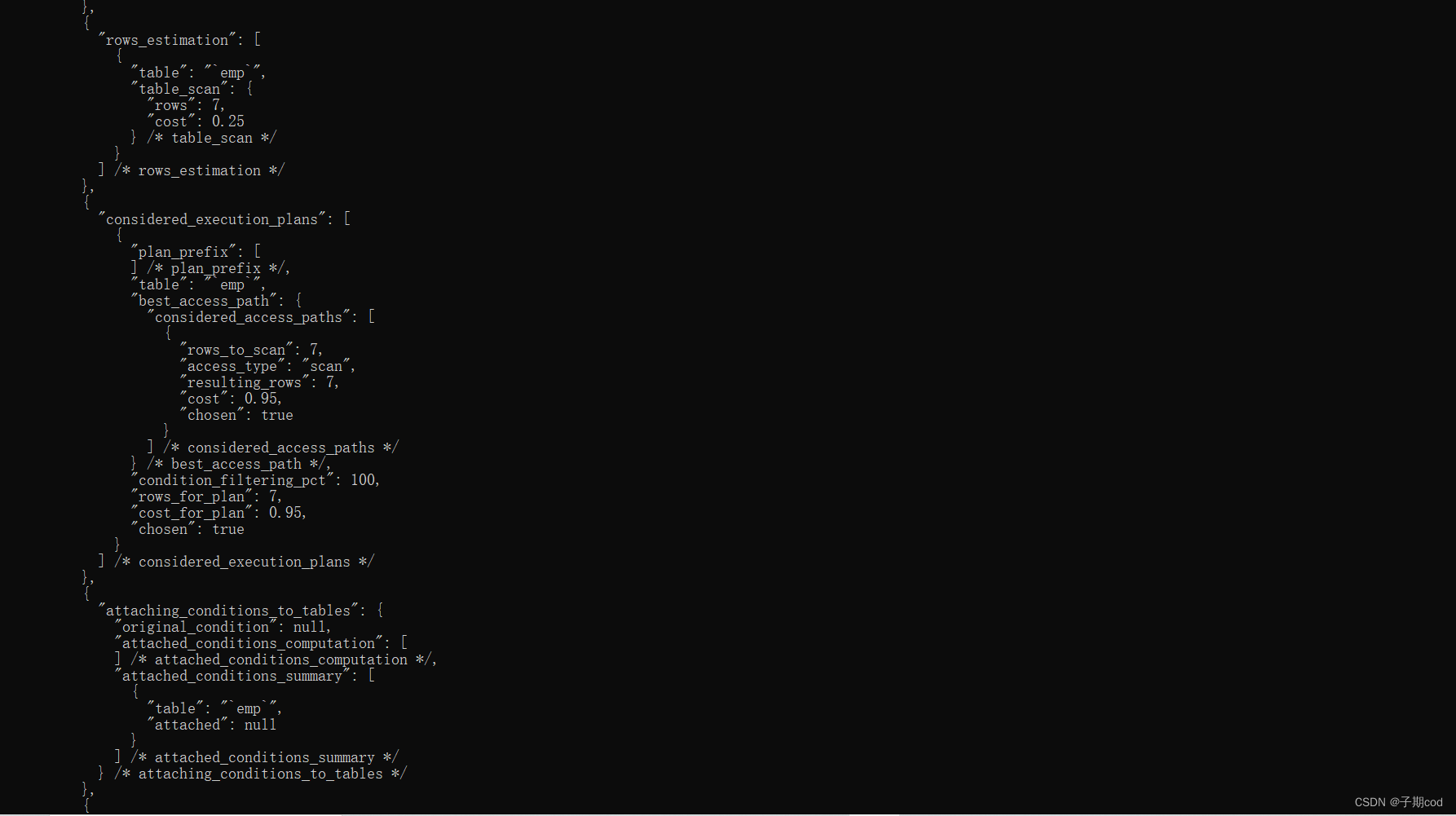
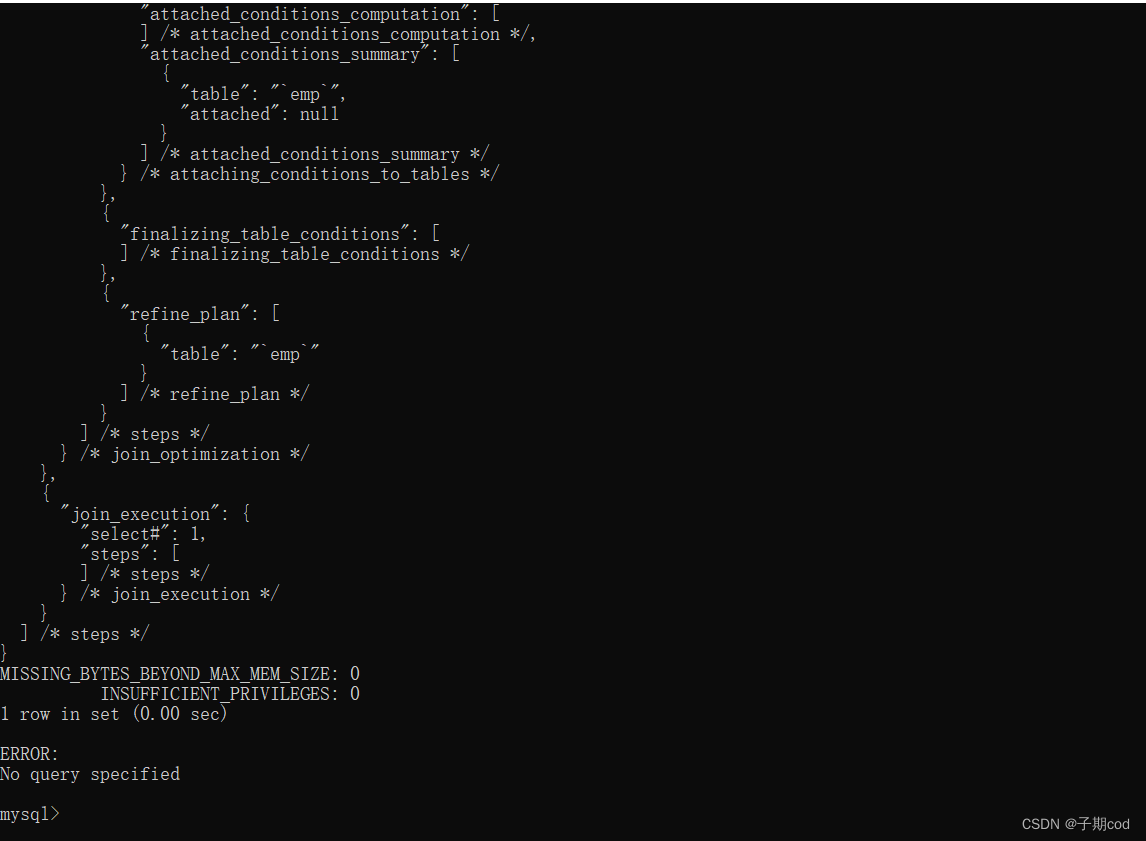
15.10 使用索引优化
15.10.1 数据
sql
create table stu(
id int,
name varchar(20),
age int,
sex varchar(20),
address varchar(20),
primary key(id)
);
insert into stu values(1,'xiaoming',19,'男','北京');
insert into stu values(2,'xiaowang',25,'女','深圳');
insert into stu values(3,'xiaohong',42,'男','北京');
insert into stu values(4,'xiaowu',35,'男','北京');
insert into stu values(5,'xiaoli',52,'女','上海');
insert into stu values(6,'xiaomi',21,'男','北京');
insert into stu values(7,'xiaolin',35,'女','深圳');
insert into stu values(8,'xiaowa',41,'男','深圳');
insert into stu values(9,'xiaoya',23,'女','深圳');
insert into stu values(10,'xiaoyi',27,'女','上海');
insert into stu values(11,'xiaoniu',23,'男','北京');
insert into stu values(12,'xiaohei',43,'女','上海');
create index index_name_sex_address on stu(name,sex,address); -- 创建组合索引15.10.2 避免索引失效应用 - 权值匹配
- 该情况下,索引生效,执行效率高
sql
-- 和字段匹配成功即可,和字段无关
explain select * from stu where name = 'xiaoming' and age = '19' and address = '北京';
explain select * from stu where address = '北京' and name = 'xiaoming' and age = '19';15.10.3 避免索引失效应用 - 最左前缀法则
- 该情况下,索引生效,执行效率高
sql
-- 若索引了多列,要遵守最左前缀法则。查询从索引的最左前列开始,且不跳过索引中的列
explain select * from stu where name = 'xiaoming';
-- 违反最左前缀法则,索引失效
explain select * from stu where id = '1';
-- 复合最左前缀法则,但出现跳跃某一列,只有最左列索引生效
explain select * from stu where name = 'xiaoming' and address = '北京';15.10.4 避免索引失效应用 - 其他匹配
- 该情况下,索引生效,执行效率高
sql
/*
Extra:
using index :使用覆盖索引时会出现
using where :查找使用索引情况下,需回表去查询所需数据
using index condition :查找使用了索引,但需要回表查询数据
using index;using where :查找使用了索引,但所需的数据都在索引列中能找到,因此无需回表查询数据
*/
-- 范围查询右边的列,不能使用索引
explain select * from stu where name = 'xiaoming' and age > '18' and address = '北京';
