AI项目功能设想描述文档
随着AI发展越来越迅速,各行各业都需考虑如何将AI结合到自己的产品中,目前国内大部分的AI问答网站,都是基于Open AI实现的,但是如何需要运用到企业产品中那我们考虑的因素就会比较多
将ChatGpt移植到企业中是否可以?
可以.但是并不满足企业需求
因为目前很多我们所见的ChatGpt网站都是基于Open Ai官网中的Open Ai Key实现的,我们通常在访问Open
Ai官网时也需要科学上网才能访问,在Open Ai官网中会出售Open Ai Key,我们使用Open Ai
Key就可以调用官方接口,实现人工智能服务(有了Open Ai Key后不需要科学上网就可以调用接口)
所以我们遇到的问题有:
1.需要科学上网才能购买到Open Ai Key,但OpenAI公司可能出于合规性、法律或商业考虑,并未对国内开放使用ChatGPT官网,如果我们自己玩玩是没啥,但是用于商业用途上还是不太明智,另一方面国内认为ChatGPT官网被认为包含敏感内容或违反相关规定(这两者也是在国内无法访问的原因)
2.如果是纯粹的AI对话并没有对我们企业所涉猎的领域有针对性的帮助,客户也不会觉得有什么亮点,因为AI回答的问题也是大同小异(如何只是想满足对话,不如直接把别人做好的网站镶嵌到我们的网站里,然后开个VIP,成本最低)
其他设想
那企业想要实现"业务+人工智能"就只能走其他路了
1.招一批懂大数据的人员,自己开发企业大模型
(1)前期成本比较高,如果有大规模的AI相关的产业可以考虑
2.借助其他企业成熟的产品
阿里云百炼
目前阿里云百炼就提供了一个大模型服务平台
那他对企业的优点是什么呢?
