由上一章结尾,我们知道神经网络的一个重要性质是它可以自动地从数据中学习到合适的权重参数。接下来会介绍神经网络的概要,然后再结合手写数字识别案例进行介绍。
1.神经网络概要
1.1从感知机到神经网
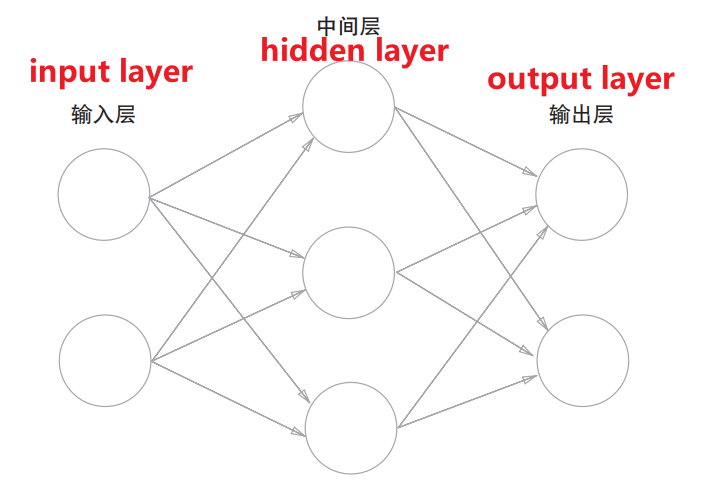
我们可以用图来表示神经网络,我们把最左边的一列称为输入层,最右边的一列称为输出层,中间的一列称为中间层(隐藏层)。
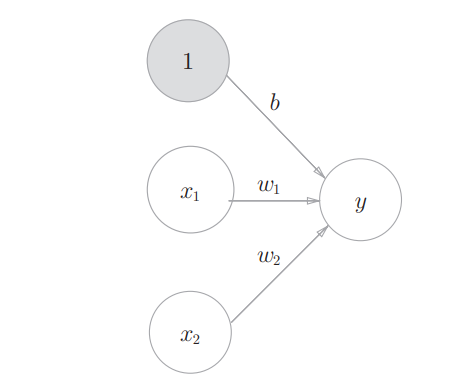
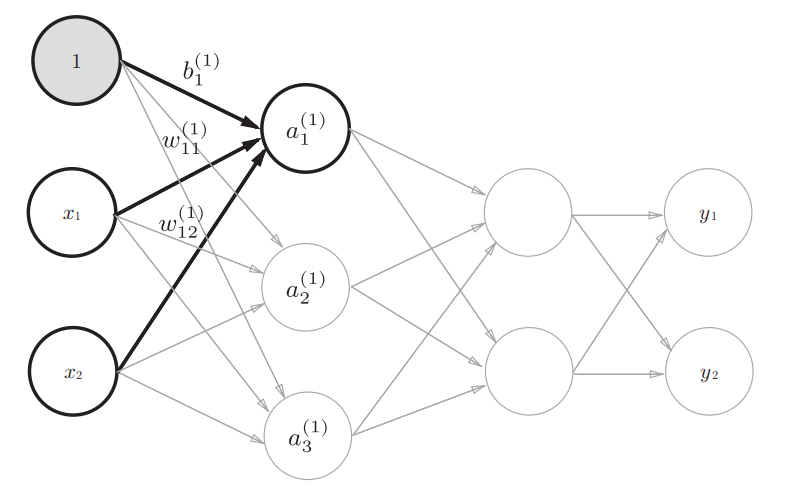
在感知机的基础上,我们添加权重为b的输入信号1。这个感知机将x1、x2、1三个信号作为神经元的输入,将其和各自的权重相乘后传送至下一个神经元。在下一个神经元中,计算这些加权信号的总和。由于偏置的输入信号一直是1, 所以为了区别于其他神经元,我们在图中把这个神经元整个涂成灰色(如下图所示)。
我们改写感知机的数学表达式,用一个函数h(x)来表示这种分情况的动作(超过0则输出1,否则输出0):
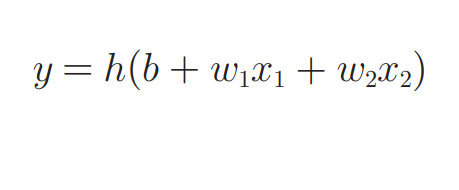
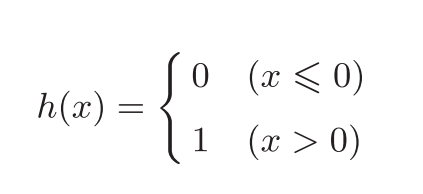
1.2激活函数(连接感知机和神经网络的桥梁。)
先来了解一下神经网络中的激活函数的概念。上面给出的h(x)函数会将输入信号的总和转换为输出信号,这种函数一般称为激活函数(activation function)。如"激活"一词所示,__激活函数的作用在于决定如何来激活输入信号的总和。__神经网络可表达为如下方式:
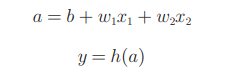

上述图像展示了信号的加权总和为节点a被激活函数h()转换成节点y的详细过程。在一般的神经网络图中不表达为上述形式,而是以一个圆圈表示上述的整个过程。
接下来介绍几种常用的激活函数:
① sigmoid函数(水车,根据流入量决定流出量)

exp(-x)指的是e (−x)次方 ,e为的自然常数(纳皮尔常数2.7182...)。其本质就是给定某个输入后,会返回某个输出的转换器。值得注意的是,sigmoid函数的平滑性对神经网络的学习具有重要意义。sigmoid函数的图像及代码实现如下所示。

def sigmoid(x):
