Mamba:基于选择状态空间的线性时间序列建模
Albert Gu∗1 和 Tri Dao∗2
卡内基梅隆大学机器学习系
普林斯顿大学 计算机科学系
ag@u.cs.cmu.edu, tri@tridao.me
摘要
现在驱动深度学习中大多数令人兴奋的应用程序的基础模型,几乎普遍基于变压器架构及其核心注意力模块。已经开发出了许多次方时间的架构,如线性关注、门控卷积和循环模型以及结构化状态空间模型(SSM),以解决变压器在长序列上的计算低效性,但它们在诸如语言等重要模态上没有表现出与注意力相同的效果。我们发现这类模型的一个关键弱点是无法进行基于内容的推理,并做出了几个改进。首先,简单地让 SSMS 参数成为输入的函数解决了它对离散模态的缺陷,使模型能够根据当前标记选择传播或遗忘信息沿着序列长度维度。其次,尽管这一变化阻止了高效卷积的使用,但我们设计了一个在循环模式下针对硬件并行的算法。我们将这些选择性的 SSMS 集成到一个简化版端到端神经网络架构中,该架构不包含注意力甚至多层感知机块(Mamba)。Mamba 享有快速推断(比变压器高出 5 倍的吞吐量)和序列长度的线性扩展,且在真实数据上性能提升高达数百万级的序列长度。作为一种通用序列模型,Mamba 在多个模态(例如语言、音频和基因组学)上实现了最先进的性能。在语言建模方面,我们的 Mamba-3B 模型在预训练和下游评估中均优于同规模的变压器,并且与两倍大小的变压器相匹配。
1. 简介
基础模型(FMs),即在大规模数据上预先训练好的模型,然后针对下游任务进行调整,已成为现代机器学习的有效范例。这些 FMs 的核心通常是序列模型,它们可以操作来自各种领域的输入序列,如语言、图像、语音、音频、时间序列和基因组学(Brown 等人,2020 年;Dosovitskiy 等人,2020 年;Ismail Fawaz 等人,2019 年;Oord 等人,2016 年;Poli 等人,2023 年;Sutskever、Vinyals 和 Quoc V Le,2014 年)。虽然这个概念对特定的模型架构选择持中立态度,但现代 FMs 主要基于一种序列模型:Transformer(Vaswani 等人,2017 年)及其核心注意力层(Bahdanau、Cho 和 Bengio,2015 年)。自我关注的效果归功于它能够在上下文窗口内密集路由信息,使其能够建模复杂的数据。然而,这种特性带来了根本性的缺点:无法建模有限窗口之外的任何事物,并且与窗口长度成二次方增长。已经出现了大量关于更有效注意力变体的研究,以克服这些缺点(Tay、Dehghani、Bahri 等人,2022 年),但通常是在牺牲使其实现有效的属性的基础上。到目前为止,还没有证据表明这些变体在跨领域大范围内证明其有效性。
最近,结构化状态空间序列模型(SSMs) (Gu、Goel 和 Ré, 2022; Gu、Johnson、Goel 等, 2021) 已成为序列建模的有希望的一类架构。这些模型可以解释为循环神经网络(RNN)和卷积神经网络(CNN)的组合,灵感来自经典的贝叶斯滤波器(Kalman, 1960)。这类模型可以以非常高效的方式计算,作为递归或卷积,并且具有线性或近似线性的扩展规模。此外,它们还有原则机制来处理某些数据模式中的长程依赖关系(Gu、Dao 等, 2020),并在诸如 Long Range 的基准测试中占主导地位
按名字首字母排序。
Arena 等人,2021 年。许多种 SSMS(Gu、Goel 和 Ré,2022;Gu、Gupta 等人,2022;Gupta、Gu 和 Berant,2022;Y. Li 等人,2023;Ma 等人,2023;Orvieto 等人,2023;Smith、Warrington 和 Linderman,2023)在涉及连续信号数据(如音频和视觉)的领域取得了成功(Goel 等人,2022;Nguyen、Goel 等人,2022;Saon、Gupta 和 Cui,2023)。然而,它们在建模文本等离散且信息密集的数据方面效果较差。
我们提出了一类新的选择性状态空间模型,它在多个维度上改进了以前的工作,以实现与序列长度线性扩展的变压器建模能力。
选择机制。首先,我们确定了先前模型的一个关键局限性:高效地根据输入(即关注或忽略特定输入)选择数据的能力。基于对重要合成任务的选择复制和归纳头的直观理解,我们设计了一个简单的选择机制,通过参数化 SSM 参数来实现。这使得模型能够过滤掉不相关的信息,并无限期地记住相关信息。
硬件感知算法。这种简单的改变给模型计算带来了技术挑战;事实上,为了高效计算,所有之前的 SSM 模型都必须具有时间和输入不变性。我们通过一种硬件感知算法来克服这一点,该算法使用扫描而不是卷积来递归地计算模型,但不会实现扩展状态,以避免在不同层次的 GPU 内存层次结构之间进行 I/O 访问。结果的实现比以前的方法更快,无论是在理论上(与基于卷积的所有 SSM 相比,在序列长度上呈线性增长,而伪线性为所有)还是在现代硬件上(在 A100 GPU 上最快可提高 3 倍)。
架构。我们通过将先前的 SSM 架构的设计(Dao、Fu、Saab 等人,2023 年)与 Transformer 的 MLP 块合并为一个块,从而简化了之前的深度序列模型架构,这导致了一个包含选择性状态空间的简单而统一的架构设计(Mamba)。
