文章目录
- 一、说明
- 二、GAN中的问题
-
- [2.1 难以实现纳什均衡(Nash equilibrium)](#2.1 难以实现纳什均衡(Nash equilibrium))
- [2.2 低维度支撑](#2.2 低维度支撑)
- [2.3 梯度消失](#2.3 梯度消失)
- [2.4 模式坍缩](#2.4 模式坍缩)
- [2.5 缺乏适当的评估指标](#2.5 缺乏适当的评估指标)
- 三、改进的GAN训练
- 四、瓦瑟斯坦(Wasserstein)WGAN
-
- [4.1 什么是 Wasserstein 距离?](#4.1 什么是 Wasserstein 距离?)
- [4.2 为什么 Wasserstein 优于 JS 或 KL 背离?](#4.2 为什么 Wasserstein 优于 JS 或 KL 背离?)
- [4.3 使用 Wasserstein 距离作为 GAN 损失函数](#4.3 使用 Wasserstein 距离作为 GAN 损失函数)
- [4.4 利普希茨连续性Lipschitz continuity?](#4.4 利普希茨连续性Lipschitz continuity?)
- 五、示例:创建新的口袋妖怪!
上篇文章: 从GAN到WGAN(01/2)
一、说明
生成对抗网络 (GAN) 在许多生成任务中显示出巨大的效果,以复制现实世界的丰富内容,如图像、人类语言和音乐。它的灵感来自博弈论:两个模型,一个生成器和一个批评家,在相互竞争的同时使彼此更强大。然而,训练GAN模型是相当具有挑战性的,因为人们面临着训练不稳定或收敛失败等问题。在这里,我想解释一下生成对抗网络框架背后的数学原理,为什么很难训练,最后介绍一个旨在解决训练难点的GAN修改版本。
二、GAN中的问题
尽管GAN在逼真的图像生成方面取得了巨大成功,但训练并不容易;众所周知,该过程缓慢且不稳定。
2.1 难以实现纳什均衡(Nash equilibrium)
Salimans等人(2016)讨论了GAN基于梯度下降的训练程序的问题。同时训练两个模型,以找到两人非合作博弈的纳什均衡。但是,每个模型都会独立更新其成本,而不考虑游戏中的其他玩家。同时更新两个模型的梯度并不能保证收敛( convergence)。
让我们看一个简单的例子,以更好地理解为什么在非合作博弈中很难找到纳什均衡。假设一个玩家通过x控制了最小化 f 1 ( x ) = x y f_1(x) = xy f1(x)=xy,同时其他玩家不断更新y最小化 f 2 ( y ) = − x y f_2(y) = -xy f2(y)=−xy.
因为 ∂ f 1 ∂ x = y \frac{\partial f_1}{\partial x} = y ∂x∂f1=y和 ∂ f 2 ∂ y = − x \frac{\partial f_2}{\partial y} = -x ∂y∂f2=−x,我们更新x为 x − y ∗ η x-y*\eta x−y∗η跟y改成 y + x ∗ η y+x*\eta y+x∗η在一次迭代中同时进行,其中 η \eta η是学习率。当x和y具有不同的正负号,每次梯度更新都会引起巨大的振荡,并且不稳定性会随着时间的推移而变得更糟,如图 3 所示。
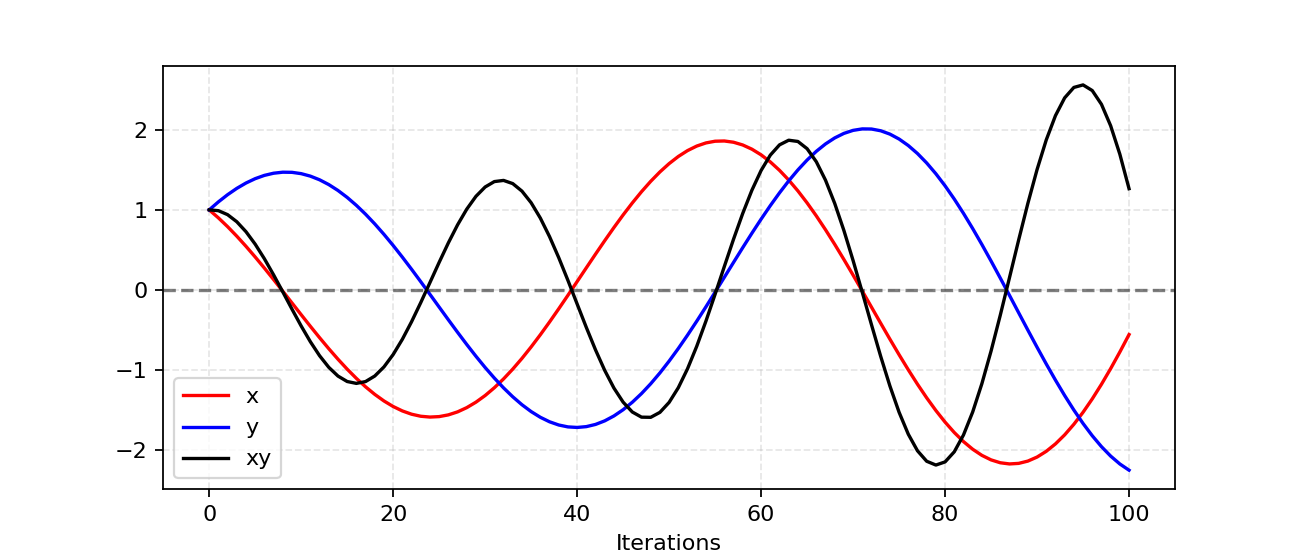
Fig. 3. A simulation of our example for updating x to minimize xy and updating y to minimize -xy . The learning rate η . With more iterations, the oscillation grows more and more unstable.