return 1 / (1 + np.exp(-x))② 阶跃函数(竹筒敲石,到达一定值才输出1)

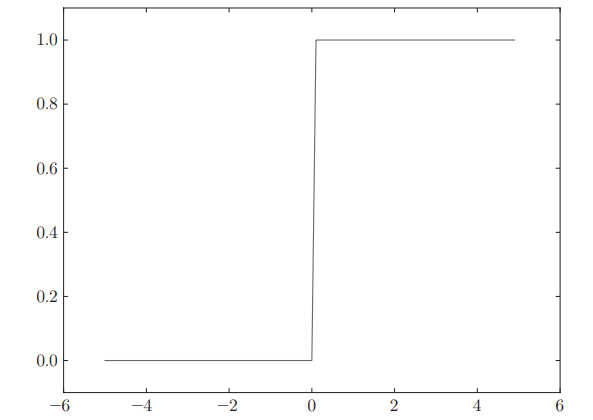
def step_function(x):
if x > 0:
return 1
else:
return 0
#为支持Numpy数组的实现,我们将阶跃函数的实现改为:
#对输入的NumPy数组x进行不等号运算,生成一个布尔型数组。
#数组x中大于0的元素被转换为True,小于等于0的元素被转换为False。
#将布尔型数组输出为阶跃函数输出的0或1。True转换为1,False转换为0。
def step_function(x):
return np.array(x > 0, dtype=np.int)上面介绍的sigmoid函数和阶跃函数均为非线性函数。神经网络的激活函数必须使用非线性函数。换句话说,激活函数不能使用线性函数。为什么不能使用线性函数呢?因为使用线性函数的话,加深神经网络的层数就没有意义了。
③ ReLU函数(Rectified Linear Unit)
ReLU函数在输入大于0时,直接输出该值;在输入小于等于0时,输 出0。
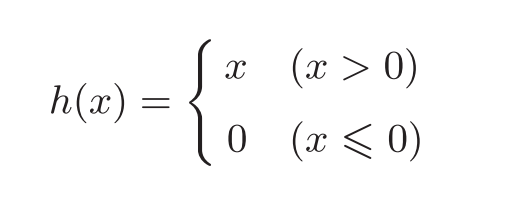

def relu(x):
return np.maximum(0, x)1.3 多维数组的运算
在高校实现神经网络之前,需要掌握Numpy多维数组的运算。
import numpy as np
A = np.array([1, 2, 3, 4])
print(A) # [1 2 3 4]
np.ndim(A) # 1 数组的维数
A.shape # (4,) 数组的形状
A.shape[0] # 4 第一个维度的大小,为行数,表示改数组为4行1列。
A = np.array([[1,2], [3,4]])
B = np.array([[5,6], [7,8]])
np.dot(A, B)
#array([[19, 22],
# [43, 50]])
C = np.array([[1,2], [3,4]])
np.dot(A, C) # 不能完成矩阵乘法因为A的列数不等于C的行数2. 3层神经网络的实现
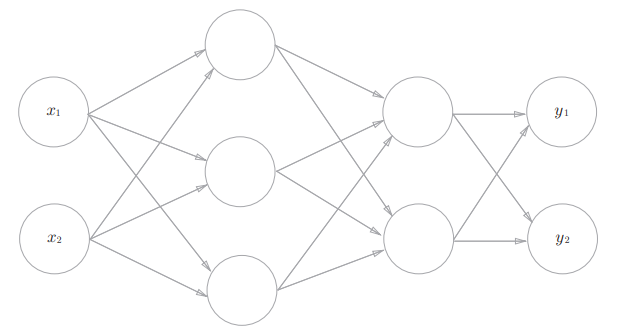
2.1 符号规定
为了便于理解如何从Numpy数组之间的运算对应到神经网络图中的信息流动过程,故对神经网络表示的符号进行说明。
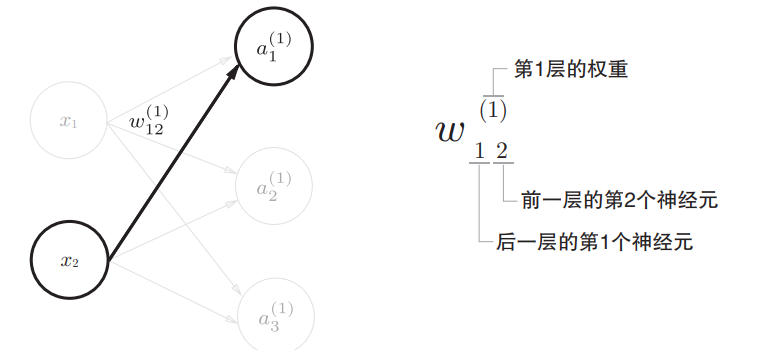
现在开始推导前向传播的整个过程:
第0层到第1层的第一个数值a1(1)计算方法为:
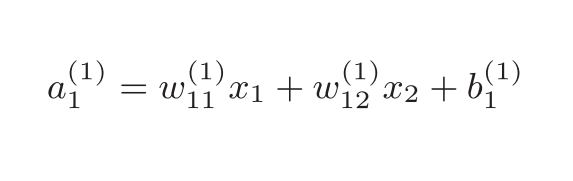
推广到第一层的三个值:

第0层到第1层的Numpy数组实现如下:
X = np.array([1.0, 0.5])
W1 = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]]) #0-1层的权重矩阵
B1 = np.array([0.1, 0.2, 0.3]) #0-1层的偏置矩阵
print(W1.shape) # (2, 3)
print(X.shape) # (2,)
print(B1.shape) # (3,)
A1 = np.dot(X, W1) + B1
Z1 = sigmoid(A1)
print(A1) # [0.3, 0.7, 1.1]
print(Z1) # [0.57444252, 0.66818777, 0.75026011]同理第1层到第2层的Numpy数组实现如下:
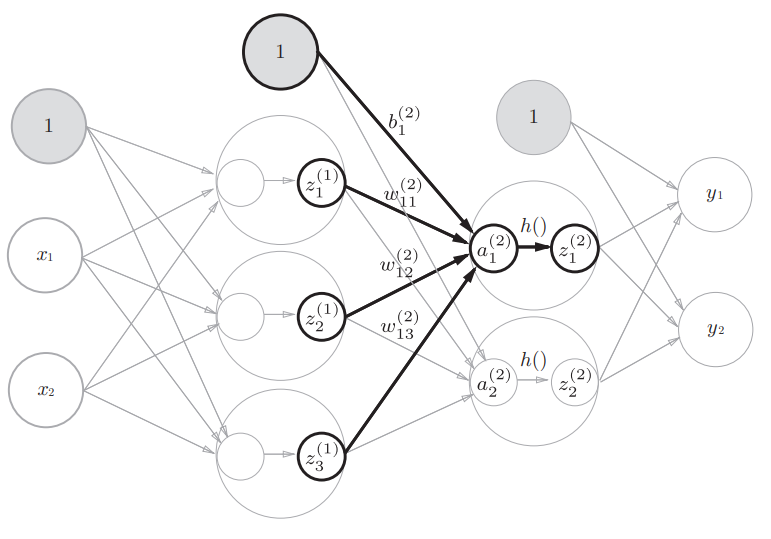
W2 = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
B2 = np.array([0.1, 0.2])
print(Z1.shape) # (3,)
print(W2.shape) # (3, 2)
print(B2.shape) # (2,)
A2 = np.dot(Z1, W2) + B2
Z2 = sigmoid(A2)第2层到第3层(输出层)的实现:
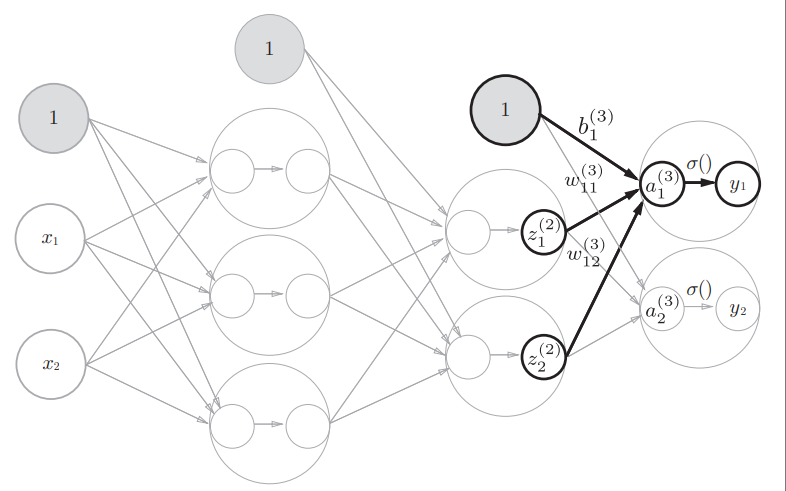
def identity_function(x): # 恒等函数,将输入按原样输出,仅起程序一致作用
return x
W3 = np.array([[0.1, 0.3], [0.2, 0.4]])
B3 = np.array([0.1, 0.2])
A3 = np.dot(Z2, W3) + B3
