引言
先看问题:
我手边有一数据集,然后我想分分类!~~·
咳咳,最近刚做了一个:训练集有1143张,分为5类,里面图片是打乱的。测试集有248张,想把它分分类看看咋样。
再看一下效果:
这是经过100轮训练后准确率。(准确率最高也就72%左右,要想再升高就要改变数据集或者改网络了)
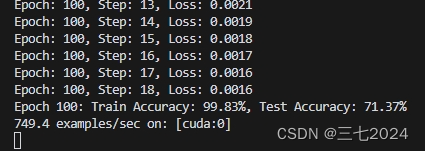
同时我们也将训练后的结果保存到了文件夹里。

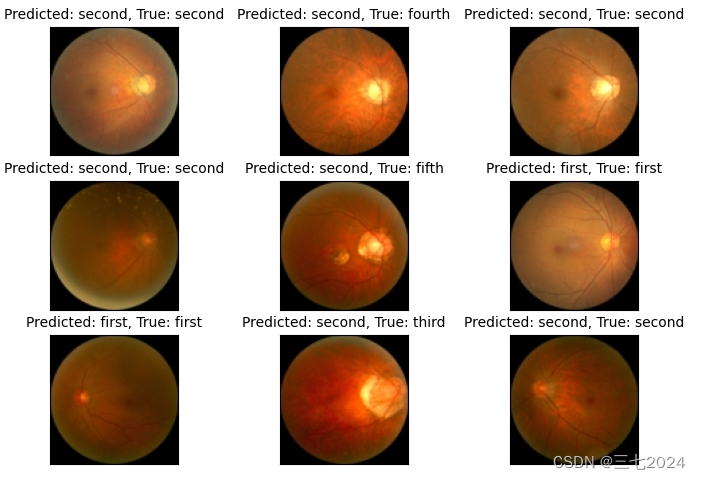
经过网络训练后,最后的显示图:
预测第一张图属于第二类,它的确也确实属于第二类;但第二张图预测它是第二类,但是它事实上属于第四类。
操作
一、明确知道代码结构流程
① Prepare dataset 构建数据集
② Design model using Class 设计模型
③ Construct loss and optimizer 构造损失函数和优化器
④ Training 训练
⑤ Prediction 预测结果(第五步可适当补充想生成的图像)
二、写代码
1.构建数据集
在写代码的时候,如果数据集都构建不好,后续都不用进行了。
接下来,我们简单说一下两种数据集构建代码。
(1) torchvision内置的数据集
这种就是最为简单的一种,可以直接调用的。如 MNIST、Fashion-MNIST、EMNIST、COCO、LSUN、ImageFolder、DatasetFolder、Imageenet-12、CIFAR、STL10 等。
下面简单以 CIFAR-10 为例:
a. 下载
CIFAR-10 and CIFAR-100 datasets (toronto.edu)
(下载解压后如下,并将文件夹放入一个新的文件夹 CIFAR 里,并将该文件夹放入另一个文件夹SH1中。)

大致构建如下:

b. 简单介绍 CIFAR-10

The CIFAR-10 dataset consists of 60000 32x32 colour images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images.The dataset is divided into five training batches and one test batch, each with 10000 images. The test batch contains exactly 1000 randomly-selected images from each class. The training batches contain the remaining images in random order, but some training batches may contain more images from one class than another. Between them, the training batches contain exactly 5000 images from each class.
(该数据集包含10个类别的60000张32x32彩色图像,每类有6000张图像。其中,有50000张用于训练,10000张用于测试。数据集被分为五个训练批次和一个测试批次,每批包含10000张图像。测试批次包含每个类别中随机选取的1000张图像。训练批次按照随机顺序包含剩余的图像,但有些训练批次可能包含某一类图像的数量多于另一类。在它们之间,训练批次包含每类5000张图像.)