图 3. 更新 x 以最小化 xy 和更新 y 以最小化 -xy 的示例的模拟。学习率 η 。随着迭代次数的增加,振荡变得越来越不稳定。
2.2 低维度支撑
| 术语 | 解释 |
|---|---|
| 流形manifold | 局部类似于每个点附近的欧几里得空间的拓扑空间。确切地说,当这个欧几里得空间为尺寸,歧管称为n(n维) |
| 支持 | 实值函数是包含未映射到零的元素的域的子集。 |
Arjovsky 和 Bottou (2017) 讨论了 p r p_r pr和 p g p_g pg是基于低维度流场。在一篇非常理论化的论文"Towards principled methods for training generative adversarial networks"中,深入探讨了低维流形及其如何导致GAN训练的不稳定性。
许多现实世界数据集的维度,如 p r p_r pr,只是人为地显得很高。已发现它们集中在较低维的流形中。这实际上是流形学习的基本假设。想想现实世界的图像,一旦主题或包含的对象被固定下来,图像就有很多限制要遵循,例如狗应该有两只耳朵和一条尾巴,摩天大楼应该有笔直高大的身体等。这些限制使图像远离具有高维自由形式的可能性。
概率分布 p g p_g pg 也位于低维流形内。当生成器从小维输入(例如 100 维噪声变量 z z z)创建更大的图像(例如 64x64)时,4096 个像素上的颜色分布受到 100 维向量的约束,并且很难填充整个图像高维空间。
因为 p r p_r pr 和 p g p_g pg 都位于低维流形中,所以它们几乎肯定是不相交的(见图 4)。当它们具有不相交的支持时,我们总是能够找到一个完美的判别器,能够 100% 正确地区分真实和虚假样本。如果您对证明感到好奇,请检查论文。
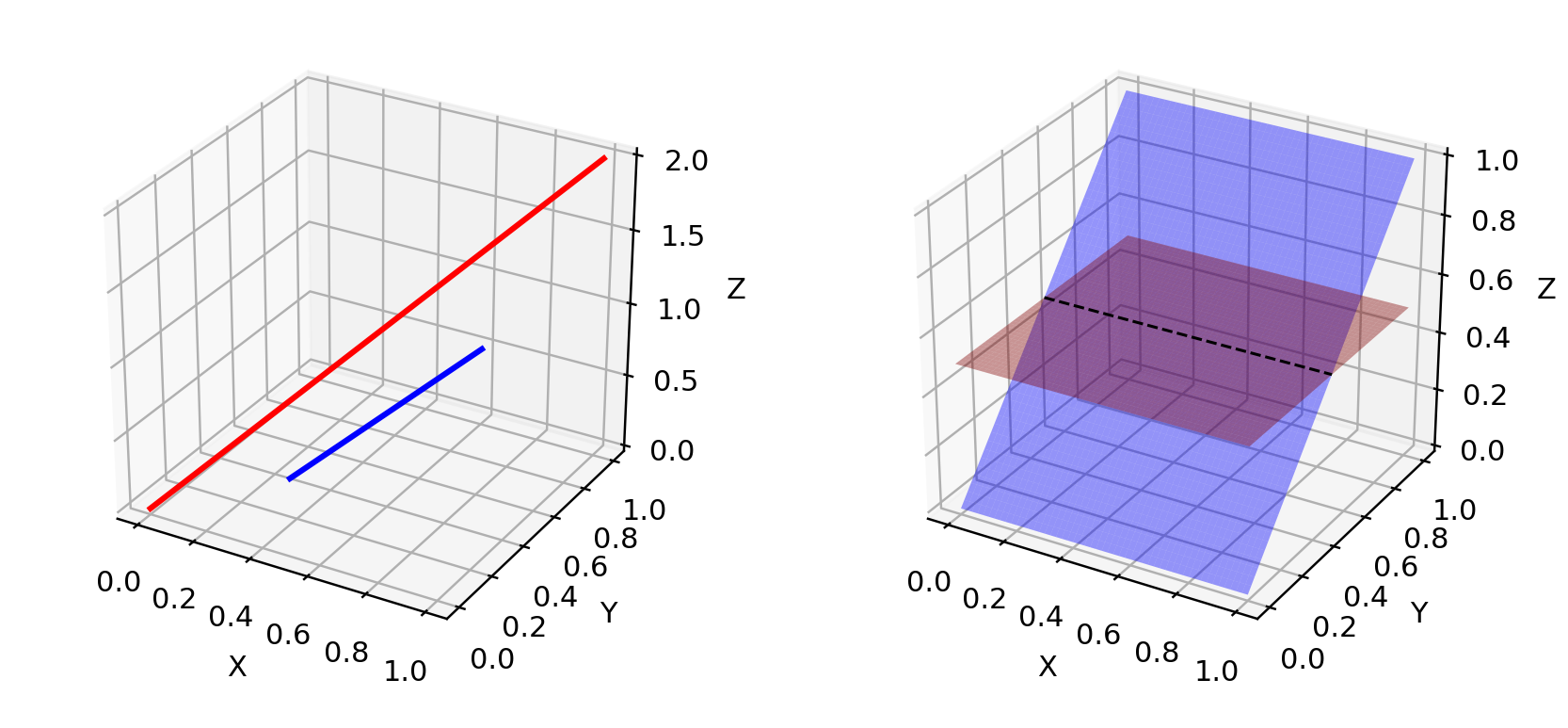 Fig. 4. Low dimensional manifolds in high dimension space can hardly have overlaps. (Left) Two lines in a three-dimension space. (Right) Two surfaces in a three-dimension space.
Fig. 4. Low dimensional manifolds in high dimension space can hardly have overlaps. (Left) Two lines in a three-dimension space. (Right) Two surfaces in a three-dimension space.
