关注我的公众号:【编程朝花夕拾】,可获取首发内容。

01 引言
应粉丝朋友要求,我们一起学习搭建了一个语言识别模型,并集成SpringBoot项目中。在搭建过程中遇到不少问题,总结一下分享给其他需要的朋友。
官网的给出的Java客户端稍微有点问题,并不能接受到大模型识别的反馈。网上的相关的技术博客也很少,这里帮大家把坑点填平,本文一片文章助你轻松拿下FunASR。
02 FunASR简介
FunASR是一个基础语音识别工具包,提供多种功能,包括语音识别(ASR)、语音端点检测(VAD)、标点恢复、语言模型、说话人验证、说话人分离和多人对话语音识别等。FunASR提供了便捷的脚本和教程,支持预训练好的模型的推理与微调。更是通过CPU可以直接跑起来的大模型。
FunASR旨在通过语音识别的学术研究和工业应用之间架起一座桥梁。通过发布工业级语音识别模型的训练和微调,研究人员和开发人员可以更方便地进行语音识别模型的研究和生产,并推动语音识别生态的发展。让语音识别更有趣!
开源仓库地址:github.com/modelscope/...
03 FunASR 部署
我们采用Docker技术直接部署,部署的官方指导文档:
Docker安装的本章不在赘述,之前的文章中已经介绍过安装过程。
3.1 拉取镜像并启动
我们这里使用的是cpu版本的模型:funasr-runtime-sdk-online-cpu-0.1.13。直接拉取镜像并启动:
sh
#拉取镜像
sudo docker pull \
registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-online-cpu-0.1.13
# 创建保存模型的文件夹
mkdir -p ./funasr-runtime-resources/models
# 挂载启动镜像
sudo docker run -p 10096:10095 -it --privileged=true \
-v $PWD/funasr-runtime-resources/models:/workspace/models \
registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-online-cpu-0.1.133.2 启动服务端
docker启动之后,启动 funasr-wss-server-2pass服务程序。
因为docker启动之后,直接进入到workspace下。可以继续使用cd 等命令

启动脚本
sh
cd FunASR/runtime
nohup bash run_server_2pass.sh \
--certfile 0 \
--download-model-dir /workspace/models \
--vad-dir damo/speech_fsmn_vad_zh-cn-16k-common-onnx \
--model-dir damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-onnx \
--online-model-dir damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-online-onnx \
--punc-dir damo/punc_ct-transformer_zh-cn-common-vad_realtime-vocab272727-onnx \
--lm-dir damo/speech_ngram_lm_zh-cn-ai-wesp-fst \
--itn-dir thuduj12/fst_itn_zh \
--hotword /workspace/models/hotwords.txt > log.txt 2>&1 &
# 如果您想关闭ssl,增加参数:--certfile 0
# 如果您想使用SenseVoiceSmall模型、时间戳、nn热词模型进行部署,请设置--model-dir为对应模型:
# iic/SenseVoiceSmall-onnx
# damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-onnx(时间戳)
# damo/speech_paraformer-large-contextual_asr_nat-zh-cn-16k-common-vocab8404-onnx(nn热词)
# 如果您想在服务端加载热词,请在宿主机文件./funasr-runtime-resources/models/hotwords.txt配置热词(docker映射地址为/workspace/models/hotwords.txt):
