在c语言中,我们常常在对有参函数进行传参,这样的繁琐过程,C++祖师爷对此进行了相关改进,多说无益,上干货:
1 缺省参数:
缺省参数 是指在声明或定义函数时为函数的形参指定一个默认值(默认参数)。在调用该函数时,如果没有指定实参,则采用该形参的缺省值;否则使用指定的实参。 缺省参数主要分为两种类型:全缺省参数 和半缺省参数
1.1 全缺省参数:
全缺省参数是指函数的所有参数都具有默认值。以下是一个全缺省参数的示例代码:
cpp
// 全缺省
void F2(int a = 10, int b = 20, int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl << endl;
}
int main()
{
F2(1, 2, 3);
F2(1, 2);
F2(1);
F2();
return 0;
}在上述代码中,我们会发现,有所不同的是在形参的位置上,我们给予了赋值,这样写又什么作用呢?唉~这样写当我们在调用的时候,少给参数的时候,编译器也不会报错,会自动给上默认值.同时也可以多种方式调用函数了.比如在上述代码中:F2(1,2,3)这样的调用时,上面形参的默认值就不会起作用了,而当我们F2(1,2)这样传参的时候,也不会报错,这是编译器会把a和b的值变为,1和2,而c的值就使用我们给的默认参数进行赋值30.同理可以去理解后两个调用,也可以一个都不传哦,这样形参用的全是我们所给的默认值.
1.2 半缺省参数:
半缺省参数是指从右往左连续地为函数的部分参数提供默认值。以下是一个半缺省参数的示例代码:
cpp
// 半缺省,从右往左缺省
void F3(int a, int b = 20 , int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl << endl;
}
int main()
{
F3(1);
F3(1, 2);
F3(1, 2, 3);
}在上述代码中,我们只是缺省了b和c,同样可以进行赋值,但是这时我们就不能一个参数也不传了,因为这时我们如果一个都不传的话,这时a是没有默认值的,编译器就会报错,半缺省参数必须从右往左依次提供默认值,不能间隔着给。为什么呢?请看下面的代码:
cpp
void F3(int a=10, int b = 20 , int c)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl << endl;
}
int main()
{
F3(1,2);
return 0;
}这时我们这样给默认值的时候,用F3(1,2)进行传参时,2可以赋值给c,但是这个1会赋值给谁呢?是a还是b呢?这是编译器就会存在歧义,就会报错喽,所以,我们平时在写半缺省参数的时候,应该极为注意.细心使用~
1.3 缺省参数的注意事项:
注意:
使用缺省参数可以提高代码的灵活性和可读性,减少函数调用时的参数传递数量。但需要注意以下几点:
- 半缺省参数必须 从右往左依次 来给出,不能间隔着给
- 缺省参数不能在函数声明和定义中同时出现,如果要给,只能在声明的时候给缺省值
- 缺省值必须是常量或者全局变量
- C 语言不支持(编译器不支持)
- 如果声明与定义位置同时出现,恰巧两个位置提供的值不同,那编译器就无法确定到底该
用那个缺省值。
6.缺省参数在后续的使用中尤为重要,尤其是数据结构中.
2 函数重载:
在C语言中,不支持重名函数存在,这就让一些程序很麻烦,比如要写一个整形数据的交换和浮点数的交换就不行,那么C++祖师爷就改进了这一点---函数重载
在同一作用域内,可以有多个具有相同函数名但参数列表不同(参数的类型、个数或顺序不同)的函数 。这些函数就被称为重载函数 。
那么具体什么是重载函数呢?请看代码:
cpp
namespace bit1
{
void Swap(int* pa, int* pb)
{
cout << "void Swap(int* pa, int* pb)" << endl;
}
}
namespace bit2
{
void Swap(int* px, int* py)
{
cout << "void Swap(int* pa, int* pb)" << endl;
}
}这样的两个函数构不构成重载呢?
显然它们在不同的命名空间中,不符合重载函数中的属于同一作用域这一条件,所以上述两个函数不构成函数重载.让我们来看一下另一个示例:
cpp
namespace bit1
{
void Swap(int* pa, int* pb)
{
cout << "void Swap(int* pa, int* pb)" << endl;
}
}
namespace bit2
{
void Swap(int* px, int* py)
{
cout << "void Swap(int* pa, int* pb)" << endl;
}
}
using namespace bit1;
using namespace bit2;如果把它们两个的命名空间展开,是否构成函数重载呢?
