感知器是一种非常早期的线性分类模型,作为一种简单的神经网络模型被提出。感知器是一种模拟生物神经元行为的机器,有与生物神经元相对应的部件,如权重(突触)、偏置(阈值)及激活函数(细胞体),输出为+1或-1。
模型
感知器的模型结构与其他回归函数相同,都是对线性模型的复合。
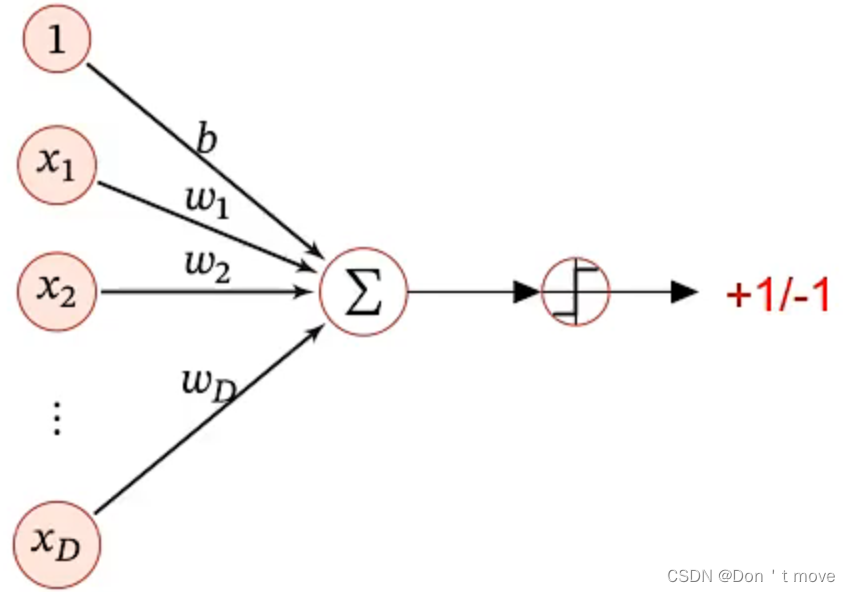
y ^ = s g n ( w T x ) \hat{y}=\mathrm{sgn}(w^Tx) y^=sgn(wTx)
但是与之前那些线性分类模型不同的是,感知器的输出在区间 ( − 1 , 1 ) (-1, 1) (−1,1)上
学习目标
在保证数据集线性可分的情况下( w ∗ w^* w∗存在),对于训练集 { ( x ( n ) , y ( n ) ) } n = 1 N \{(x^{(n)},y^{(n)})\}_{n=1}^N {(x(n),y(n))}n=1N,找到最优权重 w ∗ w^* w∗使得:
y ( n ) w ∗ T x ( n ) > 0 , ∀ n ∈ { 1 , ⋯ , N } y^{(n)}{w^*}^Tx^{(n)}>0,\ \ \forall n\in\{1,\cdots,N\} y(n)w∗Tx(n)>0, ∀n∈{1,⋯,N}
举例来说,假设一个样本中 y = 1 y=1 y=1,如果上式<0则说明预测值 y ^ = w ∗ T x = − 1 \hat{y}={w^*}^Tx=-1 y^=w∗Tx=−1,也就是说预测值与真实值不同,意味着该样本的分类不是正确的分类;反之则意味着样本被分到了正确的分类中。
优化方法:一种错误驱动的在线学习算法
- 在线学习:数据是流式传输、一个一个的过来的,类似于从队列取出数据来进行学习,完成一次迭代后从头重新开始再一个一个进行学习。
- 错误驱动:在数据预测错误时才对参数进行更新,否则不更新
首先初始化一个权重向量 w ← 0 w\leftarrow 0 w←0(通常是全零向量),每次分错一个样本(即 y w T x < 0 yw^Tx<0 ywTx<0)则更新权重
w ← w + y x w\leftarrow w+yx w←w+yx
至于为什么要这样更新,可以看一个例子:如果 y w t T x < 0 y{w_t}^Tx<0 ywtTx<0,那么更新参数 w t + 1 = w t + y x w_{t+1}=w_t+yx wt+1=wt+yx,更新后 y w t + 1 T x = y ( w t + y x ) T x = y w t T x + y y T x T x = y w t T x + y 2 ∥ x ∥ 2 y{w_{t+1}}^Tx=y(w_t+yx)^Tx=y{w_t}^Tx+yy^Tx^Tx=y{w_t}^Tx+y^2\parallel x\parallel^2 ywt+1Tx=y(wt+yx)Tx=ywtTx+yyTxTx=ywtTx+y2∥x∥2,其中后项 y 2 ∥ x ∥ 2 > 0 y^2\parallel x\parallel^2>0 y2∥x∥2>0,因此最终 y w t + 1 T x ≥ y w t T x y{w_{t+1}}^Tx\geq yw_t^Tx ywt+1Tx≥ywtTx,经过多次迭代后,最终可以让这个结果>0。