-- 不要在索引列上进行运算操作,不然索引将失效
explain select * from stu where substring(name,5,4) = 'ming';
-- 字符串不加单引号,会造成索引失效
explain select * from stu where name = 'xiaoming' and age > 18;
-- 尽量使用覆盖索引,避免select *
explain select * from stu where name = 'xiaoming' and age = 19; -- 需从原表及磁盘上读取数据,效率较低
-- 从索引树中就可查询所有数据
explain select name from stu where name = 'xiaoming' and address = '北京'; -- 效率较高
explain select name,age from stu where name = 'xiaoming' and address = '北京'; -- 效率较高
explain select name,age,sex,address from stu where name = 'xiaoming' and address = 'beijing'; -- 效率较高
-- 用or分隔的条件,若or前的条件中的列有索引,而后面的列没有索引,那么涉及的索引都不会被用到
explain select * from stu where name = 'xiaoming' or address = '北京';
-- 以%开头的like模糊查询,索引失效
explain select * from stu where name like 'ming%'; -- 使用索引
explain select * from stu where name like '%ming'; -- 不用索引
explain select * from stu where name like '%ming%'; -- 不用索引
-- 弥补不足,不用*,使用索引列
explain select name from stu where name like '%ming%';
-- 若MySQL评估使用索引比全表慢,则不使用
create index index_stu_address on stu(address);
explain select * from stu where address = '北京'; -- 没用索引
-- is NULL, is NOT NULL 有时有效 有时失效
create index index_age on stu(age);
explain select * from stu where address is NULL; -- 有效
explain select * from stu where age is not NULL; -- 无效
-- in 有效 , not in 索引无效
-- 普通索引
explain select * from stu where name in('xiaoming','xiaohong'); -- 使用索引
explain select * from stu where name not in('xiaoming','xiaohong'); -- 不使用索引
-- 主键索引
explain select * from stu where age in(18, 19); -- 使用索引
explain select * from stu where age not in(18, 19); -- 不使用索引
-- 单列索引和复合索引,尽量使用复合索引
create index index_stu_name_age_address on stu(name, age, address);
-- 等价 ---》 name / name + age / name + age + address