图 4.高维空间中的低维流形几乎不可能有重叠。(左)三维空间中的两条线。(右)三维空间中的两个表面。
2.3 梯度消失
当判别器完美时,我们保证 D ( x ) = 1 , ∀ x ∈ p r D(x) = 1, \forall x \in p_r D(x)=1,∀x∈pr 和 D ( x ) = 0 , ∀ x ∈ p g D(x) = 0, \forall x \in p_g D(x)=0,∀x∈pg。因此,损失函数 L L L 降至零,并且我们最终在学习迭代期间没有梯度来更新损失。图 5 展示了一个实验,当判别器变得更好时,梯度很快消失。
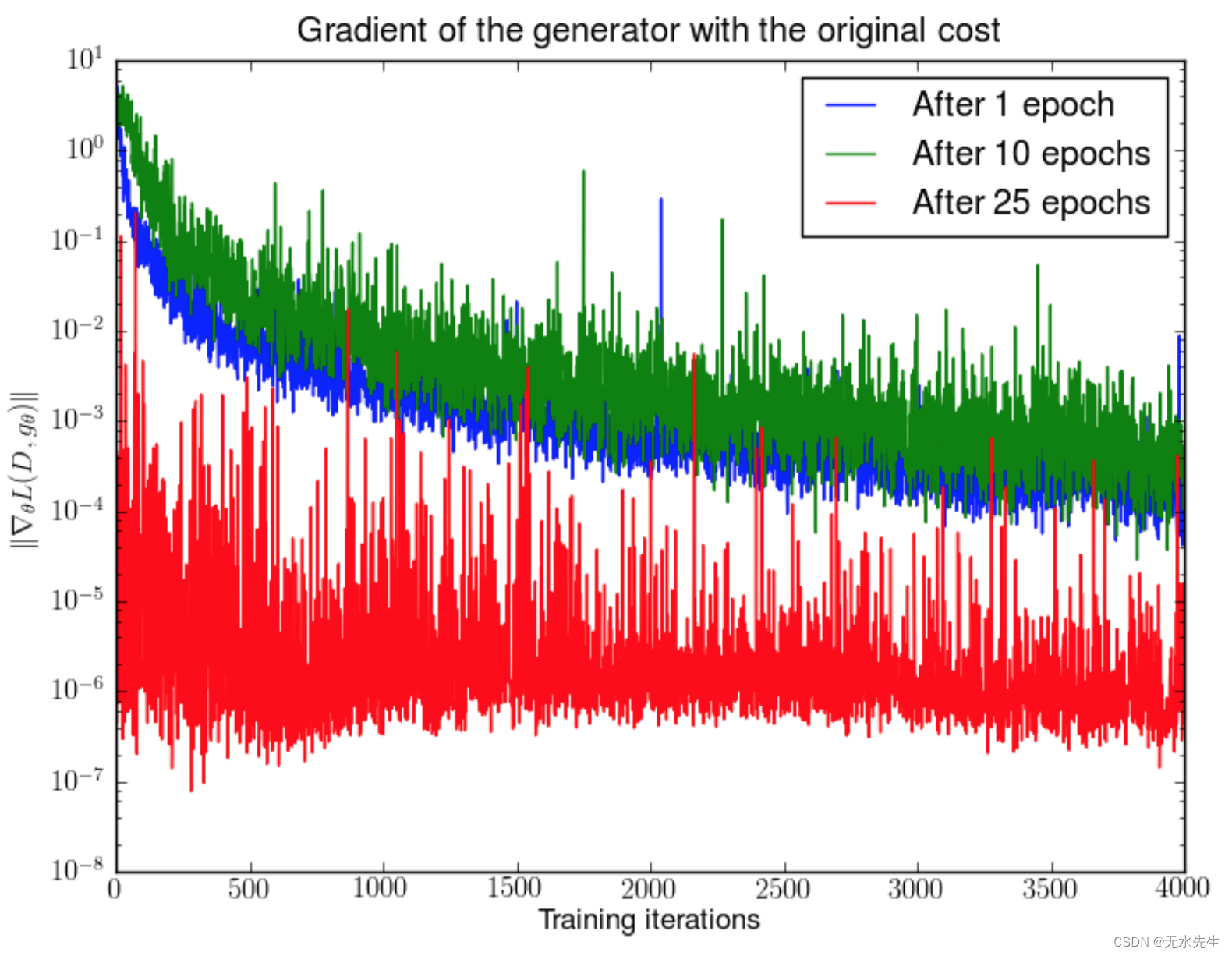 Fig. 5. First, a DCGAN is trained for 1, 10 and 25 epochs. Then, with the generator fixed , a discriminator is trained from scratch and measure the gradients with the original cost function. We see the gradient norms decay quickly (in log scale), in the best case 5 orders of magnitude after 4000 discriminator iterations. (Image source: Arjovsky and Bottou, 2017)
Fig. 5. First, a DCGAN is trained for 1, 10 and 25 epochs. Then, with the generator fixed , a discriminator is trained from scratch and measure the gradients with the original cost function. We see the gradient norms decay quickly (in log scale), in the best case 5 orders of magnitude after 4000 discriminator iterations. (Image source: Arjovsky and Bottou, 2017)
图 5.首先,DCGAN 训练了 1、10 和 25 个周期。然后,在生成器固定 的情况下,从头开始训练判别器,并使用原始成本函数测量梯度。我们看到梯度范数 衰减迅速(以对数刻度为单位),在最佳情况下,经过 4000 次鉴别器迭代后,梯度范数为 5 个数量级。(图片来源:Arjovsky 和 Bottou,2017 年)
因此,训练GAN面临两难境地:
- 如果鉴别器行为不当,则生成器没有准确的反馈,损失函数无法代表现实。
- 如果判别器做得很好,损失函数的梯度就会下降到接近零,学习会变得非常慢,甚至卡住。
这种困境显然能够使GAN训练变得非常艰难。
2.4 模式坍缩
在训练期间,发生器可能会崩溃到始终产生相同输出的设置。这是 GAN 的常见故障情况,通常称为模式崩溃。尽管生成器可能能够欺骗相应的鉴别器,但它无法学会表示复杂的真实世界数据分布,并且被困在一个变化极低的小空间中。

Fig. 6. A DCGAN model is trained with an MLP network with 4 layers, 512 units and ReLU activation function, configured to lack a strong inductive bias for image generation. The results shows a significant degree of mode collapse. (Image source: Arjovsky, Chintala, & Bottou, 2017.)
