编辑:SelectDB 技术团队
在当今数据驱动的时代,如何高效、有序地管理数据库中的海量数据成为挑战。为了处理庞大的数据集,分布式数据库引入了类似分区和分桶策略,通过将数据按特定规则划分成较小的单位并分布到不同节点上,利用并行计算能力以提升处理和分析性能,并加强了数据管理的灵活性。
在 Apache Doris 中,数据划分包含分区和分桶两个层级。分区一般按照时间或其他连续值对数据进行划分,在查询时,通过分区裁剪过滤不必要的范围扫描,提升执行效率,同时极大地方便了对分区数据的增删改等管理操作;分桶则是基于某个或某些列的哈希值将数据分配到不同的桶中,从而有效定位数据、避免数据倾斜。
在 2.1 版本以前,Apache Doris 的分区主要依赖手动分区和动态分区功能(Dynamic Partition)自动创建两种方式:
- 手动创建分区:需要在建表时指定该表包含的分区,或者在使用过程中通过 DDL 语句修改。
- 动态分区:主要支持按照时间维度分区,以建表时的现实时间为标准来维护一个范围内的分区。
这两种方式都有其不够灵活之处,因此我们在 2.1 版本引入了 自动分区(Auto Partition)来拓展分区功能。自动分区同时支持按时间维度的 Range 分区,和支持多种数据类型的 List 分区,按照导入数据的实际分布创建分区,提供了更为灵活的分区创建手段,相比于动态分区,保证流程自动化的前提下极大提升了分区使用的自由度。
分区策略演进
面对数据分布的设计维度时,我们往往更关注分区的规划,因为分区列和分区间隔的选择与实际的数据分布模式强相关,合理的分区设计能够大幅提升表的查询和存储效率。
在 Doris 中,数据表(Table)按照分区(Partition)和分桶(Bucket)两种方式依次划分,最终同一个分桶中的数据形成数据分片(Tablet,可视作 Bucket)。Tablet 是 Doris 中多副本高可用、集群间数据调度与均衡的最小物理存储单位。图示如下:

01 手动创建分区
最常见也最基本的创建方式是手动创建,Doris 支持 Range 和 List 两种分区创建方式。对于日志、交易记录等基础业务场景,数据的时间维度较为明确,我们一般按照时间维度创建 Range 分区,建表语句示例如下:
sql
-- Range Partition
CREATE TABLE IF NOT EXISTS example_range_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
ENGINE=OLAP
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY RANGE(`date`)
(
PARTITION `p201701` VALUES LESS THAN ("2017-02-01"),
PARTITION `p201702` VALUES LESS THAN ("2017-03-01"),
PARTITION `p201703` VALUES LESS THAN ("2017-04-01"),
PARTITION `p2018` VALUES [("2018-01-01"), ("2019-01-01"))
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
PROPERTIES
(
"replication_num" = "1"
);该表按照数据导入日期 date 进行分区,并预先创建了 4 个分区。在每个分区下,又根据 user_id 的哈希值划分成 16 个分桶。此时对 2018 年及以后的数据查询时,根据该表的分区设计,实际我们只需要对 p2018 进行扫描,查询语句如下:
SQL
mysql> desc select count() from example_range_tbl where date >= '20180101';
+--------------------------------------------------------------------------------------+
| Explain String(Nereids Planner) |
+--------------------------------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS: |
| count(*)[#11] |
| PARTITION: UNPARTITIONED |
| |
| ...... |
| |
| 0:VOlapScanNode(193) |
| TABLE: test.example_range_tbl(example_range_tbl), PREAGGREGATION: OFF. |
| PREDICATES: (date[#1] >= '2018-01-01') |
| partitions=1/4 (p2018), tablets=16/16, tabletList=561490,561492,561494 ... |
| cardinality=0, avgRowSize=0.0, numNodes=1 |
| pushAggOp=NONE |
| |
+--------------------------------------------------------------------------------------+即使入库的数据集中在某几个分区内,分桶的哈希运算机制也能根据 user_id 的值对数据进行二次划分,避免在查询和存储时对部分机器造成不合理的负载倾斜。
在数据量较少的情况下,手动分区尚能应对,而在实际业务场景中,一个集群可能有上万张分区表,此时管理难度将呈指数级上升。例如:
SQL
CREATE TABLE `DAILY_TRADE_VALUE`
(
`TRADE_DATE` datev2 NOT NULL COMMENT '交易日期',
`TRADE_ID` varchar(40) NOT NULL COMMENT '交易编号',
......