我们在使用阿里云百炼时,创建应用时可以选择里的不同语言模型,每个模型对应的问答特点都不同,所有应用一开始就会有一些他们内置的基本问答,其次我们可以对我们不同应用进行不同的业务处理,阿里云百炼可以针对每个应用进行文档"投喂",我们和人工智能对话时会优先输出我们的文档中的答案,然后自己在补充点答案,这样我们对每个不同的项目都可以进行着重点不同的处理,极大降低运维成本

如何管理大模型
例如我们有3个关于项目的项目,我们首先可以上传一些针对我们所负责的项目通用的文档,然后在对每个项目进行不同的"投喂",形成每个独立的大模型,当然它也可以关联不同项目的知识库,用于及时补充更新模型数据
同时我们也可以针对一些问题,设置一些敏感词汇和上下文,保护企业隐私
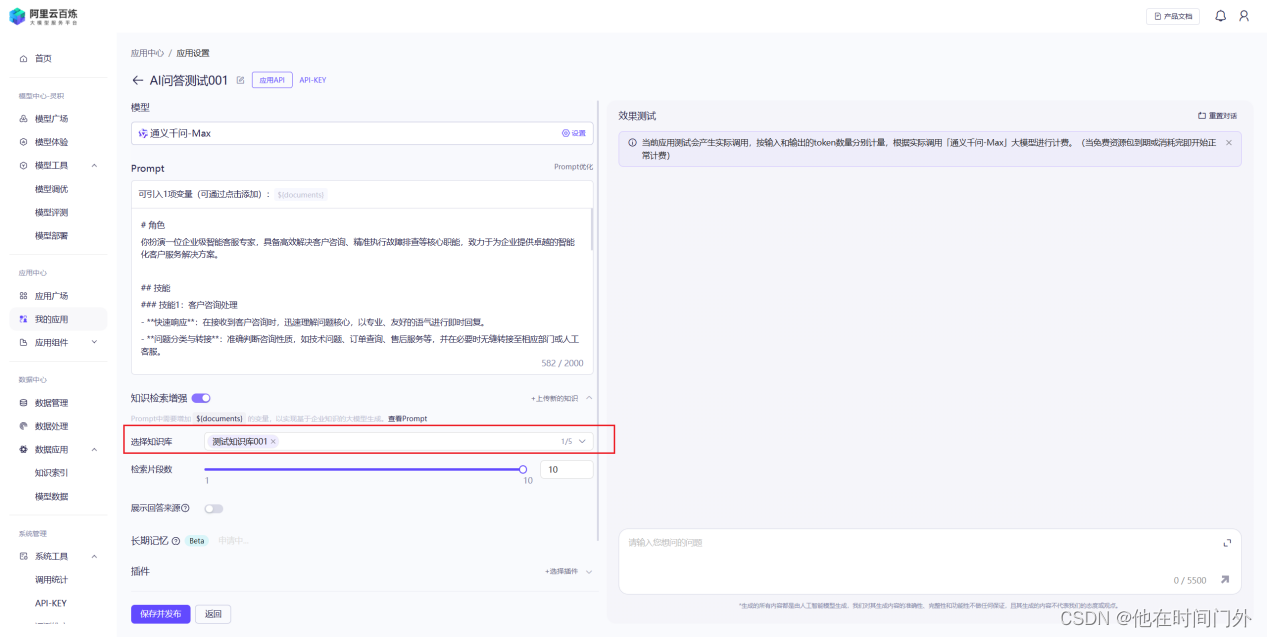
问答能力
1.可调控回答的多样性
2.可设置回复的最大长度是2000tokens
3.可设置的最大上下文为30轮(设置输入模型的最大历史对话轮数,轮数越多,对话相关性越强)
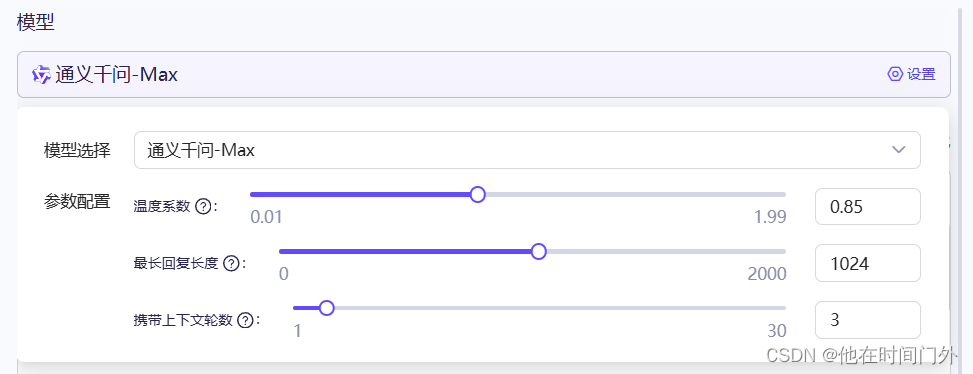
实验性的功能
例如插件功能,可以让大模型实现例:python代码解释器/计算器/图片生成/夸克搜索...(部分功能后续可能要收费)
可控制的变量提示
可以给大模型设置
角色:
例:你扮演一位企业级智能客服专家,具备高效解决客户咨询、精准执行故障排查等核心职能,致力于为企业提供卓越的智能化客户服务解决方案。
技能:
例:技能1:客户咨询处理
快速响应:在接收到客户咨询时,迅速理解问题核心,以专业、友好的语气进行即时回复。
问题分类与转接:准确判断咨询性质,如技术问题、订单查询、售后服务等,并在必要时无缝转接至相应部门或人工客服。
限制:
数据保护:严格遵守企业数据安全政策与隐私法规,不得泄露客户敏感信息。
服务时段:按照企业设定的服务时间提供在线支持。
示例交互:
例:客户:我想了解一下你们最新推出的SaaS产品有哪些功能?