c. 下载并配置数据集及加载器
Delphi
# 下载并配置数据集
trans = transforms.Compose(
[transforms.Resize((96, 96)), transforms.ToTensor()])
train_dataset = datasets.CIFAR10(
root=r'D:\SH1\CIFAR', train=True, transform=trans)
test_dataset = datasets.CIFAR10(
root=r'D:\SH1\CIFAR', train=False, transform=trans)
# 配置数据加载器
batch_size = 64
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset=test_dataset,
batch_size=batch_size, shuffle=True)-
trans = transforms.Compose(transforms.Resize((96, 96)), transforms.ToTensor()): 这行代码创建了一个数据转换操作的组合 trans,其中包括将图像大小调整为 (96, 96) 并将其转换为张量的操作。
-
train_dataset = datasets.CIFAR10(root=r'D:\SH1\CIFAR', train=True, transform=trans): 这行代码创建了一个 CIFAR-10 数据集的训练集 train_dataset,指定了数据集的根目录和使用的数据转换操作。
-
test_dataset = datasets.CIFAR10(root=r'D:\SH1\CIFAR', train=False, transform=trans): 这行代码创建了一个 CIFAR-10 数据集的测试集 test_dataset,同样指定了数据集的根目录和使用的数据转换操作。
-
batch_size = 64: 这行代码定义了批量大小为 64。
-
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True): 这行代码创建了一个训练数据加载器 train_loader,用于加载训练数据集,指定了数据集、批量大小和是否打乱数据顺序。
-
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=True): 这行代码创建了一个测试数据加载器 test_loader,用于加载测试数据集,同样指定了数据集、批量大小和是否打乱数据顺序。
(2)我们自己手里的数据集
a. 整理标签
以上上周我们老师给我的数据集为例。老师给我的数据集里面包含训练集和测试集以及相应的标签。

但是标签里面的信息太多了,我只需要它的名称以及类别。
以Training_Labels为例,我只需要第一列 image 和 第二列 myopic_maculopathy_grade。

import pandas as pd
# 读取原始标签文件
df_train = pd.read_csv('Training_labels.csv')
df_test = pd.read_csv('Testing_labels.csv')
# 提取所需字段
new_df_train = df_train[['image', 'myopic_maculopathy_grade']]
new_df_test = df_test[['image', 'myopic_maculopathy_grade']]
# 重命名列
new_df_train.columns = ['filename', 'label']
new_df_test.columns = ['filename', 'label']
# 保存新的标签文件
new_df_train.to_csv('train_labels.csv', index=False)
new_df_test.to_csv('test_labels.csv', index=False)所以我通过上面的代码将第一列和第二列进行了提取,并且改成了:filename', 'label',生成了另外的标签。

同样以train_Labels为例:

b. 定义一个自定义数据集类
我们要定义一个自定义数据集类 CustomDataset , 用于加载图像数据集并返回及其对应的标签。
class CustomDataset(Dataset):
def __init__(self, csv_file, root_dir, transform=None):
self.labels_df = pd.read_csv(csv_file)
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.labels_df)
def __getitem__(self, idx):
img_name = os.path.join(self.root_dir, self.labels_df.iloc[idx, 0])
try:
image = Image.open(img_name)
except FileNotFoundError:
print(f"File not found: {img_name}")
raise
label = int(self.labels_df.iloc[idx, 1]) # 使用标签列
if self.transform:
image = self.transform(image)
return image, label-
class CustomDataset(Dataset)::定义了一个名为 CustomDataset 的类,该类继承自 Dataset 类,用于创建自定义数据集。
-
def init(self, csv_file, root_dir, transform=None)::定义了类的初始化方法,接受三个参数:csv_file 表示包含标签信息的 CSV 文件路径,root_dir 表示图像文件所在的根目录,transform 表示数据转换操作,默认为 None。
-
self.labels_df = pd.read_csv(csv_file): 从给定的 CSV 文件中读取标签信息并存储在 labels_df 中。
-
self.root_dir = root_dir:将图像文件的根目录路径存储在 root_dir 中。
-
self.transform = transform:存储数据转换操作,例如将图像转换为张量等。
-
def len(self)::定义了 len 方法,返回数据集的长度,即标签信息的数量。
-
def getitem(self, idx)::定义了 getitem 方法,用于获取数据集中特定索引 idx 处的图像及其标签。
-
img_name = os.path.join(self.root_dir, self.labels_df.ilocidx, 0):构建图像文件的完整路径。
-