感知器这种学习策略实际上与梯度下降的迭代过程非常类似,用这种思想,可以反推感知器的损失函数。按照随机梯度下降的迭代思路,对于一个样本,将 y x yx yx看作含梯度的项,同时参数优化方向与梯度方向相反,得:
∂ L ( w ) ∂ w = { − y x i f y w T x < 0 0 i f y w T x > 0 L ( w ) = { − y w T x i f y w T x < 0 C i f y w T x > 0 \begin{aligned} \frac{\partial\mathcal{L}(w)}{\partial w} &=\left\{\begin{aligned} -yx\ \ \ \ & if\ \ yw^Tx<0\\ 0\ \ \ \ & if\ \ yw^Tx>0 \end{aligned}\right.\\\\ \mathcal{L}(w) &=\left\{\begin{aligned} -yw^Tx\ \ \ \ & if\ \ yw^Tx<0\\ C\ \ \ \ \ \ \ & if\ \ yw^Tx>0 \end{aligned}\right. \end{aligned} ∂w∂L(w)L(w)={−yx 0 if ywTx<0if ywTx>0={−ywTx C if ywTx<0if ywTx>0
因此损失函数为
L ( w ; x , y ) = max ( 0 , − y w T x ) \mathcal{L}(w;x,y)=\max(0, -yw^Tx) L(w;x,y)=max(0,−ywTx)
也就是说,当样本分类正确( y w T x > 0 yw^Tx>0 ywTx>0)时损失为0,分类错误( y w T x < 0 yw^Tx<0 ywTx<0)时损失为 − y w T x -yw^Tx −ywTx
下面是对错误驱动算法的伪代码描述

其中,随机排序的目的是为了保证了样本的随机性,不受少数几个样本的影响,如果已知保持训练集顺序不变就会导致训练集后面几个样本的权重大。其次,达到最大迭代次数也可以是在验证集上收敛。
相比Logistic回归,感知器不需要比较预测值与真实值之间的差异( y ( n ) − y ^ ( n ) y^{(n)}-\hat{y}^{(n)} y(n)−y^(n))。也就是说,感知器不比较犯错误的程度有多大,而Logistic回归需要比较犯错误程度,但凡有一点偏差就要纠正,二者在不同的场景下各有优劣。
下面是一个感知器参数学习的更新过程示例,其中空心点表示负例,实心表示正例:
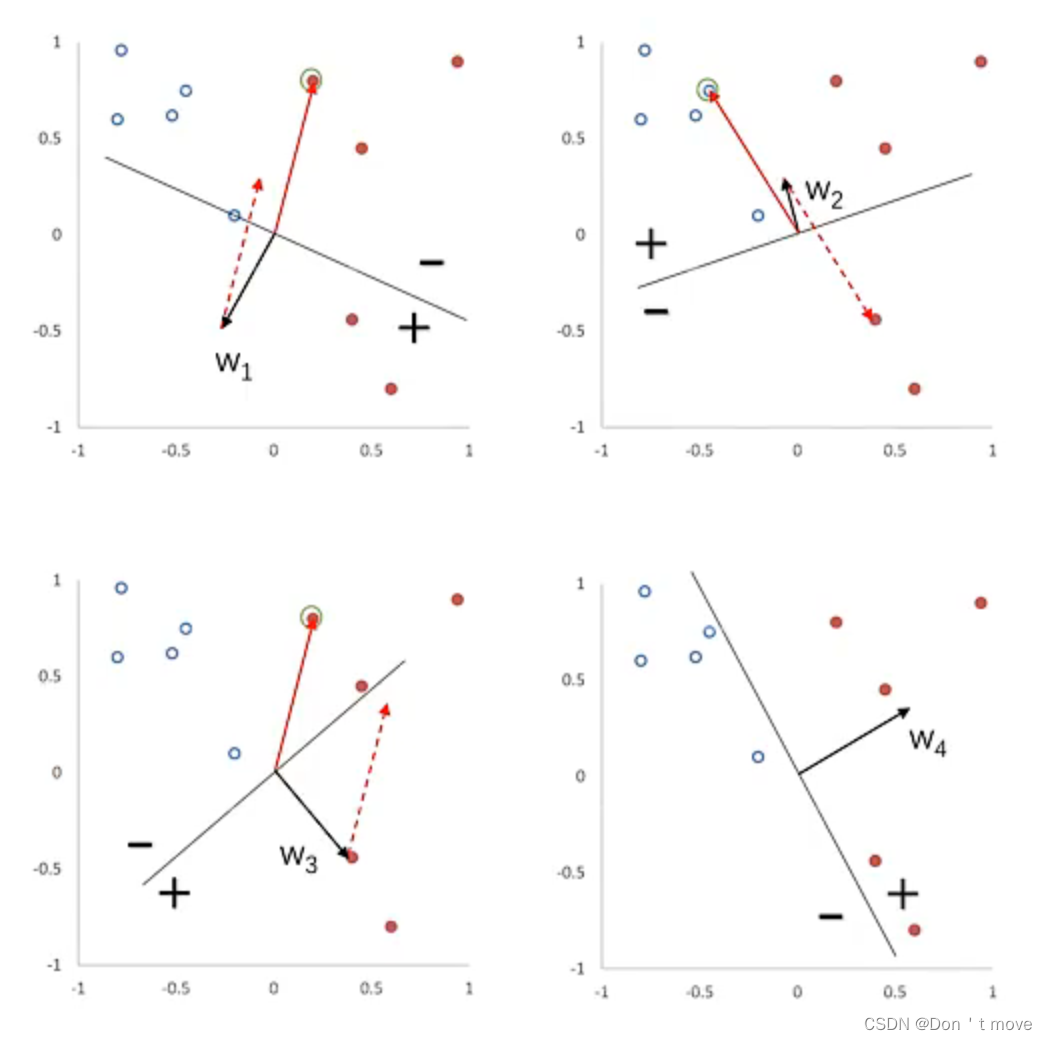
开始先随机初始化一个参数 w 1 w_1 w1,分界面为 w 1 T x = 0 w_1^Tx=0 w1Tx=0,此时,感知器预测的正例为 y w 1 T x > 0 yw_1^Tx>0 yw1Tx>0、负例为 y w 1 T x < 0 yw_1^Tx<0 yw1Tx<0,直观上来看,从分界线到参数 w 1 w_1 w1所在一侧为正例,另一侧为负例,如上图中左上所示。从中随机挑选一个样本,假如取到了正例样本但却被分为负例,则更新参数 w 2 = w 1 + y x w_2=w_1+yx w2=w1+yx,其中由于随机的样本是正例,也就是 y = 1 y=1 y=1,则 w 2 = w 1 + x w_2=w_1+x w2=w1+x,变成如上图右上所示。同样的操作,经过四次后变为右下所示的图,完成参数学习。