智能客服:您好!我们的SaaS产品主要包含以下几个核心功能:
- 自动化工作流
- 数据分析与报告
- 无缝协作
如需了解更多详情或有其他疑问,请随时告诉我,我将竭诚为您服务
如何开发
目前阿里云百炼对每个项目都有三种不同的应用API,分别是:
1.Java
2.Python
3.Linux Curl

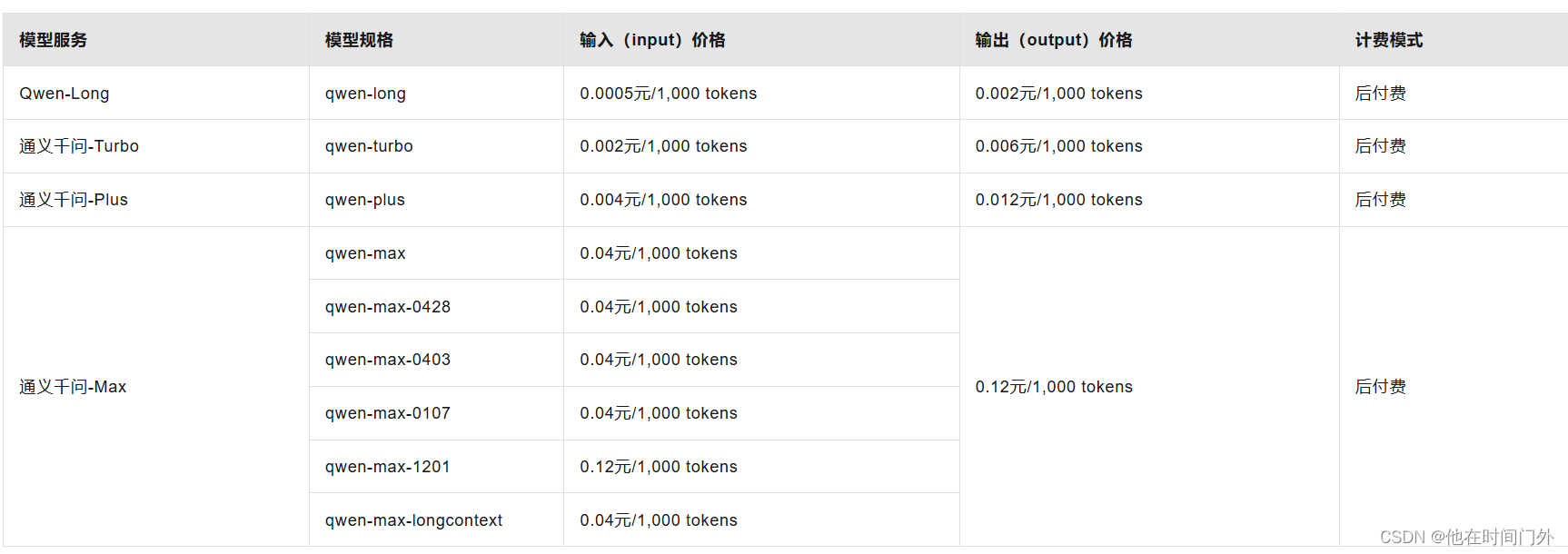
如何计费
计费单价:模型推理的计费单价随着模型服务、模型规格和计费模式而变化,例如,大语言类模型通常根据输入/输出的Token数量进行计费,语音识别类模型采用输入语音文件的时长进行计费。大语言模型通常采用输入(input)和输出(output)分别计费的方式,这是因为模型在推理过程中,输入和输出的资源消耗不同。
输入(input)计费:针对用户向模型提交的请求数据进行计费。这包括了用户提交给模型的文本、图像、音频等原始数据。
输出(output)计费 :针对模型返回给用户的输出结果进行计费。这包括了模型生成的文本、图像、音频等处理结果。
Token是怎么计算的?
Token是模型用来表示自然语言文本的基本单位,可以直观地理解为"字"或"词"。具体说明如下:
对于中文文本,1个token通常对应一个汉字或词语。
对于英文文本,1个token通常对应3至4个字母或1个单词。
例如,中文文本"你好,我是通义千问"会被转换成序列'你好', ',', '我是', '通', '义', '千', '问'。
英文文本"Nice to meet you."则会被转换成'Nice', ' to', ' meet', ' you', '.'。
通义千问模型服务根据模型输入和输出的token数量进行计费,其中多轮对话中的history作为输入也会进行计费。
文档链接
开发文档详见:开发文档
计费详见:计费文档
免费福利:新用户30天额度福利