try...except...:尝试打开图像文件,如果文件不存在则捕获 FileNotFoundError 异常并打印错误信息。
-
label = int(self.labels_df.ilocidx, 1):从标签数据中提取标签信息,转换为整数类型。
-
if self.transform::检查是否存在数据转换操作。
-
image = self.transform(image):如果存在数据转换操作,则对图像进行相应的转换。
-
return image, label:返回处理后的图像及其对应的标签。
c. 配置数据集及加载器
# 定义数据转换
trans = transforms.Compose([transforms.Resize((96, 96)), transforms.ToTensor()])
# 创建自定义数据集
train_dataset = CustomDataset(csv_file='train_labels.csv', root_dir='training', transform=trans)
test_dataset = CustomDataset(csv_file='test_labels.csv', root_dir='testing', transform=trans)
# 配置数据加载器
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=0) # 设置 num_workers=0 以避免多线程问题
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=True, num_workers=0)( 由于这个代码和下载并配置CIFAR-10数据集及加载器的代码差不多,刚才仔细讲过了,所以这里就不再讲一遍了)
2. 设计模型
我们用的是ResNet-18网络,要想更好的理解这个网络,我们需要了解一个知识点----残差块。
在 ResNet-18 中,残差块起着关键的作用,通过**引入跳跃连接(skip connection)**来缓解深层神经网络中的梯度消失问题,从而使得训练更深层的网络成为可能。具体来说:
-
跳跃连接:在每个残差块中,通过将输入直接与输出相加(即跳跃连接),实现了从底层到顶层的直接信息传递。这种跳跃连接有助于梯度的流动,避免了梯度在深层网络中逐渐消失的问题。
-
缓解梯度消失:由于跳跃连接的存在,即使在深层网络中,梯度可以通过跳跃连接直接传播到较浅层,从而减轻了梯度消失问题,使得网络更容易训练。
-
增强网络性能:残差块的设计使得网络更加深层时仍能保持较好的性能,因为网络可以更好地学习残差(即残差块的输出与输入之间的差异),而不是直接学习原始特征。
了解后,我们要了解一下网络的结构图:
经典CNN网络:Resnet18网络结构输入和输出通俗易懂-腾讯云开发者社区-腾讯云 (tencent.com)
(网上有很多资料,我随便找了一个,应该还是比较容易的)
接下来,我们讲下代码:
(1) 残差块
class Residual(nn.Module):
# 残差块
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
# self.bn1(...):对卷积层的输出应用第一个批量归一化层,F.relu(...): 对归一化后的输出应用ReLU激活函数,Y: 存储激活后的输出
Y = F.relu(self.bn1(self.conv1(X)))
# Y: 更新Y为第二个卷积层和归一化后的输出
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X # Y += X: 将输入X(或经过1x1卷积层的X)加到Y上,实现残差连接。
return F.relu(Y)-
class Residual(nn.Module)::定义了一个名为 Residual 的类,继承自 nn.Module 类,表示这是一个 PyTorch 模型。
-
def init(self, input_channels, num_channels, use_1x1conv=False, strides=1)::定义了类的初始化方法,接受输入通道数 input_channels、输出通道数 num_channels、是否使用 1x1 卷积 use_1x1conv 和步幅 strides 作为参数。
-
super().init():调用父类的初始化方法。
-
self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1, stride=strides): 创建第一个卷积层,使用 3x3 的卷积核,填充为 1,步幅为 strides。
-
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1): 创建第二个卷积层,输入通道数为 num_channels,输出通道数为 num_channels,使用 3x3 的卷积核,填充为 1。
-
if use_1x1conv::检查是否使用 1x1 卷积。
-
self.conv3 = nn.Conv2d(input_channels, num_channels, kernel_size=1, stride=strides): 如果使用 1x1 卷积,创建一个 1x1 的卷积层。
-
self.bn1 = nn.BatchNorm2d(num_channels): 创建第一个批量归一化层。
-
self.bn2 = nn.BatchNorm2d(num_channels): 创建第二个批量归一化层。
-
def forward(self, X)::定义了前向传播方法,接受输入 X。
-
Y = F.relu(self.bn1(self.conv1(X))): 应用第一个卷积层、批量归一化和 ReLU 激活函数。
-
Y = self.bn2(self.conv2(Y)): 应用第二个卷积层和批量归一化。
-
if self.conv3::检查是否存在第三个卷积层。
-
X = self.conv3(X): 如果存在第三个卷积层,应用该卷积层。
-
Y += X: 将输入 X(或经过 1x1 卷积层的 X)加到 Y 上,实现残差连接。
-
return F.relu(Y): 返回经过激活函数处理后的输出 Y。
(2) ResNet-18 网络
# ResNet-18
b1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(), # 批量归一化层,通道数为64, ReLU激活函数
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)) # 最大池化层,核大小为3x3,步幅为2,填充为1
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = [] # blk = []: 初始化一个空列表 blk,用于存储残差块。
for i in range(num_residuals):