)
UNIQUE KEY(`TRADE_DATE`, `TRADE_ID`)
PARTITION BY RANGE(`TRADE_DATE`)
(
PARTITION p_200001 VALUES [('2000-01-01'), ('2000-02-01')),
PARTITION p_200002 VALUES [('2000-02-01'), ('2000-03-01')),
PARTITION p_200003 VALUES [('2000-03-01'), ('2000-04-01')),
PARTITION p_200004 VALUES [('2000-04-01'), ('2000-05-01')),
PARTITION p_200005 VALUES [('2000-05-01'), ('2000-06-01')),
PARTITION p_200006 VALUES [('2000-06-01'), ('2000-07-01')),
PARTITION p_200007 VALUES [('2000-07-01'), ('2000-08-01')),
PARTITION p_200008 VALUES [('2000-08-01'), ('2000-09-01')),
PARTITION p_200009 VALUES [('2000-09-01'), ('2000-10-01')),
PARTITION p_200010 VALUES [('2000-10-01'), ('2000-11-01')),
PARTITION p_200011 VALUES [('2000-11-01'), ('2000-12-01')),
PARTITION p_200012 VALUES [('2000-12-01'), ('2001-01-01')),
PARTITION p_200101 VALUES [('2001-01-01'), ('2001-02-01')),
......
)
DISTRIBUTED BY HASH(`TRADE_DATE`) BUCKETS 10
PROPERTIES (
......
);该表通过手动、逐月的方式创建分区,每个月都需要手动重复增添下一个分区。这不仅需要管理员定期维护表结构变更,在处理实时数据时,可能还需要更频繁地按天、甚至按小时来划分数据分区,给 DBA 带来了沉重负担。
02 动态分区
因此 Doris 引入了动态分区(Dynamic partition)来处理重复性较高的时间分区需求,自动化创建和回收数据分区。通过指定分区单位、历史分区数量和未来分区数量,让 Doris 根据现实时间自动完成分区的创建和回收。
例如按天为单位创建分区,设置 start 为 -7 ,end 为 3:预创建未来 3 天的数据分区,并自动回收距今超过 7 天的历史数据分区。这一功能的实现依赖 FE 端的固定线程,通过不断轮询,检查当前是否需要创建新分区或回收旧分区,从而定期更新数据表的分区结构,建表语句示例如下:
SQL
CREATE TABLE `DAILY_TRADE_VALUE`
(
`TRADE_DATE` datev2 NOT NULL COMMENT '交易日期',
`TRADE_ID` varchar(40) NOT NULL COMMENT '交易编号',
......
)
UNIQUE KEY(`TRADE_DATE`, `TRADE_ID`)
PARTITION BY RANGE(`TRADE_DATE`) ()
DISTRIBUTED BY HASH(`TRADE_DATE`) BUCKETS 10
PROPERTIES (
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-7",
"dynamic_partition.end" = "3",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "10"
);随时间推移,该表将始终保持 [当前日期-7, 当前日期+3] 范围内的分区。对于实时数据收集场景,例如 ODS 层直接从外部数据源(如 Kafka)接收数据时,动态分区功能尤为适用。
由于 start 和 end 参数限定了分区的固定范围,用户只能在此范围内管理分区,若需要包含更久远的历史数据,不得不将start 值调大,而这会导致集群中元数据的不必要浪费。因此,在使用动态分区功能时,需要权衡实时管理的便利性与元数据管理的效率。
数据库分区管理的设计思考
对于更复杂的业务场景来说,动态分区有着明显的局限性:
- 仅支持 Range 分区,而无法支持 List 分区
- 只能应用于现实世界的时间维度,如果数据与现实时间无关则无法使用
- 只能包含 1 个连续分区段,无法容纳该范围以外的分区
这导致在某些特定场景下,无法仅依靠动态分区实现分区管理,例如:
- 当分区的时间维度不再和当前现实时间相关,而是对历史数据进行重放计算。例如处理过往某一年的数据,且需要进行天级别的分区。
- 在当前数据导入过程中,偶尔发生历史数据变更。例如在天级别的分区表中,偶尔导入若干年前的数据,是否需要将动态分区的 start 调整到非常大的级别以容纳这些数据?
基于上述的功能局限,我们开始思考,能否提出一种新的分区方式,进一步提升分区管理的自动化程度、简化数据表的维护工作?分析发现,理想分区的实现是同时满足 2 个条件:
- 建表后无需手动调整分区
- 所有的入库数据都有对应分区
前者是动态分区已经具备的"自动化"能力,后者是希望拥有一种"更加灵活"的分区创建能力。而这种能力的本质,是要求分区创建与实际数据关联。
因此我们开始思考:分区的创建能否从建表时或者日常轮询,延后到数据到达时?从预先构造分区的分布,转为定义"从数据到分区"的映射规则,等数据入库后等待分区容纳时,再根据规则创建对应的分区。这样,相较于手动分区,整个流程都是自动发生的,不再需要人工维护;相较于动态分区,避免了有而无用和用而没有的分区情况。
让分区的创建与实际数据的分布自动关联, 是我们理想分区方式的核心思想。
更灵活便捷的自动分区创建策略
基于以上思考,我们在 Apache Doris 2.1 版本引入了"自动分区"(Auto Partition)功能,不再预先创建分区,而是在数据导入过程中根据设置的规则为创建对应的分区。负责数据处理、分发的 BE 节点会在执行计划的 DataSink 算子中尝试为每行数据找到它所属的 Partition。在以往分区表中,找不到对应分区的新增导入数据将被过滤或直接报错。而在自动分区表中,我们仅需在建表时定义分区创建规则,就可以随数据导入自动生成对应分区。接下来介绍自动分区的具体使用方式。
01 Range 自动分区
Range 自动分区(Auto Range Partition)提供了时间维度上的更优分区方案,弥补了动态分区在调参方面的局限性。它的语法如下:
SQL
-- AUTO RANGE PARTITION 语法
AUTO PARTITION BY RANGE (FUNC_CALL_EXPR)
()
FUNC_CALL_EXPR ::= DATE_TRUNC ( <partition_column>, '<interval>' )其中 <partition_column> 指分区列名,<interval> 指分区单位,也就是希望生成分区的宽度。例如分区列为 k0,按照月级别分区,那么最终的分区描述语句就是 AUTO PARTITION BY RANGE (DATE_TRUNC(k0, 'month'))。此时对于所有导入数据,我们会调用 (DATE_TRUNC(k0, 'month') 对 k0 计算出分区的左端点,再增加一个 interval 得到分区的右端点。通俗来说就是,此处选定的时间单位是"月",数据导入后自动创建的分区区间是其所属的自然月。
前文动态分区章节中介绍的 DAILY_TRADE_VALUE 表,通过自动分区功能优化如下:
SQL
CREATE TABLE DAILY_TRADE_VALUE
(
`TRADE_DATE` DATEV2 NOT NULL COMMENT '交易日期',
`TRADE_ID` VARCHAR(40) NOT NULL COMMENT '交易编号',
......
)
AUTO PARTITION BY RANGE (DATE_TRUNC(`TRADE_DATE`, 'month'))
()
DISTRIBUTED BY HASH(`TRADE_DATE`) BUCKETS 10
PROPERTIES
(
......
);导入数据后,分区创建结果如下:
SQL
mysql> show partitions from DAILY_TRADE_VALUE;
Empty set (0.10 sec)
mysql> insert into DAILY_TRADE_VALUE values ('2015-01-01', 1), ('2020-01-01', 2), ('2024-03-05', 10000), ('2024-03-06', 10001);
Query OK, 4 rows affected (0.24 sec)
{'label':'label_2a7353a3f991400e_ae731988fa2bc568', 'status':'VISIBLE', 'txnId':'85097'}
mysql> show partitions from DAILY_TRADE_VALUE;
+-------------+-----------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+
| PartitionId | PartitionName | VisibleVersion | VisibleVersionTime | State | PartitionKey | Range | DistributionKey | Buckets | ReplicationNum | StorageMedium | CooldownTime | RemoteStoragePolicy | LastConsistencyCheckTime | DataSize | IsInMemory | ReplicaAllocation | IsMutable | SyncWithBaseTables | UnsyncTables |
+-------------+-----------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+
| 588395 | p20150101000000 | 2 | 2024-06-01 19:02:40 | NORMAL | TRADE_DATE | [types: [DATEV2]; keys: [2015-01-01]; ..types: [DATEV2]; keys: [2015-02-01]; ) | TRADE_DATE | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL |
| 588437 | p20200101000000 | 2 | 2024-06-01 19:02:40 | NORMAL | TRADE_DATE | [types: [DATEV2]; keys: [2020-01-01]; ..types: [DATEV2]; keys: [2020-02-01]; ) | TRADE_DATE | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL |
| 588416 | p20240301000000 | 2 | 2024-06-01 19:02:40 | NORMAL | TRADE_DATE | [types: [DATEV2]; keys: [2024-03-01]; ..types: [DATEV2]; keys: [2024-04-01]; ) | TRADE_DATE | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL |
+-------------+-----------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+
3 rows in set (0.09 sec)可以看到,该表在导入数据之后自动创建了数据所属的对应分区,而没有数据的分区则不会自动创建。
02 List 自动分区
List 自动分区(Auto List Partition)用来应对实际业务场景中,非时间维度的数据划分需求,例如事件所属的地域、部门等维度。在 Doris 以往的功能中,List 分区不存在一个近似"动态分区"的自动管理机制,自动分区同时补齐了这一短板。它的语法如下:
SQL
-- AUTO LIST PARTITION 语法
AUTO PARTITION BY LIST (`partition_col`)
()例如,使用一张表的 VARCHAR 列作为分区列,实际含义为条目所属的城市:
SQL
mysql> CREATE TABLE `str_table` (
-> `city` VARCHAR NOT NULL,
-> ......
-> )
-> DUPLICATE KEY(`city`)
-> AUTO PARTITION BY LIST (`city`)
-> ()
-> DISTRIBUTED BY HASH(`city`) BUCKETS 10
-> PROPERTIES (
-> ......
-> );
Query OK, 0 rows affected (0.09 sec)
mysql> insert into str_table values ("Beijing"), ("Shanghai"), ("Los_Angeles");
Query OK, 3 rows affected (0.25 sec)
mysql> show partitions from str_table;
+-------------+-----------------+----------------+---------------------+--------+--------------+-------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+
| PartitionId | PartitionName | VisibleVersion | VisibleVersionTime | State | PartitionKey | Range | DistributionKey | Buckets | ReplicationNum | StorageMedium | CooldownTime | RemoteStoragePolicy | LastConsistencyCheckTime | DataSize | IsInMemory | ReplicaAllocation | IsMutable | SyncWithBaseTables | UnsyncTables |
+-------------+-----------------+----------------+---------------------+--------+--------------+-------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+
| 589685 | pBeijing7 | 2 | 2024-06-01 20:12:37 | NORMAL | city | [types: [VARCHAR]; keys: [Beijing]; ] | city | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL |
| 589643 | pLos5fAngeles11 | 2 | 2024-06-01 20:12:37 | NORMAL | city | [types: [VARCHAR]; keys: [Los_Angeles]; ] | city | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL |
| 589664 | pShanghai8 | 2 | 2024-06-01 20:12:37 | NORMAL | city | [types: [VARCHAR]; keys: [Shanghai]; ] | city | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL |
+-------------+-----------------+----------------+---------------------+--------+--------------+-------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+
3 rows in set (0.10 sec)可以看到,插入"北京"、"上海"、"洛杉矶"三个城市名后,结果根据城市名划分了对应分区,而以往只能通过手动的 DDL 语句实现。Auto List Partition 功能的引入在很大程度上降低了自定义分区的维护成本,拓宽了 Doris 的使用自由度。
03 使用技巧与注意事项
手动调整历史分区
对于写入最新实时数据和零散历史变更数据的表,由于 Auto Partition 不会自动回收历史分区,我们推荐两种可能的处理方式:
-
正常使用自动分区功能,为零散数据自动创建分区。相较于动态分区,避免创建冗余的空置分区,极大地节省了元数据使用量。
-
自动分区与手动创建分区相结合,按时间维度创建一个 LESS THAN 分区,容纳历史变更数据,这样可以更清晰地划分历史与实时数据,也为后续的数据管理带来效率上的提升。
SQL
mysql> CREATE TABLE DAILY_TRADE_VALUE
-> (
-> `TRADE_DATE` DATEV2 NOT NULL COMMENT '交易日期',
-> `TRADE_ID` VARCHAR(40) NOT NULL COMMENT '交易编号'
-> )
-> AUTO PARTITION BY RANGE (DATE_TRUNC(`TRADE_DATE`, 'DAY'))
-> (
-> PARTITION `pHistory` VALUES LESS THAN ("2024-01-01")
-> )
-> DISTRIBUTED BY HASH(`TRADE_DATE`) BUCKETS 10
-> PROPERTIES
-> (
-> "replication_num" = "1"
-> );
Query OK, 0 rows affected (0.11 sec)
mysql> insert into DAILY_TRADE_VALUE values ('2015-01-01', 1), ('2020-01-01', 2), ('2024-03-05', 10000), ('2024-03-06', 10001);
Query OK, 4 rows affected (0.25 sec)
{'label':'label_96dc3d20c6974f4a_946bc1a674d24733', 'status':'VISIBLE', 'txnId':'85092'}
mysql> show partitions from DAILY_TRADE_VALUE;
+-------------+-----------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+
| PartitionId | PartitionName | VisibleVersion | VisibleVersionTime | State | PartitionKey | Range | DistributionKey | Buckets | ReplicationNum | StorageMedium | CooldownTime | RemoteStoragePolicy | LastConsistencyCheckTime | DataSize | IsInMemory | ReplicaAllocation | IsMutable | SyncWithBaseTables | UnsyncTables |
+-------------+-----------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+
| 577871 | pHistory | 2 | 2024-06-01 08:53:49 | NORMAL | TRADE_DATE | [types: [DATEV2]; keys: [0000-01-01]; ..types: [DATEV2]; keys: [2024-01-01]; ) | TRADE_DATE | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL |
| 577940 | p20240305000000 | 2 | 2024-06-01 08:53:49 | NORMAL | TRADE_DATE | [types: [DATEV2]; keys: [2024-03-05]; ..types: [DATEV2]; keys: [2024-03-06]; ) | TRADE_DATE | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL |
| 577919 | p20240306000000 | 2 | 2024-06-01 08:53:49 | NORMAL | TRADE_DATE | [types: [DATEV2]; keys: [2024-03-06]; ..types: [DATEV2]; keys: [2024-03-07]; ) | TRADE_DATE | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL |
+-------------+-----------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+
3 rows in set (0.10 sec)NULL 值分区
Doris 支持分区表中存储 NULL 值。对于自动分区功能而言,List 分区表的 NULL 值将会存储在真正的 NULL 分区中,例如:
SQL
mysql> CREATE TABLE list_nullable
-> (
-> `str` varchar NULL
-> )
-> AUTO PARTITION BY LIST (`str`)
-> ()
-> DISTRIBUTED BY HASH(`str`) BUCKETS auto
-> PROPERTIES
-> (
-> "replication_num" = "1"
-> );
Query OK, 0 rows affected (0.10 sec)
mysql> insert into list_nullable values ('123'), (''), (NULL);
Query OK, 3 rows affected (0.24 sec)
{'label':'label_f5489769c2f04f0d_bfb65510f9737fff', 'status':'VISIBLE', 'txnId':'85089'}
mysql> show partitions from list_nullable;
+-------------+---------------+----------------+---------------------+--------+--------------+------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+
| PartitionId | PartitionName | VisibleVersion | VisibleVersionTime | State | PartitionKey | Range | DistributionKey | Buckets | ReplicationNum | StorageMedium | CooldownTime | RemoteStoragePolicy | LastConsistencyCheckTime | DataSize | IsInMemory | ReplicaAllocation | IsMutable | SyncWithBaseTables | UnsyncTables |
+-------------+---------------+----------------+---------------------+--------+--------------+------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+
| 577297 | pX | 2 | 2024-06-01 08:19:21 | NORMAL | str | [types: [VARCHAR]; keys: [NULL]; ] | str | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL |
| 577276 | p0 | 2 | 2024-06-01 08:19:21 | NORMAL | str | [types: [VARCHAR]; keys: []; ] | str | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL |
| 577255 | p1233 | 2 | 2024-06-01 08:19:21 | NORMAL | str | [types: [VARCHAR]; keys: [123]; ] | str | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true | true | NULL |
+-------------+---------------+----------------+---------------------+--------+--------------+------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+--------------------+--------------+
3 rows in set (0.11 sec)而 Range 自动分区目前并不支持 NULL 值分区。这是因为在 Doris 中,Range 分区的 NULL 值将会存入最小的 LESS THAN 分区 ,Auto Partition 难以确定该分区应有的范围。如果按照(-INFINITY, MIN_VALUE)范围创建,则分区有在业务中被误删除的风险。
04 功能总结
自动分区在功能上基本覆盖了动态分区的使用场景,并带来分区规则前置的拓展,大大减轻了DBA 在管理数据时的工作负担。完成分区规则的定义后,大量的分区创建工作将全部由 Doris 自动完成。在使用自动分区前,我们需要先明确相关限制条件,包括:
- LIST 自动分区支持多列分区,每个自动创建的分区仅包含一个分区值,分区名长度不能超过 50。Auto List Partition 中,分区名的创建依赖某种特定的规则,对元数据维护具有特定的含义,长度 50 的分区名,所能包含的数据实际长度可能更短。
- RANGE 自动分区支持单个分区列 ,分区列类型必须为 DATE 或 DATETIME
- LIST 自动分区支持 NULLABLE 分区列和实际插入 NULL 值;RANGE 自动分区不支持 NULLABLE 分区列
- 自从 Doris 2.1.3 版本开始,自动分区不再支持与动态分区共同使用。动态分区在进行分区回收时,不会考虑分区的创建来源。导致即使是 Auto Partition 自动创建的分区,也有可能被立即回收,导致不易察觉的数据丢失。
性能对比
自动分区和动态分区的功能区别主要体现在创建与删除、支持类型以及性能影响这三个方面。
动态分区通过固定线程创建并定期检查和回收分区,只支持按 RANGE 分区。而自动分区根据特定的分区规则在导入数据时按需创建,在 Range 分区的基础上提供了 LIST 分区支持。总体而言,自动分区在灵活性和节约人力方面都具有显著优势。