create index index_address on stu(address);
explain select * from stu where name = 'xiaoming' and age > 18 and address = '北京';
-- 若一张表有多个单列索引,即使WHERE中都使用了索引列,则只有一个最优索引列生效
create index index_name on stu(name);
create index index_age on stu(age);
create index index_address on stu(address);
explain select * from stu where name = 'xiaoming' and age = '19' and address = '北京';15.11 SQL优化
15.11.1 大批量数据加载优化
使用load命令导入数据时,适当设置可提高导入效率。对于InnoDB类型的表,以下方式可提高导入的效率:
-
主键顺序插入:InnoDB类型的表按照主键的顺序保存,将导入的数据按照主键的顺序排列,可有效提高导入数据的效率
-
关闭唯一性校验:导入数据前执行SET UNIQUE_CHECKS=0,关闭唯一性校验,导入结束后SET UNIQUE_CHECKS=1, 恢复唯一性校验,可提高导入效率
15.11.2 insert优化
sql
-- 原始方法
insert into stu values(1,'xiaoming',19,'男','北京');
insert into stu values(2,'xiaowang',25,'女','深圳');
insert into stu values(3,'xiaohong',42,'男','北京');
-- 优化后
insert into stu values(1,'xiaoming',19,'男','北京'),(2,'xiaowang',25,'女','深圳'),(3,'xiaohong',42,'男','北京');
-- 大大缩减客户端与数据库之间的连接、关闭等消耗
-- 在事务中进行数据插入
begin;
insert into stu values(1,'xiaoming',19,'男','北京');
insert into stu values(2,'xiaowang',25,'女','深圳');
insert into stu values(3,'xiaohong',42,'男','北京');
commit;
-- 数据有序插入
insert into stu values(3,'xiaoming',19,'男','北京');
insert into stu values(1,'xiaowang',25,'女','深圳');
insert into stu values(2,'xiaohong',42,'男','北京');
-- 优化后
insert into stu values(1,'xiaoming',19,'男','北京');
insert into stu values(2,'xiaowang',25,'女','深圳');
insert into stu values(3,'xiaohong',42,'男','北京');15.11.3 order by优化
-
通过对返回数据进行排序,该情况为filesort排序,所有不是通过索引直接返回排序结果的排序都叫FileSort排序
-
通过有序索引顺序扫描直接返回有序数据,该情况为using index,无需额外排序,操作效率高