选择性自回归模型(SSMs)以及由此扩展出的 Mamba 架构,都是完全递归的模型。它们具有关键特性,使其非常适合用作一般基础模型的序列操作核心。(i)高质量:选择性为诸如语言和基因组学等稠密模态带来了出色的性能。(ii)快速训练和推断:在训练过程中,计算和内存都与序列长度呈线性增长;而在推理过程中,由于不需要缓存之前的元素,因此只需要常数时间来展开自回归模型,而无需花费额外的时间。(iii)长上下文:质量和效率共同提高了对真实数据的性能表现,最长可达 1M 序列长度。
我们在多种模态和设置上,通过验证Mamba作为通用序列FM后端的预训练质量和特定领域的任务性能来实证其潜力:
• 合成。在诸如复制和归纳等关键合成任务中,作为大型语言模型的关键组成部分,Mamba 不仅可以轻松解决这些问题,而且还可以无限期地推断解决方案 (> 1M 个标记)。
• 音频和基因组学。Mamba 在建模音频波形和 DNA 序列方面,无论是预训练质量还是下游指标(例如,在具有挑战性的语音生成数据集上将 FID 减少一半以上),都优于之前的最先进模型,如 SaShiMi、Hyena 和 Transformers。在两种情况下,它的性能随着上下文长度的增加而提高,可以处理长达一百万长度的序列。
• 语言建模。Mamba 是第一个真正实现与 Transformer 相同质量性能的线性时间序列模型,无论是预训练困惑度还是下游评估。通过 10 亿个参数的扩展法则,我们证明了 Mamba 超越了一系列基准,包括基于 LLaMA (Touvron et al. 2023) 的非常强大的现代 Transformer 训练食谱。我们的 Mamba 语言模型的生成吞吐量比类似大小的 Transformer 高 5 倍,而 Mamba-3B 的质量与其两倍大的 Transformer 相当(例如,在常识推理上的平均值比 Pythia-3B 高 4 分,甚至超过 Pythia-7B)。
模型代码和预训练检查点在 https://github.com/state-spaces/mamba 上开源。
2 状态空间模型
结构化状态空间序列模型(S4)是深度学习中的一类近期的序列模型,与循环神经网络、卷积神经网络和经典的状态空间模型密切相关。它们受到特定连续系统(1)的启发,该系统将一个
硬件感知状态扩展
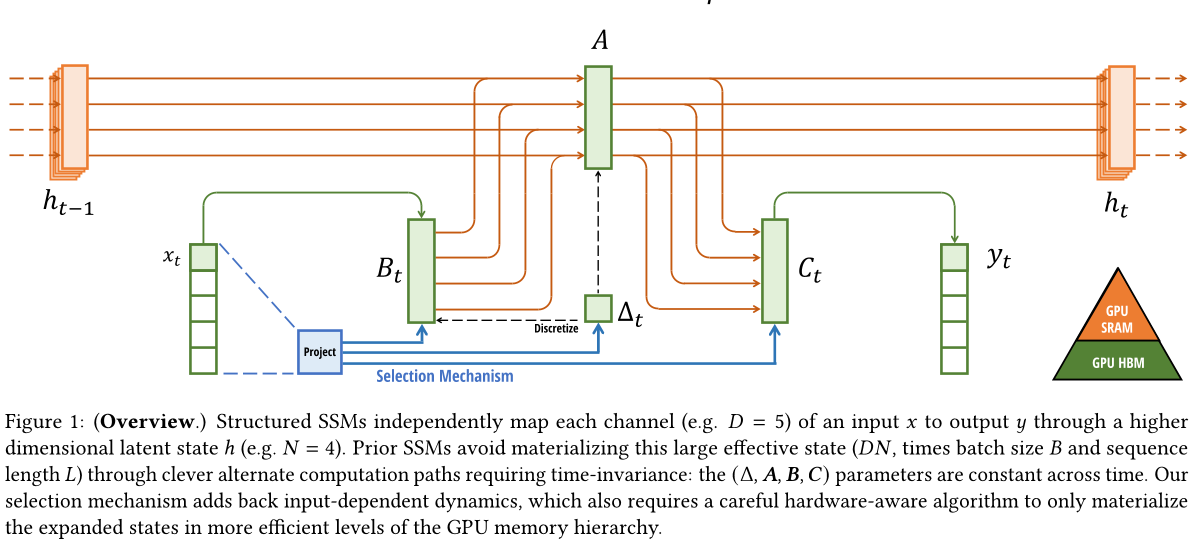
一个一维函数或序列x(t)∈R 🟥→y(t)∈R通过一个隐含的潜在状态h(t)∈RN。
具体来说,S4模型由四个参数(A、B、C)定义,这些参数在两个阶段中定义了一个序列到序列的转换。
离散化。第一阶段通过固定公式 A = fA (A, A) 和 B = fB (A, A, B) 将"连续参数"(A, A, B) 转换为"离散参数"(A, B),其中二元组 (fA, fB) 称为离散规则。可以使用各种规则,如方程 (4) 中定义的零阶保持器(ZOH)。
离散化与连续时间系统之间有深厚的联系,这赋予了它们额外的特性,如分辨率不变性(Nguyen、Goel等人,2022年)以及自动确保模型正确归一化(Gu、Johnson、Timalsina等人,2023年;Orvieto等人,2023年)。它还与RNN的门控机制有关(Gu、Gulcehre等人,2020年;Tallec和Ollivier,2018年),我们将在第3.5节中再次讨论。然而,从机械的角度来看,离散化可以简单地看作是SSM前向计算图的第一步。替代的SSM变体可以跳过离散化步骤,直接参数化(A,B)(Zhang等人,2023),这可能更容易推理。
计算。在参数从 (A, A, B, C) 变换为 (A, B, C) 之后,模型可以以两种方式计算:线性递归(2) 或全局卷积(3)。
通常,模型使用卷积模式(3)进行高效的并行训练(其中整个输入序列提前查看),并在有效的自回归推断中切换到循环模式(2)(其中一次只看一个时间步骤)。
线性时不变系统。方程(1)到(3)的一个重要特性是模型的动力学在时间上保持恒定。换句话说,A、B 和 C 在所有时间步长都是固定的,因此 A 和 B 也是固定的。这个性质可以被描述为
我们称之为 线性时间不变(LTI) ,它与递归和卷积密切相关。非正式地说,我们认为 LTI 随机微分方程等同于任何线性递归 (2a) 或卷积 (3b),并使用 LTI 作为这些模型类的通称。
到目前为止,所有结构化的隐式自回归模型都是线性时间不变的(例如,通过卷积计算)。这是因为第 3.3 节中讨论的基本效率限制。然而,这项工作的核心见解是,LTI 模型在建模某些类型的数据时存在固有局限性,而我们的技术贡献包括移除 LTI 约束并克服效率瓶颈。
结构与维度。最后,我们注意到,有结构的 SSM 是如此命名的原因是因为高效计算它们也需要对 A 矩阵施加结构。最常见的形式是对角线(Gu、Gupta等人,2022;Gupta、Gu 和 Berant,2022;Smith、Warrington 和 Linderman,2023),我们也使用这种形式。
在这种情况下,属于RN ×N、B 属于RN ×1 和C 属于R1×N 的矩阵都可以用N个数字来表示。为了对输入序列x进行处理,其批量大小为B,长度为L,具有D个通道,每个通道独立应用SSM。请注意,在这种情况下,总隐藏状态具有DN维度,计算它需要O(BLDN)的时间和内存;这是在第3.3节中讨论的基本效率瓶颈的根本原因。
一般状态空间模型。我们注意到"状态空间模型"这个词有非常广泛的意思,它只是代表了任何具有潜在状态的可复现过程的概念。它被用来指代许多不同学科中的许多不同的概念,包括马尔科夫决策过程(MDP)(强化学习(Hafner等人,2020年)),动态因果建模(DCM)(计算神经科学(Friston、Harrison和Penny,2003年)),卡尔曼滤波器(控制(Kalman,1960年)),隐马尔科夫模型(HMM)和线性动力学系统(LDS)(机器学习),以及更广泛的循环(有时是卷积)模型(深度学习)。
