目录
效果一览
基本介绍
Adaboost集成学习 | Matlab实现基于CNN-LSTM-Adaboost集成学习时间序列预测(股票价格预测)
模型设计
融合Adaboost的CNN-LSTM模型的时间序列预测,下面是一个基本的框架。
数据准备:
收集并整理用于时间序列预测的数据集。确保数据集包含时间序列的输入特征和对应的目标变量。
划分数据集为训练集和测试集,一般按照时间顺序划分。
单个模型训练:
使用CNN-LSTM模型对时间序列数据进行预测。
Adaboost集成:
将CNN-LSTM的预测结果作为特征输入到Adaboost算法中。
将预测结果作为Adaboost的训练样本标签,并为每个样本分配一个权重。
训练Adaboost模型,通过迭代选择最佳的基分类器,并更新样本权重。
模型预测:
对测试集中的时间序列数据,使用已训练的Adaboost模型进行预测,得到最终的时间序列预测结果。
模型评估:
使用测试集对集成模型进行评估,计算预测结果与真实值之间的误差指标,如均方根误差(RMSE)或平均绝对误差(MAE)。
程序设计
- 完整程序订阅专栏Adaboost集成学习后获取。
matlab
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc
%% 导入数据
data = readmatrix('Price.xlsx');
[h1,l1]=data_process(data,6); %步长为6,采用前6个时刻预测第7个时刻
res = [h1,l1];
num_samples = size(res,1); %样本个数
% 训练集和测试集划分
outdim = 1; % 最后一列为输出
num_size = 0.7; % 训练集占数据集比例
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
layers0 = [ ...
% 输入特征
sequenceInputLayer([numFeatures,1,1],'name','input') %输入层设置
sequenceFoldingLayer('name','fold') %使用序列折叠层对图像序列的时间步长进行独立的卷积运算。
% CNN特征提取
convolution2dLayer([3,1],16,'Stride',[1,1],'name','conv1') %添加卷积层,64,1表示过滤器大小,10过滤器个数,Stride是垂直和水平过滤的步长
batchNormalizationLayer('name','batchnorm1') % BN层,用于加速训练过程,防止梯度消失或梯度爆炸
reluLayer('name','relu1') % ReLU激活层,用于保持输出的非线性性及修正梯度的问题
% 池化层
maxPooling2dLayer([2,1],'Stride',2,'Padding','same','name','maxpool') % 第一层池化层,包括3x3大小的池化窗口,步长为1,same填充方式
% 展开层
sequenceUnfoldingLayer('name','unfold') %独立的卷积运行结束后,要将序列恢复
%平滑层
flattenLayer('name','flatten')
lstmLayer(25,'Outputmode','last','name','hidden1')
dropoutLayer(0.1,'name','dropout_1') % Dropout层,以概率为0.2丢弃输入
%% Set the hyper parameters for unet training
options0 = trainingOptions('adam', ... % 优化算法Adam
'MaxEpochs', 100, ... % 最大训练次数
'GradientThreshold', 1, ... % 梯度阈值
'InitialLearnRate', 0.01, ... % 初始学习率
'LearnRateSchedule', 'piecewise', ... % 学习率调整
'LearnRateDropPeriod',70, ... % 训练100次后开始调整学习率
'LearnRateDropFactor',0.01, ... % 学习率调整因子
'L2Regularization', 0.001, ... % 正则化参数
'ExecutionEnvironment', 'cpu',... % 训练环境
'Verbose', 1, ... % 关闭优化过程
'Plots', 'none'); % 画出曲线
%% Adaboost增强学习部分
% 权重初始化%%
D = ones(1, M) / M;
%% 参数设置
K = 5; % 弱回归器个数
%% 弱回归器回归
for i = 1 : K
i
%% 创建模型
clear net
net = trainNetwork(trainD,targetD',lgraph0,options0);
result1 = predict(net, trainD);
result2 = predict(net, testD);
% 数据格式转换
E_sim1 = double(result1);% cell2mat将cell元胞数组转换为普通数组
E_sim2 = double(result2);
%% 仿真预测
t_sim1(i, :) = E_sim1';
t_sim2(i, :) = E_sim2';
%% 数据反归一化
T_sim1 = mapminmax('reverse', T_sim1, ps_output);
T_sim2 = mapminmax('reverse', T_sim2, ps_output);
T_sim1 = double(T_sim1);
T_sim2 = double(T_sim2);
%% 计算各项误差参数 %%
% 指标计算
disp('............CNN-LSTM-Adaboost训练集误差指标............')
