目录
-
- 1.感知机
- 2.多层感知机(MLP)
-
- 学习XOR
- 单隐藏层(全连接层)
- 激活函数:Sigmoid
- 激活函数:Tanh
- [激活函数:ReLu 最常用的 因为计算速度快](#激活函数:ReLu 最常用的 因为计算速度快)
- [多分类 结构是相同的,只是输出为k个而不是1个](#多分类 结构是相同的,只是输出为k个而不是1个)
- 多隐藏层
- 总结
- 3.多层感知机的从零实现
- 4.多层感知机的简洁实现
- 5.模型选择
- 6.过拟合和欠拟合
- [7.权重衰退(Weight_decay) 处理过拟合的一种方法,效果不是很好](#7.权重衰退(Weight_decay) 处理过拟合的一种方法,效果不是很好)
-
- 使用均方范数作为硬性限制,一般不使用
- 使用均方范数作为柔性限制
- 演示对最优解的影响
- [参数更新法则 权重衰退](#参数更新法则 权重衰退)
- 总结
- 8.丢弃法(Dropout),效果比权重衰退可能更好
-
- 无偏差的加入噪音
- 使用丢弃法/暂退法(Dropout)
- 总结
- [Dropout 代码实现](#Dropout 代码实现)
- [Dropout 代码简洁实现](#Dropout 代码简洁实现)
- [9.数值稳定性 梯度爆炸和消失](#9.数值稳定性 梯度爆炸和消失)
- [10.合理的模型初始化和激活函数 让训练更加稳定](#10.合理的模型初始化和激活函数 让训练更加稳定)
- 11.实战Kaggle比赛:预测房价
- "Dummy_na=True"将"na"(缺失值)视为有效的特征值,并为其创建指示符特征
1.感知机
- 给定输入x,权重w,和偏移b,感知机输出:

感知机实际是一个二分类问题:-1或1
- 回归输出实数
- Softmax回归输出概率
训练感知机

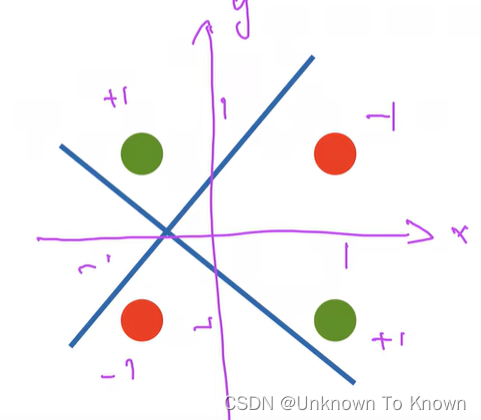
XOR问题(Minsky&Papert 1969) AI的第一个寒冬
感知机不能拟合XOR函数,它只能产生线性分割面
总结
- 感知机是一个二分类模型,是最早的AI模型之一
- 它的求解算法等价于使用批量大小为1的梯度下降 批量大小为1:指在训练神经网络时,每次更新参数时只使用单个样本的数据
- 它不能拟合XOR函数,导致第一次AI寒冬
2.多层感知机(MLP)
学习XOR

通过两个分类器,第一个蓝色分类器,通过 1 和 3 时为 正 2 和 4 为负,同时再通过黄色分类器,通过1 2 时为正,3 4 时为负。最后两个分类器的结果融合,相同为正 不同为负 如图上表,以此分类
单隐藏层(全连接层)
当多个分类器,结合起来就是多层感知机,也是全连接层