# 每行一个热词,格式(热词 权重):阿里巴巴 20(注:热词理论上无限制,但为了兼顾性能和效果,建议热词长度不超过10,个数不超过1k,权重1~100)
# SenseVoiceSmall-onnx识别结果中"<|zh|><|NEUTRAL|><|Speech|> "分别为对应的语种、情感、事件信息这里的脚本比官网上增加了--certfile 0,用来关闭ssl。
启动之后,可能需要等一会。直到服务启动起来,我们可以直接使用命令直接看看日志详情:
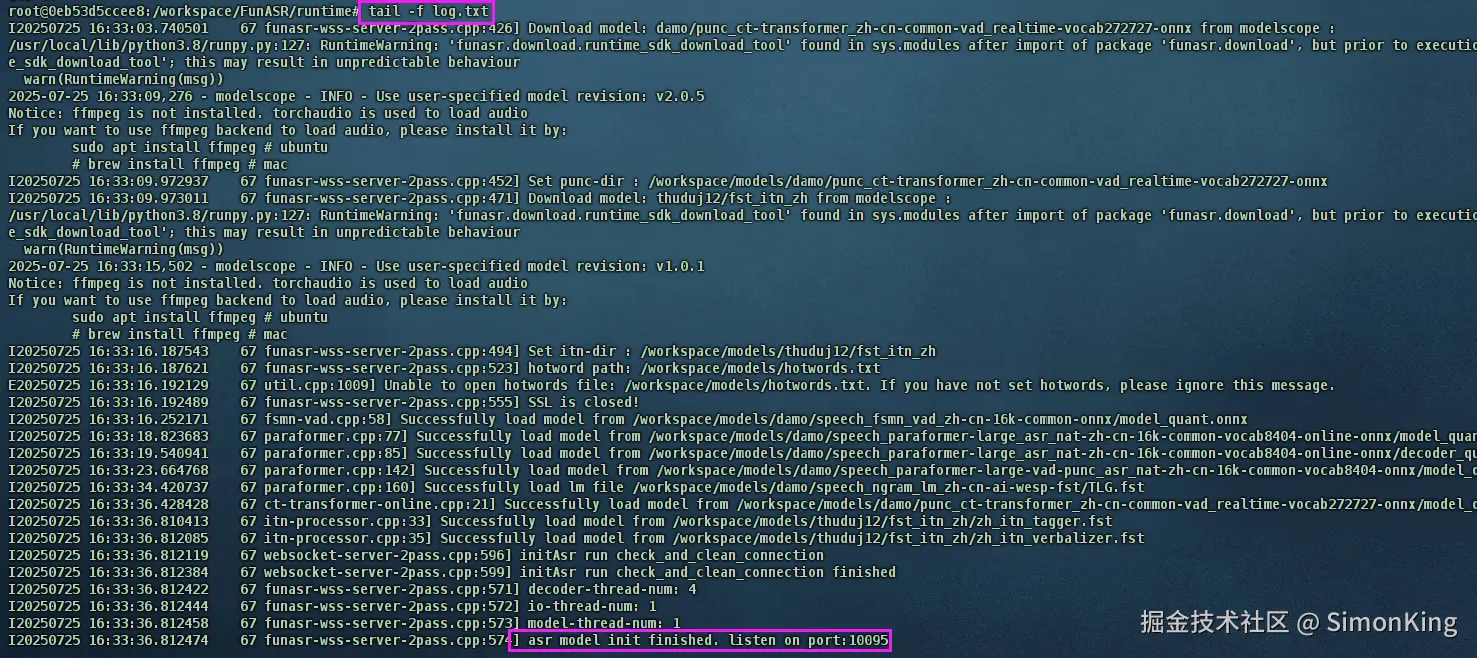
sh
tail -f log.txt直到出现模型初始化成功表示启动成功,如图:
3.3 客户端测试
官方提供了多个客户端,我们选择最简单的H5客户端测试大模型是否部署成功

Html客户端我们可以从GitHub直接下载,也可以从docker里面的下载,说明文档里面也给了链接:
sh
wget https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/sample/funasr_samples.tar.gz
浏览器里面直接访问Url,自动下载压缩包。打开里面的Html即可:
下载的samples喜下面还包含了,离线的.wav后缀的audio语音文件。
测试
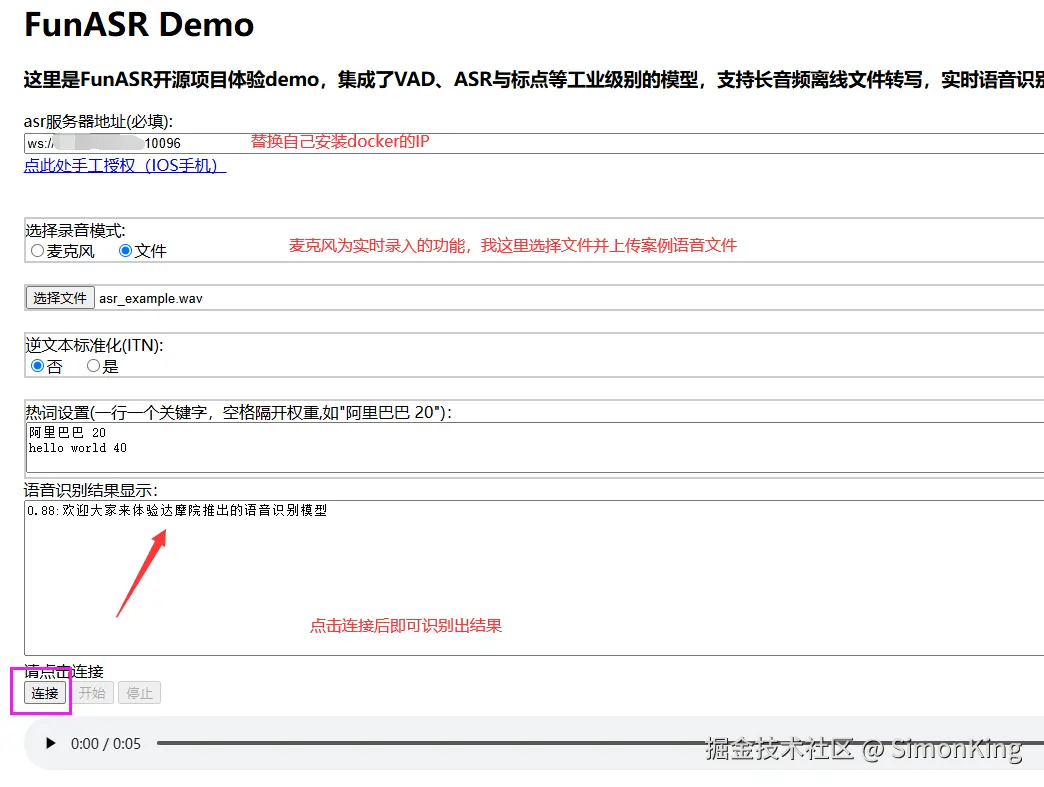
