Prompt-to-Prompt Image Editing with Cross Attention Control (P2P)
Amir Hertz, Tel Aviv University, ICLR23, Paper, Code
1. 前言
编辑对这些生成模型来说是具有挑战性的,因为编辑技术的一个固有特性是保留大部分原始图像,而在基于文本的模型中,即使对文本提示进行微小修改,也往往会导致完全不同的结果 。现有技术的方法通过要求用户提供空间掩模来定位编辑,从而忽略掩模区域内的原始结构和内容来减轻这种情况。在本文中,我们追求一个直观的示编辑框架,其中编辑仅由文本控制 。为此,我们深入分析了一个文本条件模型,并观察到交叉注意力层是控制图像空间布局与提示中每个单词之间关系的关键。根据这一观察结果,我们提出了几个仅通过编辑文本提示来监控图像合成的应用程序。这包括通过替换单词进行本地化编辑,通过添加规范进行全局编辑,甚至精细地控制单词在图像中的反映程度。我们在不同的图像和提示上展示了我们的结果,展示了高质量的合成和对编辑提示的逼真度。
2. 整体思想
通常U-Net结构用Cross-Attention接入文本,再细致一点是Q来自扩散模型,K和V来自文本Prompt。在Cross-Attention中,细微的语义改变可能对采样有很大影响。本文希望固定背景和布局的语义,细微调整特定文字的语义。换句话说,本文微调Cross- Attention中的注意力图达到控制的目的。但是本文仅从Prompt出发,无法像Mask方法保证背景完全一致性,但从效果来看还是很好的。是值得细读的一篇文章。
3. 方法
设 I I I是由文本引导的扩散模型使用文本提示 P P P和随机种子 s s s生成的图像。我们的目标是编辑仅由编辑提示 P ∗ P^* P∗引导的输入图像,从而生成编辑图像 I ∗ I^* I∗。如果我们想固定种子,消除随机性,然后仅 通过改变文本来进行编辑,就会出现以下问题。

可以看到原始图片的结构和背景都被替换。本文的观察来自于交叉注意力的注意力图,这也是融合文本的地方。通过下图可以看到,如果固定了注意力图,那么的确可以达到较好的可编辑性。

注意力图在Cross-Attention中可以表示为:
M = s o f t m a x ( Q K T d ) M = softmax(\frac{QK^T}{\sqrt{d}}) M=softmax(d QKT)
其中, M i , j M_{i,j} Mi,j定义像素 i i i上的第 j j j个令牌的值的权重,并且其中 d d d是Keys和Queries的潜在投影维度。直观地说,交叉注意力输出 M V M V MV是值 V V V的加权平均值,其中权重是与 Q Q Q和 K K K之间的相似性相关的注意力图 M M M。在实践中,为了提高它们的表现力,并行使用多头注意力,然后将结果连接起来并通过学习的线性层来获得最终输出。
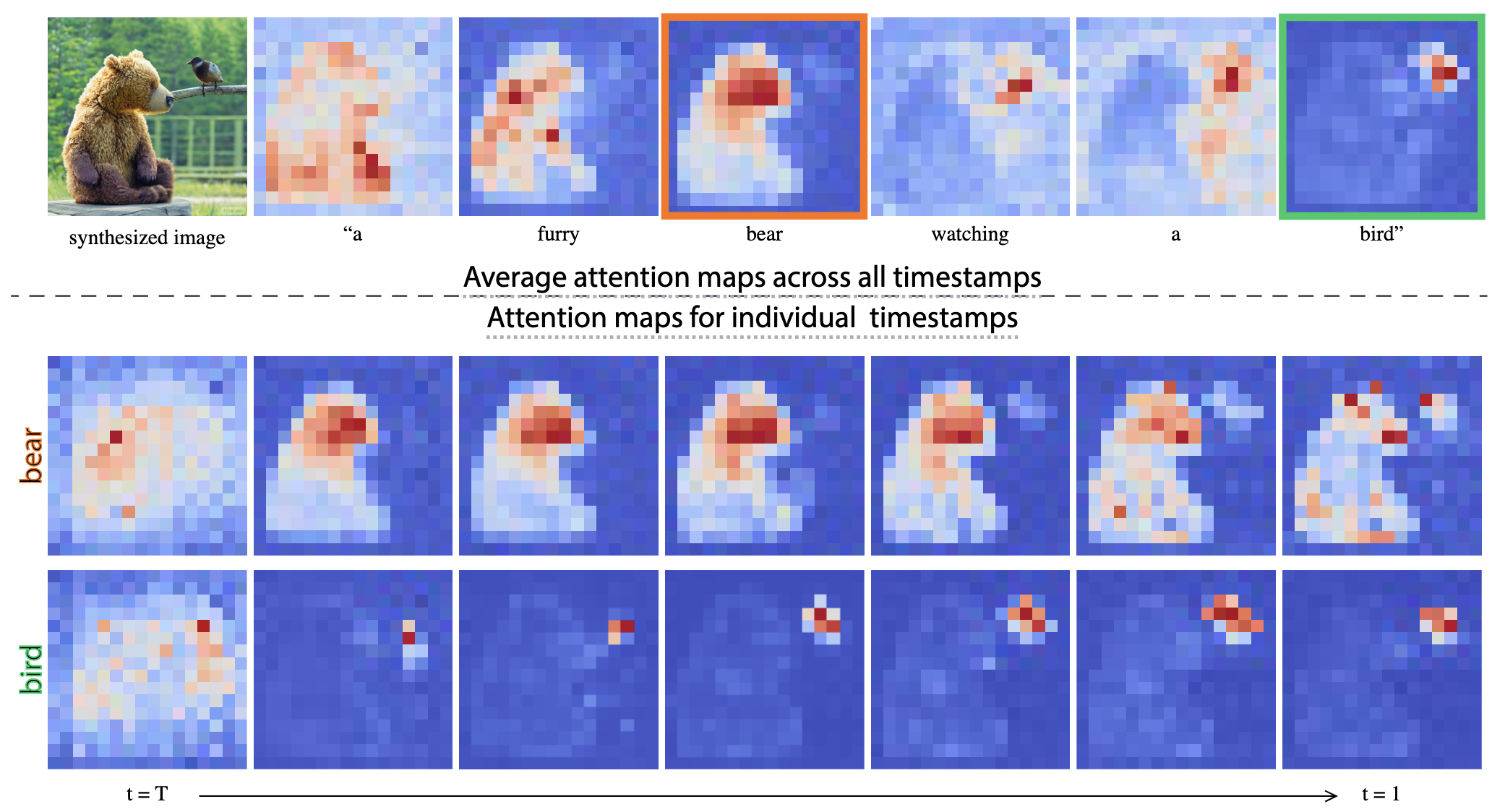