收敛性
感知器的收敛性 是指给定训练集 D = { ( x ( n ) , y ( n ) ) } n = 1 N \mathcal{D}=\{(x^{(n)}, y^{(n)})\}{n=1}^N D={(x(n),y(n))}n=1N,令R是训练集中最大的特征向量的模,即 R = max n ∥ x ( n ) ∥ R=\max\limits{n}\parallel x^{(n)}\parallel R=nmax∥x(n)∥ 。如果训练集 D \mathcal{D} D线性可分,两类感知器的参数学习算法权重更新次数不超过 R 2 γ 2 \frac{R^2}{\gamma^2} γ2R2。其中 γ \gamma γ表示一个趋向于零的很小的数,衡量样本中正负例的分离程度, γ \gamma γ越大说明样本中两例分离越大反之越小。
也就是说对于线性可分的数据集来说,感知器能够保证在有限的更新步骤当中找到这个分界面。
收敛性证明:
对于感知器来说,权重向量的更新方式为:
w k = w k − 1 + y ( k ) x ( k ) = w k − 2 + y ( k − 1 ) x ( k − 1 ) + y ( k ) x ( k ) \begin{aligned} w_k &=w_{k-1}+y^{(k)}x^{(k)}\\ &=w_{k-2}+y^{(k-1)}x^{(k-1)}+y^{(k)}x^{(k)} \end{aligned} wk=wk−1+y(k)x(k)=wk−2+y(k−1)x(k−1)+y(k)x(k)
则在第K次更新时的感知器的权重向量为:
w k = ∑ k = 1 K y ( k ) x ( k ) w_k=\sum_{k=1}^Ky^{(k)}x^{(k)} wk=k=1∑Ky(k)x(k)
则:
∥ w k ∥ 2 = ∥ w k − 1 + y ( k ) x ( k ) ∥ 2 = ∥ w k − 1 ∥ 2 + ∥ y ( k ) x ( k ) ∥ 2 + 2 w k − 1 T y ( k ) x ( k ) \begin{aligned} \parallel w_k\parallel^2 &=\parallel w_{k-1}+y^{(k)}x^{(k)}\parallel^2\\ &=\parallel w_{k-1}\parallel^2+\parallel y^{(k)}x^{(k)}\parallel^2+2w_{k-1}^Ty^{(k)}x^{(k)} \end{aligned} ∥wk∥2=∥wk−1+y(k)x(k)∥2=∥wk−1∥2+∥y(k)x(k)∥2+2wk−1Ty(k)x(k)
上式中,由于只有遇到判错才会更新,因此 2 w k − 1 T y ( k ) x ( k ) < 0 2w^T_{k-1}y^{(k)}x^{(k)}<0 2wk−1Ty(k)x(k)<0。此外, y ( k ) = ± 1 y^{(k)}=\pm 1 y(k)=±1所以式子中 ∥ y ( k ) x ( k ) ∥ 2 = ∥ x ( k ) ∥ 2 \parallel y^{(k)}x^{(k)}\parallel^2=\parallel x^{(k)}\parallel^2 ∥y(k)x(k)∥2=∥x(k)∥2。式子中的正数项:
∥ w k − 1 ∥ 2 + ∥ y ( k ) x ( k ) ∥ 2 = ∥ w k − 1 ∥ 2 + ∥ x ( k ) ∥ 2 ≤ ∥ w k − 1 ∥ 2 + R 2 ≤ ∥ w k − 2 ∥ 2 + 2 R 2 ≤ K R 2 \begin{aligned} \parallel w_{k-1}\parallel^2+\parallel y^{(k)}x^{(k)}\parallel^2 &=\parallel w_{k-1}\parallel^2+\parallel x^{(k)}\parallel^2\\ &\leq\parallel w_{k-1}\parallel^2+R^2\\ &\leq\parallel w_{k-2}\parallel^2+2R^2\\ &\leq KR^2 \end{aligned} ∥wk−1∥2+∥y(k)x(k)∥2=∥wk−1∥2+∥x(k)∥2≤∥wk−1∥2+R2≤∥wk−2∥2+2R2≤KR2
加上最后的小于0的项后上式仍然成立,因此可得 ∥ w k ∥ 2 ≤ K R 2 \parallel w_k\parallel^2\leq KR^2 ∥wk∥2≤KR2。
接下来,设 w ∗ w^* w∗为最优分界面对应的参数,由于 w w w的模与分类是无关的,只需要考虑正负号,因此约定 ∥ w ∗ ∥ 2 = 1 \parallel w^*\parallel^2=1 ∥w∗∥2=1,同时有公式向量模的内积大于向量内积的模,因此:
∥ w k ∥ 2 = ∥ w ∗ ∥ 2 ∥ w k ∥ 2 ≥ ∥ w ∗ w k ∥ 2 = ∥ ∑ k = 1 K w ∗ T y ( k ) x ( k ) ∥ 2 \begin{aligned} \parallel w_k\parallel^2 &=\parallel w^*\parallel^2\parallel w_k\parallel^2\\ &\geq\parallel w^*w_k\parallel^2\\ &=\parallel \sum_{k=1}^K{w^*}^Ty^{(k)}x^{(k)}\parallel^2 \end{aligned} ∥wk∥2=∥w∗∥2∥wk∥2≥∥w∗wk∥2=∥k=1∑Kw∗Ty(k)x(k)∥2
因为 w ∗ w^* w∗是最优的参数,因此上式是正确分类,也就是 w ∗ T y x {w^*}^Tyx w∗Tyx一定大于零。假设 γ → 0 \gamma\rightarrow 0 γ→0,则:
∥ w k ∥ 2 ≥ K 2 γ 2 \begin{aligned} \parallel w_k\parallel^2 &\geq K^2\gamma^2 \end{aligned} ∥wk∥2≥K2γ2
综上所述,得到:
K 2 γ 2 ≤ ∥ w k ∥ 2 ≤ K R 2 K^2\gamma^2\leq\parallel w_{k}\parallel^2\leq KR^2 K2γ2≤∥wk∥2≤KR2
则有:
K 2 γ 2 ≤ K R 2 K γ 2 ≤ R 2 K ≤ R 2 γ 2 \begin{aligned} K^2\gamma^2&\leq KR^2\\ K\gamma^2&\leq R^2\\ K&\leq\frac{R^2}{\gamma^2} \end{aligned} K2γ2Kγ2K≤KR2≤R2≤γ2R2