到这里,说明我们部署的语音大模型FunASR就已经成功了。
04 SpringBoot集成FunASR
FunASR的部署得益于Docker的容器化部署,几乎不会有问题。但是当与SpringBoot集成的时候,才是恶梦的开始。我们一起看看Java客户端。

Java的客户端是让我们将Java代码构建成shell命令,这并不是我们想要的。好在Github上提供了Java的案例
4.1 踩坑1
代码里面的关键类:RecognitionServiceImpl

多么优秀的代码,直接拷贝到自己的项目中。为了能够就减少问题,特意看了官方依赖的Maven。

xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-websocket</artifactId>
</dependency>
<dependency>
<groupId>org.json</groupId>
<artifactId>json</artifactId>
<version>20240303</version>
</dependency>笔者这里采用单元测试的方式,使用的SpringBoot版本是2.6.13。

standardWebSocketClient.execute()报错,最终采用了划红线的方法代替。
4.2 踩坑2
按照官方的模版代码,修正了错误之后,正常连接Websocket:
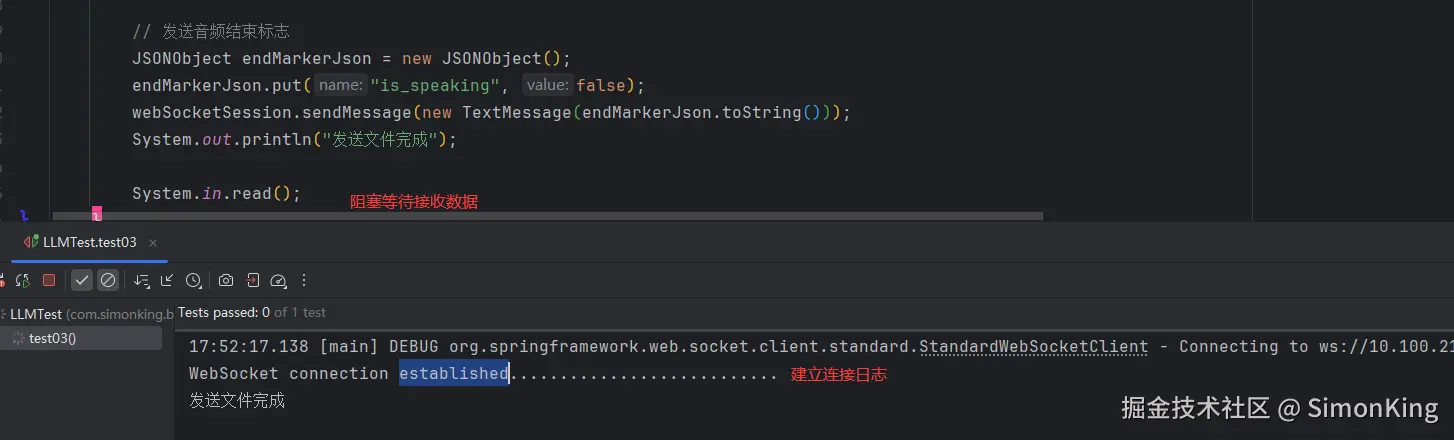