在本文中,我们用"结构化隐式状态模型(SSM)"一词来专门指代一类结构化的隐式状态模型或S4模型(Gu、Goel 和 Ré 2022;Gu、Gupta 等人。2022;Gupta、Gu 和 Berant 2022;Hasani 等人。2023;Ma 等人。2023;Smith、Warrington 和 Linderman 2023),并互换使用这些术语。为了方便起见,我们还可以包括此类模型的变体,例如侧重于线性递归或全局卷积观点的模型(Y. Li 等人。2023;Orvieto 等人。2023;Poli 等人。2023),并在必要时澄清细微差别。
序列到序列模型。 SSMS 是可以集成到端到端神经网络架构中的独立序列转换。(我们有时也把 SSMS 架构称为 SSNN,就像卷积神经网络中的卷积层一样) 我们会讨论一些最著名的 SSMS 架构,其中许多也将作为我们的主要基准线。
• 线性注意力(Katharopoulos et al. 2020)是对涉及递归的自注意的近似,可以将其视为退化的线性隐马尔可夫模型。
H3 (Dao、Fu、Saab等,2023) 将此递归推广到使用 S4;它可以被看作是一种具有两个门控连接之间的 SSM 的架构(图3)。H3还在主要的 SSM 层之前插入了一个标准局部卷积,他们将其称为位移-SSM。
Hyena (Poli等人,2023) 使用与H3相同的架构,但用MLP参数化的全局卷积替换了S4层(Romero等人,2021)。
RetNet (Sun等人,2023年) 在架构中添加了一个额外的门,并使用一个更简单的 SSM,从而允许使用多头注意力(MHA)的一种变体而不是卷积来进行替代并行计算路径。
• RWKV (B. Peng等人,2023年) 是一种最近设计用于语言建模的 RNN,基于另一种线性注意力近似------无关注力场Transformer (S. Zhai 等人,2021)。其主要"WKV"机制涉及LTI递归,并可以视为两个SSM之比。
在附录B中,我们进一步讨论了其他与之密切相关的模型和架构。 我们特别强调S5(Smith等人,2023)、QRNN(Bradbury等人,2016)和SRU(Lei等人,2017),我们认为这些方法最接近我们的核心选择性自回归模型。
3. 选择性状态空间模型
我们利用合成任务(第 3.1 节)的直觉来激励我们的选择机制,然后解释如何将其纳入状态空间模型(第 3.2 节)。由此产生的时变状态空间模型不能使用卷积,这给计算效率提出了技术挑战。通过一个硬件感知算法解决这个问题,该算法利用了现代硬件上的内存层次结构(第 3.3 节)。然后,我们描述了一个没有注意力或甚至多层感知器块的简单状态空间模型架构(第 3.4 节)。最后,我们讨论了一些选择机制的额外属性(第 3.5 节)。
3.1 激励:选择作为压缩的一种手段
我们认为,序列建模的基本问题在于如何将上下文压缩为更小的状态。事实上,我们可以从这个角度来审视流行序列模型之间的权衡。例如,注意力机制在效率上是有效的,但却是低效的,因为它不会对上下文进行任何压缩。这可以从自回归推理需要显式存储整个上下文(即 KV 缓存)这一事实中看出,这就直接导致了 Transformer 的线性推理时间和二次训练时间。另一方面,循环模型由于具有有限状态而高效,这意味着常数时间推理和线性时间训练。然而,它们的有效性受到这种状态对上下文压缩程度的限制。
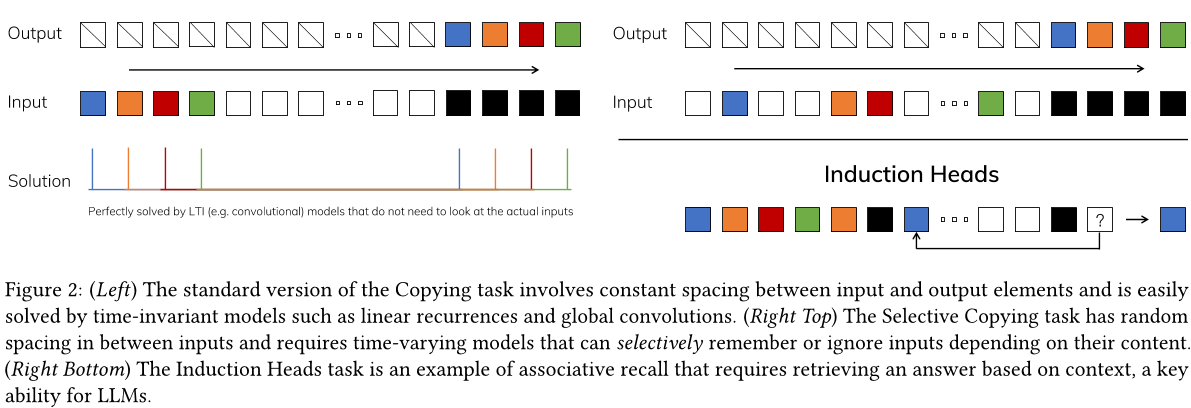
为了理解这一原则,我们关注两个合成任务的例子(图2)。
选择性复制任务通过改变要记住的标记的位置来修改流行的复制任务(Arjovsky、Shah 和 Bengio 2016)。它需要内容感知推理,以便能够记住相关的标记(彩色)并过滤掉不相关的标记(白色)。
• Induction Heads 任务是一种众所周知的机制,用于解释大多数语言模型在上下文中的学习能力(Olsson 等人,2022 年)。它需要对语境进行推理,以了解何时以及如何在适当的情况下生成正确的输出(黑色)。
简而言之,序列模型的效率与有效性权衡由它们压缩状态的能力来刻画:高效模型必须具有小的状态,而有效模型必须具有包含来自上下文的所有必要信息的状态。反过来,我们提出构建序列模型的基本原则是选择性,即能够关注或过滤输入以进入序列状态的上下文感知能力。具体来说,选择机制控制着信息如何沿着序列维度传播或交互(参见第3.5节进行更多讨论)。
3.2 通过选择改进 SSMs
一种在模型中引入选择机制的方法是让影响序列交互的参数(例如,RNN 的递归动力学或 CNN 的卷积核)依赖于输入。
算法1和2展示了我们使用的主要选择机制。主要区别在于,简单地使几个参数A、B、C成为输入的函数,并相应地改变张量形状。具体来说,我们强调这些参数现在具有长度维度L,这意味着模型已经从不变性变为可变性。(注意:形状注释在第2节中进行了描述。)这导致了与卷积(3)等价性的丧失,从而对其效率产生了影响,如下面讨论的那样。
我们特别选择sB(x) = LinearN(x), sC(x) = LinearN(x), sA(x) = BroadcastD(Linear1(x)) 和τa = softplus,其中Lineard 是一个参数化投影到维度d。sa 和τt 的选择与在第3.5节中解释的RNN门控机制有关。

3.3 选择性SSM的有效实现