Y = identity_function(A3) # 或者Y = A3最后,我们把整个过程串起来,一个完整的实现:
def init_network():
network = {}
network['W1'] = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
network['b1'] = np.array([0.1, 0.2, 0.3])
network['W2'] = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
network['b2'] = np.array([0.1, 0.2])
network['W3'] = np.array([[0.1, 0.3], [0.2, 0.4]])
network['b3'] = np.array([0.1, 0.2])
return network
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = identity_function(a3)
return y
network = init_network()
x = np.array([1.0, 0.5])
y = forward(network, x)
print(y) # [ 0.31682708 0.69627909]3.输出层的设计
神经网络可以用在分类问题和回归问题上,不过需要根据情况改变输出 层的激活函数。一般而言,回归问题用恒等函数,分类问题用softmax函数。恒等函数会将输入按原样输出,对于输入的信息,不加以任何改动地直 接输出。
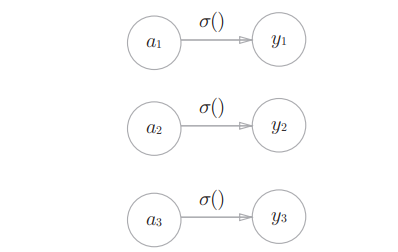
softmax函数的分子是输入信号ak的指数函数,分母是所有输入信号的指数函数的和。输出层的各个神经元都受到所有输入信号的影响。可以用下面进行表示和实现:
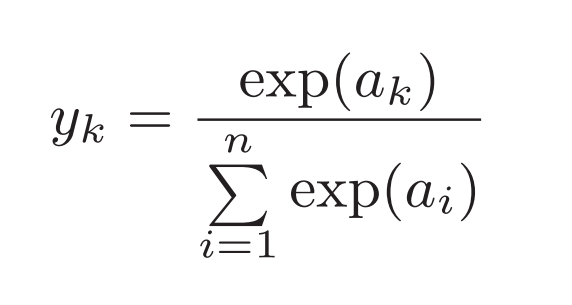

def softmax(a): #a为倒数第二层的输出向量