if i == 0 and not first_block:
# blk.append: 将一个新的残差块添加到 blk 列表中。
blk.append(Residual(input_channels, num_channels,
use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels)) # 不使用1x1卷积层,步幅为默认值1。
return blk
# *: 解包操作符,将 resnet_block 返回的列表解包为单个参数传递给 nn.Sequential。
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
# nn.AdaptiveAvgPool2d((1, 1)):自适应平均池化层,将每个特征图的空间维度(高度和宽度)缩小到1x1。
# 作用是将不同大小的特征图统一到相同的输出尺寸。
# nn.Flatten():将多维特征图展平成一维向量
# 作用是将特征图转换为全连接层可以处理的输入格式
# nn.Linear(512, 5)):全连接层,输入维度为512,输出维度为5。
# 作用是将展平后的特征向量映射到 5个类别 .(例如,CIFAR-10数据集有10个类别)。
# 定义完整的ResNet模型
net = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(), nn.Linear(512, 5))
# nn.AdaptiveAvgPool2d((1, 1)), # 自适应平均
# nn.Flatten(), # 将特征图展平为一维向量
# nn.Linear(512, 5) # 全连接层,将特征向量映射到 5个类别(这段的讲解放在了代码里面)
3. 构造损失函数和优化器
lr = 0.001
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()-
lr = 0.001: 定义了学习率为 0.001,即优化器在更新模型参数时的步长大小。
-
optimizer = torch.optim.Adam(net.parameters(), lr=lr): 创建了一个 Adam 优化器,用于更新模型 net 中的参数。Adam 是一种常用的优化算法,通过调整学习率来最小化损失函数。
-
loss = nn.CrossEntropyLoss(): 创建了一个交叉熵损失函数,用于计算模型输出与真实标签之间的损失。交叉熵损失通常用于多分类问题,特别是在输出层使用 softmax 激活函数时。
4.训练
# 定义训练模型
epochs = 100
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def train(net, train_iter, test_iter, epochs, device):
# 初始化模型参数的权重
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
# 对模型应用初始化权重函数
net.apply(init_weights)
# 打印当前训练使用的设备
print(f'Training on: [{device}]')
# 将模型移动到指定的设备上进行训练
net.to(device)
# 创建计时器和获取训练数据迭代器的长度
timer, num_batches = d2l.Timer(), len(train_iter)
# 检查训练数据迭代器是否为空
if num_batches == 0:
print("No batches found in the training data.")
return
# 循环遍历每个训练轮数
for epoch in range(epochs):
# 训练损失之和,训练准确率之和,样本数
metric = d2l.Accumulator(3)
# 将模型设置为训练模式
net.train()
# 遍历训练数据迭代器
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad() # 清空优化器的梯度
X, y = X.to(device), y.to(device) # 将输入数据和标签移动到指定的设备上
y_hat = net(X) # 前向传播,获取模型的预测输出
l = loss(y_hat, y) # 计算模型输出与真实标签之间的损失
l.backward() # 反向传播,计算梯度
optimizer.step() # 更新模型参数
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0]) # 累积训练损失、准确率和样本数
timer.stop()
train_l = metric[0] / metric[2] # 计算平均训练损失
train_acc = metric[1] / metric[2] # 计算平均训练准确率
if (i + 1) % max(1, (num_batches // 30)) == 0 or i == num_batches - 1:
print(f'Epoch: {epoch + 1}, Step: {i + 1}, Loss: {train_l:.4f}') # 打印每个训练步骤的损失
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter) # 在测试集上评估模型的准确率
print(f'Epoch {epoch + 1}: Train Accuracy: {train_acc * 100:.2f}%, Test Accuracy: {test_acc * 100:.2f}%') # 打印每个训练轮数的训练准确率和测试准确率
# 确保保存目录存在
print(f'{metric[2] * epochs / timer.sum():.1f} examples/sec on: [{str(device)}]')
# 确保保存目录存在
save_dir = 'D:\\SH2\\result' # 这里我在SH2文件夹里新建了一个文件夹result,用于存放最后结果
os.makedirs(save_dir, exist_ok=True)
# 保存模型
torch.save(net.state_dict(), os.path.join(save_dir, f"ResNet-18_SHIYAN_Epoch{epochs}_Accuracy{test_acc * 100:.2f}%.pth"))
train(net, train_loader, test_loader, epochs, device)5. 预测结果
def show_predict():
# 预测结果图像可视化
net.to(device) # 将模型移动到指定设备
loader = DataLoader(dataset=test_dataset, batch_size=1, shuffle=True) # 创建数据加载器