sqlexplain select * from stu order by age; -- using filesort explain select * from stu order by age,sex; -- using filesort explain select id from stu order by age; -- using index explain select id,age from stu order by age; -- using index explain select id,age,sex from stu order by age; -- using index -- order by后的多个排序字段尽量排序方式相同 explain select id,age from stu order by age asc, sex desc; -- Using index;Using filesort explain select id,age from stu order by age desc, sex desc; -- Backward index scan;Using index -- order by后边的多个排序字段字段顺序尽量和组合索引字段一致 explain select id,age from stu order by sex,age; -- using index, using filesort
FileSort优化
通过创建合适的索引,减少FileSort的出现,需要加快排序操作,MySQL有两种排序算法:
-
两次扫描算法:先根据条件取出排序字段和行指针信息,然后在排序区sort buffer中排序,若sort buffer不够,则在临时表temporary table中存储排序结果。完成排序后,再根据行指针回表读取记录,该操作会导致大量随机I/O操作
-
一次扫描算法:一次性取出满足条件的所有字段,,然后在排序区sort buffer中排序后直接输出结果集。排序时内存开销较大,但排序效率比两次扫描算法更高
MySQL通过比较系统变量max_length_for_sort_data和Query语句取出的字段总大小,判定使用哪种算法,若max_length_for_sort_data更大,使用第二种优化后的算法,反之使用第一种算法。可适当提高max_length_for_sort_data和sort_buffer_size系统变量,来增大排序区的大小,提高排序效率
sql
show variables like 'max_length_for_sort_data'; -- 4096
show variables like 'sort_buffer_size'; -- 26214415.11.4 子查询优化
使用子查询可一次性完成很多逻辑上需要多个步骤才能完成的操作,同时还可避免事务或表锁死,写起来也比较容易。但在有些情况,子查询可被更加高效的连接(JOIN)替代
sql
explain select * from stu where uid in (select uid from stu_role);
explain select * from stu s, stu_role sr where s.uid = ur.uidsystem>const>eq_ref>ref>range>index>ALL
连接(JOIN)查询效率更高些的原因是MySQL不需要在内存中创建临时表来完成逻辑上需要两个步骤的查询工作
15.11.5 limit优化
-
在索引上完成排序分页操作,最后根据主键关联回原表查询所需的其他列内容
-
可把limit查询转换程某个位置的查询,适用于主键自增的表
sql
select count(*) from stu;
select * from stu limit 0,10;
select * from * from stu limit 900000,10; -- 0.582
select * from stu a, (select id from stu2 order by id limit 900000,10) b where a.id = b.id -- 0.375
explain select * from stu where id > 90000 limit 10;16.pymysql
16.1 查询操作
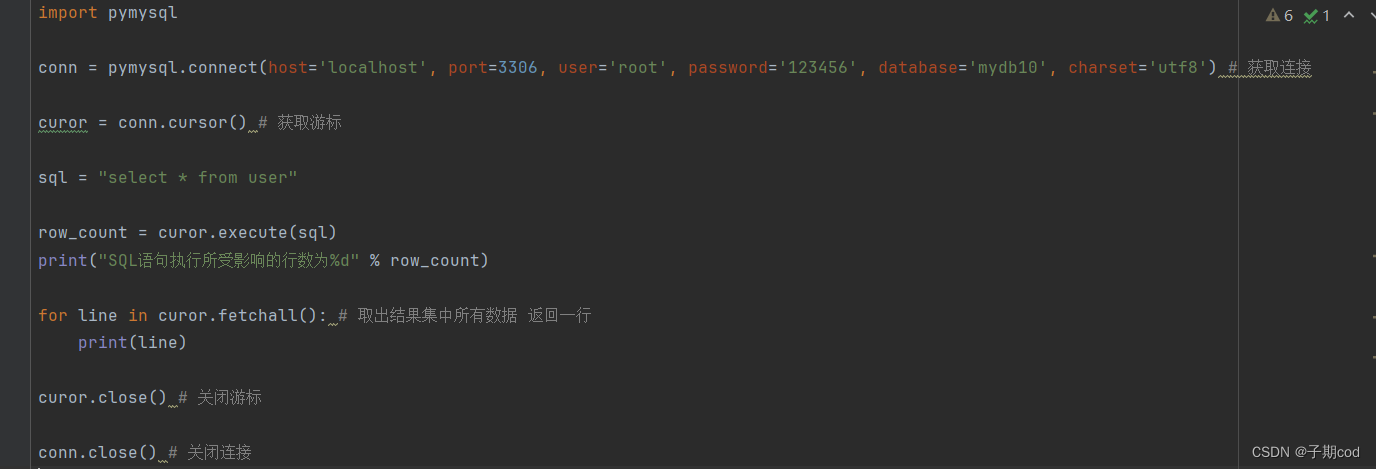
16.2 增删改操作