图 6.DCGAN 模型使用具有 4 层、512 个单元和 ReLU 激活函数的 MLP 网络进行训练,该网络配置为缺乏用于图像生成的强感应偏差。结果显示,模式坍塌程度显著。(图片来源:Arjovsky,Chintala和Bottou,2017。)
2.5 缺乏适当的评估指标
生成对抗网络并不是天生就有一个很好的反对函数,可以告诉我们训练进度。没有一个好的评估指标,就像在黑暗中工作一样。没有好的迹象可以告诉何时停止;没有好的指标来比较多个模型的性能。
三、改进的GAN训练
提出以下建议,以帮助稳定和改进GAN的训练。
前五种方法是在"改进GAN训练技术"中提出的实现GAN训练更快收敛的实用技术。 在"Towards principled methods for training generative adversarial networks"中提出了后两种方法,以解决不相交分布的问题。
(1) 功能匹配
特征匹配建议优化鉴别器,以检查生成器的输出是否与实际样本的预期统计量匹配。在这种情况下,新的损失函数定义为 ∣ E x ∼ p r f ( x ) − E z ∼ p z ( z ) f ( G ( z ) ) ∣ 2 2 | \mathbb{E}{x \sim p_r} f(x) - \mathbb{E}{z \sim p_z(z)}f(G(z)) |_2^2 ∣Ex∼prf(x)−Ez∼pz(z)f(G(z))∣22这里, f ( x ) f(x) f(x)可以是特征统计量的任意计算,例如均值或中位数。
(2) 小批量鉴别
在一个小批量中,我们近似每对样本之间的接近度, c ( x i , x j ) c(x_i, x_j) c(xi,xj),并通过总结一个数据点与同一批次中其他样本的接近程度来获得一个数据点的整体摘要, o ( x i ) = ∑ j c ( x i , x j ) o( x_i) = \sum_{j} c(x_i, x_j) o(xi)=∑jc(xi,xj)
。然后 o ( x i ) o(x_i) o(xi) 被显式添加到模型的输入中。
(3) 历史平均
对于这两种模型,添加 ∣ Θ − 1 t ∑ i = 1 t Θ i ∣ 2 | \Theta - \frac{1}{t} \sum_{i=1}^t \Theta_i |^2 ∣Θ−t1∑i=1tΘi∣2 进入损失函数,其中 Θ \Theta Θ 是模型参数, Θ i \Theta_i Θi 是在过去的训练时间 i i i 中参数的配置方式。当 Θ \Theta Θ 时,这个附加部分会惩罚训练速度时间变化太剧烈了。
(4) 单侧标签平滑
在输入鉴别器时,不要提供 1 和 0 标签,而是使用 0.9 和 0.1 等软化值。它被证明可以减少网络的脆弱性。
(5) 虚拟批量规范化 (VBN)
每个数据样本都基于固定批次("参考批次")的数据进行归一化,而不是在其小批量中进行归一化。参考批次在开始时选择一次,并在整个训练过程中保持不变。
Theano 实现:openai/improved-gan
(6) 添加噪音。
根据上一节的讨论,我们现在知道了 p r p_r pr和 p g p_g pg在高维空间中是不相交的,这会导致梯度消失的问题。为了人为地"分散"分布,并为两个概率分布创造更高的重叠机会,一种解决方案是在判别器的输入上添加连续噪声D
.
(7)使用更好的分布相似度指标
香草 GAN 的损失函数测量 p r p_r pr和 p g p_g pg.当两个分布不相交时,此指标无法提供有意义的值。
Wasserstein 度量被提议取代 JS 散度,因为它具有更平滑的值空间。在下一节中查看更多内容。
四、瓦瑟斯坦(Wasserstein)WGAN
4.1 什么是 Wasserstein 距离?