plt.figure(figsize=(12, 8)) # 创建图像窗口
name = ('first', 'second', 'third', 'fourth', 'fifth') # 类别名称
for i in range(9):
(images, labels) = next(iter(loader)) # 获取图像和标签
images = images.to(device) # 将图像移动到指定设备
labels = labels.to(device) # 将标签移动到指定设备
outputs = net(images) # 获取模型输出
_, predicted = torch.max(outputs.data, 1) # 获取预测结果
title = f"Predicted: {name[int(predicted[0])]}, True: {name[int(labels[0])]}" # 设置标题
plt.subplot(3, 3, i + 1) # 创建子图
plt.imshow(images.cpu()[0].permute(1, 2, 0)) # 显示图像
plt.title(title, fontsize=10) # 设置标题
plt.xticks([]) # 隐藏x轴刻度
plt.yticks([]) # 隐藏y轴刻度
plt.show() # 显示图像
show_predict()三、总代码
import os
import pandas as pd
from PIL import Image
from torch.utils.data import Dataset
from torchvision import transforms
import torch
from d2l.torch import d2l
from torch import nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torch.nn import functional as F
import matplotlib.pyplot as plt
# import pandas as pd
# # 读取原始标签文件
# df_train = pd.read_csv('Training_labels.csv')
# df_test = pd.read_csv('Testing_labels.csv')
# # 提取所需字段
# new_df_train = df_train[['image', 'myopic_maculopathy_grade']]
# new_df_test = df_test[['image', 'myopic_maculopathy_grade']]
# # 重命名列
# new_df_train.columns = ['filename', 'label']
# new_df_test.columns = ['filename', 'label']
# # 保存新的标签文件
# new_df_train.to_csv('train_labels.csv', index=False)
# new_df_test.to_csv('test_labels.csv', index=False)
class CustomDataset(Dataset):
def __init__(self, csv_file, root_dir, transform=None):
self.labels_df = pd.read_csv(csv_file)
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.labels_df)
def __getitem__(self, idx):
img_name = os.path.join(self.root_dir, self.labels_df.iloc[idx, 0])
try:
image = Image.open(img_name)
except FileNotFoundError:
print(f"File not found: {img_name}")
raise
label = int(self.labels_df.iloc[idx, 1]) # 使用标签列
if self.transform:
image = self.transform(image)
return image, label
# 定义数据转换
trans = transforms.Compose([transforms.Resize((96, 96)), transforms.ToTensor()])
# 创建自定义数据集
train_dataset = CustomDataset(csv_file='train_labels.csv', root_dir='training', transform=trans)
test_dataset = CustomDataset(csv_file='test_labels.csv', root_dir='testing', transform=trans)
# 配置数据加载器
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=0) # 设置 num_workers=0 以避免多线程问题
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=True, num_workers=0)
# 这些代码定义了一个残差块(Residual Block),这是ResNet(残差网络)中的基本构建单元。
# 残差块的主要作用是通过引入跳跃连接(skip connection)来缓解深层神经网络中的梯度消失问题,从而使得训练更深层的网络成为可能。
class Residual(nn.Module):
# 残差块
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
# self.bn1(...):对卷积层的输出应用第一个批量归一化层,F.relu(...): 对归一化后的输出应用ReLU激活函数,Y: 存储激活后的输出
Y = F.relu(self.bn1(self.conv1(X)))
# Y: 更新Y为第二个卷积层和归一化后的输出
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X # Y += X: 将输入X(或经过1x1卷积层的X)加到Y上,实现残差连接。
return F.relu(Y)
# ResNet-18
b1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(), # 批量归一化层,通道数为64, ReLU激活函数
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)) # 最大池化层,核大小为3x3,步幅为2,填充为1