显然也是不构成重载的,因为"using namespace"只是把他们展开供全局可以使用这两个命名空间中的成员,并不意味着它们合并同一个作用域,所以还是不符合重载函数中的属于同一作用域这一条件,不构成函数重载,那么怎么才能构成呢?请看正确示例:
2.1 类型一:参数类型不同:
cpp
void Swap(int* pa, int* pb)
{
cout << "void Swap(int* pa, int* pb)" << endl;
}
void Swap(double* pa, double* pb)
{
cout << "void Swap(double* pa, double* pb)" << endl;
}上述代码就满足了重载函数的条件:参数类型不同.可以看到上述代码中,形参的类型不同,一个是int,一个是double,当然还可以写其他类型等等等...这样就可以使函数的功能变得更加丰富!
2.2 类型二:参数个数不同:
cpp
void f()
{
cout << "f()" << endl;
}
void f(int a)
{
cout << "f(int a)" << endl;
}在上述代码中:显而易见这两个函数的参数个数不同,第一个函数无参,第二个函数有一个整形参数a,可以构成重载函数.
2.3 类型三:参数顺序不同:
cpp
void f(int a, char b)
{
cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{
cout << "f(char b, int a)" << endl;
}大眼一看,好像是一样的,仔细的小伙伴就会发现,上述两个函数的参数的顺序好像不一样,第一个函数是(int a,char b),第二个函数参数是(char b,int a)这样也是可以构成函数重载的哦~
2.4 函数重载的注意事项:
-
参数类型必须不同:重载的函数之间参数的类型要有明显区别,不能仅通过可隐式转换的类型差异来重载。
-
参数个数不同:这是常见的重载方式之一。
-
参数顺序不同:也可以作为重载的依据,但要注意使用时的清晰性。
-
不能仅靠返回值不同来重载:因为调用时通常不关心返回值来确定调用哪个重载函数。
-
作用域要明确:确保重载的函数都在同一个合理的作用域内,避免混淆。
-
避免过度重载:过多的重载可能导致代码复杂难以理解和维护。
-
注意歧义:确保参数的组合不会导致调用时产生歧义,编译器能明确地选择正确的重载函数。
-
考虑可读性:重载函数的命名和功能设计要符合逻辑,便于其他开发者理解和使用。