为什么要激活函数并且是要非线性的?
如果,是线性的情况下,这个就相当于一个单层的感知机,输入和输出只是线性的变化,没有什么作用
激活函数:Sigmoid

激活函数:Tanh

激活函数:ReLu 最常用的 因为计算速度快

多分类 结构是相同的,只是输出为k个而不是1个

多隐藏层

激活函数必不能少,否则会造成层数的坍塌
总结
- 多层感知机使用隐藏层和激活函数来得到非线性模型
- 常用激活函数是Sigmoid,Tanh,ReLu
- 使用Softmax来处理多类分类
- 超参数为隐藏层数 和各个隐藏层大小
3.多层感知机的从零实现
python
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
#获取了两个迭代器 train_iter 和 test_iter 每次256张图像和对应的标签
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
#初始化模型参数 num_hiddens隐藏层256
num_inputs, num_outputs, num_hiddens = 784, 10, 256
#输入层和隐藏层的权重矩阵,其形状为 (num_inputs, num_hiddens),初始化为从均值为 0、标准差为 0.01 的正态分布中随机抽取的值
W1 = nn.Parameter(torch.randn(#
num_inputs, num_hiddens, requires_grad=True) * 0.01)
#是隐藏层的偏置项,形状为 (num_hiddens,),初始化为零。
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
#封装为 nn.Parameter 对像
params = [W1, b1, W2, b2]
#实现ReLU激活函数
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)
#实现模型
def net(X):
X = X.reshape((-1, num_inputs))# 重新调整形状为 (batch_size, num_inputs)
H = relu(X@W1 + b1) # 这里"@"代表矩阵乘法
return (H@W2 + b2)
#多层感知机的训练过程与Softmax回归的训练过程完全相同
#损失函数
loss = nn.CrossEntropyLoss(reduction='none')
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)4.多层感知机的简洁实现
python
#使用 nn.Sequential 定义了一个神经网络模型 net,该模型包括一个展平层(nn.Flatten())、一个线性层(输入维度为 784,输出维度为 256)、一个ReLU激活函数层、以及一个线性层(输入维度为 256,输出维度为 10)。这些层依次组成了一个神经网络模型。
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))
#使用 init_weights 函数对模型的权重进行初始化。具体来说,它遍历模型的所有 nn.Linear 层,并对每一层的权重进行正态分布初始化,标准差为 0.01。
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
#将初始化函数应用于神经网络模型 net 中的所有层。
net.apply(init_weights);
#量大小 batch_size、学习率 lr、以及训练周期数 num_epochs
batch_size, lr, num_epochs = 256, 0.1, 10
#交叉熵损失函数(nn.CrossEntropyLoss)作为损失函数
loss = nn.CrossEntropyLoss(reduction='none')
#使用随机梯度下降(SGD)优化器来优化神经网络模型中的参数,其中优化的参数为 net.parameters()。
trainer = torch.optim.SGD(net.parameters(), lr=lr)
#加载 Fashion MNIST 数据集,并将数据集分为训练集和测试集。
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
#用 d2l.train_ch3 函数进行模型训练。
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)5.模型选择
训练误差和泛化误差
- 训练误差:模型在训练数据上的误差
- 泛化误差:模型在新数据上的误差
- 例子:根据模考成绩来预测未来考试分数
- 在过的考试中表现很好(训练误差)不代表未来考试一定会好(泛化误差)
验证数据集合测试数据集
- 验证数据集:一个用来评估模型好坏的数据集
- 例如拿出50%的训练数据
- 不要跟训练数据混在一起(常犯错误)
- 测试数据集:只用一次的数据集,不能用来调节超参数。例如
- 未来的考试
- 我出价的房子的实际成交价
- 用在Kaggle私有排行榜中的数据集
K-则交叉验证
- 在没有足够多数据时使用(这是常态)
- 算法:
- 将训练数据分割成K块
- For i = 1...k
- 使用第i块作为验证数据集,其余的作为训练数据集
- 报告K个验证集误差的平均
- 常用:K = 5 或 10
总结
- 训练数据集:训练模型参数
- 验证数据集:选择模型超参数
- 非大数据集上通常使用K-则交叉验证
6.过拟合和欠拟合
| 模型容量\数据 | 简单 | 复杂 |
|---|---|---|
| 低 | 正常 | 欠拟合 |
| 高 | 过拟合 | 正常 |
模型容量
- 拟合各种函数的能力
- 低容量的模型难以拟合训练数据(欠拟合)
- 高容量的模型可以记住所有的训练数据(过拟合)