Wasserstein 距离是两个概率分布之间距离的度量。 它也被称为推土机距离,是 EM 距离的缩写,因为它可以非正式地解释为以一种概率分布的形状移动和转换一堆泥土到另一种分布形状的最小能量成本。成本的量化公式为:移动的污垢量 x 移动距离。
让我们首先看一个简单的情况,其中概率域是离散的。例如,假设我们有两个分布P和Q,每个都有四堆泥土,总共有十铲泥土。每个土堆中的铲子数量分配如下:
P 1 = 3 , P 2 = 2 , P 3 = 1 , P 4 = 4 Q 1 = 1 , Q 2 = 2 , Q 3 = 4 , Q 4 = 3 P_1 = 3, P_2 = 2, P_3 = 1, P_4 = 4\\ Q_1 = 1, Q_2 = 2, Q_3 = 4, Q_4 = 3 P1=3,P2=2,P3=1,P4=4Q1=1,Q2=2,Q3=4,Q4=3
为了改变P看起来像Q,如图 7 所示,我们:
- 第一次移动 2 铲子从 P 1 P_1 P1 到 P 2 P_2 P2 = > ( P 1 , Q 1 ) => (P_1, Q_1) =>(P1,Q1)相配
- 第二次移动 2 铲子从自 P 2 P_2 P2 到 P 3 P_3 P3 = > ( P 2 , Q 3 ) => (P_2, Q_3) =>(P2,Q3)相配。
- 最后从中移动 1 铲子自 Q 3 Q_3 Q3 到 Q 4 Q_4 Q4, = > ( P 3 , Q 3 ) => (P_3, Q_3) =>(P3,Q3)和 = > ( P 4 , Q 4 ) => (P_4, Q_4) =>(P4,Q4)相配。
如果我们贴上标签,要支付的成本要使 P i P_i Pi和 Q i Q_i Qi匹配为 δ i \delta_i δi;我们会有 δ i + 1 = δ i + P i − Q i \delta_{i+1} = \delta_i + P_i - Q_i δi+1=δi+Pi−Qi,在示例中:
δ 0 = 0 δ 1 = 0 + 3 − 1 = 2 δ 2 = 2 + 2 − 2 = 2 δ 3 = 2 + 1 − 4 = − 1 δ 4 = − 1 + 4 − 3 = 0 \begin{aligned} \delta_0 &= 0\\ \delta_1 &= 0 + 3 - 1 = 2\\ \delta_2 &= 2 + 2 - 2 = 2\\ \delta_3 &= 2 + 1 - 4 = -1\\ \delta_4 &= -1 + 4 - 3 = 0 \end{aligned} δ0δ1δ2δ3δ4=0=0+3−1=2=2+2−2=2=2+1−4=−1=−1+4−3=0
最后,推土机的距离是 W = ∑ ∣ δ i ∣ = 5 W = \sum \vert \delta_i \vert = 5 W=∑∣δi∣=5
.
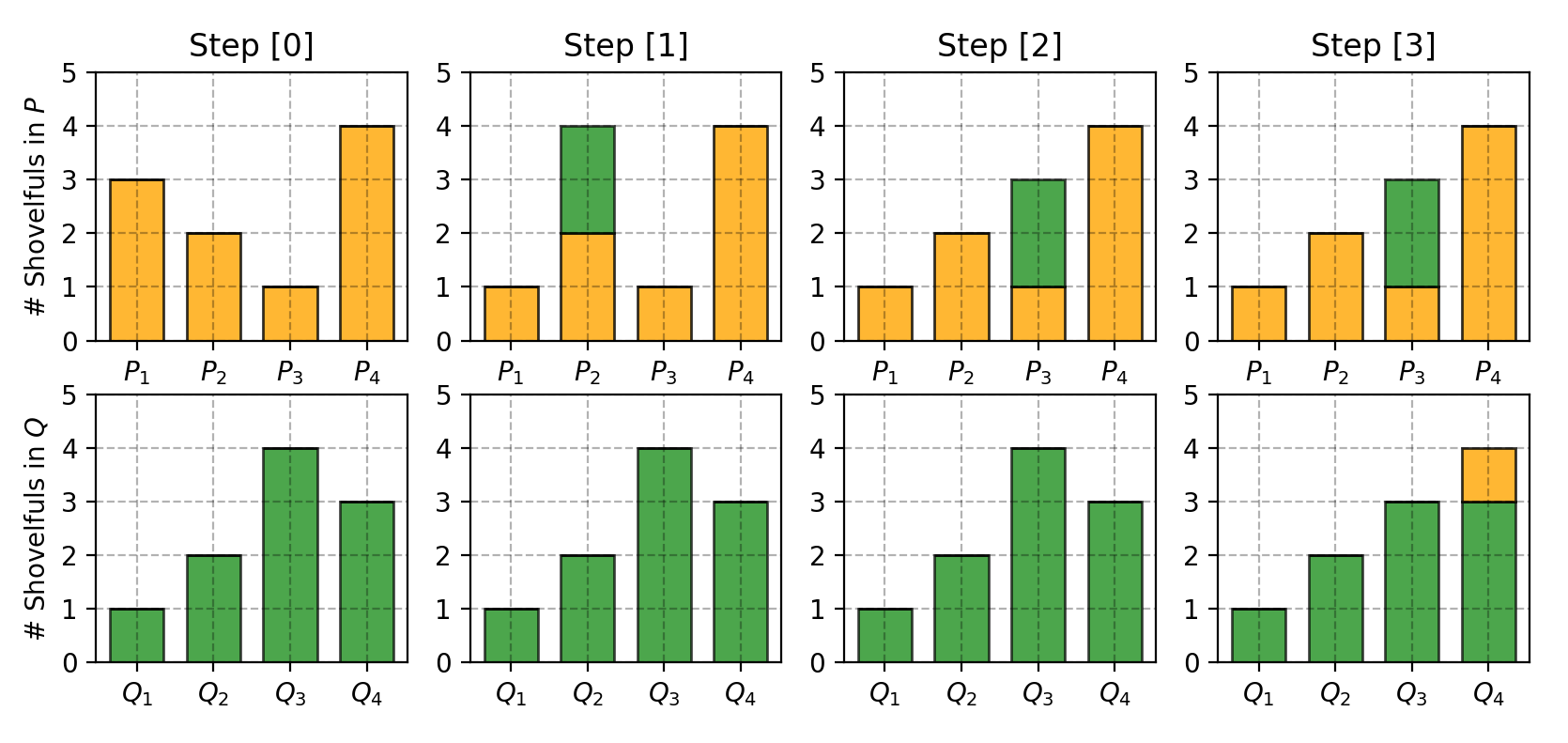 Fig. 7. Step-by-step plan of moving dirt between piles in P and Q to make them match.
Fig. 7. Step-by-step plan of moving dirt between piles in P and Q to make them match.
