引言
在语音增强、语音合成、语音转换、声音转换、语音克隆、语音修复等等领域,常常要对输出的语音进行评价。对语音的质量评价一般关注两个方面,即主观评价和客观评价。主观评价就是人凭借听觉感受对语音进行打分,客观评价比较广泛,有的是通过计算输出语音与目标语音之间的声学参数之间的差异来衡量输出语音的质量;有的是依靠仪器测试响度、频率响应、灵敏度等指标;有的依靠模型和算法,模拟人工打分。
- 主观评价方法:MOS、CMOS、ABX(XAB)、Mushar、PESQ...
- 客观评价方法:MCD、MSD 、MEL loss、F0 MSE、F0RMSE、F0 CC、E MSE、 DurMSE...
注:
这些评价方法并不都是相互独立的,如:F0 MSE、F0RMSE是计算最小均方误差和最小均方根误差。有一定的相似性。
这些评价方法在不同的领域评价又有一定的区别。评估的目的不同,所用的评估方法也不同。
平均意见得分MOS
早期语音质量的评价方式是凭主观的,人们在打通电话之后通过人耳来感知语音质量的好坏。1996年国际ITU组织在ITU-T P.800(电话传输系统语音质量主观评价)和P.830(电话宽带和宽带数字语音编解码器主观评价方法)建议书开始制订相关的评测标准,即MOS(Mean Opinion Score)测试。
平均主观值MOS是广泛认同的语音质量标准。因此,无论采用何种方法,所有测量方法所得到的结果都必须对应到最终的平均主观值MOS。
评价标准
它是一种主观测试方法,将用户接听和感知语音质量的行为进行调研和量化,由不同的调查用户分别对原始标准语音和经过无线网传播后的衰退声音进行主观感受对比,评出MOS分值。评价为5分制,标准如下:
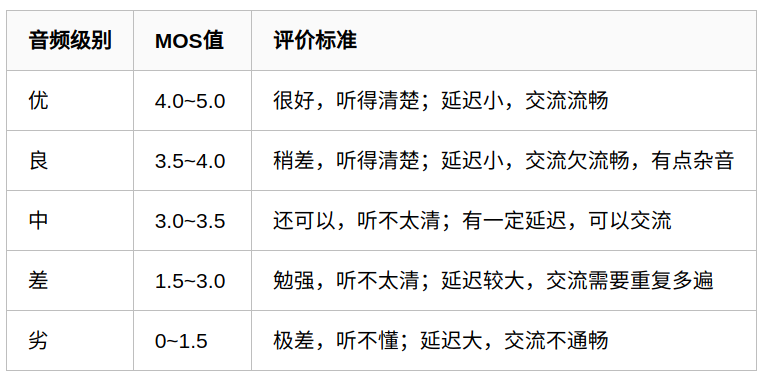
与评测的人员对语音整体质量进行打分,分值范围为1-5分,分数越大表示语音质量最好。
一般MOS应为4或者更高,这可以被认为是比较好的语音质量,若MOS低于3.6,则表示大部分被测不太满意这个语音质量。
MOS测试一般要求:
- 足够多样化的样本(即试听者和句子数量)以确保结果在统计上的显著;
- 控制每个试听者的实验环境和设备保持一致;
- 每个试听者遵循同样的评估标准。
评价规则
标准中的测试规则主要定义几点:
-
参考的标准音频和被测试音频间隔测试,连续重复4次;
-
音频源采用15~20s;
-
一次完整的测试时间不应超过15~20min;
-
测试成员:专家成员最少10人,非专家20人。(语音合成需至少40人)
-
如果预先定义评分值,则不需要对单个评分值做归一化,否则需要归一化处理。
-
评分可以采用5分或者7分制,也有嫌它不够精细的,用10分20分的。
-
所测语音材料要足够丰富,测试环境要尽量保持相同。
评价内容
对于语音合成系统,评估的内容也包含三个方面,即合成语音的清晰度,可懂度,自然度。
对于语音转换系统,一般评估
语音合成中的MOS
对于语音合成(文语转换TTS)系统,评估的工作有三个方面的任务和目的:
- 对比不同的合成系统或算法,排出位次;
- 对某个系统或算法进行诊断,指出其不足之处和问题所在;
- 应用评价,确定某系统是否适应某种应用。
对于语音合成系统,评估的内容也包含三个方面,即合成语音的清晰度,可懂度,自然度:
- 清晰度:针对语音中词以下的语音单元(音素、声母、韵母等)的清晰度;
- 可懂度:针对语音中词以上的语言单元(如字、单词和句子等)的可懂程度;
- 自然度:指的是更高一层的内容,如短语、句子、篇章等方面的整体自然水平。
合成语音质量的评估,不但与语音学、语言学相关、而且与心理学也有着密切的联系。
MOS不仅用于语音编码、通信设备的性能测试上,也可用于语音合成系统的整体评估,1994年国际ITU组织在ITU-T P.85(语音输出设备质量的主观性能评测方法),根据该建议草案,选择10-30句语音测试材料,从8个方面用5分制MOS进行打分。
- 整体印象:整体感觉如何
- 可接受度:你认为这种声音是否可以在某个应用领域上做信息服务?
- 收听效果、注意力:需要多大的专心或注意力程度才能听懂语音
- 理解难度:句子的意思是不是说清楚了?是否有些词不好理解
- 清晰度:声音是不是清晰可辨?
- 发音:发音中的规则让人不舒服的程度
- 声音的悦耳程度:声音好听吗?
- 讲话速度:速度快,慢,还是正常?
在P.85中虽然没有给出整体印象的5个等级的具体定义,但其他7个方面都给出了5个等级的具体说明。可以用计权平均的方法得到总体的满意度评价,也可以综合这几个方面给出一个主观的评价得分。
附语音合成论文中计算MOS的脚本,其不仅强调MOS值,并且要求95%的置信区间内的分数:
python
# -*- coding: utf-8 -*-
# @FileName: caculate_MOS.py
import math
import numpy as np
import pandas as pd
from scipy.linalg import solve
from scipy.stats import t
def calc_mos(data_path: str):
'''
计算MOS,数据格式:MxN,M个句子,N个试听人,data_path为MOS得分文件,内容都是数字,为每个试听的得分
:param data_path:
:return:
'''
data = pd.read_csv(data_path)
mu = np.mean(data.values)
var_uw = (data.std(axis=1) ** 2).mean()
var_su = (data.std(axis=0) ** 2).mean()
mos_data = np.asarray([x for x in data.values.flatten() if not math.isnan(x)])
var_swu = mos_data.std() ** 2
x = np.asarray([[0, 1, 1], [1, 0, 1], [1, 1, 1]])
y = np.asarray([var_uw, var_su, var_swu])
[var_s, var_w, var_u] = solve(x, y)
M = min(data.count(axis=0))
N = min(data.count(axis=1))
var_mu = var_s / M + var_w / N + var_u / (M * N)
df = min(M, N) - 1 # 可以不减1
t_interval = t.ppf(0.975, df, loc=0, scale=1) # t分布的97.5%置信区间临界值
interval = t_interval * np.sqrt(var_mu)
print('{} 的MOS95%的置信区间为:{} +---{} '.format(data_path, round(float(mu), 3), round(interval, 3)))
if __name__ == '__main__':
data_path = ''
calc_mos(data_path)