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = [] # blk = []: 初始化一个空列表 blk,用于存储残差块。
for i in range(num_residuals):
if i == 0 and not first_block:
# blk.append: 将一个新的残差块添加到 blk 列表中。
blk.append(Residual(input_channels, num_channels,
use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels)) # 不使用1x1卷积层,步幅为默认值1。
return blk
# *: 解包操作符,将 resnet_block 返回的列表解包为单个参数传递给 nn.Sequential。
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
# nn.AdaptiveAvgPool2d((1, 1)):自适应平均池化层,将每个特征图的空间维度(高度和宽度)缩小到1x1。
# 作用是将不同大小的特征图统一到相同的输出尺寸。
# nn.Flatten():将多维特征图展平成一维向量
# 作用是将特征图转换为全连接层可以处理的输入格式
# nn.Linear(512, 5)):全连接层,输入维度为512,输出维度为5。
# 作用是将展平后的特征向量映射到 5个类别 .(例如,CIFAR-10数据集有10个类别)。
# 定义完整的ResNet模型
net = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(), nn.Linear(512, 5))
# nn.AdaptiveAvgPool2d((1, 1)), # 自适应平均
# nn.Flatten(), # 将特征图展平为一维向量
# nn.Linear(512, 5) # 全连接层,将特征向量映射到 5个类别
lr = 0.001
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
# 定义训练模型
epochs = 100
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def train(net, train_iter, test_iter, epochs, device):
# 初始化模型参数的权重
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
# 对模型应用初始化权重函数
net.apply(init_weights)
# 打印当前训练使用的设备
print(f'Training on: [{device}]')
# 将模型移动到指定的设备上进行训练
net.to(device)
# 创建计时器和获取训练数据迭代器的长度
timer, num_batches = d2l.Timer(), len(train_iter)
# 检查训练数据迭代器是否为空
if num_batches == 0:
print("No batches found in the training data.")
return
# 循环遍历每个训练轮数
for epoch in range(epochs):
# 训练损失之和,训练准确率之和,样本数
metric = d2l.Accumulator(3)
# 将模型设置为训练模式
net.train()
# 遍历训练数据迭代器
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad() # 清空优化器的梯度
X, y = X.to(device), y.to(device) # 将输入数据和标签移动到指定的设备上
y_hat = net(X) # 前向传播,获取模型的预测输出
l = loss(y_hat, y) # 计算模型输出与真实标签之间的损失
l.backward() # 反向传播,计算梯度
optimizer.step() # 更新模型参数
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0]) # 累积训练损失、准确率和样本数
timer.stop()
train_l = metric[0] / metric[2] # 计算平均训练损失
train_acc = metric[1] / metric[2] # 计算平均训练准确率
if (i + 1) % max(1, (num_batches // 30)) == 0 or i == num_batches - 1:
print(f'Epoch: {epoch + 1}, Step: {i + 1}, Loss: {train_l:.4f}') # 打印每个训练步骤的损失
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter) # 在测试集上评估模型的准确率
print(f'Epoch {epoch + 1}: Train Accuracy: {train_acc * 100:.2f}%, Test Accuracy: {test_acc * 100:.2f}%') # 打印每个训练轮数的训练准确率和测试准确率
# 确保保存目录存在
print(f'{metric[2] * epochs / timer.sum():.1f} examples/sec on: [{str(device)}]')
# 确保保存目录存在
save_dir = 'D:\\SH2\\result'
os.makedirs(save_dir, exist_ok=True)
# 保存模型
torch.save(net.state_dict(), os.path.join(save_dir, f"ResNet-18_CIFAR-10_Epoch{epochs}_Accuracy{test_acc * 100:.2f}%.pth"))
train(net, train_loader, test_loader, epochs, device)
def show_predict():
# 预测结果图像可视化
net.to(device) # 将模型移动到指定设备
loader = DataLoader(dataset=test_dataset, batch_size=1, shuffle=True) # 创建数据加载器
plt.figure(figsize=(12, 8)) # 创建图像窗口
name = ('first', 'second', 'third', 'fourth', 'fifth') # 类别名称
for i in range(9):
(images, labels) = next(iter(loader)) # 获取图像和标签
images = images.to(device) # 将图像移动到指定设备
labels = labels.to(device) # 将标签移动到指定设备