图 7.在桩之间移动泥土的分步计划P和Q使它们匹配。
在处理连续概率域时,距离公式变为:
W ( p r , p g ) = inf γ ∼ Π ( p r , p g ) E ( x , y ) ∼ γ ∥ x − y ∥ W(p_r, p_g) = \inf_{\gamma \sim \Pi(p_r, p_g)} \mathbb{E}_{(x, y) \sim \gamma}\\\| x-y \\\| W(pr,pg)=infγ∼Π(pr,pg)E(x,y)∼γ∥x−y∥
上式中, Π ( p r , p g ) \Pi(p_r, p_g) Π(pr,pg)表示 p r p_r pr和 p g p_g pg之间所有可能的联合概率分布的集合。特定的联合分布 γ ∈ Π ( p r , p g ) \gamma \in \Pi(p_r, p_g) γ∈Π(pr,pg) 概述了污垢运输计划,类似于离散示例,但在连续概率空间内。具体来说, γ ( x , y ) \gamma(x, y) γ(x,y)表示从点 x x x输送到点 y y y的污垢比例,确保 y y y的分布保持一致。因此, x x x 上的边际分布总计为 p g p_g pg,表示为 ∑ x γ ( x , y ) = p g ( y ) \sum_{x} \gamma(x, y) = p_g(y) ∑xγ(x,y)=pg(y),这意味着在从所有可能的地方运输了计划数量的污垢之后 x x x 到给定的 y y y,结果与 y y y 处的分布 p g p_g pg 匹配。相反, y y y 的总和得到 ∑ y γ ( x , y ) = p r ( x ) \sum_{y} \gamma(x, y) = p_r(x) ∑yγ(x,y)=pr(x)。
具体处理时 x x x 作为起点, y y y 作为目的地,移动的泥土总量为 γ ( x , y ) \gamma(x, y) γ(x,y),行进距离为 ∣ x − y ∣ | x-y | ∣x−y∣ 因此成本是 γ ( x , y ) ⋅ ∣ x − y ∣ \gamma(x, y) \cdot | x-y | γ(x,y)⋅∣x−y∣。所有 ( x , y ) (x,y) (x,y) 的平均预期成本 对可以很容易地计算为:
∑ x , y γ ( x , y ) ∥ x − y ∥ = E x , y ∼ γ ∥ x − y ∥ \sum_{x, y} \gamma(x, y) \| x-y \| = \mathbb{E}_{x, y \sim \gamma} \| x-y \| x,y∑γ(x,y)∥x−y∥=Ex,y∼γ∥x−y∥
最后,我们将所有污垢移动解决方案的成本中最小的一个作为 EM 距离。在 Wasserstein 距离的定义中,inf (infimum,也称为最大下限)表示我们只对最小的成本感兴趣。
4.2 为什么 Wasserstein 优于 JS 或 KL 背离?
即使两个分布位于没有重叠的低维流形中,Wasserstein 距离仍然可以提供有意义且平滑的表示之间的距离。
WGAN的论文用一个简单的例子来说明这个想法。
假设我们有两个概率分布,P和Q:
∀ ( x , y ) ∈ P , x = 0 and y ∼ U ( 0 , 1 ) ∀ ( x , y ) ∈ Q , x = θ , 0 ≤ θ ≤ 1 and y ∼ U ( 0 , 1 ) \forall (x, y) \in P, x = 0 \text { and } y \sim U(0, 1) \forall (x, y) \in Q, x = \theta, 0 \leq \theta \leq 1 \text{ and } y \sim U(0, 1) ∀(x,y)∈P,x=0 and y∼U(0,1)∀(x,y)∈Q,x=θ,0≤θ≤1 and y∼U(0,1)
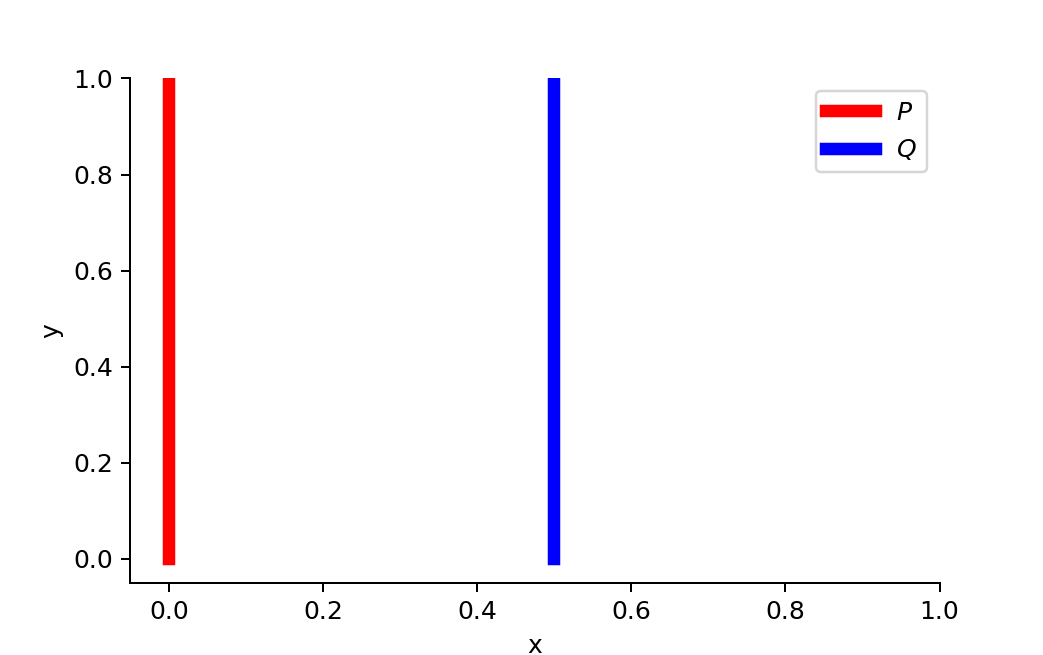
图 8.两者之间没有重叠P和Q,在θ≠0
当 θ ≠ 0 \theta \neq 0 θ=0时:
D K L ( P ∥ Q ) = ∑ x = 0 , y ∼ U ( 0 , 1 ) 1 ⋅ log 1 0 = + ∞ D K L ( Q ∥ P ) = ∑ x = θ , y ∼ U ( 0 , 1 ) 1 ⋅ log 1 0 = + ∞ D J S ( P , Q ) = 1 2 ( ∑ x = 0 , y ∼ U ( 0 , 1 ) 1 ⋅ log 1 1 / 2 + ∑ x = 0 , y ∼ U ( 0 , 1 ) 1 ⋅ log 1 1 / 2 ) = log 2 W ( P , Q ) = ∣ θ ∣ \begin{aligned} D_{KL}(P \| Q) &= \sum_{x=0, y \sim U(0, 1)} 1 \cdot \log\frac{1}{0} = +\infty \\ D_{KL}(Q \| P) &= \sum_{x=\theta, y \sim U(0, 1)} 1 \cdot \log\frac{1}{0} = +\infty \\ D_{JS}(P, Q) &= \frac{1}{2}(\sum_{x=0, y \sim U(0, 1)} 1 \cdot \log\frac{1}{1/2} + \sum_{x=0, y \sim U(0, 1)} 1 \cdot \log\frac{1}{1/2}) = \log 2\\ W(P, Q) &= |\theta| \end{aligned} DKL(P∥Q)DKL(Q∥P)DJS(P,Q)W(P,Q)=x=0,y∼U(0,1)∑1⋅log01=+∞=x=θ,y∼U(0,1)∑1⋅log01=+∞=21(x=0,y∼U(0,1)∑1⋅log1/21+x=0,y∼U(0,1)∑1⋅log1/21)=log2=∣θ∣
但当 θ = 0 \theta = 0 θ=0,两个分布完全重叠:
D K L ( P ∥ Q ) = D K L ( Q ∥ P ) = D J S ( P , Q ) = 0 W ( P , Q ) = 0 = ∣ θ ∣ \begin{aligned} D_{KL}(P \| Q) &= D_{KL}(Q \| P) = D_{JS}(P, Q) = 0\\ W(P, Q) &= 0 = \lvert \theta \rvert \end{aligned} DKL(P∥Q)W(P,Q)=DKL(Q∥P)=DJS(P,Q)=0=0=∣θ∣
当两个分布不相交时, D K L D_{KL} DKL 给我们无穷大。 D J S D_{JS} DJS 的值突然跳跃,在 θ = 0 \theta = 0 θ=0 处不可微分。只有 Wasserstein 度量提供了平滑的度量,这对于使用梯度下降的稳定学习过程非常有帮助。
4.3 使用 Wasserstein 距离作为 GAN 损失函数
穷尽 Π ( p r , p g ) \Pi(p_r, p_g) Π(pr,pg) 中所有可能的联合分布来计算 inf γ ∼ Π ( p r , p g ) \inf_{\gamma \sim \Pi(p_r, p_g)} infγ∼Π(pr,pg) 是很困难的。因此,作者提出了基于 Kantorovich-Rubinstein 对偶性的公式的巧妙转换:
W ( p r , p g ) = 1 K sup ∥ f ∥ L ≤ K E x ∼ p r f ( x ) − E x ∼ p g f ( x ) W(p_r, p_g) = \frac{1}{K} \sup_{\| f \|L \leq K} \mathbb{E}{x \sim p_r}f(x) - \mathbb{E}_{x \sim p_g}f(x) W(pr,pg)=K1∥f∥L≤KsupEx∼prf(x)−Ex∼pgf(x)
在这里 sup(supremum)与inf(infimum)相反;我们想要测量最小上限,或者更简单地说,最大值。
4.4 利普希茨连续性Lipschitz continuity?
函数 f f f在Wasserstein度量的新形式中,要求满足 ∣ f ∣ L ≤ K | f |_L \leq K ∣f∣L≤K,这意味着它应该是 K-Lipschitz 连续的。
实值函数 f : R → R f: \mathbb{R} \rightarrow \mathbb{R} f:R→R被称为K-Lipschitz 连续,如果存在实常数 K ≥ 0 K \geq 0 K≥0,这样,对于所有 x 1 , x 2 ∈ R x_1, x_2 \in \mathbb{R} x1,x2∈R,
∣ f ( x 1 ) − f ( x 2 ) ∣ ≤ K ∣ x 1 − x 2 ∣ \lvert f(x_1) - f(x_2) \rvert \leq K \lvert x_1 - x_2 \rvert ∣f(x1)−f(x2)∣≤K∣x1−x2∣
这里K被称为函数 f ( ⋅ ) f(\cdot) f(⋅)的 Lipschitz 常数.随处可微的函数是 Lipschitz 连续的,有界限。导数估计为 ∣ f ( x 1 ) − f ( x 2 ) ∣ ∣ x 1 − x 2 ∣ \frac{\lvert f(x_1) - f(x_2) \rvert}{\lvert x_1 - x_2 \rvert} ∣x1−x2∣∣f(x1)−f(x2)∣,然而,Lipschitz 连续函数可能不是在所有地方都是可微的,例如 f ( x ) = ∣ x ∣ f(x) = \lvert x \rvert f(x)=∣x∣.