估计模型容量
- 难以在不同中类算法之间比较
- 例如树模型和神经网络
- 给定一个模型种类,将有两个主要因素
- 参数的个数
- 参数值的原则范围
VC维(了解一下)
- 统计学习理论的一个核心思想
- 对于一个分类模型,VC等于一个最大的数据集的大小,不管如何给定标号,都存在一个模型来对它进行完美分类
线性分类器的VC维

VC维的用处
- 提供为什么一个模型好的理论依据
- 它可以衡量训练误差和泛化误差之间的间隔
- 单深度学习中很少用
- 衡量不是很准确
- 计算深度学习模型的VC维很困难
数据复杂度
- 样本个数
- 每个样本的元素个数
- 时间,空间结果
- 多样性
总结
- 模型容量需要匹配数据复杂度,否则可能导致欠拟合和过拟合
- 统计机器学习提供数学工具来衡量模型复杂度
- 实际中一般靠观察训练误差和验证误差
7.权重衰退(Weight_decay) 处理过拟合的一种方法,效果不是很好
使用均方范数作为硬性限制,一般不使用

使用均方范数作为柔性限制

演示对最优解的影响

参数更新法则 权重衰退

总结
- 权重衰退通过L2正则项使得模型参数不会过大,从而控制模型复杂度
- 正则项权重是控制模型复杂度的超参数
8.丢弃法(Dropout),效果比权重衰退可能更好
- Dropout 操作会在每一次训练迭代中随机选择一些神经元,并将它们的输出值设为零。这样可以防止网络过度依赖某些特定的神经元,从而增强网络的泛化能力。
- 动机
- 一个好的模型需要对输入数据的扰动有鲁棒性
- 使用有噪音的数据等价于Tikhonov正则
- Dropout:在层之间加入噪音
- 一个好的模型需要对输入数据的扰动有鲁棒性
无偏差的加入噪音

丢弃法:有p的概率把x设置为0,再把剩下的x扩大
使用丢弃法/暂退法(Dropout)

总结
- 丢弃法将一些输出项随机设置0来控制模型复杂度
- 常作用在多层感知机的隐藏层输出上
- 丢弃概率是控制模型复杂度的超参数
Dropout 代码实现
python
import torch
from torch import nn
from d2l import torch as d2l
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1
# 如果 dropout 等于 1,所有元素都被丢弃
if dropout == 1:
return torch.zeros_like(X)
# 如果 dropout 等于 0 或者不在训练阶段,直接返回输入 X
if dropout == 0:
return X
#生成与 X 相同形状的掩码
mask = (torch.rand(X.shape) > dropout).float()
#对掩码进行缩放,并应用到输入 X 上
return mask * X / (1.0 - dropout)
#定义具有两个隐藏层的多层感知机,每个隐藏层包含256个单元
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
dropout1, dropout2 = 0.2, 0.5
class Net(nn.Module):
#定义网络模型的结构
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,
is_training = True):
#通常会定义一个自定义的神经网络模型类,并使其继承自框架提供的基类
#super().__init__() 来调用父类的初始化方法
super(Net, self).__init__()
#将输入层的神经元数量保存在模型的 num_inputs 属性中。
self.num_inputs = num_inputs
#保存是否处于训练状态的布尔值
self.training = is_training
#创建了一个全连接,将输入特征的维度从 num_inputs 缩减到 num_hiddens1。
self.lin1 = nn.Linear(num_inputs, num_hiddens1)
#创建了一个全连接,将输入特征的维度从 num_hiddens1 到 num_hiddens1。
self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)
#创建了一个输出,将输入特征的维度从 num_hiddens2 到 num_outputs。
self.lin3 = nn.Linear(num_hiddens2, num_outputs)
# ReLU 激活函数,用非线性变换
self.relu = nn.ReLU()
def forward(self, X):
#输入数据 X 被重塑成一个二维张量,然后通过第一个线性层 self.lin1,并经过 ReLU 激活函数 self.relu
H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))
# 只有在训练模型时才使用dropout
if self.training == True:
# 在第一个全连接层之后添加一个dropout层
H1 = dropout_layer(H1, dropout1)
#第一个隐藏层的输出 H1 经过第二个线性层 self.lin2,然后再经过 ReLU 激活函数
H2 = self.relu(self.lin2(H1))
#如果处于训练状态,就在第二个全连接层之后应用 Dropout。
if self.training == True:
# 在第二个全连接层之后添加一个dropout层
H2 = dropout_layer(H2, dropout2)
#第二个隐藏层的输出经过输出层 self.lin3,得到模型的最终输出。
out = self.lin3(H2)
#返回模型的输出。
return out
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
#训练
num_epochs, lr, batch_size = 10, 0.5, 256
#损失函数
loss = nn.CrossEntropyLoss(reduction='none')
#获取训练集和验证集
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
#使用随机梯度下降,更新模型
trainer = torch.optim.SGD(net.parameters(), lr=lr)
#d2l.train_ch3 函数进行模型训练
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)Dropout 代码简洁实现
python
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
# 在第一个全连接层之后添加一个dropout层
nn.Dropout(dropout1),
nn.Linear(256, 256),
nn.ReLU(),
# 在第二个全连接层之后添加一个dropout层
nn.Dropout(dropout2),
nn.Linear(256, 10))
#用于初始化神经网络模型的权重
def init_weights(m):
#判断当前层 m 是否为线性层(nn.Linear 类型)。如果是线性层,则执行下面的操作。
if type(m) == nn.Linear:
#对线性层 m 的权重进行正态分布初始化,均值为 0,标准差为 0.01
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);9.数值稳定性 梯度爆炸和消失
神经网络的梯度

数值稳定性的常见两个问题
在计算梯度是,要对向量求导,一个向量求导后就是一个矩阵,所以要进行大量的矩阵乘法,所以会出现两个问题,一个是梯度爆炸,一个是梯度消失。

梯度爆炸的例子

梯度爆炸的问题
- 值超出域值(infinity)
- 对于16位浮点数尤为严重(数值区间6e-5,6e4)
- 对学习率敏感
- 如果学习率太大---->大参数值------->更大的梯度
- 如果学习率太小----->训练无进展
- 我们可能需要在训练过程不断调整学习率(在很小的范围内)
梯度消失
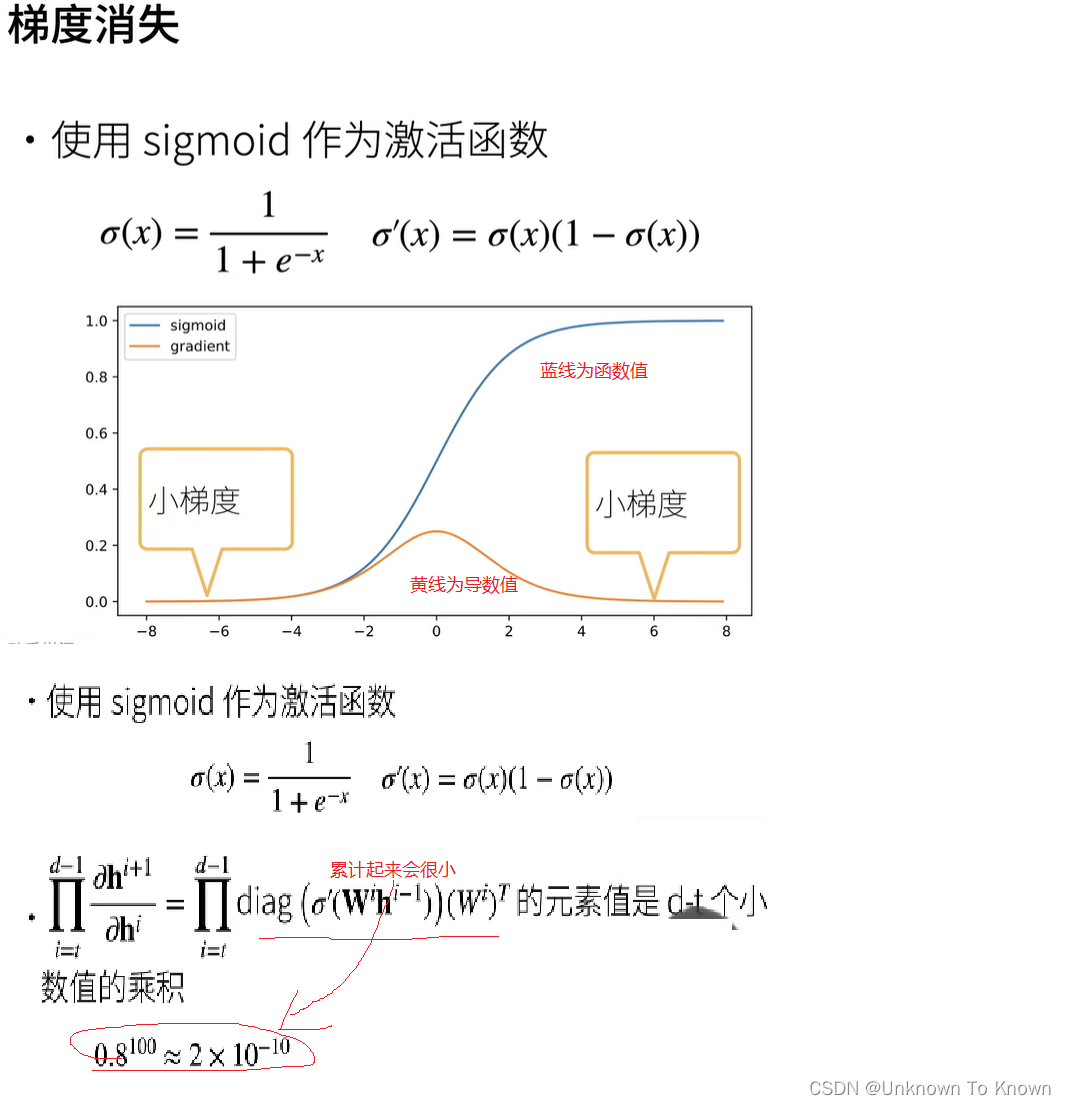
梯度消失的问题
- 梯度值变为0
- 对16位浮点数尤为严重
- 训练没有进展
- 不管如何选择学习率
- 对于底部层尤为严重
- 不仅仅顶部层训练的较好
- 无法让神经网络更深
总结
- 当数值过大或者过小时会导致数值问题
- 梯度爆炸和消失,常发生在深度模型中,因为其会对n个数累乘
10.合理的模型初始化和激活函数 让训练更加稳定
- 目标:让梯度值在合理的范围内
- 例如1e-6,1e3
- 方法
- 将乘法变加法
- ResNet,LSTM
- 归一化
- 梯度归一化,梯度裁剪
- 合理的权重初始和激活函数
- 将乘法变加法
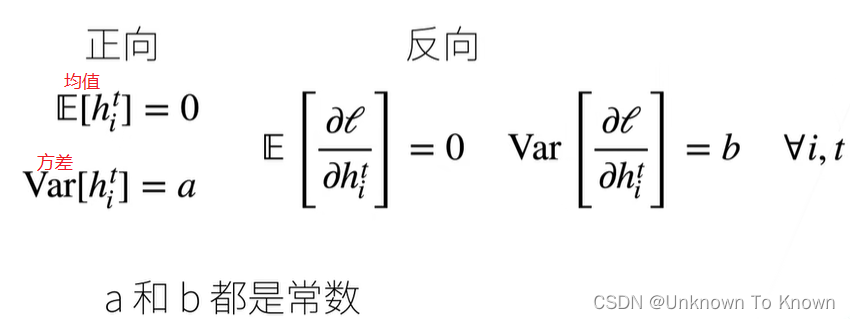
让每一层的方差是一个常数
- 将每层的输出和梯度都看做随机变量
- 让它们的均值和方差都保持一致
权重初始化
- 在合理值区间里随机初始参数
- 训练开始的时候更容易有数值不稳定
- 远离最优解的地方损失函数表面可能很复杂
- 最优解附近表面会比较平
- 使用N(0,0.01)来初始可能对小网络没问题,但不能保证深度神经网络
总接
- 合理的权重初始值和激活函数的选取可以提升数值稳定性
11.实战Kaggle比赛:预测房价
访问和读取数据集
python
import numpy as np
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
#为方便起见,我们可以使用上面定义的脚本下载并缓存Kaggle房屋数据集。
DATA_HUB['kaggle_house_train'] = ( #@save
DATA_URL + 'kaggle_house_pred_train.csv',
'585e9cc93e70b39160e7921475f9bcd7d31219ce')
DATA_HUB['kaggle_house_test'] = ( #@save
DATA_URL + 'kaggle_house_pred_test.csv',
'fa19780a7b011d9b009e8bff8e99922a8ee2eb90')
#使用pandas分别加载包含训练数据和测试数据的两个CSV文件
train_data = pd.read_csv(download('kaggle_house_train'))#包括1460个样本,每个样本80个特征和1个标签
test_data = pd.read_csv(download('kaggle_house_test'))#包含1459个样本,每个样本80个特征
#前四个和最后两个特征,以及相应标签(房价)
print(train_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]])