[test_MAE1,test_MAPE1,test_MSE1,test_RMSE1,test_R2_1,test_RPD1] = calc_error(T_train,T_sim1);
fprintf('\n')
disp('............CNN-LSTM-Adaboost测试集误差指标............')
[test_MAE2,test_MAPE2,test_MSE2,test_RMSE2,test_R2_2,test_RPD2] = calc_error(T_test,T_sim2);
fprintf('\n')
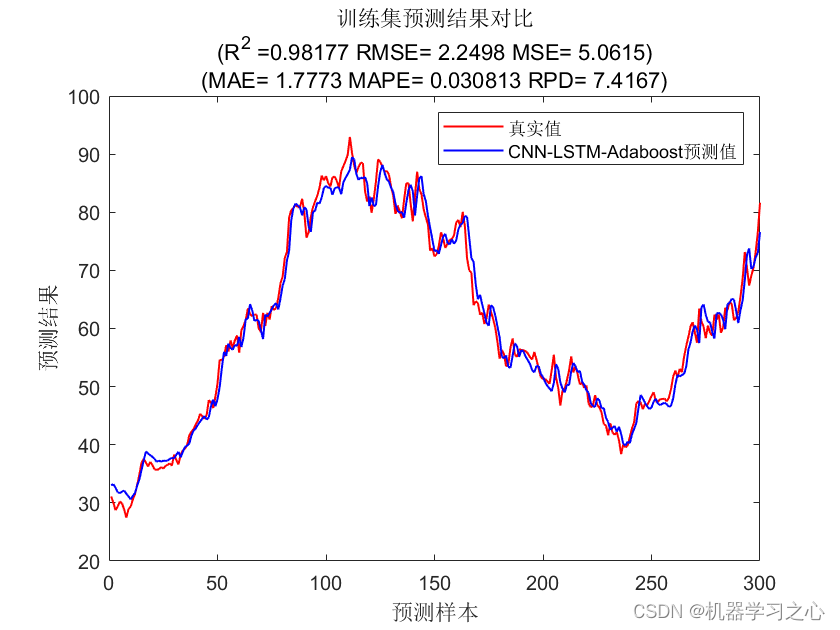
%% 训练集绘图 %%
figure
plot(1:M,T_train,'r-','LineWidth',1,'MarkerSize',2)
hold on
plot(1:M,T_sim1,'b-','LineWidth',1,'MarkerSize',3)
legend('真实值','CNN-LSTM-Adaboost预测值')
xlabel('预测样本')
ylabel('预测结果')
string={'训练集预测结果对比';['(R^2 =' num2str(test_R2_1) ' RMSE= ' num2str(test_RMSE1) ' MSE= ' num2str(test_MSE1) ')'];[ '(MAE= ' num2str(test_MAE1) ' MAPE= ' num2str(test_MAPE1) ' RPD= ' num2str(test_RPD1) ')' ]};
title(string)
