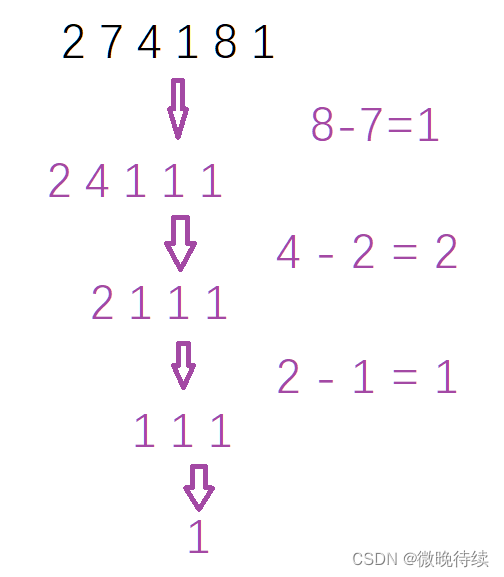
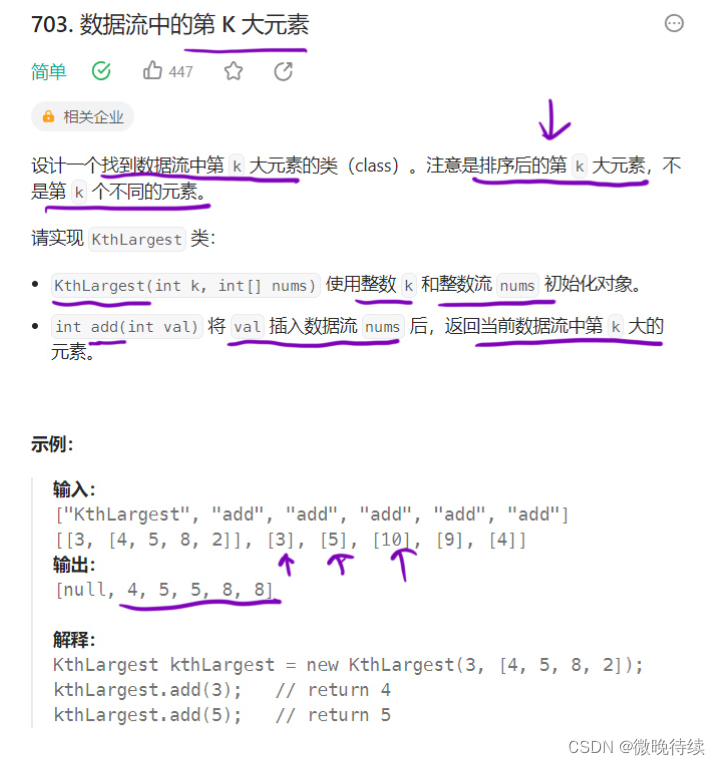
class Solution {
public int lastStoneWeight(int[] stones) {
//1、创建一个大根堆
PriorityQueue<Integer> heap = new PriorityQueue<>((a,b) -> b-a);
//2、把所有的石头放进堆里里面
for(int x :stones){
heap.offer(x);
}
//3、模拟
while(heap.size()>1){
int a = heap.poll();
int b = heap.poll();
if(a > b ){
heap.offer(a-b);
}
}
return heap.isEmpty()?0:heap.peek();
}
}
class KthLargest {
PriorityQueue<Integer> heap;
int k1;
public KthLargest(int k, int[] nums) {
k1 = k;
heap = new PriorityQueue<>();
for(int x : nums){
heap.offer(x);
if(heap.size() > k1){
heap.poll();
}
}
}
public int add(int val) {
heap.offer(val);
if(heap.size() > k1){
heap.poll();
}
return heap.peek();
}
}
/**
* Your KthLargest object will be instantiated and called as such:
* KthLargest obj = new KthLargest(k, nums);
* int param_1 = obj.add(val);
*/