3 C++支持函数重载的原理---名字修饰原则:(选看)
为什么C++ 支持函数重载,而 C 语言不支持函数重载呢?
这是因为在 C/C++ 中,一个程序要运行起来,需要经历以下几个阶段: 预处理、编译、汇编、链接
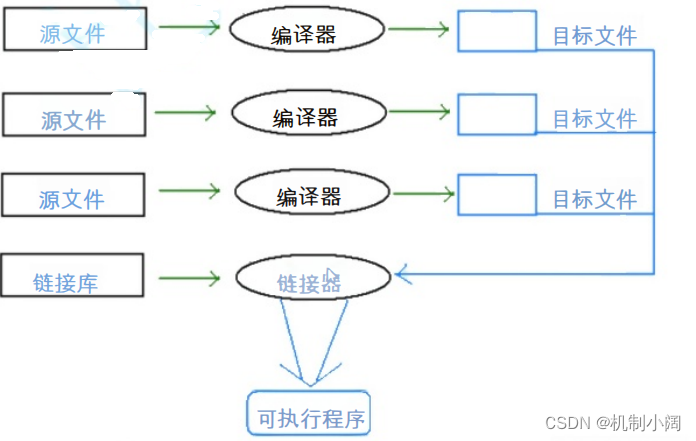

- 实际项目通常是由多个头文件和多个源文件构成,而通过 C 语言阶段学习的编译链接,我们
可以知道,【当前 a.cpp 中调用了 b.cpp 中定义的 Add 函数时】,编译后链接前, a.o 的目标
文件中没有 Add 的函数地址,因为 Add 是在 b.cpp 中定义的,所以 Add 的地址在 b.o 中。那么
怎么办呢? - 所以链接阶段就是专门处理这种问题, 链接器看到 a.o 调用 Add ,但是没有 Add 的地址,就
会到 b.o 的符号表中找 Add 的地址,然后链接到一起 。 ( 老师要带同学们回顾一下 ) - 那么链接时,面对 Add 函数,链接接器会使用哪个名字去找呢?这里每个编译器都有自己的
函数名修饰规则。 - 由于 Windows 下 vs 的修饰规则过于复杂,而 Linux 下 g++ 的修饰规则简单易懂,下面我们使
用了 g++ 演示了这个修饰后的名字。 - 通过下面我们可以看出 gcc 的函数修饰后名字不变。而 g++ 的函数修饰后变成【 _Z+ 函数长度
+ 函数名 + 类型首字母】。
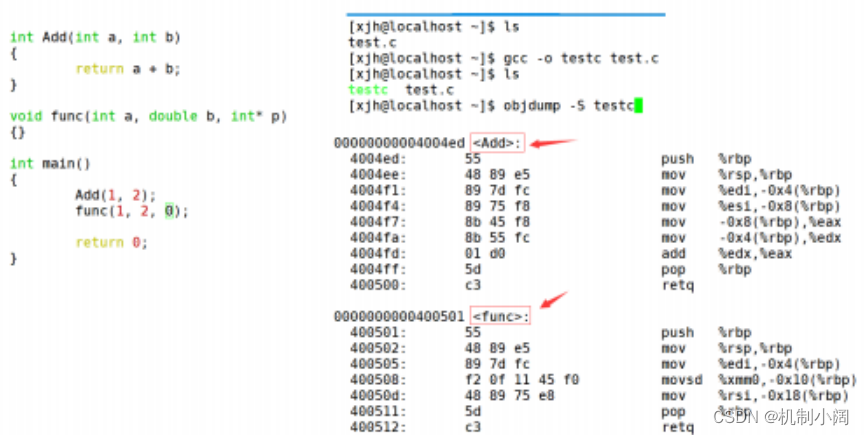
结论: 在 linux 下,采用 gcc 编译完成后,函数名字的修饰没有发生改变。 采用 C++ 编译器编译后结果.

结论: 在 linux 下,采用 g++ 编译完成后,函数名字的修饰发生改变,编译器将函数参 数类型信息添加到修改后的名字中。
Windows 下名字修饰规则:
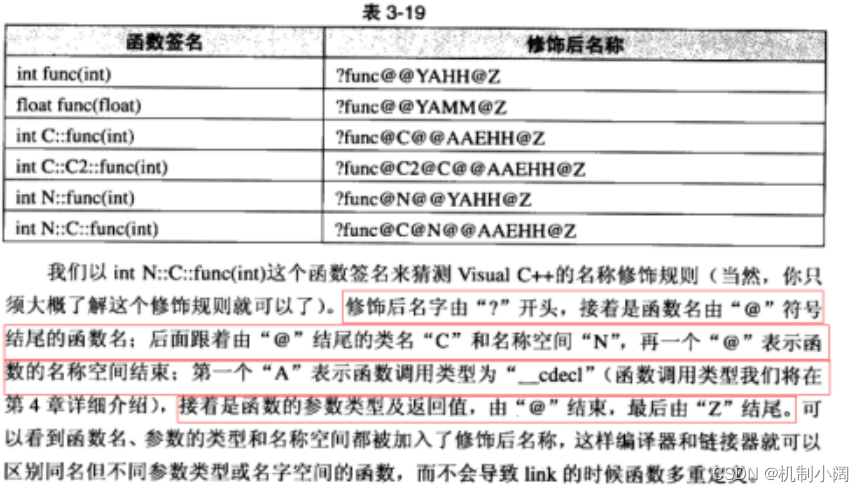
对比 Linux 会发现, windows 下 vs 编译器对函数名字修饰规则相对复杂难懂 ,但道理都
是类似的,我们就不做细致的研究了。 - 通过这里就理解了 C 语言没办法支持重载,因为同名函数没办法区分。而 C++ 是通过函数修
饰规则来区分,只要参数不同,修饰出来的名字就不一样,就支持了重载 。 - 如果两个函数函数名和参数是一样的,返回值不同是不构成重载的,因为调用时编译器没办
法区分。
到此有关缺省参数和函数重载的只是就讲解到这啦~希望这篇博客能给您带来一些启发和思考!那我们下次再一起探险喽,欢迎在评论区进行讨论~~~