exp_a = np.exp(a)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y上面的softmax函数的实现虽然正确描述了上式,但在计算机的运算中有缺陷即溢出问题。softmax函数的实现中要进行指数函数运算,指数函数的值很容易变得非常大。比如,e 的100次方会变成一个后面有40多个0的超大值,e 的1000次方的结果会返回一个表示无穷大的inf。如果在这些超大值之间进行除法运算,结果会出现"不确定"的情况。为了避免溢出问题,常常使用下面的计算方法便是softmax函数。

上面的C撇可以使用任何值,但是为了防止溢出,一般会使用输入信号(倒数第二层输出向量a)中的最大值。具体实例如下:
a = np.array([1010, 1000, 990])
np.exp(a) / np.sum(np.exp(a)) # softmax函数的运算
array([ nan, nan, nan]) # 没有被正确计算
c = np.max(a) # 1010
print(a - c) # array([ 0, -10, -20])
print(np.exp(a - c) / np.sum(np.exp(a - c)))
# array([ 9.99954600e-01, 4.53978686e-05, 2.06106005e-09])
print(np.sum(np.exp(a - c) / np.sum(np.exp(a - c)))) # 1
# 和为1,故softmax函数可以作为多分类问题的激活函数(依概率输出)改进后的softmax函数实现为:
def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c) # 溢出对策
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y一般而言,神经网络只把输出值最大的神经元所对应的类别作为识别结果。 并且,即便使用softmax函数,输出值最大的神经元的位置也不会变。因此, 神经网络在进行分类时,输出层的softmax函数可以省略。在实际的问题中, 由于指数函数的运算需要一定的计算机运算量,因此输出层的softmax函数 一般会被省略。
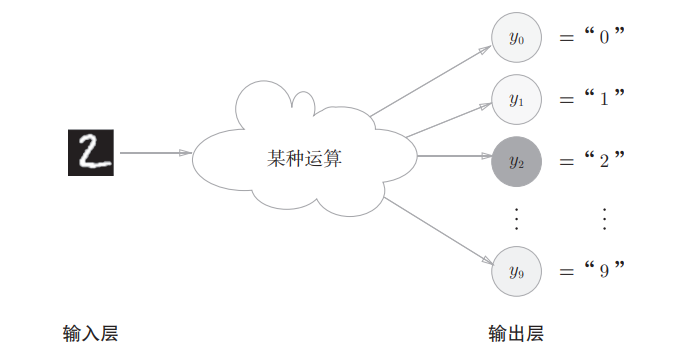
上图表示了手写数字的识别(10分类问题),输出值越大,颜色越"灰"。由于有softmax函数,最终的输出值均在0~1之间,且所有输出值的和为1。因此,输出之中的最大值可以作为该神经网络预测该图片中的数字为2的概率。