我们回到我们的关键观察点------生成图像的空间布局和几何结构取决于交叉注意力图。像素和文本之间的这种交互如下图所示,其中绘制了平均注意力图。可以看出,像素更容易被描述它们的单词所吸引,例如,熊的像素与单词"熊"相关。请注意,进行平均是为了可视化,在我们的方法中,每个头部的注意力图都是分开的。有趣的是,我们可以看到,图像的结构已经在扩散过程的早期步骤中确定。
设 D M ( z t , P , t , s ) DM(z_t,P,t,s) DM(zt,P,t,s)是扩散过程的单个步骤 t t t的计算,其输出噪声图像 z t − 1 z_{t−1} zt−1和注意力图 M t M_t Mt(如果不使用则省略)。我们用 D M ( z t , P , t , s ) { M ← o ~ M } DM(z_t,P,t,s)\{M←õM\} DM(zt,P,t,s){M←o~M}表示扩散步骤,在该步骤中,我们用额外的给定映射 M ^ \hat M M^覆盖注意力映射 M M M,但保持所提供提示的值 V V V。我们还用 M t ∗ M^*_t Mt∗表示使用编辑提示 P ∗ P^* P∗生成的注意力图。最后,我们将 E d i t ( M t , M t ∗ , t ) Edit(M_t,M^*_t,t) Edit(Mt,Mt∗,t)定义为一个通用的编辑函数,在原始图像和编辑图像的生成过程中接收它们的第 t t t个注意力图作为输入。
我们用于受控图像生成的通用算法包括同时对两个提示执行迭代扩散过程,其中根据所需的编辑任务在每个步骤中应用基于注意力的操作。我们注意到,为了使上述方法发挥作用,我们必须修复内部随机性。这是由于扩散模型的性质,即使对于相同的提示,两个随机种子也会产生截然不同的输出。形式上,我们的通用算法是:

这里其实就是把你想编辑的 P ∗ P^* P∗产生的注意力图替换或者修改原来 P P P的注意力图。图和替换或修改如下:
- 单词交换。例如, P P P="a big red bicycle"到 P ∗ P^* P∗="a big red car"。主要的挑战是在处理新提示的内容的同时保留原始组成 。为此,我们将源图像的注意力图注入到具有修改提示的生成中。然而,所提出的注意力注入可能会过度约束几何结构,尤其是当涉及大型结构修改时,如"汽车"到"自行车"。我们通过建议更温和的注意力约束来解决这一问题:
E d i t ( M t , M t ∗ , t ) : = { M t ∗ if t < τ M t otherwise Edit\left(M_{t}, M_{t}^{*}, t\right):=\left\{\begin{array}{ll} M_{t}^{*} & \text { if } t<\tau \\ M_{t} & \text { otherwise } \end{array}\right. Edit(Mt,Mt∗,t):={Mt∗Mt if t<τ otherwise
