与之前的SD1.5大模型不同,这次的SDXL在架构上采用了"两步走"的生图方式:
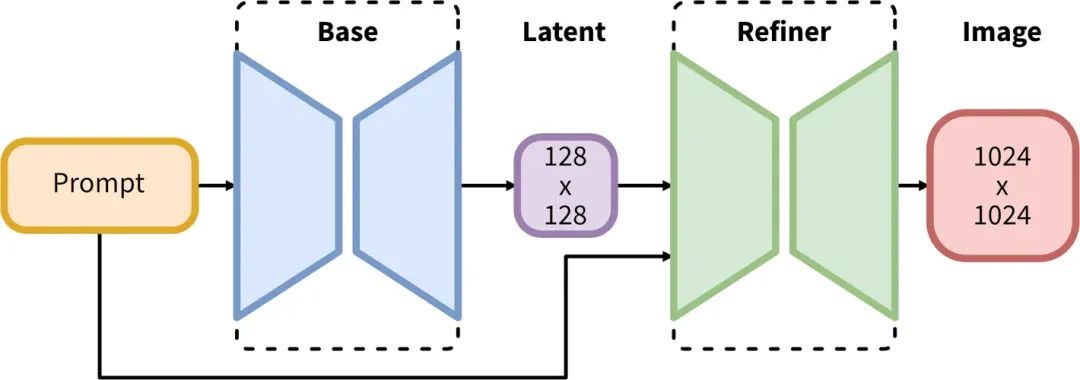
以往SD1.5大模型,生成步骤为 Prompt → Base → Image,比较简单直接;而这次的SDXL大模型则是在中间加了一步 Refiner。Refiner的作用是什么呢?简单来说就是能够自动对图像进行优化,提高图像质量和清晰度,减少人工干预的需要。
简单来说,SDXL这种设计就是先用基础模型(Base)生成一张看起来差不多的图片,然后再使用一个图像精修模型(Refiner)进行打磨,从而让图片生成的质量更高。而在没有这个之前,我们往往需要通过其他手段,如高清修复或面部修复来进行调优。
除了有出图质量更高这个优势,SDXL还有以下优点:
-
支持更高像素的图片(1024 x 1024)
-
对提示词的理解能力更好,比较简短的提示词也能达到不错的效果
-
相比SD1.5模型,在断肢断手多指的情况上有所改善
-
风格更为多样化
当然,每件事物不可能是完美的,所以SDXL也有一些局限性:
1、低像素出图质量不高
由于SDXL都是用1024x1024的图片训练的,这既导致它在这个像素级别上生成的质量比较高。但同时也导致了它在低像素级别(如512x512)生成的质量反而比较低,甚至不如SD1.5等模型。
2、与旧Lora不兼容
过去一些适用于SD1.5, 2.x 的Lora和ControlNet模型,大概率无法使用,得重新找一些带有SDXL的模型
**3、**对GPU显存的要求更高(这个下面会着重讲到)
4、出图时间也变久了
好了,简单讲完了SDXL大模型以及它的优缺点,接下来就开始实战了!
一、模型的下载
这次模型的下载有点不同,因为我们需要下载三个模型,分别是:sd_xl_base_1.0.safetensors、1 sd_xl_refiner_1.0.safetensors 和 2 sdxl_vae.safetensors3 。
三个模型的地址分别是:
-
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main
-
https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/tree/main
二、模型的加载
如果你的模型下载好了,就把 sd_xl_base_1.0.safetensors、sd_xl_refiner_1.0.safetensors 丢到根目录的 models\Stable-diffusion,把 sdxl_vae.safetensors 丢到 models\VAE 即可。
需要注意的是 Refiner 模型的加载,看发布日志是 SD1.6.0 的时候才支持,所以如果想使用的话得看你的版本有没有达到。另外就是这里的SD1.6.0指的是内核的版本,并不是模型的版本(不要被各种简写误导了)
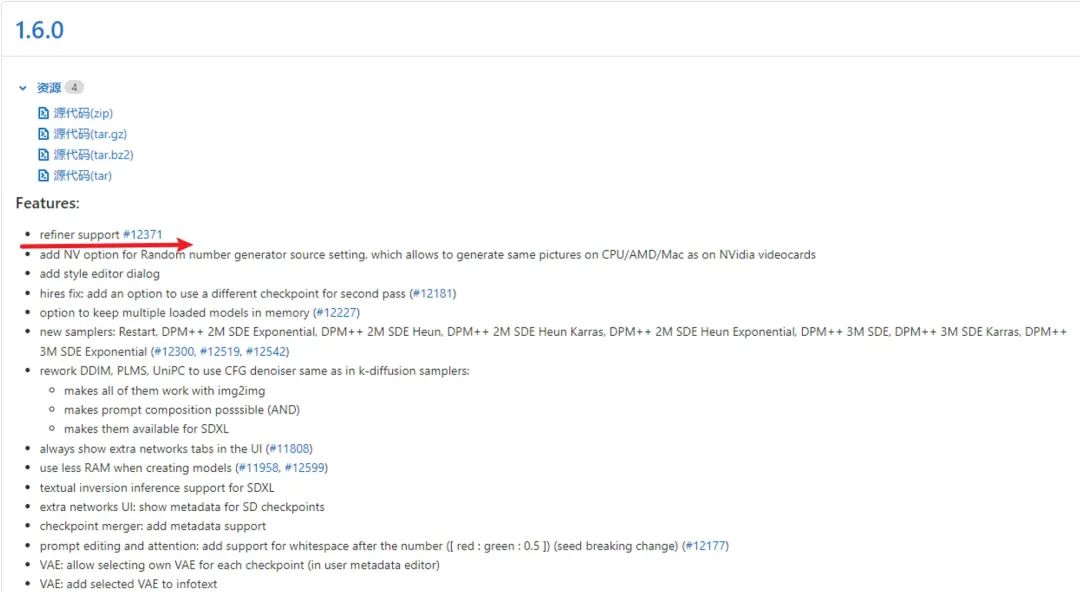
内核的版本指的是这里的版本

还有一个需要注意的是貌似升级版本容易有一些不兼容的问题,而且在使用SDXL大模型时也不一定就得用Refiner,单纯使用基础模型(base)也是OK的,只不过效果会差点,所以建议升级前也做一下调研工作。
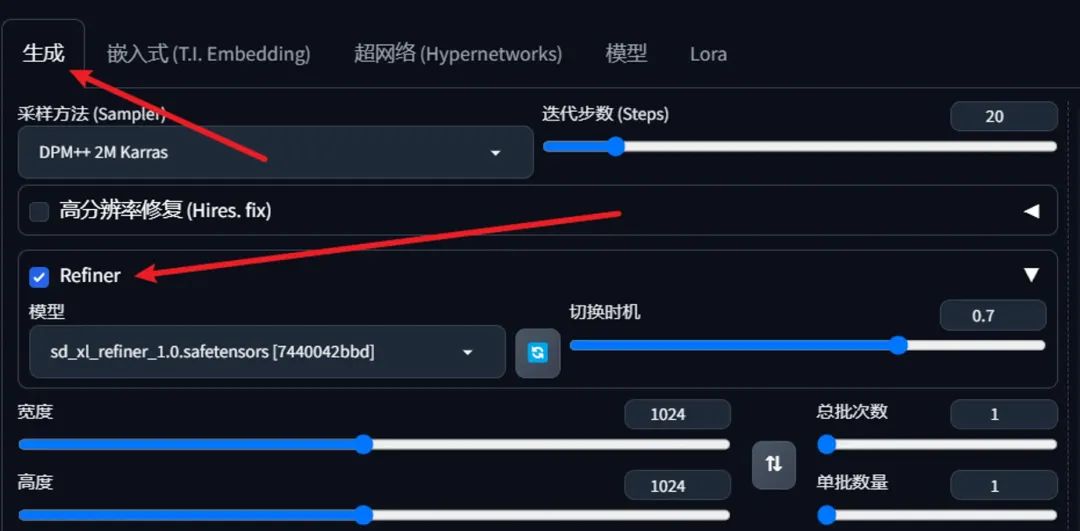
最后Refiner的位置可能没那么显眼,在生成选项卡里面
三、显存的大小
由于SDXL的模型和出图尺寸比之前的SD1.5大得多,所以也间接导致了它在出图方面所需要的显存和时间也变大了。
那到底需要多少显存呢?网上有一个说法是:跑SDXL最低显存是8G。经过我的测试,这个数据具有一定参考性,在进行一些优化的情况下,8G的显存的确能跑;但如果你什么优化都不做的话,8G的显存是不够的。
我自己的显卡是4060Ti 16G,内存32G,在这个配置的基础上我做了几个小测试(都是1024 x 1024的尺寸)
提示词:
a beatuiful real female play guitar
3.1 不开任何优化 + 不使用Refiner
第一个测试是在不开任何优化的情况下出图,结果还是出人意料的,居然爆显存了


3.2 不开任何优化 + 使用Refiner
第二个测试是在第1个的基础上,加了Refiner,但出乎意料的是,并没有爆显存,但从下方的显存使用看,也几乎达到了极限。为什么加了Refiner就没有爆显存我也不太清楚,希望有大佬留言科普下。

这里也简单说明最下方的A、R、Sys 三个指标:
💡
