链接参考 https://zhuanlan.zhihu.com/p/435908830
主要介绍GEMM中的数据分块和如何在多级存储进行数据搬运,HPC优化的核心思想,怎么样让数据放在更近的存储上来掩盖计算的延时,从而减少存储墙的影响
从global memory到shared memory
假设有矩阵A,B,需要计算矩阵A和B的乘,即矩阵C。A/B/C三个矩阵的维度分别为m*k,k*n,m*n,且三个矩阵中的数据都是单精度浮点数。对于C中的每一个元素,Cij,可以看作是A的一行和B的一列进行一次归约操作。采用最navie的GEMM算法,在GPU中,一共开启m*n个线程,每个线程需要读取矩阵A的一行和矩阵B的一列,而后将计算结果写回矩阵C中。因而,完成计算一共需要从global memeory中进行2mnk次读操作和m*n次写操作。大量的访存操作使得GEMM效率难以提高,因而考虑global memory中进行分块,并将矩阵块放置到shared memory中。示意图如下
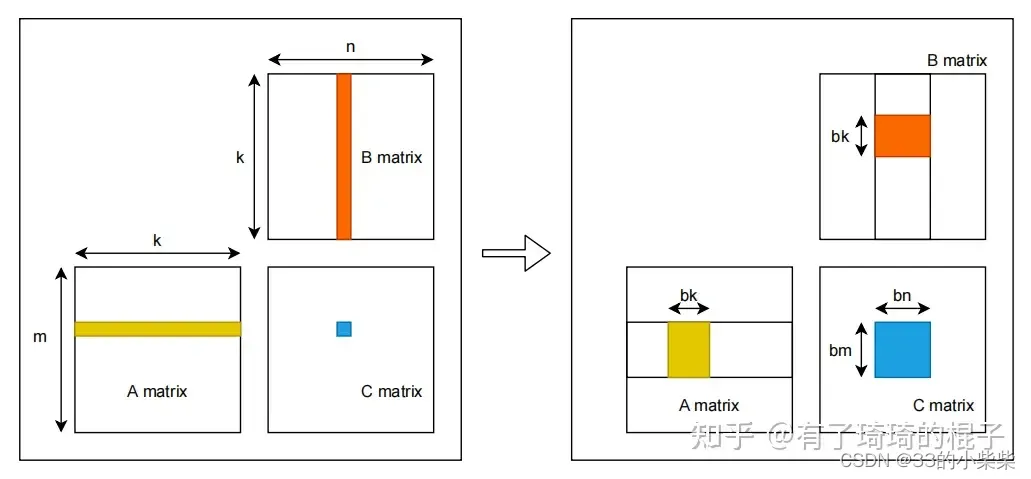 对global memory进行分块的GEMM算法示意图见上图右侧。首先将A/B/C三个矩阵划分为多个维度为bm*bk,bk*bn,bm*bn的小矩阵块 。三个矩阵形成M*K,K*N,M*N的小矩阵网格 。其中,M=m/bm,N=n/bn,K=k/bk。随后在GPU中开启M*N个block,每个block负责C中一个维度为bm*bn的小矩阵块的计算。计算一共有K次迭代,每次迭代都需要读取A中一个维度为bm*bk的小矩阵块和B中的一个维度为bk*bn的小矩阵块,并将其都放置在shared memory中。因而,完成C中所有元素的计算一共需要从global memory中读取M*N*K*(bm*bk+bk*bn) ,即m*n*k(1/bm+1/bn)个单精度浮点数。相比于navie的GEMM算法,访存量减少为原来的1/2*(1/bm+1/bn)。通过global memory中分块算法极大减少了对global memory的访存量。并且相对于navie算法,对global进行分块可以更充分地利用数据局部性 。在navie算法中,每一个线程都需要直接从global memory中取数,其延时非常长,计算性能非常差。而进行分块后,将维度为bm*bk,bk*bn的小矩阵块先存储到shared memory中 。而后计算单元进行计算时可以直接从shared memory中取数,大大减少了访存需要的时延。
对global memory进行分块的GEMM算法示意图见上图右侧。首先将A/B/C三个矩阵划分为多个维度为bm*bk,bk*bn,bm*bn的小矩阵块 。三个矩阵形成M*K,K*N,M*N的小矩阵网格 。其中,M=m/bm,N=n/bn,K=k/bk。随后在GPU中开启M*N个block,每个block负责C中一个维度为bm*bn的小矩阵块的计算。计算一共有K次迭代,每次迭代都需要读取A中一个维度为bm*bk的小矩阵块和B中的一个维度为bk*bn的小矩阵块,并将其都放置在shared memory中。因而,完成C中所有元素的计算一共需要从global memory中读取M*N*K*(bm*bk+bk*bn) ,即m*n*k(1/bm+1/bn)个单精度浮点数。相比于navie的GEMM算法,访存量减少为原来的1/2*(1/bm+1/bn)。通过global memory中分块算法极大减少了对global memory的访存量。并且相对于navie算法,对global进行分块可以更充分地利用数据局部性 。在navie算法中,每一个线程都需要直接从global memory中取数,其延时非常长,计算性能非常差。而进行分块后,将维度为bm*bk,bk*bn的小矩阵块先存储到shared memory中 。而后计算单元进行计算时可以直接从shared memory中取数,大大减少了访存需要的时延。
从shared memory到register