发现连上websocket,但是没有数据返回。这是最大的坑。
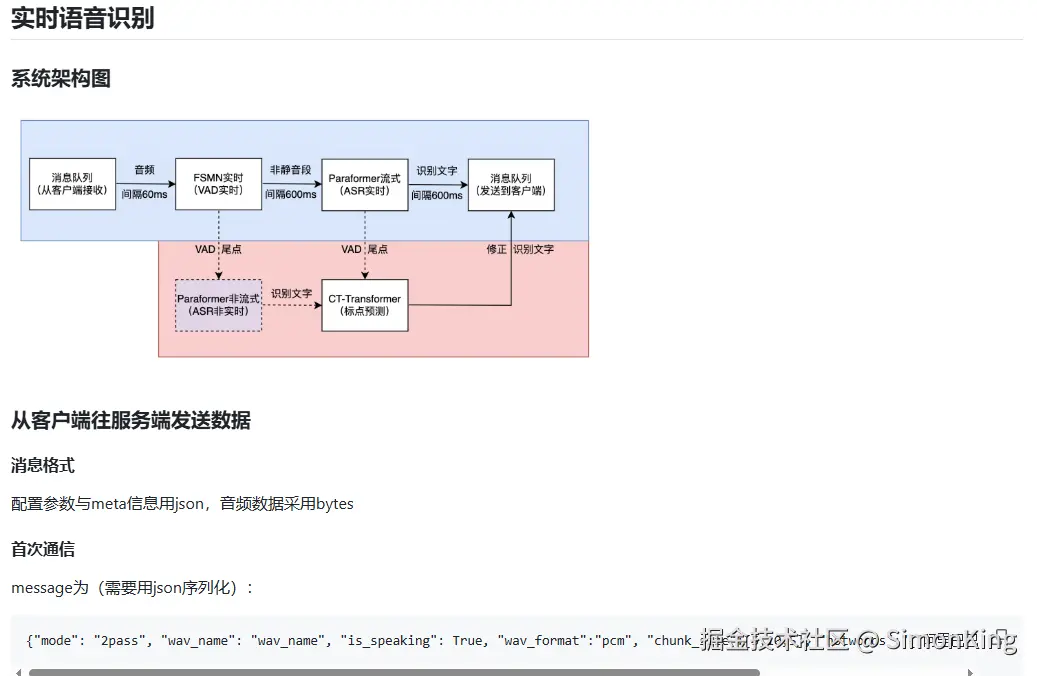
由于我们对接的事实时语音识别,服务端使用的是socket协议,我们看看官方文档的参数说明:
json
{
"mode": "2pass",
"wav_name": "wav_name",
"is_speaking": true,
"wav_format": "pcm",
"chunk_size": [5,10,5],
"hotwords": "{\"阿里巴巴\":20,\"通义实验室\":30}",
"itn": true
}参数说明:
mode:offline,表示推理模式为一句话识别;online,表示推理模式为实时语音识别;2pass:表示为实时语音识别,并且说话句尾采用离线模型进行纠错。wav_name:表示需要推理音频文件名wav_format:表示音视频文件后缀名,只支持pcm音频流is_speaking:表示断句尾点,例如,vad切割点,或者一条wav结束chunk_size:表示流式模型latency配置,[5,10,5],表示当前音频为600ms,并且回看300ms,又看300msaudio_fs:当输入音频为pcm数据是,需要加上音频采样率参数hotwords:如果使用热词,需要向服务端发送热词数据(字符串),格式为 "{"阿里巴巴":20,"通义实验室":30}"itn: 设置是否使用itn,默认Truesvs_lang: 设置SenseVoiceSmall模型语种,默认为"auto"svs_itn: 设置SenseVoiceSmall模型是否开启标点、ITN,默认为True