硬件友好的基本元素,如卷积( Krizhevsky、Sutskever 和 Hinton,2012 年)和注意力( Bahdanau、Cho 和 Bengio,2015 年; Vaswani 等人,2017 年),得到了广泛的应用。在这里,我们的目标是在现代硬件(GPU)上高效地实现选择性 SSM。这种选择机制非常自然,早期的工作试图纳入选择的一些特殊情况,例如在递归 SSM 中让 A 随时间变化(Gu、Dao 等人,2020 年)。但是,正如前面提到的,SSM 的使用存在一个关键限制,即它们的计算效率低下,这就是为什么 S4 及其所有变体都使用了线性时不变 (LTI) 模型,最常见的是全局卷积的形式。
3.3.1 早期模型的动机
我们首先回顾这一动机,并概述了克服先前方法局限性的方法。
• 高级地,如 SSMs 这样的递归模型总是权衡表达能力和速度:正如第 3.1 节讨论的那样,具有更大隐藏状态维度的模型应该更有效但运行速度会慢一些。因此我们希望在不支付速度和内存成本的情况下最大化隐藏状态维度。
注意,递归模式比卷积模式更灵活,因为后者(3)是由前者的扩展计算得到的。 (Gu, Goel 和 Ré, 2022; Gu, Johnson, Goel 等人, 2021)。然而,这需要计算并生成形状为 (B, L, D, N) 的潜在状态 h,其大小(N 是 SSM 状态维度的倍数)远大于输入 x 和输出 y 的形状 (B, L, D)。因此引入了更有效的卷积模式,它可以跳过状态计算,并生成仅包含 (B, L, D) 的卷积核(3a)。
• 之前的 LTI 状态空间模型利用双重递归卷积形式,以 N(≈10−100) 的因子增加有效状态维度,比传统的 RNN 大得多,而不会产生效率损失。
3.3.2 选择扫描概述:硬件感知状态扩展
选择机制旨在克服 LTI 模型的局限性;因此,我们需要重新审视 SSM 的计算问题。我们使用三种经典技术来解决这个问题:核融合、并行扫描和重新计算。我们的观察如下:
• 简单循环计算使用 O(BLDN) 浮点运算,而卷积计算使用 O(BLDlog(L)) 浮点运算,前者具有较小的常数因子。因此对于长序列和不太大的状态维度N,循环模式实际上可以少用一些浮点运算。
• 两个挑战分别是递归的顺序性质,以及巨大的内存使用。为了应对后一个挑战,就像卷积模式一样,我们可以尝试不实际生成完整的状态h。
主要思想是利用现代加速器(GPU)的特性,仅在内存层次结构中更有效率的级别上实现状态h。特别是,除了矩阵乘法之外,大多数操作(Dao、Fu、Ermon等人,2022;Ivanov等人,2021;Williams、Waterman和Patterson,2009)都受到内存带宽的限制。这包括我们的扫描操作,我们使用内核融合来减少内存IO的数量,从而比标准实现产生显著的速度提升。
具体来说,我们不准备GPU HBM(高带宽内存)中大小为 (B, L, D, N) 的扫描输入,而是直接从慢HBM加载SSM参数(A, A, B, C),在SRAM中执行离散化和递归,然后将大小为 (B, L, D) 的最终输出写回到HBM。
为了避免这种顺序递归,我们观察到尽管它不是线性的,但仍然可以使用工作高效的并行扫描算法进行并行化(Blelloch 1990;Martin 和 Cundy 2018;Smith、Warrington 和 Linderman 2023)。
最后,我们还必须避免保存反向传播所需的中间状态。 我们仔细应用了经典的重新计算技术来减少内存需求:在从 HBM 加载到 SRAM 时,在反向传递过程中重新计算中间状态而不是存储它们。 因此,与优化的带 FlashAttention 的 Transformer 实现相比,融合选择性扫描层具有相同的内存要求。
融合内核和重新计算的详细信息在附录D中。完整的选择性SSM层和算法如图1所示。
3.4 简化的 SSM 架构
与结构化自回归模型类似,选择性自回归模型是独立于序列的转换,可以灵活地嵌入到神经网络中。H3 架构是所有已知的自回归架构的基础(第 2 节),通常由一个受线性注意力启发的块和一个多层感知机 (MLP) 块交替组成。我们通过将这两个组件合并为一个堆叠式同质组件来简化该架构(图 3)。这是受到门控注意力单元 (GAU) 的启发(华等人,2022 年),它对注意力做了类似的处理。
这种架构通过可控制扩展因子E来增加模型维度D。对于每个块,大部分参数(3ED2)都在线性投影中(输入投影为2ED2,输出投影为ED^2),而内部 SSM 的贡献较少。SSM 参数(A、B、C 的投影和矩阵A)的数量比这些要少得多。我们在标准归一化和残差连接之间重复这个块以形成 Mamba 架构。在我们的实验中,我们总是固定 E = 2,并使用两个堆叠块来匹配交织的 MHA(多头注意力)和 MLP 块的 12D^2 参数。我们使用 SiLU/Swish 激活函数(Hendrycks 和 Gimpel 2016;Ramachandran、Zoph 和 Quoc V Le 2017),以使门控 MLP 成为流行的"SwiGLU"变体(Chowdhery 等人,2023;Dauphin 等人,2017;Shazeer,2020;Touvron 等人,2023)。最后,我们额外使用一个可选的归一化层(我们选择层归一化(Ba、Kiros 和 Hinton,2016)),这是受 RetNet 在类似位置使用归一化层的启发(Sun 等人,2023)。
3.5 选择机制的性质
选择机制是一种更广泛的概念,可以用不同的方式应用于各种传统循环神经网络或卷积神经网络、不同参数(例如算法2中的A)或使用不同的变换s(x)。