outputs = net(images) # 获取模型输出
_, predicted = torch.max(outputs.data, 1) # 获取预测结果
title = f"Predicted: {name[int(predicted[0])]}, True: {name[int(labels[0])]}" # 设置标题
plt.subplot(3, 3, i + 1) # 创建子图
plt.imshow(images.cpu()[0].permute(1, 2, 0)) # 显示图像
plt.title(title, fontsize=10) # 设置标题
plt.xticks([]) # 隐藏x轴刻度
plt.yticks([]) # 隐藏y轴刻度
plt.show() # 显示图像
show_predict()附赠:用CIFAR-10数据集操作的代码(20轮,准确率大概在80%左右)
代码1和代码2都差不多,代码1和今天讲的差不多就改了一下数据集,代码2删减了一部分更改了一些,更为简单一点
代码1:
import os
import torch
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
from d2l import torch as d2l
# 下载并配置数据集
trans = transforms.Compose(
[transforms.Resize((96, 96)), transforms.ToTensor()])
train_dataset = datasets.CIFAR10(
root=r'D:\SH1\CIFAR', train=True, transform=trans)
test_dataset = datasets.CIFAR10(
root=r'D:\SH1\CIFAR', train=False, transform=trans)
# 配置数据加载器
batch_size = 64
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset=test_dataset,
batch_size=batch_size, shuffle=True)
# 这些代码定义了一个残差块(Residual Block),这是ResNet(残差网络)中的基本构建单元。
# 残差块的主要作用是通过引入跳跃连接(skip connection)来缓解深层神经网络中的梯度消失问题,从而使得训练更深层的网络成为可能。
class Residual(nn.Module):
# 残差块
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
# self.bn1(...):对卷积层的输出应用第一个批量归一化层,F.relu(...): 对归一化后的输出应用ReLU激活函数,Y: 存储激活后的输出
Y = F.relu(self.bn1(self.conv1(X)))
# Y: 更新Y为第二个卷积层和归一化后的输出
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X # Y += X: 将输入X(或经过1x1卷积层的X)加到Y上,实现残差连接。
return F.relu(Y)
# ResNet-18
b1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(), # 批量归一化层,通道数为64, ReLU激活函数
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)) # 最大池化层,核大小为3x3,步幅为2,填充为1
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = [] # blk = []: 初始化一个空列表 blk,用于存储残差块。
for i in range(num_residuals):
if i == 0 and not first_block:
# blk.append: 将一个新的残差块添加到 blk 列表中。
blk.append(Residual(input_channels, num_channels,
use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels)) # 不使用1x1卷积层,步幅为默认值1。
return blk
# *: 解包操作符,将 resnet_block 返回的列表解包为单个参数传递给 nn.Sequential。
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
# nn.AdaptiveAvgPool2d((1, 1)):自适应平均池化层,将每个特征图的空间维度(高度和宽度)缩小到1x1。
# 作用是将不同大小的特征图统一到相同的输出尺寸。
# nn.Flatten():将多维特征图展平成一维向量
# 作用是将特征图转换为全连接层可以处理的输入格式
# nn.Linear(512, 5)):全连接层,输入维度为512,输出维度为5。
# 作用是将展平后的特征向量映射到 5个类别 .(例如,CIFAR-10数据集有10个类别)。
# 定义完整的ResNet模型
net = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(), nn.Linear(512, 10))
# nn.AdaptiveAvgPool2d((1, 1)), # 自适应平均
# nn.Flatten(), # 将特征图展平为一维向量
# nn.Linear(512, 5) # 全连接层,将特征向量映射到 5个类别
lr = 0.001
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
# 定义训练模型
epochs = 20
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def train(net, train_iter, test_iter, epochs, device):
# 初始化模型参数的权重
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
# 对模型应用初始化权重函数
net.apply(init_weights)
# 打印当前训练使用的设备
print(f'Training on: [{device}]')
# 将模型移动到指定的设备上进行训练
net.to(device)
# 创建计时器和获取训练数据迭代器的长度
timer, num_batches = d2l.Timer(), len(train_iter)
# 检查训练数据迭代器是否为空
if num_batches == 0:
print("No batches found in the training data.")