在导入数据时,动态分区在导入过程中基本不会影响性能,而自动分区会先检索已有分区,按需自动创建,这中间会存在一定的时间开销。因此我们将在后文展示对于自动分区具体的性能测试结果。

自动分区导入流程详解
接下来,详细介绍 Doris 自动分区导入的技术实现。以 Stream Load 为例,Doris 发起导入时,其中一个 BE 会完成前期的数据处理工作,并将数据发送给对应的 BE。用来处理数据的 BE 被称为 Coordinator,其他 BE 则统称为 Executor。
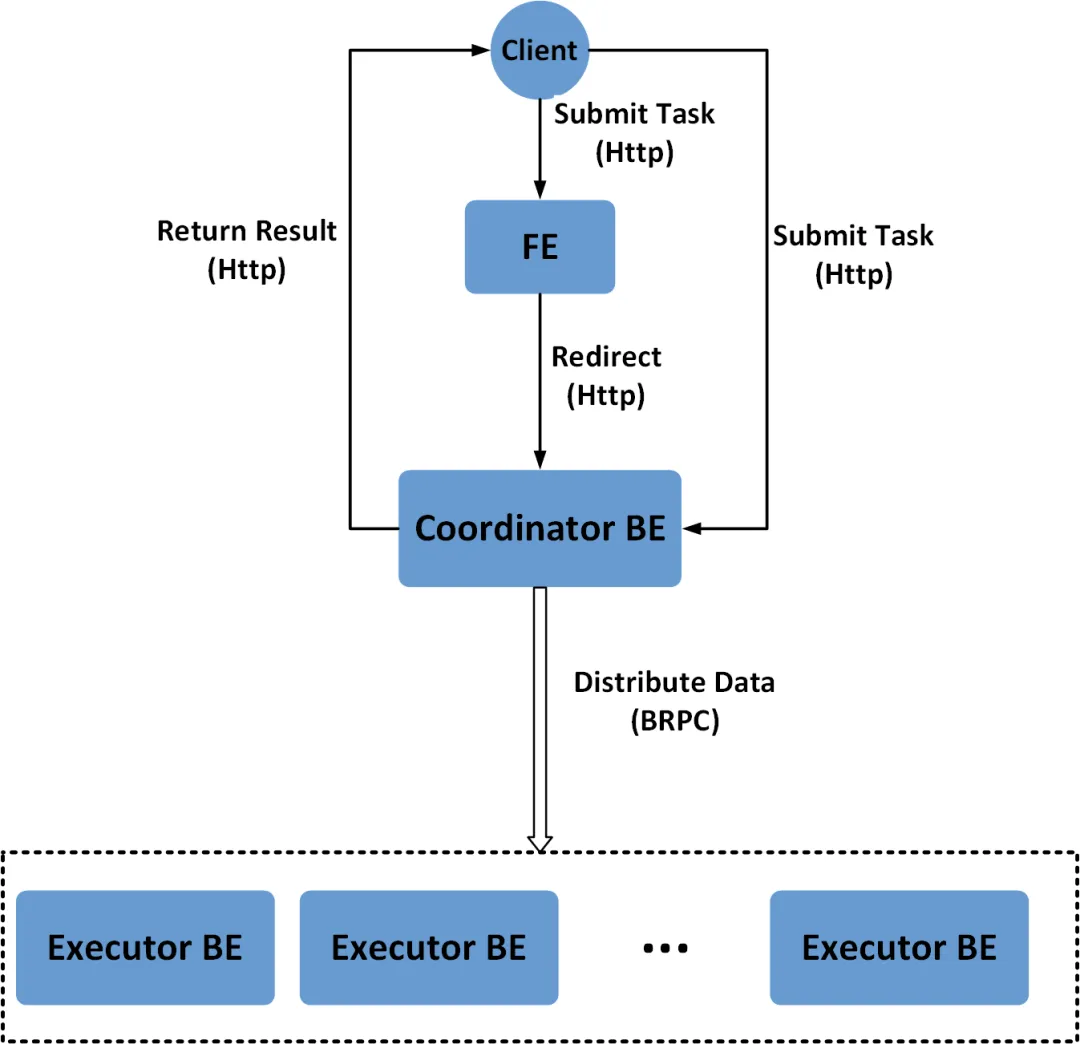
在 Coordinator 执行流程中,最后一个算子是 Datasink Node。在该算子中,数据需要先确定其对应的分区、分桶以及所在 BE 的位置,才能被成功发送到正确的 BE 节点并存储。为了实现数据传输,Coordinator 与 Executor 之间通过特定的 Channel 建立通信桥梁,发送端称为 Node Channel,与之对应的接收端称为 Tablets Channel。
自动分区主要在寻找数据对应分区这一环节发挥作用,具体工作机制如下:
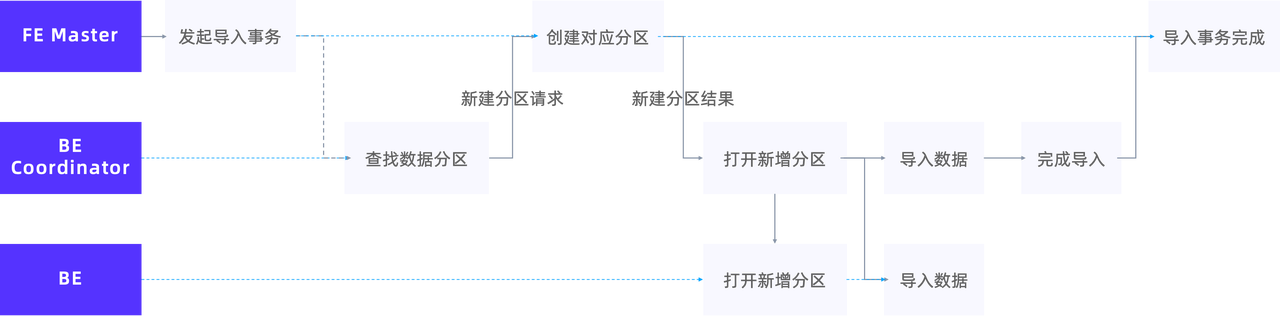
以往找不到分区时,BE 会累计错误直至报错 DATA_QUALITY_ERROR,而开启了 Auto Partition 的表,则会在此阶段发起一个新建分区的请求给 FE 并创建对应的分区。Coordinator 等待 FE 完成分区创建的回传结果后,打开分区导入的对应通道,即对应的 Node Channel 和 Tablets Channel,继续完成数据的导入。
经过上述步骤,自动分区即可实现用户侧无感知的分区创建,使导入顺利完成。
在实际集群运行环境中,Coordinator 等待 FE 完成创建分区事务往往面临巨大的时间开销成本。原因是 Thrift RPC 过程产生的固有开销,以及高负载情况下 FE 的锁开销。为了提高数据导入的效率,我们在 Auto Partition 场景中进行了攒批操作,从而大幅减少 RPC 调用次数,这一改进显著提升了数据写入性能
需要注意的是,目前 FE Master 在"创建对应分区"环节完成对应分区的创建事务后,分区即刻可见,但如果导入流程最终失败或被取消,所创建的分区不会被自动回收。
自动分区性能表现
我们基于不同场景对自动分区进行了性能和稳定性测试,具体如下:
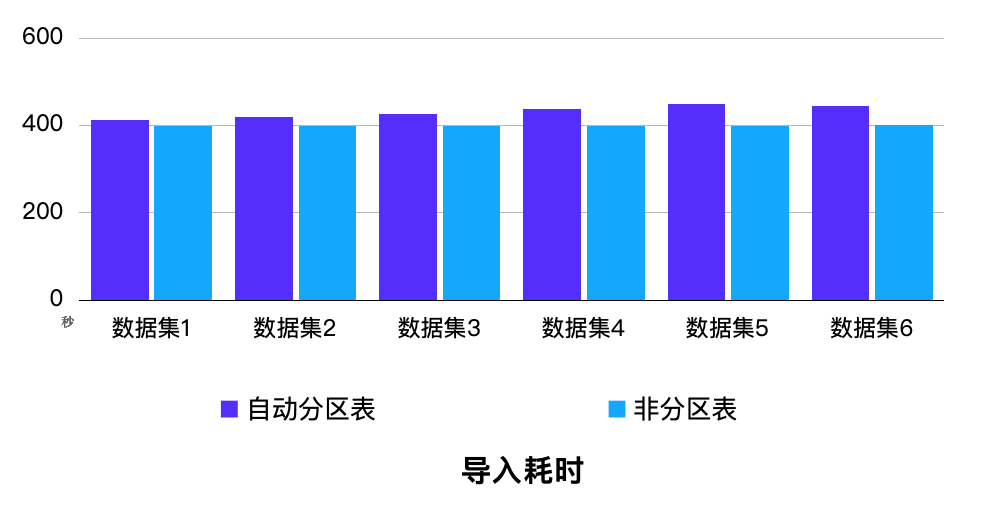
场景1: 1FE + 3BE 环境,随机生成数据集,每个数据集 1 亿行数据、涉及 2000 个分区,6 个数据集并行导入 6 张对应表。
结果:对比开启自动分区前后,所有导入事务的耗时都较为平稳,平均性能损耗不足 5%。
场景 2:1FE + 3BE 环境,使用 Flink 数据源每秒采集 100 条数据,通过 Routine Load 进行导入,分别测试在 1、10、20 个事务(表)并发下的导入反压情况。
结果:在以上并发下,开启自动分区前后均能顺利完成数据导入、未出现反压情况,20 个事务并发时 CPU 利用率接近 100%,整体表现极为平稳。

上述测试方法分别对应两个典型场景:
- 在贴近生产环境的高负载场景下,检验 Auto Partition 功能面向集群高压力的情况,是否会发生性能劣化;
- 在 Routine Load 不同并发压力下,检验 Auto Partition 功能是否存在导入瓶颈、数据积压问题;
通过以上真实场景的模拟测试我们发现,开启 Auto Partition 前后对导入性能影响甚微。不论是简单的数据插入、或是生产环境中常见的 Routine Load 消费 Flink 数据源,Auto Partition 都表现出了优异的导入性能和稳定的系统表现。即使面对高负载、集群压力较大的情况,开启 Auto Partition 的导入性能损失仅有 5% 左右,性能表现依旧出色,足以满足实际生产环境的使用需求。
基于 Doris 的自动分区在性能和稳定性方面的出色表现,用户可以放心使用该功能,替代旧有分区方式,简化数据操作流程。
总结与展望
自 Apache Doris 2.1 版本起,自动分区的出现进一步简化了复杂场景下的 DDL 和分区表的维护工作,在我们已发布的版本中,许多用户已经使用该功能简化了工作流程,并且极大的便利了从其他数据库系统迁移到 Doris 的工作,自动分区已成为处理大规模数据和应对高并发场景的理想选择。
不仅如此,我们还将对自动分区功能展开更深入的拓展,以应对更加复杂的数据模型。
对于 Auto Range Partition:
- 当前仅支持时间类型上的划分,未来期望支持更丰富的类型,如数值类型等,
- 通过指定上下界的计算方式,创建对应分区
对于 Auto List Partition:
- 将多个值按特定规则合并到同一分区
这些都是我们未来会考虑的改进方向,欢迎在分区创建方面有需求的同学积极使用并前往 Doris 问答论坛反馈建议,期待与你共建更好的 Apache Doris 社区。