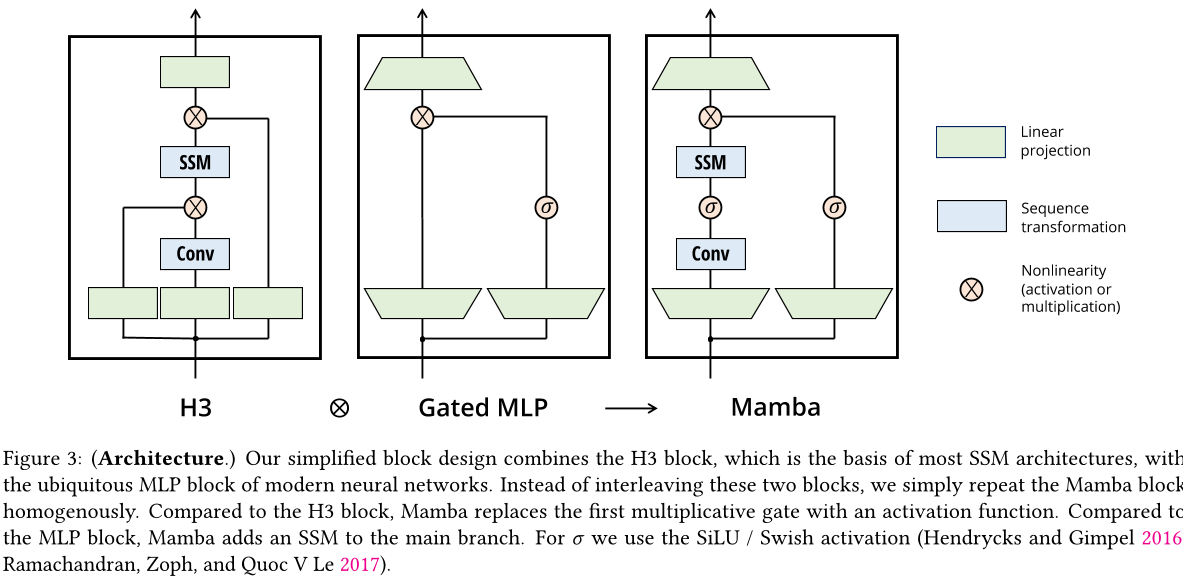
图3:(体系结构)。我们简化了块设计,将大多数SSM体系结构的基础H3块与现代神经网络中无处不在的MLP块相结合。我们没有交错这两个块,而是简单地重复使用Mamba块。与H3块相比,Mamba用激活函数替换了第一个乘法门。与MLP块相比,Mamba在主分支上添加了一个SSM。对于σ,我们使用SiLU/Swish 激活 ( Hendrycks 和 Gimpel 2016 ; Ramachandran 等人 2017 )。
3.5.1 连接门控机制
我们强调了最重要的联系:RNN 的经典门控机制是我们在 SSM 中选择机制的一个实例。我们注意到 RNN 门控与连续时间系统离散化之间的联系已经得到很好的建立(Funahashi 和 Nakamura,1993;Tallec 和 Ollivier,2018)。事实上,定理 1 是对 Gu 等人的改进(2021,引理 3.1),它推广到 ZOH 离散化和输入相关门(证明在附录 C 中)。更广泛地说,在 SSM 中,A 可以被视为 RNN 门控机制的一种一般化角色。根据以往的研究,我们认为 SSM 的离散化是启发式门控机制的合理基础。
定理 1。当 N = 1,A = -1,B = 1,sA = 线性(x),τa = softplus 时,选择性 SSM 循环(算法 2)采用如下形式
如第 3.2 节所述,我们对 sA 和 τA 的具体选择源于这种联系。特别要注意的是,如果给定的输入 x t 应该被完全忽略(在合成任务中是必要的),那么所有 D 个通道都应该忽略它,因此我们在重复/广播之前先将其投影到一维上。
3.5.2 选择机制的解释
我们详细阐述了选择的三种特定机制效应。
可变间距。选择性使模型能够过滤掉可能出现在感兴趣输入之间的不相关噪声标记。这一特性在 Selective Copying 任务中得到了体现,但在常见的数据模态中无处不在,尤其是离散数据------例如语言填充词的存在(如"额")。这种性质出现是因为模型可以机械地滤除任何特定的输入xt,在门控循环神经网络 (gated RNN) 的情况下 (Theorem 1),当gt→ 0时。
过滤上下文。 实验观察到,许多序列模型在更长的上下文环境中性能没有提高(Shi等人,2023年),尽管更多的上下文应该导致严格更好的性能的原则。 一个解释是,许多序列模型不能有效地忽略不相关的上下文;直观的例子是全局卷积(以及广义LTI模型)。 另一方面,选择性模型可以简单地在任何时候重置其状态以消除不必要的历史记录,因此它们的性能原则上随着上下文长度单调地改善(例如,第4.3.2节)。
边界重置。在多个独立序列串联在一起的情况下,transformer 可以通过实例化一个特定的注意力掩码来保持它们之间的分离,而长短期记忆模型会在序列之间泄漏信息。选择性状态向量也可以在边界处重置状态(例如,在 gt → ∞ 或当 gt → 1 时)。这些设置可能是人为的(例如,为了提高硬件利用率而将文档打包在一起)或自然的(例如,在强化学习中遇到的序列边界(Lu等人,2023年))。
此外,我们还详细阐述了每个选择参数的影响。
A 的解释。一般来说,A 控制着当前输入xt应集中或忽略的程度之间的平衡。它推广了循环神经网络门(例如定理1中的gt):从机械上讲,大的A重置状态h并关注当前输入x,而小的A保持状态并忽略当前输入。SSM (1) - (2) 可以被解释为一个由时间步长A离散化的连续系统,在这种情况下,直观地理解为大A→∞表示系统更长时间地关注当前输入(因此"选择"它并忘记其当前状态),而小A→0表示被忽略的瞬态输入。
解释A。我们注意到,尽管参数A也可以选择性地影响模型,但最终它只通过与A 的交互作用来影响模型(通过离散化)。因此,在A 中具有选择性足以确保在(A, B)中具有选择性,并且是主要的改进来源。我们假设使A 除了(或代替)A 具有选择性会具有相似的表现,并出于简单起见将其省略。
解释B和C。如第3.1节所述,选择性最重要的属性是过滤掉不相关的信息,这样序列模型的上下文就可以被压缩成一个有效的状态。在 SSM 中,通过使 B 和 C 具有选择性来修改它们,这使得可以更细粒度地控制是否允许输入 x t 进入 h t 或者从 h t 输出 y t 。这些可以理解为根据内容(输入)和上下文(隐藏状态)分别调节循环动力学。
3.6 其他模型细节
实数与复数。大多数先前的 SSM 在其状态向量 h 中使用复数,这对于感知模态任务的强性能至关重要(Gu、Goel 和 Ré,2022 年)。然而,人们已经观察到,在某些情况下,完全由实数组成的 SSM 似乎可以很好地工作,甚至可能更好(Ma 等人,2023 年)。我们在默认情况下使用实值,对于我们的所有任务来说效果都很好;我们假设复数-实数权衡与数据模式中的连续-离散谱相关,其中复数对连续模式(例如音频、视频)有帮助,但对离散模式(例如文本、DNA)没有帮助。
初始化。大多数之前的 SSM 方法也建议特殊的初始化,尤其是在复数情况中,这有助于许多低数据设置。我们对复数情况的默认初始化为 S4D-Lin 和实数情况的默认初始化为 S4D-Real (Gu、Gupta 等人,2022),这是基于 HIPPO 理论(Gu、Dao 等人,2020)。这些定义了矩阵 A 的第 n 个元素分别为 -1/2 + ni 和 -(n+1)。然而,我们预计许多初始化都会起作用,特别是在大数据和实值 SSM 情况下;一些修剪在第 4.6 节进行了讨论。