- 添加新短语。例如, P P P="a castle next to a river"到 P ∗ P^∗ P∗ ="children drawing of a castle next to a river"。为了保留共同的细节,我们只对来自两个提示的共同标记应用注意力注入。形式上,我们使用对齐函数A,该函数从目标提示 P ∗ P^* P∗接收令牌索引,并在不匹配的情况下输出相应的令牌索引inP或None。然后,编辑功能由下式给出:
( E d i t ( M t , M t ∗ , t ) ) i , j : = { ( M t ∗ ) i , j if A ( j ) = N o n e ( M t ) i , A ( j ) otherwise (Edit\left(M_{t}, M_{t}^{*}, t\right)){i,j}:=\left\{\begin{array}{ll} (M{t}^{*}){i,j} & \text { if } A(j)=None \\ (M{t})_{i,A(j)} & \text { otherwise } \end{array}\right. (Edit(Mt,Mt∗,t))i,j:={(Mt∗)i,j(Mt)i,A(j) if A(j)=None otherwise
- 注意力重新加权。例如,考虑提示 P P P="一个蓬松的红色球",并假设我们想使球或多或少蓬松。为了实现这种操作,我们用参数 c ∈ − 2 , 2 c∈−2,2 c∈−2,2缩放指定标记 j ∗ j^* j∗的注意力图,从而产生更强/更弱的效果。其余的注意力图保持不变。即:
( E d i t ( M t , M t ∗ , t ) ) i , j : = { c ( M t ) i , j if j = j ∗ ( M t ) i , A ( j ) otherwise (Edit\left(M_{t}, M_{t}^{*}, t\right)){i,j}:=\left\{\begin{array}{ll} c(M{t}){i,j} & \text { if } j=j^* \\ (M{t})_{i,A(j)} & \text { otherwise } \end{array}\right. (Edit(Mt,Mt∗,t))i,j:={c(Mt)i,j(Mt)i,A(j) if j=j∗ otherwise 
4. 实验

上图是通过不同数量的扩散步骤注入注意力。在顶部,我们显示源图像和提示。在每一行中,我们通过替换文本中的单个单词并注入源图像的交叉注意力图来修改图像的内容,该图的范围从0%(左侧)到100%(右侧)的扩散步骤。请注意,一方面,如果没有我们的方法,就不能保证保留任何源图像内容。另一方面,在所有扩散步骤中注入交叉注意力可能会过度约束几何结构,导致对文本提示的保真度较低,例如,汽车(第三排)变成了具有完全交叉注意力注入的自行车。
更多结果如下:



