目录
[2.1 编码器方面的问题:](#2.1 编码器方面的问题:)
[2.2 解码器方面的问题:](#2.2 解码器方面的问题:)
[3.1 计算 ci 值:](#3.1 计算 ci 值:)
[3.2 ci 的广义表示:](#3.2 ci 的广义表示:)
[四、Bahdanau 注意 :](#四、Bahdanau 注意 :)
[4.1. 兼容性分数计算:](#4.1. 兼容性分数计算:)
[4.3. 上下文向量:](#4.3. 上下文向量:)
[五、Luong 注意 :](#五、Luong 注意 :)
一、说明
在人工智能和机器学习领域,注意力机制的概念已成为提高神经网络效率和有效性的有力工具。受人类有选择地关注输入数据特定方面的认知过程的启发,注意力机制允许模型动态地将计算资源分配给给定输入的最相关组件。

在这篇博客中,我们将分解注意力机制:它们是什么,为什么它们如此有用,以及它们是如何运作的。从基本概念到实际应用,我们将以通俗易懂的方式解释注意力机制如何成为人工智能的重要组成部分。
二、编码器解码器架构中的问题:需要注意
2.1 编码器方面的问题:
在自然语言处理中,编码器-解码器架构面临的挑战类似于人类在尝试处理冗长句子时遇到的挑战。想象一下,试图将一个长而复杂的句子翻译成另一种语言,只看了一眼。保留整个上下文并准确翻译几乎是不可能的,尤其是在处理包含超过 25 个单词的句子时。

同样,当编码器处理一个大句子时,在固定长度的上下文向量中捕获其完整的上下文被证明是一项艰巨的任务。此限制会显著影响翻译准确性。
2.2 解码器方面的问题:
在图的解码器方面,我们可以观察到,要输出一个特定的单词,如"आपसे"(在英语中意为"你"),我们不一定需要整个句子上下文。
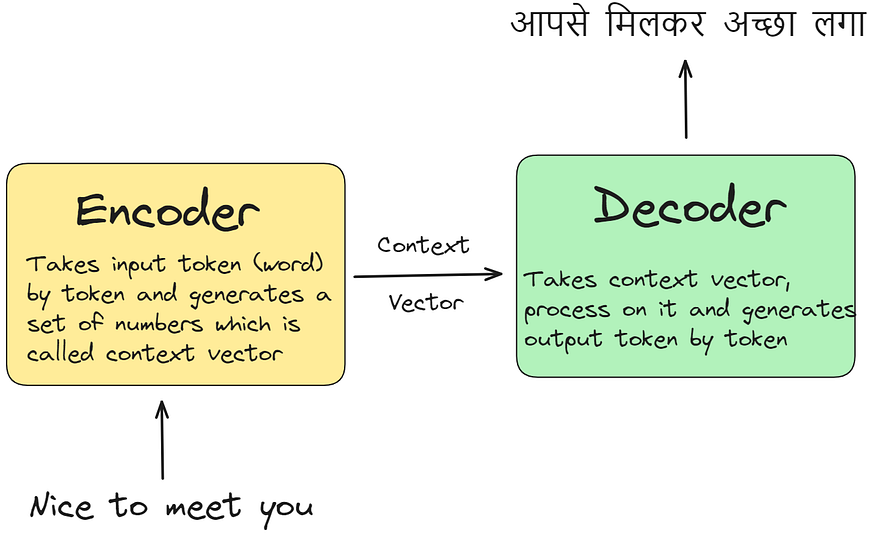
相反,只需要一个特定的单词或一组单词。然而,在传统的编码器-解码器架构中,整个句子上下文向量都提供给解码器,导致解码器难以准确解码的静态表示。
如果解码器可以动态地关注与输出相关的特定单词,则效率会更高。这个概念反映了人类的阅读和翻译方式,通过关注注意力区域和相邻单词作为上下文。当我们人类阅读一段冗长的段落时,我们的大脑会自然而然地创建一个注意力区域,我们的注意力集中在其中。就像相机镜头捕捉到一个清晰的区域,而其余部分仍然模糊不清一样,我们的注意力主要集中在这个焦点上,而周边信息则不太清晰。这种自然的认知过程使我们能够有效地理解和翻译文本。

此外,考虑一下我们发现自己在段落中途的场景。在这一点上,我们的大脑依靠相邻单词的上下文线索来破译不熟悉术语的含义。
考虑一个场景,你要解码一个句子,从解码器中的时间戳 t=1 开始。假设您需要输出单词"आपसे"(英语中的"你")。为了准确地做到这一点,您必须提供来自编码器的相关信息,特别是时间戳 t=4 处的内容,即单词"you"所在的位置,这对于生成"आपसे"至关重要。同样,在时间戳 t=2 处解码时,要输出"मिलकर"("见面"),您需要从时间戳 t=2 和 t=3 输入,其中可以找到"见面"的上下文。
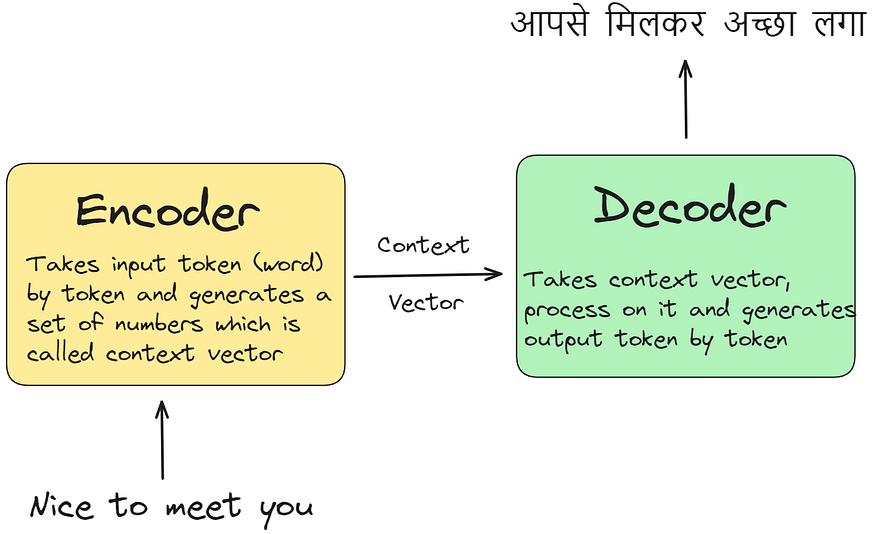
因此,挑战在于动态传递编码器的时间戳值,这些值在解码过程的每个步骤中都保存了要翻译的重要信息。这种动态机制使解码器能够有选择地关注相关的编码器时间戳,这就是我们所说的注意力机制。
三、什么是注意力机制?
注意力机制使模型能够有选择地关注输入序列的相关部分,同时生成输出序列的每个元素,从而提高准确性并捕获机器翻译等任务中的长程依赖关系。我们举个例子来理解一下:
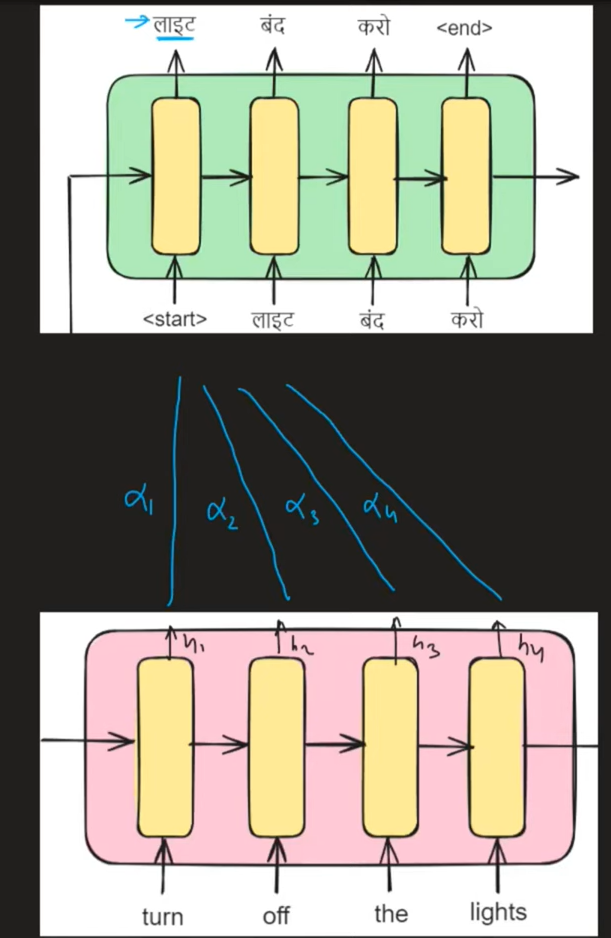
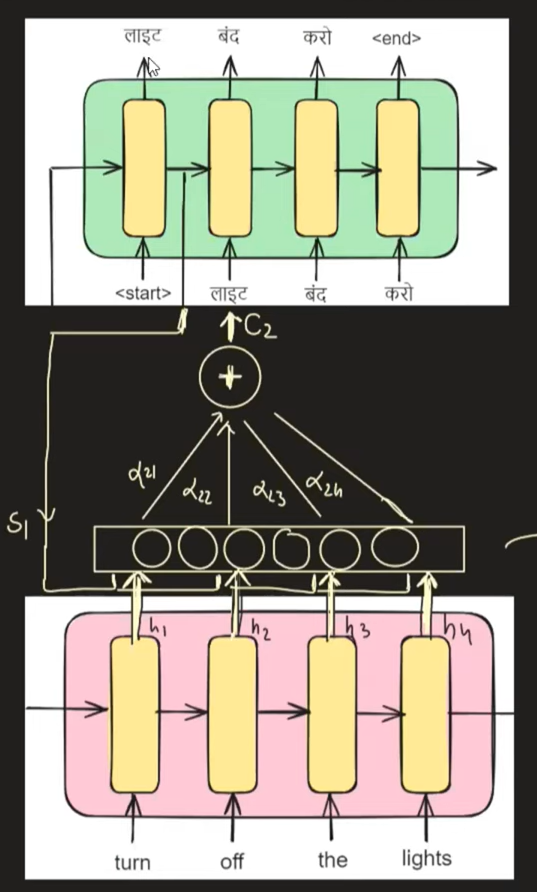
下面是编码器解码器图,我们将英语翻译成印地语。我们传递输入"关灯",我们从解码器端得到的输出是"लाइट बंद करो"。
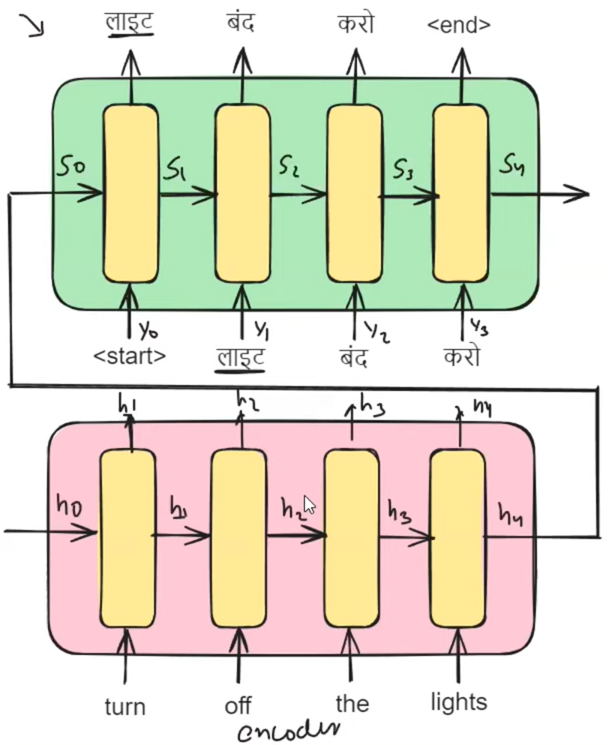
在具有注意力机制的增强型编码器-解码器体系结构中,我们将编码器隐藏状态表示为 h0、h1、h2、h3、h4,将解码器隐藏状态表示为 s0、s1、s2、s3、s4。值得注意的是,在解码器中预测特定时间戳的输出时,我们输入两个基本组件:前一个时间戳的解码器隐藏状态值(si-1)和前一个时间戳的编码器隐藏状态值(yi-1)。注意力机制的添加引入了另一个关键参数 ci,它表示特定编码器时间戳对解码器中当前解码时间戳的重要性。
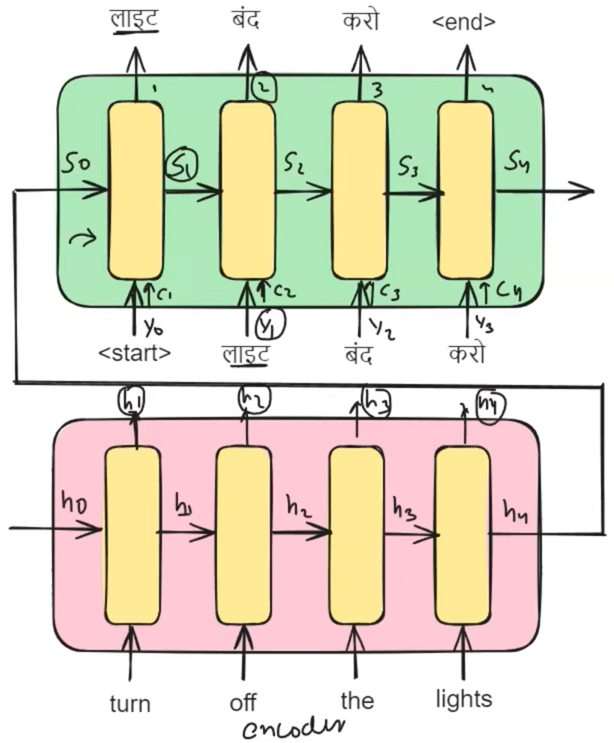
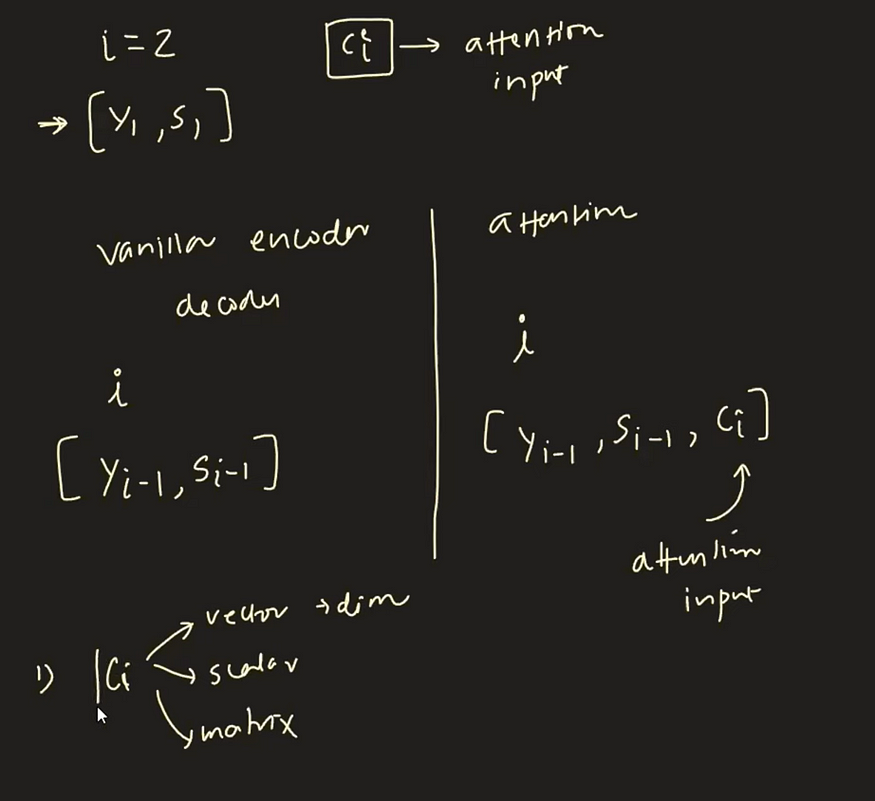
3.1 计算 ci 值:
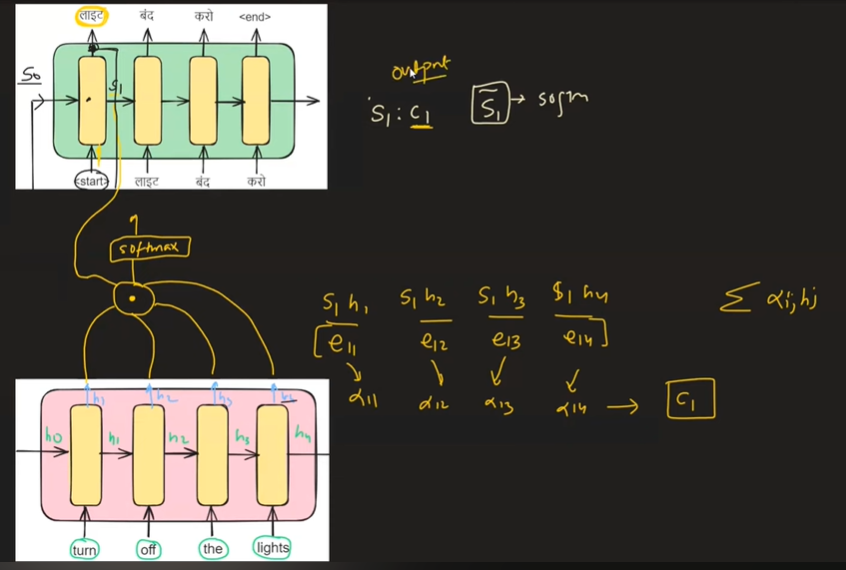
想象一下,我们在解码器中的时间戳 t=1,旨在输出单词"लाइट"(在英语中意为"光"),我们试图了解哪个编码器隐藏状态(h1、h2、h3 或 h4)与此翻译最相关。这就是注意力机制发挥作用的地方。它为所有编码器隐藏状态分配权重,表示为 α1、α2、α3 和 α4,表明它们在生成单词"लाइट"中的各自重要性。
解码器中时间戳 t =1 处的上下文向量 c1 可以表示为:
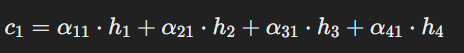
该等式表示上下文向量 c 1 是如何形成的,方法是将每个编码器隐藏状态 hi 加权为其相应的注意力权重 α 1i。
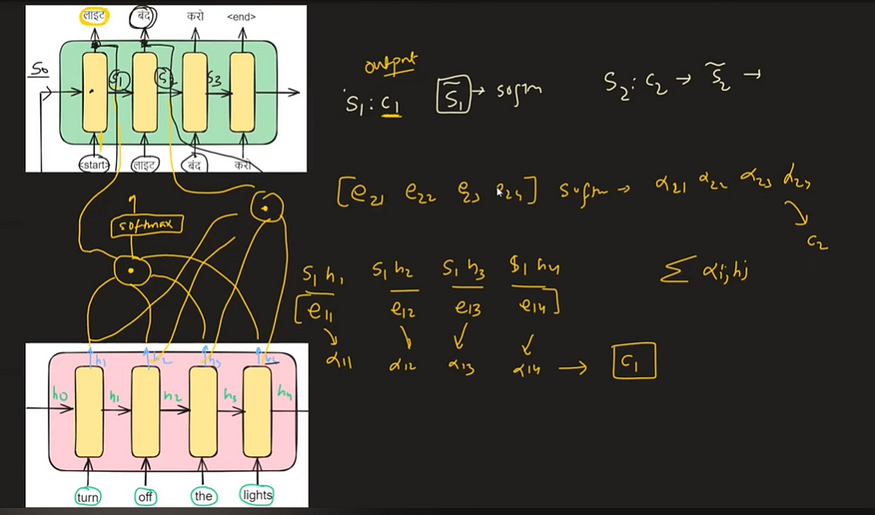
同样,对于时间戳 t= 2,请参见下文:
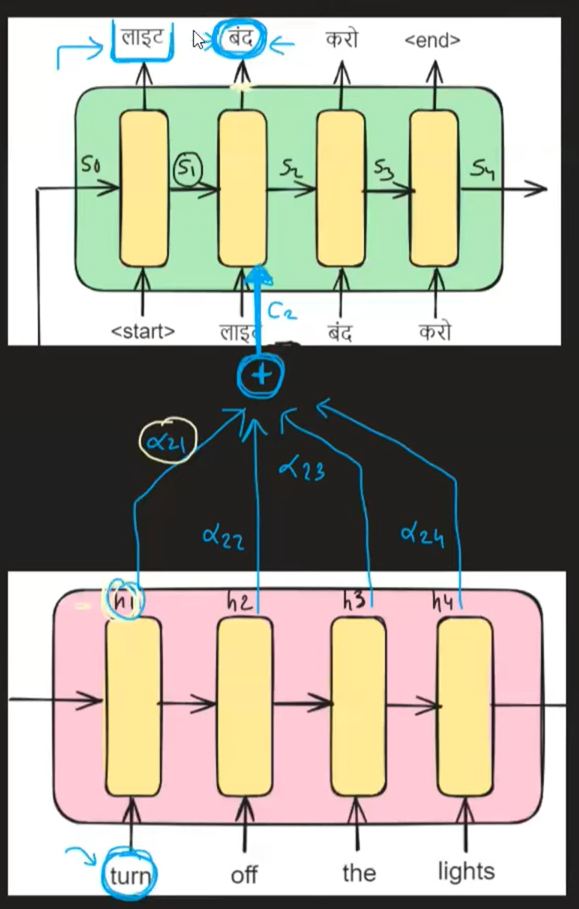
对于解码器中时间戳 t =2 时的 c2,上下文向量可以写成:
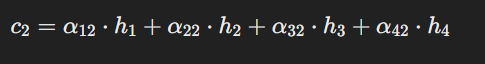
就像 c 1 一样,c 2 的计算方法是将每个编码器隐藏状态 hi 加权α 其相应的注意力权重 2i。
3.2 ci 的广义表示:
解码器中时间戳 t 处的上下文向量 ct 可以用数学方式表示如下:
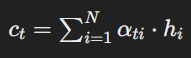
哪里:
- ct 表示时间戳 t 处的上下文向量。
- αti 表示在时间戳 t 处分配给第 i个编码器隐藏状态的注意力权重。
- hi 表示编码器的隐藏状态。
- N 是编码器隐藏状态的总数。
现在,问题来了:我们如何计算这些注意力权重值,表示为 ( α)?
注意力权重值(α)是通过考虑两个主要因素来确定的:编码器在相应时间戳处的当前隐藏状态(hj)和解码器的先前隐藏状态值(si-1)。
事实上,α 是 hj (编码器在时间戳 j 处的隐藏状态)和 si−1(解码器的先前隐藏状态)的函数。
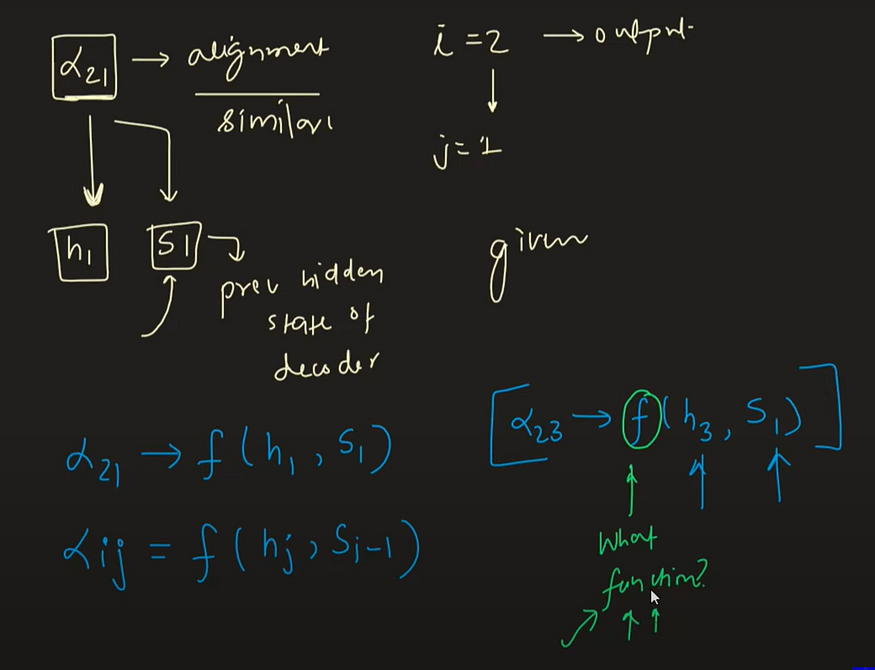
我们的目标是推导出一个捕捉这种关系的数学方程,使我们能够根据 hj 和 si−1 计算 α 的值。在最初的研究论文中,研究人员使用人工神经网络(ANN)(因为它们是通用函数逼近器)来设计这个方程,使模型能够在解码过程中动态确定注意力权重。
在注意力机制中,计算注意力权重值的两种流行方法是 Bahdanau 注意力 和 Luong 注意力。
四、Bahdanau 注意 :
Bahdanau注意力,也称为加法注意力,是一种在序列到序列模型中计算注意力权重值的方法。它是由 Dzmitry Bahdanau、Kyunghyun Cho 和 Yoshua Bengio 在 2015 年的论文"通过共同学习对齐和翻译进行神经机器翻译"中引入的。以下是对 Bahdanau 注意力如何工作的详细说明:
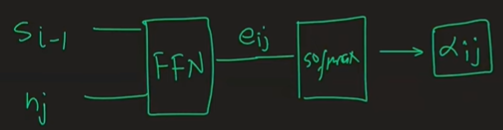
4.1. 兼容性分数计算:
- 在每个解码时间步,Bahdanau 注意力计算解码器的前一个隐藏状态 (si −1) 和每个编码器隐藏状态 (hj) 之间的兼容性分数。
- 此兼容性分数通常使用前馈神经网络(通常是单层神经网络)计算,该神经网络以 si −1 和 hj 为输入。
- 从数学上讲,编码器隐藏状态 hj 和解码器隐藏状态 si −1 的兼容性分数 eij 计算如下:
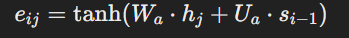
4.2.注意力权重:
- 一旦计算出兼容性分数,它们就会通过另一个神经网络(通常是单层神经网络,然后是软最大激活)来获得注意力权重。
- 从数学上讲,解码时间步长 i 处编码器隐藏状态 hj 的注意力权重 αij 计算如下:

4.3. 上下文向量:
- 计算注意力权重后,通过对编码器隐藏状态进行加权求和来获得当前解码时间步长 i 的上下文向量 ci,其中权重由注意力权重给出。
- 在数学上,上下文向量 ci 的计算方法如下:
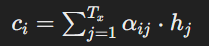
下图直观地说明了 Bahdanau 注意力是如何运作的,提供了对其功能和计算流程的直观理解。
在编码器侧,隐藏状态用 h0 表示,每个状态都是一个四维向量。类似地,在解码器端,先前的时间戳隐藏状态用 s0 表示,也包括四维向量。
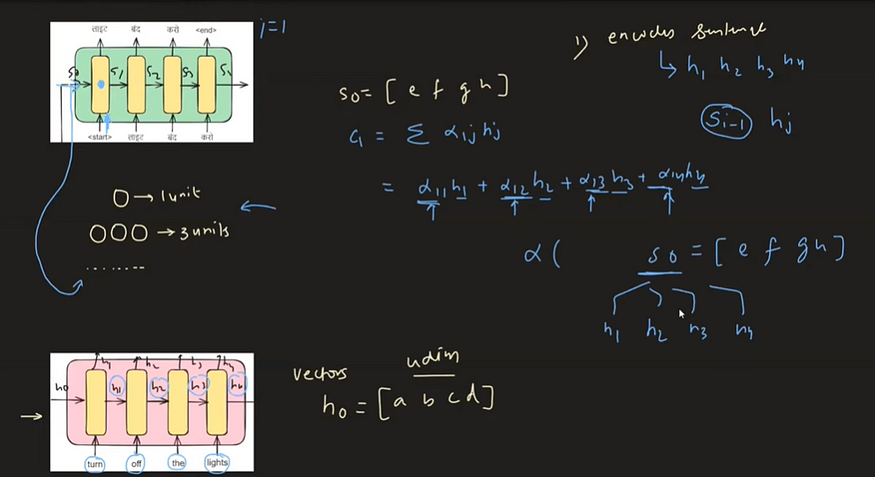
我们通过连接解码器的上一个时间戳隐藏状态 ( s0) 和每个编码器隐藏状态 ( hi ) 来创建一个矩阵。然后将该矩阵输入神经网络以计算兼容性分数 (eij)。在获得兼容性分数后,我们应用softmax函数对其进行归一化,从而得到注意力权重(αij)。然后,这些注意力权重用于计算上下文向量 ( ci )。

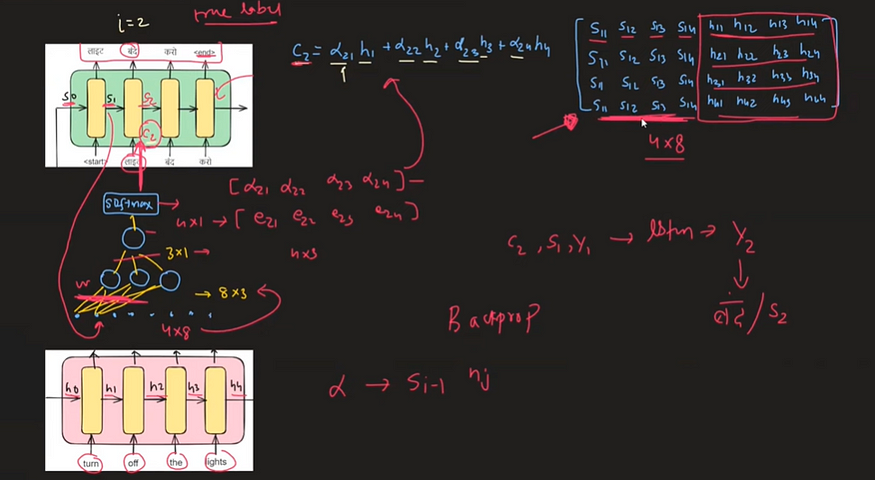
Bahdanau 的数学工作流程 注意:
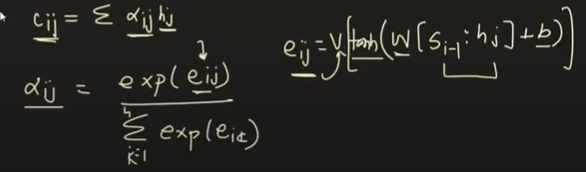