对A的参数化。我们定义了对A的选择性调整sA(x) = BroadcastD(Linear1(x)),这是由A的动力学(第3.5节)驱动的。我们观察到它可以推广到从一维到更大的维度R。我们将其设置为D的小部分,与块中的主要线性投影相比使用很少的参数。此外,我们注意到广播操作可以看作另一个线性投影,初始化为特定的1和0模式;如果这个投影是可训练的,那么这就导致了替代方案sA(x) = LinearD(LinearR(x)),可以视为低秩投影。
在我们的实验中,参数A(可以看作偏差项)初始化为τ−1(Uniform(0.001, 0.1)),这是根据之前对SSMs的工作(Gu等人,2023年)。
注释 3.1。为了简明起见,我们在实验结果中有时将选择性自适应模糊神经元模型缩写为S6模型,因为它们是带有选择机制的S4模型,并且通过扫描计算。
4 实证研究
在第 4.1 节中,我们测试了 Mamba 解决在第 3.1 节中启发的两个合成任务的能力。然后我们在三个领域进行评估,每个领域都对自回归预训练以及下游任务进行了评估。
• 第4.2节:语言模型预训练(扩展法则),以及零样本下游评估。
• 第4.3节:DNA序列预训练,以及在长序列分类任务上进行微调。
• 第4.4节:音频波形预训练,以及自回归生成语音片段的质量。
最后,第 4.5 节展示了 Mamba 在训练和推理时间上的计算效率,而第 4.6 节则消除了架构的各种组件和选择性状态转移。
4.1 生成任务
这些任务的完整实验细节,包括任务细节和训练协议,请参见附录 E.1。
4.1.1 选择性复制
复制任务 是序列建模中最广泛研究的人工合成任务之一,最初设计用于测试循环模型的记忆能力。如第 3.1 节所述,线性递归 (LTI) 隐马尔可夫模型 可以轻松地通过只关注时间而不是数据来解决此问题;例如,通过构造长度恰好正确的卷积核(图 2)。在早期关于全局卷积的工作中已经明确验证了这一点(Romero等人,2021年)。选择性复制任务 通过随机化标记之间的间距来防止这种捷径。需要注意的是,该任务以前被称为去噪任务(Jing等人,2019年)。
请注意,许多以前的工作表明,添加架构门控(乘法交互)可以赋予模型"数据依赖性",并解决相关任务(Dao、Fu、Saab等人,2023;Poli等人,2023)。然而,我们直观地发现这种解释不足,因为这样的门控不会沿着序列轴进行交互,并且不能影响标记之间的间距。特别是,架构门控不是选择机制的一个实例(附录A)。
表1证实了像H3和Mamba这样的门控架构在性能上只带来了部分改善,而选择机制(修改S4到S6)很容易解决这个任务,特别是当与这些更强大的架构结合使用时。
4.1.2 激励头
诱导头(Olsson等人,2022年)是从机制可解释性的角度(Elhage等人,2021年)提出的简单任务,令人惊讶地预测了 LLM 的上下文学习能力。它要求模型执行关联回忆和复制:例如,如果模型在序列中看到一个二元组,如"哈利·波特",那么当下一次"哈利"出现在同一序列时,模型应该能够通过从历史记录中复制来预测"波特"。
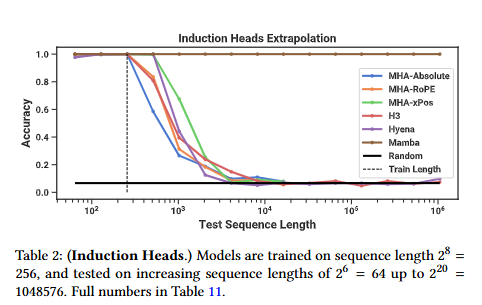
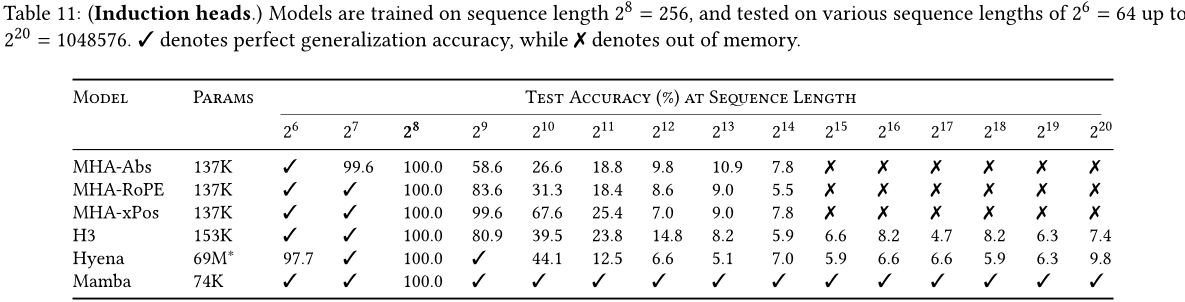
数据集。我们在序列长度为 256、词汇大小为 16 的情况下,训练了一个两层模型来处理感应头任务,这与之前在这个任务上的工作(Dao、Fu、Saab 等人,2023 年)相似,但使用了更长的序列。我们还通过在测试时评估一系列序列长度从 2^6 = 64 到 2^20 = 1048576 来研究泛化能力和外展能力。
模型。在先前关于诱导头的工作基础上,我们使用了两层模型,这使得注意力能够从机制上解决诱导头的任务(Olsson等人,2022)。我们测试了多头注意力(8个头部,带有各种位置编码)和SSM变体。我们在Mamba中使用了64维的模型维度,在其他模型中使用了128维。
结果。表2显示,Mamba 或更确切地说,其选择性 SSM 层能够完美地解决该任务,因为它有能力选择性地记住相关的标记,同时忽略其他所有在中间的内容。它能够完美地推广到比训练期间看到的长100万倍的数据序列(即比其训练数据长4000 倍),而没有任何其他方法超过两倍。
表1:
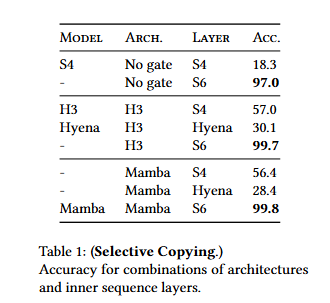
架构和内部序列层组合的准确性。
在注意力模型的不同位置编码变体中,用于长度外推的设计的位置编码xPos比其他位置编码略好;此外,请注意由于内存限制,所有注意力模型都只测试到序列长度为214 = 16384。与Poli等人(2023)的研究结果相反,在其他 SSM 中,H3 和Hyena 相似。
4.2 语言建模
我们在标准自回归语言建模任务上评估了毒蛇架构,与其他架构相比,在预训练指标(困惑度)和零样本评估方面。我们设置模型大小(深度和宽度)以反映GPT-3规范。我们使用Pile数据集(L. Gao, Biderman等人,2020),并遵循Brown等人(2020)中描述的训练食谱。所有训练细节都在附录E.2中。
4.2.1 缩放定律
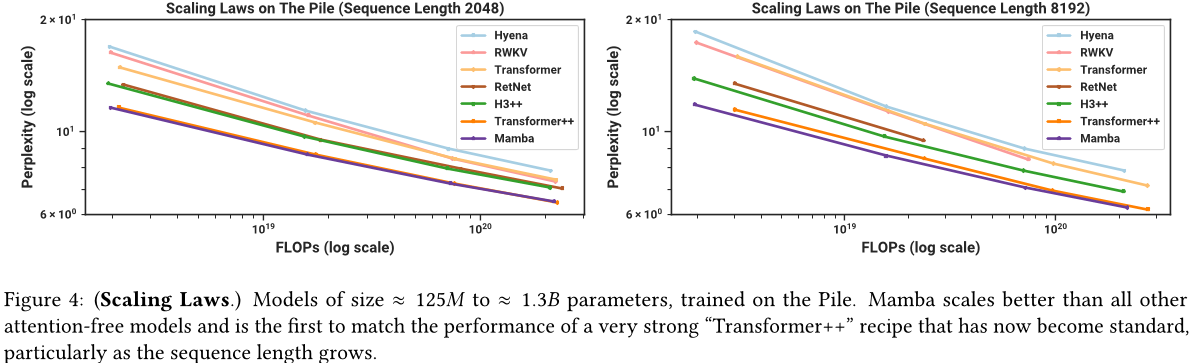
为了基准,我们比较了标准的变压器架构(GPT-3 架构)以及我们所知道的最强大的变压器食谱(这里称为变压器++),基于 PaLM 和 LLaMA 架构(例如旋转嵌入、SwiGLU MLP、RMSNorm 而不是层归一化、没有线性偏差以及更高的学习率)。我们还与其他最近的次二次架构进行了比较(图 4)。所有模型细节都在附录 E.2 中。