对比参数发现,案例的入参和文档说明的入参差了一个chunk_size,我们加上参数看看结果:
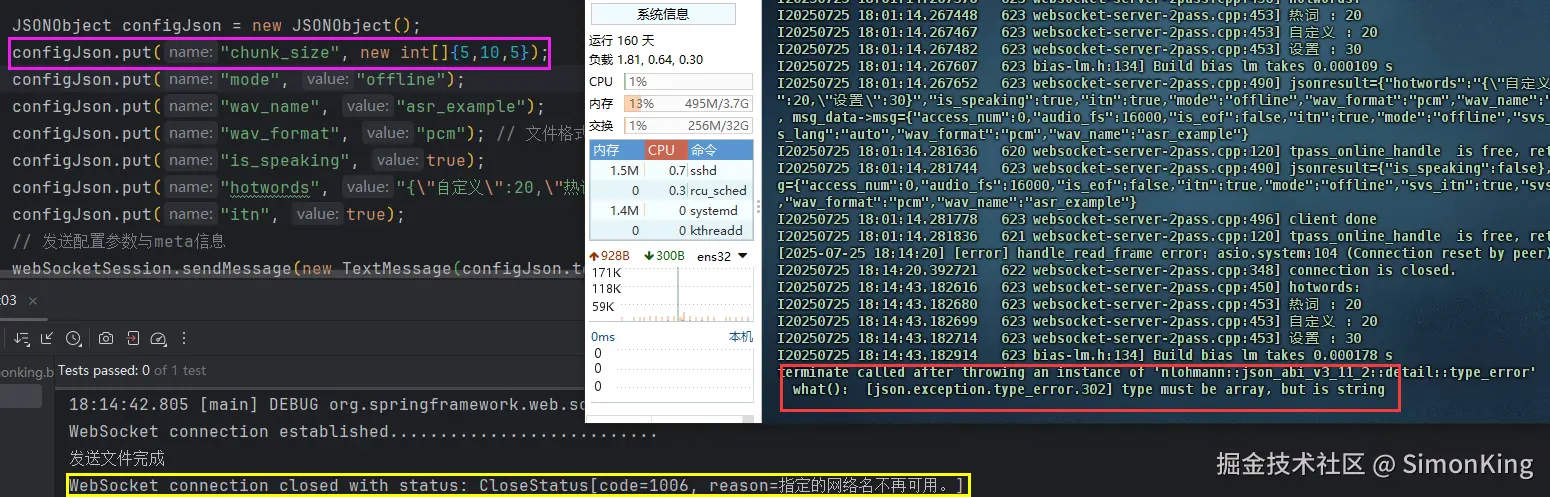
结果发现直到导致服务异常了,服务器上可以看出json参数异常了。我们打印出参数看看参数看看:
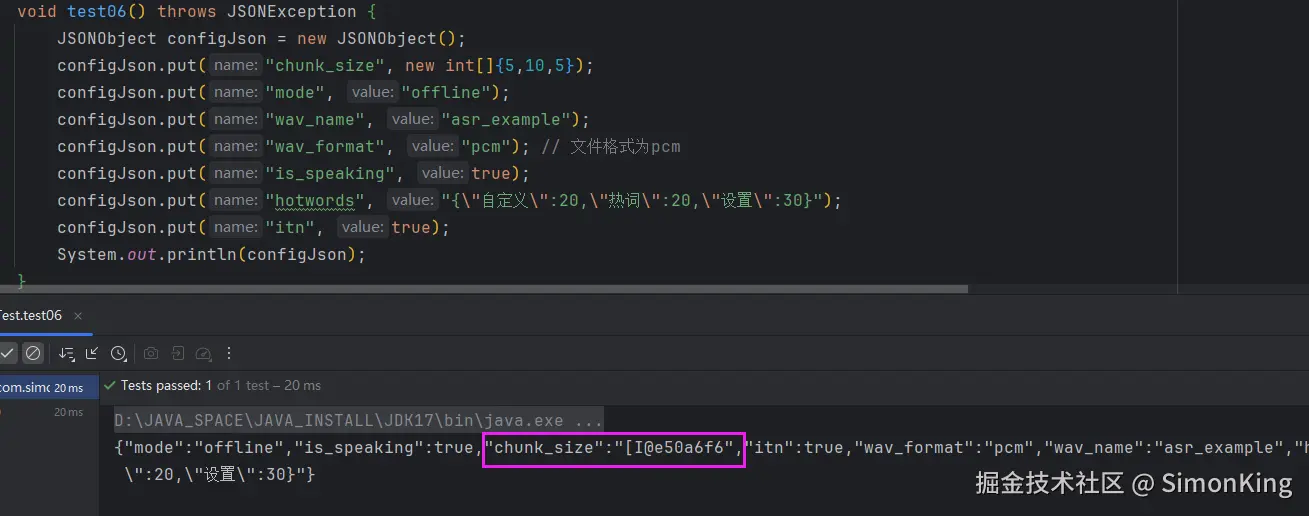
传递的数据结果变成了内存地址了,我们不用官方提供的,我们直接用fastjson2序列化,只要保证数组打印出来的是数组的值就好了。
测试结果终于正常了:

但是chunk_size到底是什么?虽然官方给了解释,但是还是一头雾水,又从官方主页里面找到了相关的解释,终于有了一点点了解,但还是懵逼状态。
小编简单以为:就是控制返回文字的频率和时间的一个指标
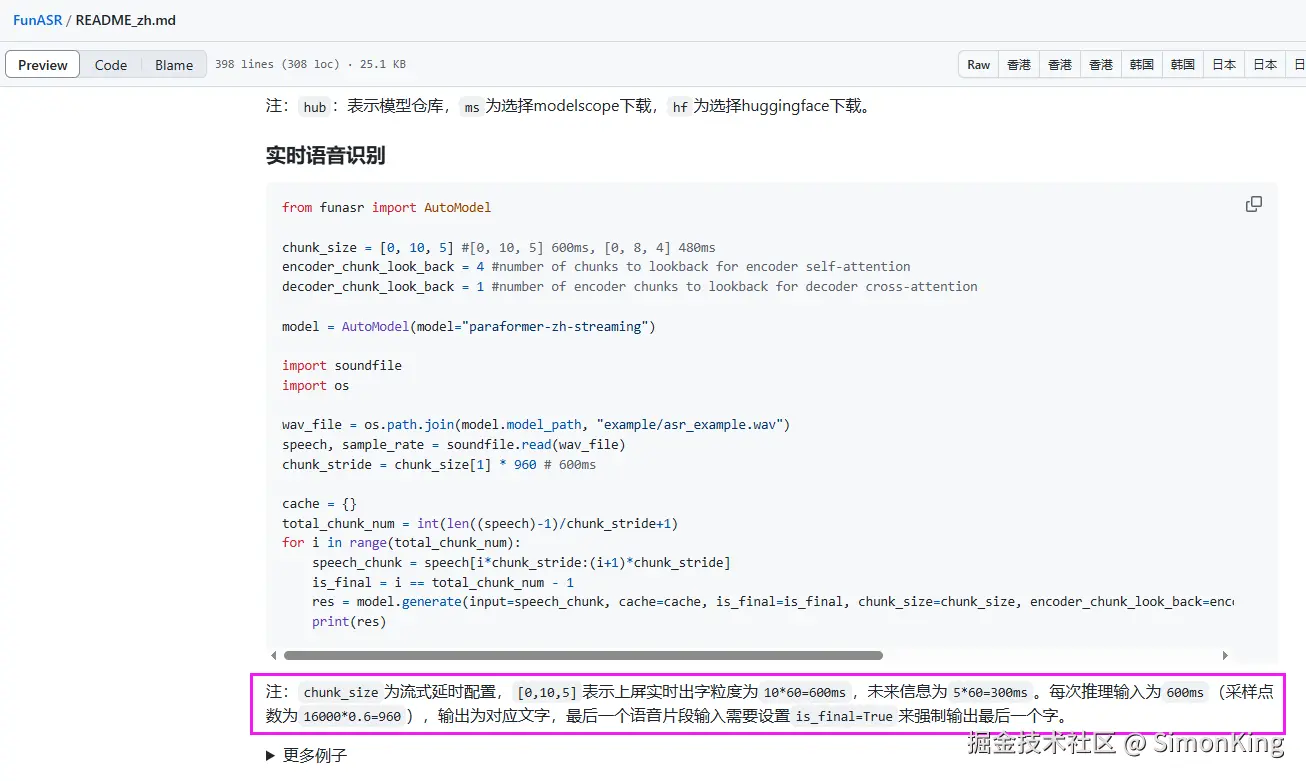
4.3 踩坑3
识别结果的处理:官方demo加了TODO,可能就会有人问到,这里获取不到结果怎么处理?
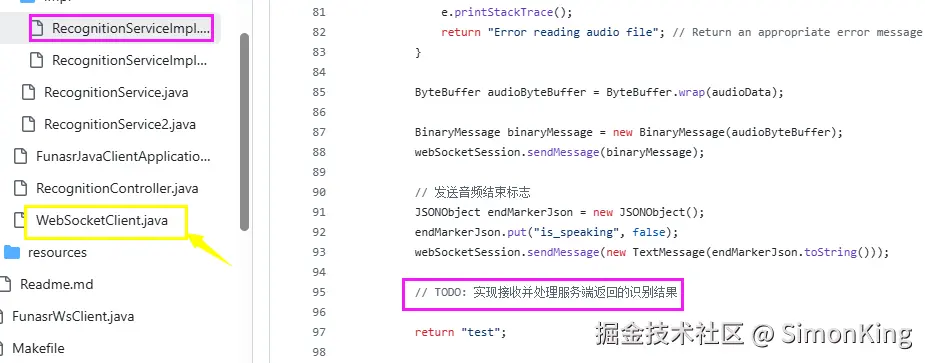
真正接收识别结果的事图中黄色的WebSocketClient,那我们如何将识别的结果传到指定的位置呢?
具体实现可以通过java.util.concurrent.CompletableFuture实现,具体不在赘述。