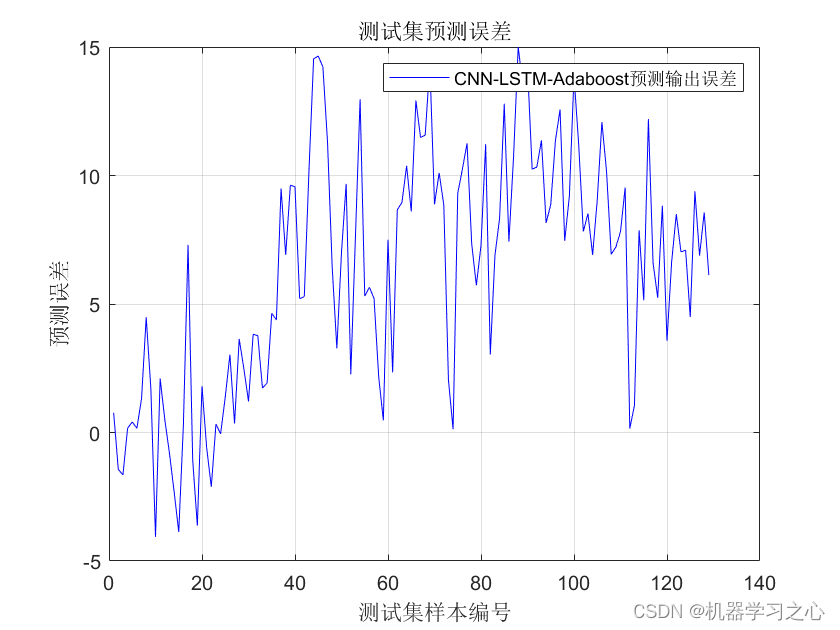
%测试集误差图 %%
figure
plot(T_test-T_sim2,'b-','LineWidth',0.1,'MarkerSize',2)
xlabel('测试集样本编号')
ylabel('预测误差')
title('测试集预测误差')
grid on;
legend('CNN-LSTM-Adaboost预测输出误差')训练结束: 已完成最大轮数。
............CNN-LSTM-Adaboost训练集误差指标............
1.均方差(MSE):5.0615
2.根均方差(RMSE):2.2498
3.平均绝对误差(MAE):1.7773
4.平均相对百分误差(MAPE):3.0813%
5.R2:98.1767%
6.剩余预测残差RPD:7.4167
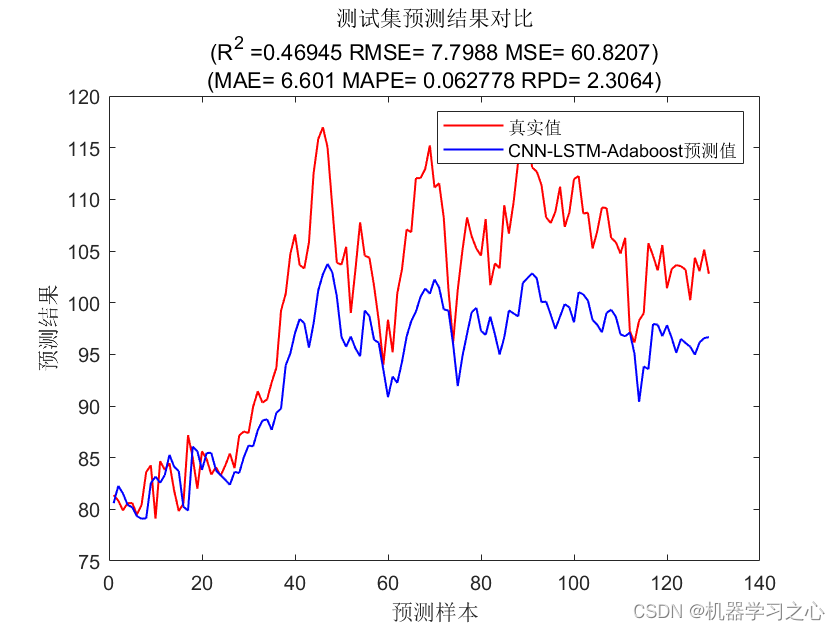
............CNN-LSTM-Adaboost测试集误差指标............
1.均方差(MSE):60.8207
2.根均方差(RMSE):7.7988
3.平均绝对误差(MAE):6.601
4.平均相对百分误差(MAPE):6.2778%
5.R2:46.9453%
6.剩余预测残差RPD:2.3064
参考资料
1 https://hmlhml.blog.csdn.net/article/details/135536086?spm=1001.2014.3001.5502
2 https://hmlhml.blog.csdn.net/article/details/137166860?spm=1001.2014.3001.5502