图 4 展示了在标准 Chinchilla(Hoffmann 等,2022 年)协议下,从约 1.25 亿到约 13 亿个参数的模型中的扩展规律。Mamba 是第一个不使用注意力机制的模型,其性能与现在已经成为标准的非常强大的 Transformer 模型(Transformer ++)相匹配,尤其是当序列长度增加时。(需要注意的是,由于缺乏有效的实现导致内存不足或计算需求不切实际,无法获得 RWKV 和 RetNet 基准以及此前的强循环模型(也可视为 SSM)在上下文长度为 8K 的完整结果。)
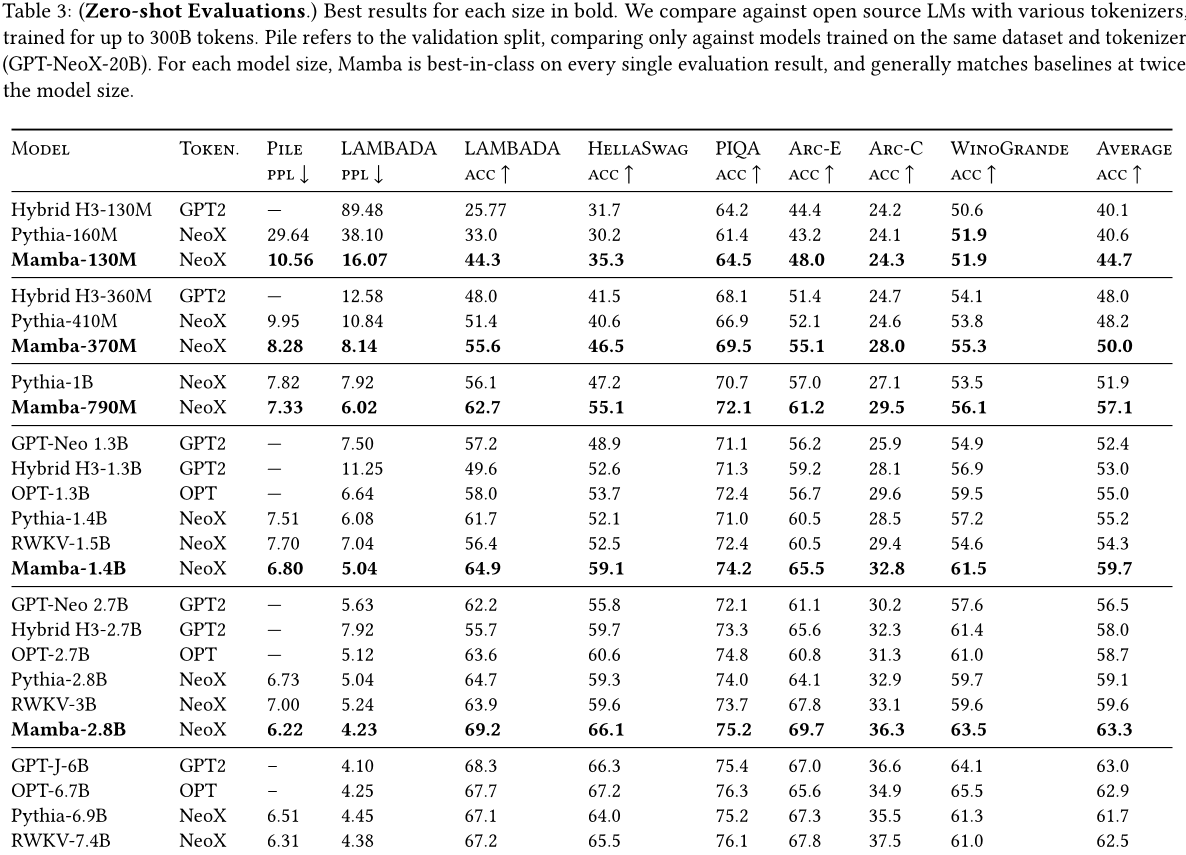
4.2.2 下游评估
表3显示了Mamba在一系列流行的下游零样本评估任务中的性能。我们与这些规模上最知名的开源模型进行了比较,最重要的是Pythia(Biderman等人,2023年)和RWKV(Peng等人,2023年),它们使用与我们的模型相同的分词器、数据集和训练长度(300B个标记)。注意,Mamba和Pythia使用上下文长度为2048进行训练,而RWKV使用上下文长度为1024进行训练。
4.3 DNA 模型
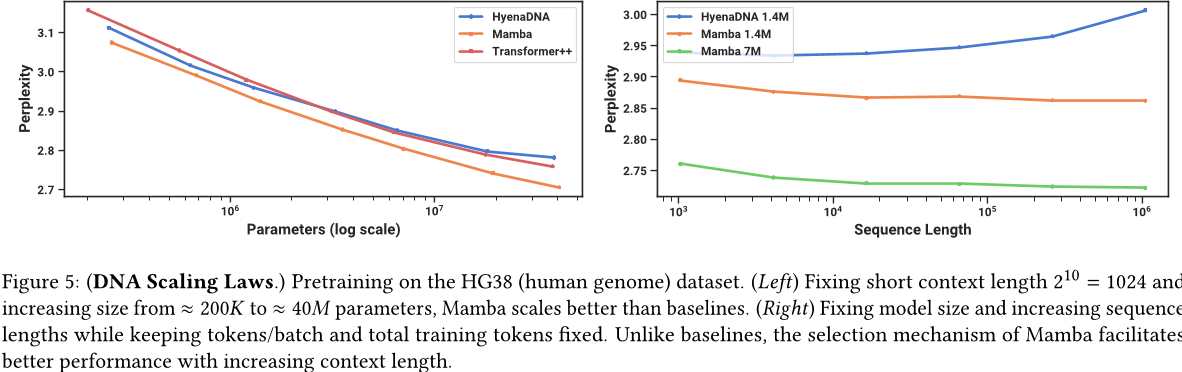
受大型语言模型成功推动,最近对使用基础模型范式进行基因组学的研究。DNA 被比作语言,因为它由有限词汇表中的离散标记序列组成。它还以需要长程依赖来建模而闻名(Avsec等人,2021)。我们研究了 Mamba 作为 FM 的预训练和微调的基础,在与最近关于 DNA 长序列模型的工作相同的设置中(Nguyen、Poli 等人,2023 年)。具体而言,我们关注两个探索跨越模型大小和序列长度的规模法则(图 5),以及一个下游困难合成分类任务,该任务要求长时间上下文(图 6)。
在预训练阶段,我们主要遵循了标准因果语言建模(下一个标记预测)设置来训练模型,并在附录E.2中提供了详细的模型细节。对于数据集,我们主要遵循了HyenaDNA (Nguyen, Poli等人,2023) 的设置,使用包含大约45亿个token(DNA碱基对)的人类基因组单体进行预训练。
人类基因组(HG38)上的尺度法则
缩放定律-序列长度(hg38)
4.3.1 伸缩性:模型大小
在这个实验中,我们研究了具有不同模型骨干的各种基因组基础模型的缩放特性(图5左)。
训练。为了优化基线,我们在序列长度为 1024 的情况下进行训练;如第 4.3.2 节所示,我们预计在较长的序列长度下结果会更有利于蟒蛇。我们固定全局批大小为 1024,每批总共有 220 ≈ 1M 个标记。模型总共进行了 10K 步梯度更新,处理了总共 10B 个标记。
结果。图 5 (左) 表明,Mamba 的预训练困惑度随着模型大小而平滑地提高,并且 Mamba 比 HyenaDNA 和 Transformer++ 更容易扩展。例如,在大约 40M 参数的最大模型大小处,曲线表明,Mamba 可以用比 Transformer++ 和 HyenaDNA 模型少约 3 到 4 倍的参数来匹配它们。
4.3.2 缩放:上下文长度
在接下来的 DNA 实验中,我们研究了模型序列长度方面的伸缩性。由于二次关注成本高昂,因此我们仅比较了HyenaDNA 和 Mamba 模型。我们在 210=1024、212=4096、214=16384、216=65536、218=262144 和 220=1048576 的序列长度上预训练模型。我们固定了一个大小为 6 层、宽度为 128(约 1.3M-1.4M 参数)的模型。总共训练了 20k 步梯度,使用了大约 330B 个标记。使用类似于 Nguyen、Poli 等人的方法进行序列长度温升。
结果。图 5 (右) 表明,蟒蛇能够利用更长的上下文,甚至可以处理长度为 1M 的非常长的序列,其预训练困惑度随着上下文的增加而提高。另一方面,HyenaDNA 模型在序列长度方面表现不佳。这可以从第 3.5 节关于选择机制属性的讨论中直观地看出。特别是,LTI 模型不能选择性地忽略信息;从卷积的角度来看,一个非常长的卷积核正在聚合整个长序列中的所有信息,这可能非常嘈杂。需要注意的是,虽然 HyenaDNA 声称其在较长的上下文环境中表现更好,但他们的实验没有控制计算时间。
4.3.3 合成物种分类
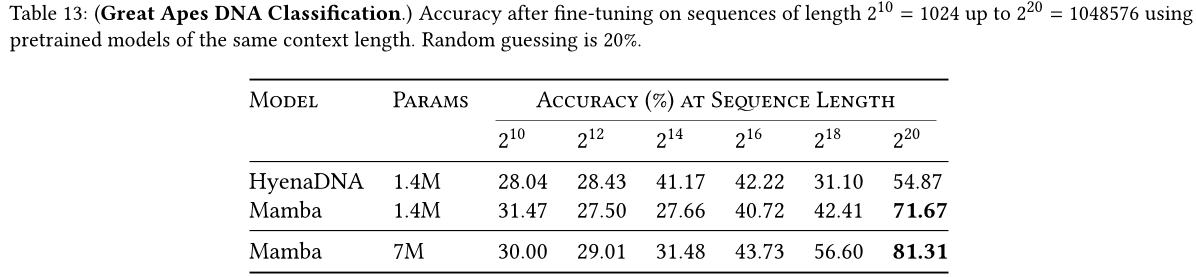
我们通过随机采样 DNA 序列的一个连续片段,对模型进行评估,以在下游任务中区分五个不同的物种。这项任务改编自 HyenaDNA,其使用的物种包括:人类、狐猴、老鼠、猪和河马。为了使任务更具挑战性,我们将任务修改为在五种类人猿(人类、黑猩猩、大猩猩、红毛猩猩和倭黑猩猩)之间分类,这五种物种共享 99% 的 DNA。
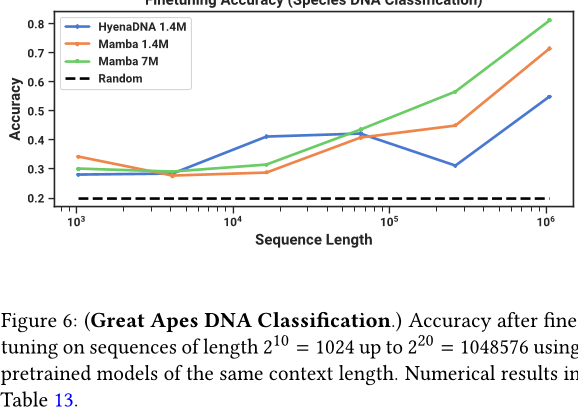
图6:大猩猩DNA分类。(使用具有相同上下文长度的预训练模型,在序列长度为210 = 1024到220 = 1,048,576之间进行微调)。表13中的数字结果。
4.4 音频建模与生成
对于音频波形模态,我们主要与 SaShiMi 架构及其训练协议进行比较(Goel et al. 2022)。该模型包括:
- 一个带有两个阶段池化,每个阶段池化因子为p,使模型维度D翻倍的U-Net骨干,
- 每个阶段交替使用S4和MLP块。
我们考虑用 Mamba 块替换 S4+MLP 块。实验细节在附录 E.4 中。
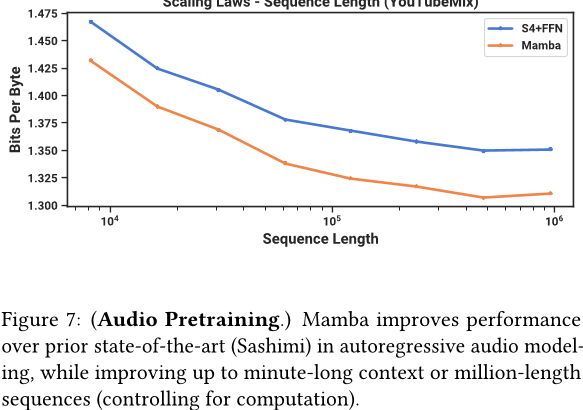
4.4.1 长距离上下文自回归预训练