解释变换是如何在 Wasserstein 距离公式上发生的,这本身就值得写一篇长文,所以在这里跳过了细节。如果您对如何使用线性规划计算 Wasserstein 度量感兴趣,或者如何根据 Kantorovich-Rubinstein 对偶性将 Wasserstein 度量转换为其对偶形式,请阅读这篇很棒的文章。
假设这个函数 f f f来自 K-Lipschitz 连续函数家族, { f w } w ∈ W \{ f_w \}{w \in W} {fw}w∈W,参数化为 w w w.在改进的 Wasserstein-GAN 中,"鉴别器"模型用于学习 w w w,找到一个好的 f w f_w fw;损失函数配置为测量Wasserstein 之间的距离 p r p_r pr和 p g p_g pg.
L ( p r , p g ) = W ( p r , p g ) = max w ∈ W E x ∼ p r f w ( x ) − E z ∼ p r ( z ) f w ( g θ ( z ) ) L(p_r, p_g) = W(p_r, p_g) = \max{w \in W} \mathbb{E}{x \sim p_r}f_w(x) - \mathbb{E}{z \sim p_r(z)}f_w(g_\\theta(z)) L(pr,pg)=W(pr,pg)=w∈WmaxEx∼prfw(x)−Ez∼pr(z)fw(gθ(z))
因此,"鉴别者"不再是将假样本与真样本区分开来的直接批评者。相反,它被训练来学习K-Lipschitz 连续函数,用于帮助计算 Wasserstein 距离。随着训练中损失函数的减小,Wasserstein 距离变小,生成器模型的输出越来越接近真实数据分布。
一个大问题是维护K-Lipschitz 连续性 f w f_w fw在培训期间,以使一切顺利。论文提出了一个简单但非常实用的技巧:每次梯度更新后,将权重 w 钳制到一个小窗口,例如 − 0.01 , 0.01 -0.01, 0.01 −0.01,0.01,从而得到紧凑的参数空间 W 和 f w f_w fw 由此获得其下限和上限以保持 Lipschitz 连续性。

图 9.Wasserstein 生成对抗网络算法.(图片来源:Arjovsky,Chintala和Bottou,2017。)
与原始GAN算法相比,WGAN进行了以下更改:
- 每次对批评函数进行梯度更新后,将权重限制在一个小的固定范围 − c , c -c,c −c,c 内。
- 使用从 Wasserstein 距离导出的新损失函数,不再使用对数。 "判别器"模型并不是直接批评者,而是估计真实数据分布和生成数据分布之间的 Wasserstein 度量的帮助者。
- 根据经验,作者推荐批评家使用 RMSProp 优化器,而不是基于动量的优化器(例如 Adam),后者可能会导致模型训练不稳定。我还没有看到关于这一点的明确的理论解释。
可悲的是,Wasserstein GAN 并不完美。甚至原始WGAN论文的作者也提到"权重削波显然是强制执行Lipschitz约束的一种可怕方式"(哎呀!WGAN仍然受到训练不稳定、权重削波后收敛缓慢(当剪切窗口太大时)和梯度消失(当剪切窗口太小时)的问题。
Gulrajani 等人,2017 年讨论了一些改进,即用梯度惩罚精确地替换权重削波。我会把它留到以后的帖子。
五、示例:创建新的口袋妖怪!
只是为了好玩,我在一个小数据集 Pokemon sprites 上尝试了 carpedm20/DCGAN-tensorflow。该数据集只有 900 多张口袋妖怪图像,包括不同级别的相同口袋妖怪物种。
让我们看看该模型能够创建哪些类型的新口袋妖怪。 不幸的是,由于训练数据很小,新的口袋妖怪只有粗糙的形状,没有细节。随着训练时间的增加,形状和颜色确实看起来更好!万岁!

图 10.在一组口袋妖怪精灵图像上训练 carpedm20/DCGAN-tensorflow。在训练周期 = 7、21、49 之后列出示例输出。
如果您对 carpedm20/DCGAN-tensorflow 的注释版本以及如何修改它以训练 WGAN 和具有梯度惩罚的 WGAN 感兴趣,请查看 lilianweng/unified-gan-tensorflow。
被引用为:
python
@article{weng2017gan,
title = "From GAN to WGAN",
author = "Weng, Lilian",
journal = "lilianweng.github.io",
year = "2017",
url = "https://lilianweng.github.io/posts/2017-08-20-gan/"
}或
python
@misc{weng2019gan,
title={From GAN to WGAN},
author={Lilian Weng},
year={2019},
eprint={1904.08994},
archivePrefix={arXiv},
primaryClass={cs.LG}
}引用
1 Goodfellow, Ian, et al. "生成对抗网络"。NIPS,2014 年。
2 蒂姆·萨利曼斯(Tim Salimans)等人,"训练gans的改进技术"。NIPS 2016。
3 马丁·阿约夫斯基(Martin Arjovsky)和莱昂·博图(Léon Bottou)。"朝着训练生成对抗网络的原则性方法迈进。"arXiv 预印本 arXiv:1701.04862 (2017)。
4 马丁·阿约夫斯基、苏米特·钦塔拉和莱昂·博图。"Wasserstein GAN。"arXiv 预印本 arXiv:1701.07875 (2017)。
5 伊沙恩·古拉贾尼、法鲁克·艾哈迈德、马丁·阿约夫斯基、文森特·杜穆林、亚伦·库尔维尔。改进了 wasserstein gans 的培训。arXiv 预印本 arXiv:1704.00028 (2017)。
6 计算变换下的地球移动器距离
7 Wasserstein GAN 和 Kantorovich-Rubinstein 二元性
8 zhuanlan.zhihu.com/p/25071913
9 费伦茨·胡扎尔."如何(不)训练你的生成模型:计划采样、可能性、对手?。"arXiv 预印本 arXiv:1511.05101 (2015)。