A,Active:peak amount of video memory used during generation(excluding cache data),个人理解就是出图时使用的显存峰值
R,Reserved:total amount of video memory allocated by the Torch library,个人理解就是Torch 库使用的显存总量
Sys:System:peak amount of video memory allocated by all running programs, out of total capacity,个人理解就是使用显存的占比。
3.3 开启VAE模型半精度优化
这个开了之后(貌似这个不是实时生效的,所以每一次修改后我都会重启),发现其实效果不大,显存的使用率和第二个测试是差不多的。
3.4 开启 VAE + UNet模型半精度优化
加了UNet模型半精度优化,显存使用率下降了一部分(12G差不多能跑),而且出图时间也下降了很多!为什么加了UNet显存使用率会下降明显,看**网上一篇文章4**说SDXL用了 larger UNet backbone,猜测是这个原因导致的。
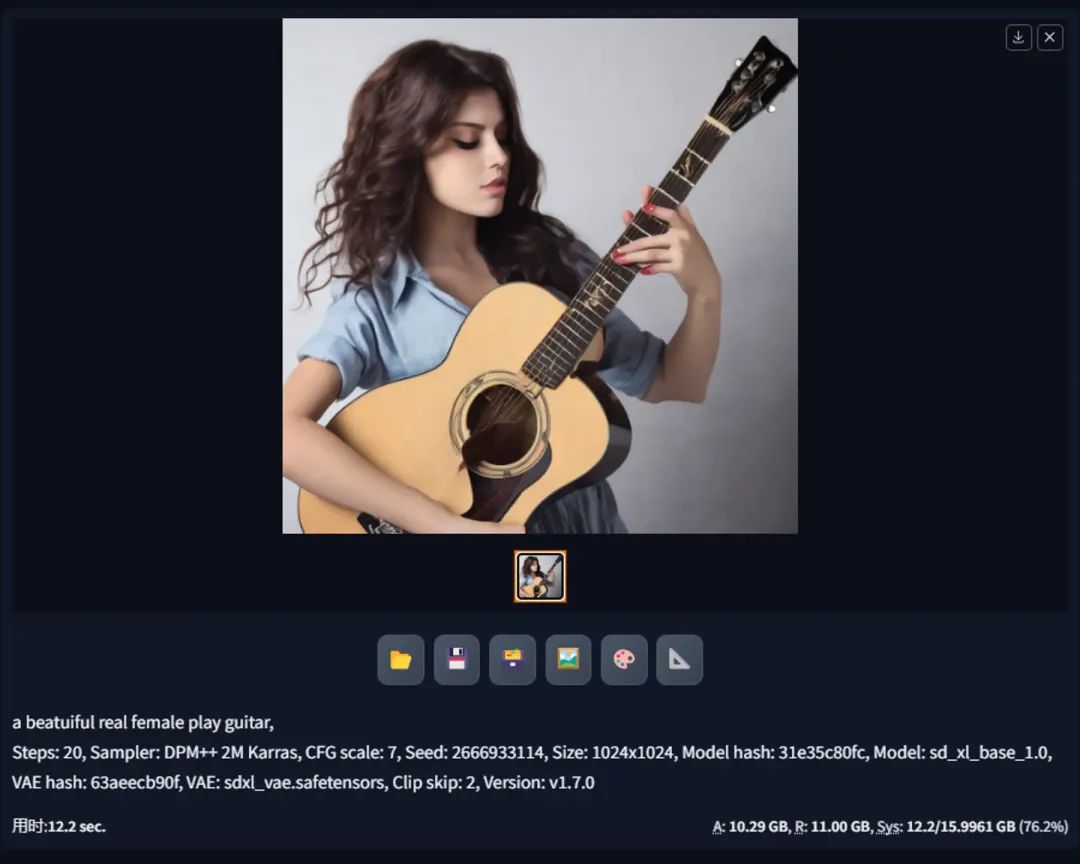
3.5 开启 VAE + UNet模型半精度优化 + 显存优化
前面四个测试都是在不开显存优化的情况下进行的,在第五个测试中,开了显存优化后,显存下降会比之前更加明显(比3.4下降了一半),但是出图时间会略长。
从这里也可以看出,显存优化的作用还是蛮明显的,不过我也试了中等显存(4GB以上)、仅SDXL中等显存(8GB以上),但是两者并没有明显区别。

通过上面的测试,我们也可以初步得到:跑SDXL最低显存是8G的说法是有一定准确性的,不过这个准确性大概率是建立在开了半精度优化和显存优化的基础上。如果你的显存达不到8G,除了上面的手段,也可以试试使用共享显存的优化方案,应该还能降一点。
四、出图测试
4.1 设置图片默认宽高
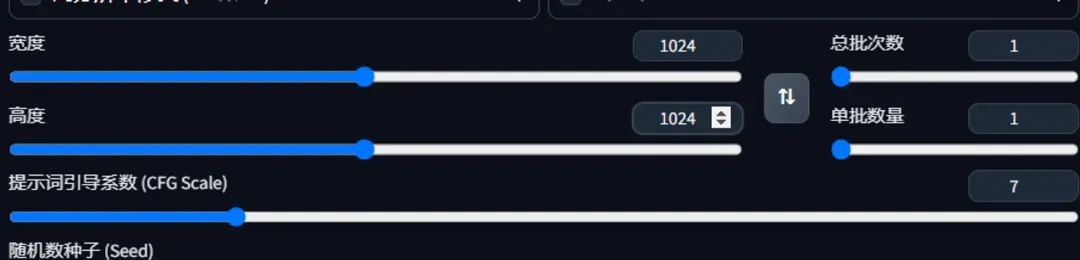
秋叶安装包默认的宽高是512x512,但是对于SDXL模型,这个尺寸是不适合的,每次刷新页面后又得调整,就想着能不能把默认值改成 1024x1024.
第一步,刷新页面,将尺寸改为 1024x1024
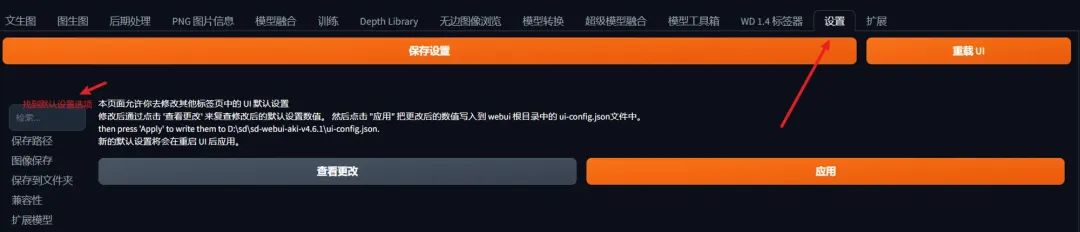
第二步,在设置里面找到"默认设置"
第三步,点击应用按钮即可。如果你想看改了啥,还可以点击"查看更改"按钮
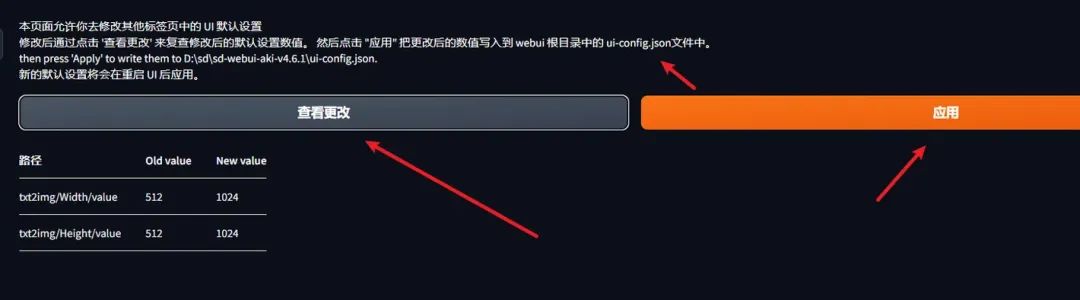
上面的步骤实际改的是ui-config.json 配置的这两个参数,对了,如果要生效必须重启启动器,刷新页面是没用的
txt2img/Width/value
txt2img/Height/value4.2 提示词理解能力对比
我给的提示词是上篇文章《Stable diffusion 3:跌宕起伏,或许终见彩虹》测试SD3的
Epic anime artwork of a wizard atop a mountain at night casting a cosmic spell into the dark sky that says "Stable Diffusion 3" made out of colorful energy
可以看到SDXL的对自然语言的提示词的理解能力确定吊打之前的模型

4.3 文字拼写能力测试
看网上说SDXL的文字拼写能力比较强,简单来说就是能按要求在图片写字,提示词如下:
// 用的网上的提示词,字面意思就是在头盔上写 future 英文
a cyberpunk girl is wearing a helmet,the helmet with the words"future" written on it,
总体感觉能力肯定是进步的,但比SD3还是差了不少,这也是从出的图里面选几张比较好的

4.4 优秀的提示词借鉴
50+ Best SDXL Prompts For Breathtaking Images5
这是一位SD资深大神整理的,100款Stable Diffusion超实用插件,涵盖目前几乎所有的,主流插件需求。
全文超过4000字。
我把它们整理成更适合大家下载安装的【压缩包 】,无需梯子,并根据具体的内容,拆解成一二级目录,以方便大家查阅使用。
单单排版就差不多花费1个小时。
希望能让大家在使用Stable Diffusion工具时,可以更好、更快的获得自己想要的答案,以上。
如果感觉有用,帮忙点个支持,谢谢了。
想要原版100款插件整合包的小伙伴,可以来点击下方插件直接免费获取