Id MSSubClass MSZoning LotFrontage SaleType SaleCondition SalePrice
0 1 60 RL 65.0 WD Normal 208500
1 2 20 RL 80.0 WD Normal 181500
2 3 60 RL 68.0 WD Normal 223500
3 4 70 RL 60.0 WD Abnorml 140000
#第一个特征是ID, 这有助于模型识别每个训练样本。 虽然这很方便,但它不携带任何用于预测的信息。 因此,在将数据提供给模型之前,我们将其从数据集中删除。
all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))数据预处理
python
# 若无法获得测试数据,则可根据训练数据计算均值和标准差
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
#对数值特征进行标准化处理
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x: (x - x.mean()) / (x.std()))
# 在标准化数据之后,所有均值消失,因此我们可以将缺失值设置为0
all_features[numeric_features] = all_features[numeric_features].fillna(0)
# "Dummy_na=True"将"na"(缺失值)视为有效的特征值,并为其创建指示符特征
all_features = pd.get_dummies(all_features, dummy_na=True)
all_features.shape#(2919, 331) 特征的总数量从79个增加到331个
#从pandas格式中提取NumPy格式,并将其转换为张量表示
n_train = train_data.shape[0]
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float32)
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float32)
train_labels = torch.tensor(
train_data.SalePrice.values.reshape(-1, 1), dtype=torch.float32)es].fillna(0)
"Dummy_na=True"将"na"(缺失值)视为有效的特征值,并为其创建指示符特征
python
all_features = pd.get_dummies(all_features, dummy_na=True)
all_features.shape#(2919, 331) 特征的总数量从79个增加到331个
#从pandas格式中提取NumPy格式,并将其转换为张量表示
n_train = train_data.shape[0]
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float32)
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float32)
train_labels = torch.tensor(
train_data.SalePrice.values.reshape(-1, 1), dtype=torch.float32)