return
# 循环遍历每个训练轮数
for epoch in range(epochs):
# 训练损失之和,训练准确率之和,样本数
metric = d2l.Accumulator(3)
# 将模型设置为训练模式
net.train()
# 遍历训练数据迭代器
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad() # 清空优化器的梯度
X, y = X.to(device), y.to(device) # 将输入数据和标签移动到指定的设备上
y_hat = net(X) # 前向传播,获取模型的预测输出
l = loss(y_hat, y) # 计算模型输出与真实标签之间的损失
l.backward() # 反向传播,计算梯度
optimizer.step() # 更新模型参数
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0]) # 累积训练损失、准确率和样本数
timer.stop()
train_l = metric[0] / metric[2] # 计算平均训练损失
train_acc = metric[1] / metric[2] # 计算平均训练准确率
if (i + 1) % max(1, (num_batches // 30)) == 0 or i == num_batches - 1:
print(f'Epoch: {epoch + 1}, Step: {i + 1}, Loss: {train_l:.4f}') # 打印每个训练步骤的损失
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter) # 在测试集上评估模型的准确率
print(f'Epoch {epoch + 1}: Train Accuracy: {train_acc * 100:.2f}%, Test Accuracy: {test_acc * 100:.2f}%') # 打印每个训练轮数的训练准确率和测试准确率
# 确保保存目录存在
print(f'{metric[2] * epochs / timer.sum():.1f} examples/sec on: [{str(device)}]')
# 确保保存目录存在
save_dir = 'D:\\SH1\\result-1'
os.makedirs(save_dir, exist_ok=True)
# 保存模型
torch.save(net.state_dict(), os.path.join(save_dir, f"ResNet-18_SHIYAN_Epoch{epochs}_Accuracy{test_acc * 100:.2f}%.pth"))
train(net, train_loader, test_loader, epochs, device)
def show_predict():
# 预测结果图像可视化
net.to(device) # 将模型移动到指定设备
loader = DataLoader(dataset=test_dataset, batch_size=1, shuffle=True) # 创建数据加载器
plt.figure(figsize=(12, 8)) # 创建图像窗口
name = ('airplane', 'automobile', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
for i in range(9):
(images, labels) = next(iter(loader)) # 获取图像和标签
images = images.to(device) # 将图像移动到指定设备
labels = labels.to(device) # 将标签移动到指定设备
outputs = net(images) # 获取模型输出
_, predicted = torch.max(outputs.data, 1) # 获取预测结果
title = f"Predicted: {name[int(predicted[0])]}, True: {name[int(labels[0])]}" # 设置标题
plt.subplot(3, 3, i + 1) # 创建子图
plt.imshow(images.cpu()[0].permute(1, 2, 0)) # 显示图像
plt.title(title, fontsize=10) # 设置标题
plt.xticks([]) # 隐藏x轴刻度
plt.yticks([]) # 隐藏y轴刻度
plt.show() # 显示图像
show_predict()代码2:
import torch
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
from d2l import torch as d2l
# 下载并配置数据集
trans = transforms.Compose(
[transforms.Resize((96, 96)), transforms.ToTensor()])
train_dataset = datasets.CIFAR10(
root=r'D:\SH1\CIFAR', train=True, transform=trans)
test_dataset = datasets.CIFAR10(
root=r'D:\SH1\CIFAR', train=False, transform=trans)
# 配置数据加载器
batch_size = 64
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset=test_dataset,
batch_size=batch_size, shuffle=True)
class Residual(nn.Module):
# 残差块
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
# ResNet-18
b1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels,
use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
net = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(), nn.Linear(512, 10))
def train(net, train_iter, test_iter, epochs, lr, device):
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print(f'Training on:[{device}]')
net.to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(epochs):
# 训练损失之和,训练准确率之和,样本数
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 30) == 0 or i == num_batches - 1:
print(f'Epoch: {epoch+1}, Step: {i+1}, Loss: {train_l:.4f}')
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
print(
f'Epoch {epoch + 1}: Train Accuracy: {train_acc*100:.2f}%, Test Accuracy: {test_acc*100:.2f}%')
print(f'{metric[2] * epochs / timer.sum():.1f} examples/sec '
f'on: [{str(device)}]')
torch.save(net.state_dict(),
f"D:\\SH1\\result-2\\ResNet-18_CIFAR-10_Epoch{epochs}_Accuracy{test_acc*100:.2f}%.pth")
epochs, lr = 20, 0.001
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
train(net, train_loader, test_loader, epochs, lr, device)
# 加载保存的模型
def show_predict():
# 预测结果图像可视化
net.to(device)
loader = DataLoader(dataset=test_dataset, batch_size=1, shuffle=True)
plt.figure(figsize=(12, 8))
name = ('airplane', 'automobile', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
for i in range(9):
(images, labels) = next(iter(loader))
images = images.to(device)
labels = labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
title = f"Predicted: {name[int(predicted[0])]}, True: {name[int(labels[0])]}"
plt.subplot(3, 3, i + 1)
plt.imshow(images.cpu()[0].permute(1, 2, 0))
plt.title(title, fontsize=10)
plt.xticks([])
plt.yticks([])
plt.show()
show_predict()