在人工智能应用领域,文生图(Text-to-Image)一直是一个重要的研究领域。通过将文本描述转换为对应的图像,广泛应用在艺术创作、广告设计、游戏开发等工作中。
在众多的文生图模型中,Stable Diffusion 因其高质量的图像生成能力、开源等特性,使得它在文生图领域独树一帜,赢得了广泛的关注。如今,Stable Diffusion 3 真正来了。
为什么说是真正来了呢?因为早在今年 4 月,Stability AI 就发布了 Stable Diffusion 3,但当时发布的并非开源版本,模型无法本地部署,只能通过 Stability AI 提供的 API 和服务来使用。2024 年 6 月 12 日发布的则是 Stable Diffusion 3 的 Medium 模型,拥有 20 亿参数。模型已经可以在 Huggingface 下载,国内很多网站也提供了镜像。
这次发布的 Medium 模型,也不是最新最强大的模型。毕竟 Stability AI 是一家商业公司,家底不能全部都无偿奉献出来。前段时间这家公司还爆出 CEO 出走、核心团队离职、亏损严重的新闻。不过 Stability AI 表示,未来还将开源 40 亿和 80 亿参数的大杯和超大杯版本。
如今,随着 Stable Diffusion 3 开源模型的发布,预示着国内图像生成技术会迎来新一轮的飞跃。
先回顾一下 Stable Diffusion 的优势。
- 高质量图像生成
Stable Diffusion通过先进的扩散模型,能够生成更高分辨率、更加细腻的图像。无论是细腻的光影变化,还是复杂的纹理细节,都能做到逼真自然。其生成的图像常常令人难以辨别真假,这在许多应用场景中尤为重要,比如影视特效、广告设计等。
- 开源与社区支持
Stable Diffusion 的开源特性使其具备了独特的活力和生命力。开源意味着透明与共享,全球开发者可以自由地访问、修改和微调模型。这不仅促进了技术的快速迭代和优化,也孕育了一个庞大且活跃的社区。社区成员之间的交流与合作,不断推动着技术的进步,使得 Stable Diffusion 能够快速响应用户需求,解决实际问题。
- 灵活性与可控性
Stable Diffusion 赋予了用户极高的自由度。通过调整不同的参数,用户可以生成风格各异的图像,从写实主义到抽象艺术,无不囊括其中。这种灵活性不仅满足了个人用户的创意需求,也为企业用户在各种商业应用中提供了广阔的发挥空间。此外,用户还可以在模型的基础上进行二次开发,进一步优化和定制,以适应特定的应用场景。
- 资源高效
相比一些需要庞大计算资源的模型,Stable Diffusion 以其高效的资源利用率赢得了广泛好评。得益于优化的算法和轻量级的架构设计,Stable Diffusion 能够在消费级显卡上高效运行。这意味着即便是个人开发者或小型团队,也能负担得起其所需的计算资源,从而在各自的项目中充分利用这项技术。
这次,Stable Diffusion 3 又带来了哪些令人兴奋的新功能呢?
- 全新的 多模态扩散变换器 (MMDiT) 架构
与以往版本相比,MMDiT 采用独立的权重集分别处理图像和语言表示,从而提升了模型对文本的理解能力,并改善了文本生成效果:
独立权重集:MMDiT 架构使用独立的权重集来处理图像和文本信息。这使得图像和文本能够在各自的空间中进行独立的处理,同时也能相互影响,提升模型对文本的理解能力和图像生成效果。
双向信息流:MMDiT 允许信息在图像和文本token之间双向流动。这意味着,模型不仅可以根据文本生成图像,还可以根据图像生成文本,并能更准确地将文本信息融入到图像中,提升图像质量和文本遵循度。
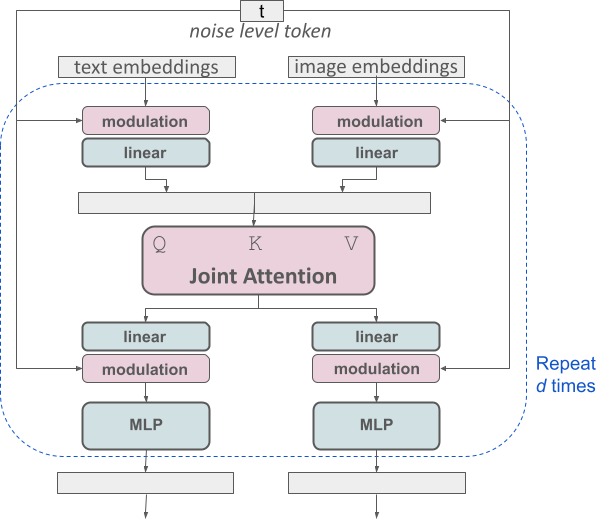
Stable Diffusion 3 采用了一种新颖的 修正流 (Rectified Flow, RF) 公式,通过将数据和噪声在训练过程中连接成线性轨迹,实现了更直接的推断路径,从而使用更少的采样步骤就能生成高质量的图像。此外,Stable Diffusion 3 还引入了新的 轨迹采样调度,对轨迹中间部分进行加权,从而提高模型在训练过程中的预测能力。
- 能力提升
与其他各种开放模型(包括 SDXL、SDXL Turbo、Stable Cascade、Playground v2.5 和 Pixart-α)以及 DALL·E 3、Midjourney v6 和 Ideogram v1 等闭源系统进行比较的结果表明,Stable Diffusion 3 在模型输出与给出的提示的上下文的接近程度("提示遵循")、文本根据提示的呈现效果("排版")以及哪幅图像的美学质量更高("视觉美学")等方面都表现优异。

- 硬件要求进一步降低
在实际应用中,Stable Diffusion 3 的 80 亿参数模型可以在 RTX 4090 显卡上运行,并能够在 34 秒内生成分辨率为 1024x1024 的图像。这次开源的 Stable Diffusion 3 medium 模型,只有 20 亿参数,体积小巧,非常适合在消费级 PC 和笔记本电脑以及企业级 GPU 上运行。(在我的 Nvidia RTX 2080 Ti 上也能运行)
结语
Stable Diffusion 3 的发布,标志着图像生成技术又一次重大的飞跃。通过一系列新功能的引入,Stable Diffusion 3不仅在生成质量和速度上有所提升,还在用户体验和扩展性方面展现出强大的优势。
需要注意的是,开源模型可通过开放的非商业许可证和低成本的 Creator 许可证获得。如需大规模商业使用,则需要授权许可。不过这对国内厂商来说都不是问题。国内的文生图应用又得忙活一阵子了。