随后,我们进一步考虑从shared memory到register的过程。在这里,只分析一个block中的计算。当进行K轮迭代中某一轮迭代时,GPU将维度为bm*bk,bk*bn的小矩阵块存储到shared memory中,而后各个线程将shared memory中的数据存入register中进行计算。
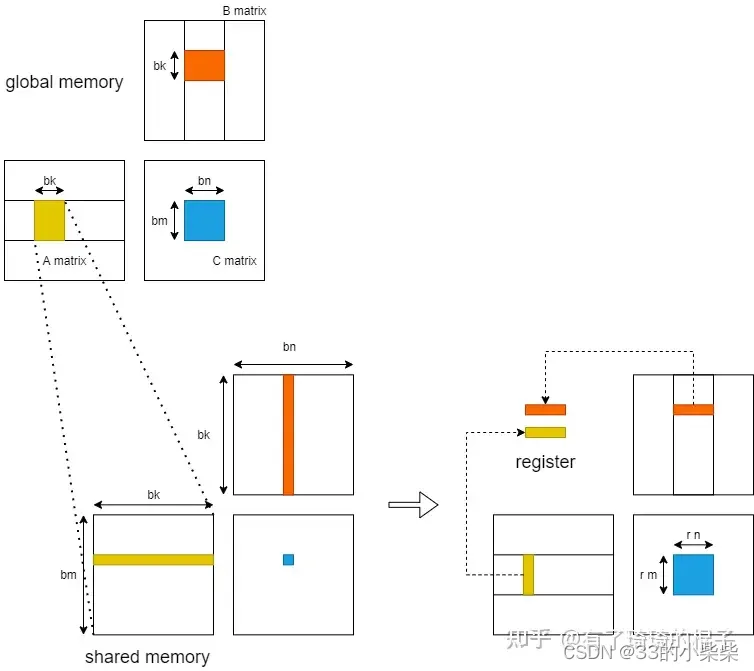
在不对shared memory分块 时,一个block中含有bm*bn个线程,每一个线程负责C中一个元素的计算 。则一个block分块一共需要对shared memory进行2*bm*bn*bk 次读操作。而后考虑对shared memory进行分块 ,对bm*bn的小矩阵进行再一次划分,将其划分为多个维度为rm*rn的子矩阵。则一个block需要负责X*Y个子矩阵。其中,X=bm/rm,Y=bn/rn。随后,在一个block中开启X*Y个线程,每个线程负责一个维度为rm*rn的子矩阵的计算 。在计算中,一个block一共需要从shared memory读取X*Y*(rm+rn)*bk ,即bm*bn*bk*(1/rm+1/rn)个单精度浮点数。相比于未分块的算法,对于shared memory中的访存量减少为原来的1/2*(1/rm+1/rn)。并且将数据放入register中,可以直接对数据进行运算,减少了从shared memory中取数的时延。
rigister分块
考虑register中的计算,并且只分析一个thread。在完成以上的过程后,对于一个线程而言,它现在拥有:rm个A矩阵的寄存器值,rn个B矩阵的寄存器值,一级rm*rn个C矩阵的寄存器值。通过这些寄存器的值,需要计算rm*rn个数。者需要rm*rn条FFMA指令。
这个时候回涉及到寄存器的bank conflict。在nv的GPU中,每个SM不仅会产生shared memory之间的bank冲突,也会产生寄存器之间的bank冲突。这对于计算密集型的算子十分重要。像shared memory一样,寄存器的Redgister File也会被分为几个bank,如果一条指令的源寄存器有2个以上来自同一bank,就会产生冲突。指令会重发射,浪费一个cycle。
我们假设对这个thread来说,rm=4,rn=4。并且计算C的寄存器以一种非常navie的情况分配,如下图所展示。则需要产生16条FFMA指令,列举如下:
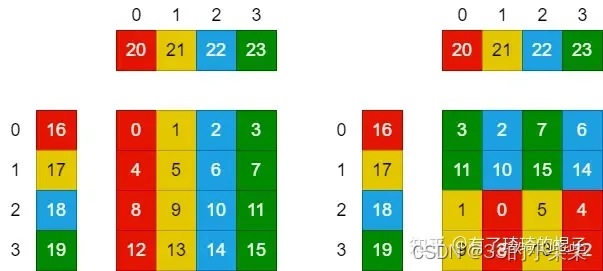
需要对参与计算的寄存器重新进行分配和排布,如上图右侧所示。在有些地方,这种方式也可以叫做register分块。
数据的prefetch
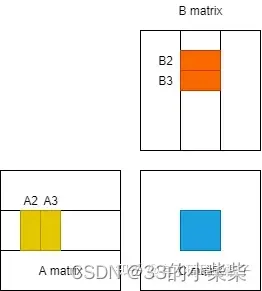
最后,如何通过对数据进行prefetch(预取)来减少访存的latency(延迟)。回顾GEMM的过程,并且仔细地看看这个访存的latency到底时怎么导致的。对于一个block而言,需要计算一个bm*bn的矩阵块,这个时后需要进行K次迭代,每次迭代都需要先将来自A和B的两个小块送到shared memory中再进行计算。而从global中访存实际上时非常慢的所以导致latency。虽然GPU中可以通过block的切换来掩盖这种latency,但是由于分配的shared memory比较多,活跃的block并不太多,所以延时很难被掩盖。对于一个thread,需要计算一个rm*rn的小矩阵,但是必须先将数据从shared memory传到寄存器上,才能开始计算。所以导致了每进行一次迭代,计算单元就需要停下来等待,计算单元不能被喂饱。
为此,需要进行数据的prefetch来尽可能地掩盖这种latency。需要多开一个buffer,进行读写分离。示意图如下。当block进行第二轮迭代时,需要对A2和B2进行计算,再计算单元进行计算的同时,我们将A3和B3提前放置到shared memory。而后,在进行第3轮迭代时,就可以直接对shared memory中的A3和B3进行计算,而不需要等待从global memory 搬运到shared memory的时间。寄存器上的prefetch也是同理。