五、Luong 注意 :
在 Luong 注意力中,与 Bahdanau 注意力的第一个区别是,Luong 注意力没有考虑解码器端的先前隐藏状态值,而是合并了解码器的当前时间戳隐藏状态值。第二个区别在于注意力权重(α)值的计算方法:Luong注意力利用解码器当前时间戳隐藏状态(si)和每个编码器隐藏状态(hi)之间的点积。

在 Luong 注意力中,最后一个区别是上下文向量 ci 直接传递到 LSTM 单元的输出中,这与 Bahdanau 注意力中的方法形成鲜明对比,后者将上下文向量与 LSTM 单元的输入连接起来。这种将上下文向量简化到 LSTM 单元输出中的集成简化了解码过程,并增强了模型生成准确输出的能力。图表确实可以帮助直观地理解这些概念。
六、注意机制的好处:
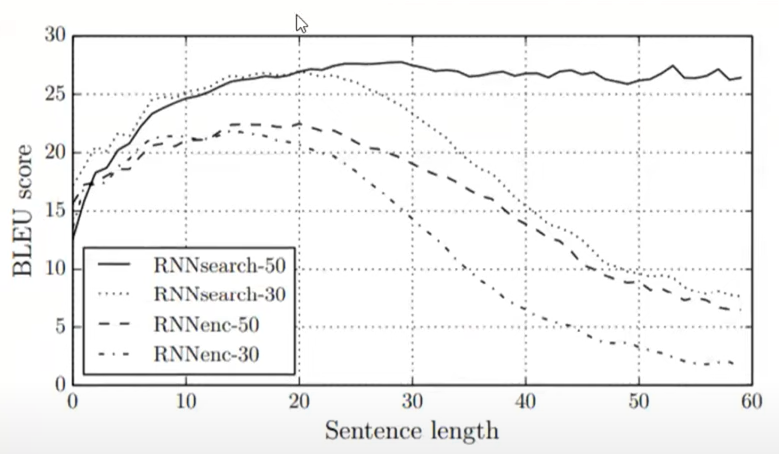
下图说明,将注意力机制集成到编码器-解码器架构中可以防止随着段落中句子长度的增加而降低 BLEU 分数。
七、引用:
研究论文: 通过共同学习对齐和翻译的神经机器翻译
Youtube频道 : https://youtu.be/0hZT4_fHfNQ?si=ALRyGf-bNeHKMvdk
我相信这篇博客丰富了你对编码器解码器架构中注意力机制的理解。如果您发现此内容的价值,我邀请您保持联系以获取更有见地的帖子。非常感谢您的时间和兴趣。感谢您的阅读!