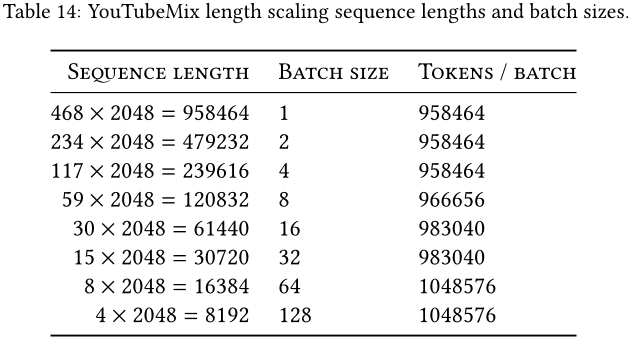
我们在 YouTubeMix(DeepSound 2017)上评估了预训练质量(自回归下一个样本预测),这是一个包含 4 小时独奏钢琴音乐的标准钢琴音乐数据集,采样率为 16kHz。预训练细节遵循标准语言建模设置(见第 4.2 节)。图 7 评估了从 2^13 = 8192 到 2^20 ≈ 106 增加训练序列长度的效果,同时保持计算量不变。(对数据进行编目的方式存在一些细微的边缘情况,可能会导致缩放曲线上的不连续性。例如,只有几分钟长的片段可用,因此最大序列长度实际上受限制为 60s · 16000Hz = 960000 。)
Mamba 和 SaShiMi (S4+MLP) 基线随着语境长度的增加而不断改善;在所有情况下,Mamba 都比 SaShiMi 更好,并且在较长的长度下差距更大。主要度量标准是每字节比特数(BPS),它是预训练其他模态的标准负对数似然损失的常数因子的以 2 为底的对数。
我们注意到一个重要的细节:这是我们在这篇论文中唯一一次从实参数化切换到复数参数化(见第 3.6 节)。我们在附录 E.4 中展示了额外的删除实验。
4.4.2 自回归语音生成
SC09 是一个基准语音生成数据集(Donahue,McAuley 和 Puckette,2019;Warden,2018),由采样频率为每秒 16000 次的数字"零"到"九"的音频片段组成,具有高度可变的特征。我们主要遵循了 Goel 等人(2022)的自回归训练设置和生成协议。
表 4 展示了来自戈尔等人。 (2022): WaveNet(Orde 等人,2016 年),SampleRNN(Mehri 等人,2017 年),WaveGAN(Donahue、McAuley 和 Puckette,2019 年),DiffWave(Z. Kong 等人,2021 年)和 SaShiMi 的各种基线与 Mamba-UNet 模型之间的自动度量:一个小的 Mamba 模型优于最先进的(并且大得多)生成对抗网络和扩散模型。一个参数匹配基准的更大模型在保真度指标上取得了显著的改进。
表5 将小Mamba模型与不同架构的不同阶段和中心阶段进行组合。它表明,在外层块中,Mamba始终优于S4+MLP,在中心块中,Mamba> S4+MLP>MHA+MLP。
表4:(SC09) 对于一个具有挑战性的固定长度语音片段数据集上的无条件生成的自动度量。(从上到下) 自回归基线,非自回归基线,Mamba 和数据集指标。
表5:(SC09模型修剪)参数为6M的模型。在SaShiMi的U-Net骨干中,有8个中心块处理序列长度为1000,在每个侧面由8个外侧块夹住,这些外侧块以序列长度为4000进行处理,并且被8个序列长度为16000的外侧块夹住(总共40个块)。中心块的架构与其余部分独立修剪。注意由于效率限制,未在更重要的外部块中测试Transformers (MHA+MLP)。
4.5 速度与内存基准测试
我们在图8中比较了SSM扫描操作(状态扩展N = 16)的速度,以及Mamba端到端推理吞吐量。 我们高效的SSM扫描在序列长度超过2k时比我们所知道的最佳注意力实现(FlashAttention-2(Dao 2024))快,并且比PyTorch中的标准扫描实现快20-40倍。 Mamba的推理吞吐量比类似大小的Transformer高出4-5倍,因为它可以使用更高的批处理大小而无需KV缓存。例如,未经训练的Mamba-6.9B的推理吞吐量高于小5倍的Transformer-1.3B。详细信息请参见附录E.5,其中包括对内存消耗基准测试。
扫描 vs 卷积 vs 注意力时间(A100 80GB PCle) 在 A100 80GB 上的推断吞吐量(提示长度为 2048)
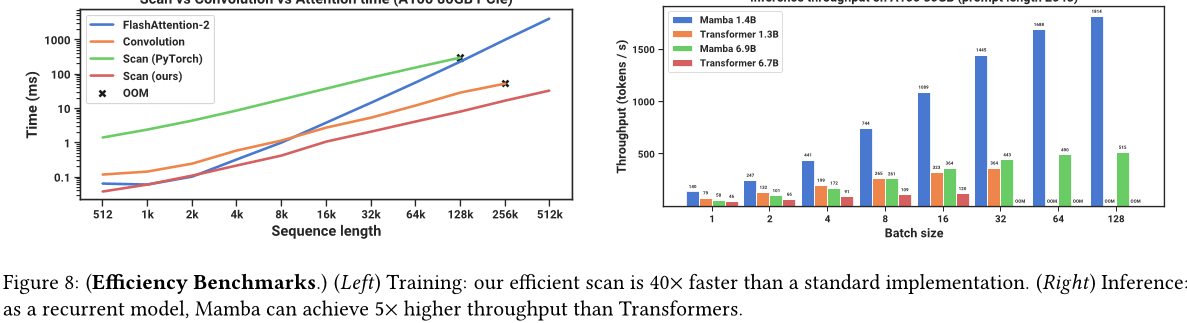
图8:(效率基准。左)训练:我们的高效扫描比标准实现快40倍。(右)推理:作为一个递归模型,Mamba 的吞吐量比 Transformer 高5倍。
4.6 模型消融
我们在我们的模型组件上进行了一系列详细的修剪,重点放在了与第4张图相同的设置下使用大小约为3.5亿的模型进行语言建模。
4.6.1 架构
表6研究了体系结构(块)及其内部SSM层(图3)的影响。我们发现
• 在之前的非选择性(LTI)SSM中,这些等同于全局卷积,在性能上非常相似。
• 用实值代替先前工作的复数值S4变体对性能影响不大,这表明(至少对于语言模型),在考虑硬件效率时,实值隐马尔可夫模型可能是更好的选择。
• 将其中任何一项替换为选择性SSM(S6)显着提高了性能,验证了第3节的动机。

• Mamba 架构与 H3 架构表现相似(使用选择性层时,似乎略好)。
我们在附录E.2.2中还研究了如何在 Mamba 块和其他块(如MLP(传统架构)MHA(混合注意力架构)之间交替。
4.6.2 选择性 SSM
表7考虑了不同的选择性A、B和C参数组合(算法2),通过移除选择性SSM层来实现,这表明由于与RNN门控有关,A是最关键的参数(定理1)。
表8考虑了不同的 SSM 初始值,这些初始值在某些数据模态和设置中被证明有很大的不同(Gu、Goel 和 Ré, 2022;Gu、Gupta 等人., 2022)。在语言建模方面,我们发现更简单的实数对角线初始化(S4D-Real,第 3 行)比更标准的复数值参数化(S4D-Lin,第 1 行)表现得更好。随机初始化也表现良好,与之前的研究结果一致(Mehta et al.2023)。
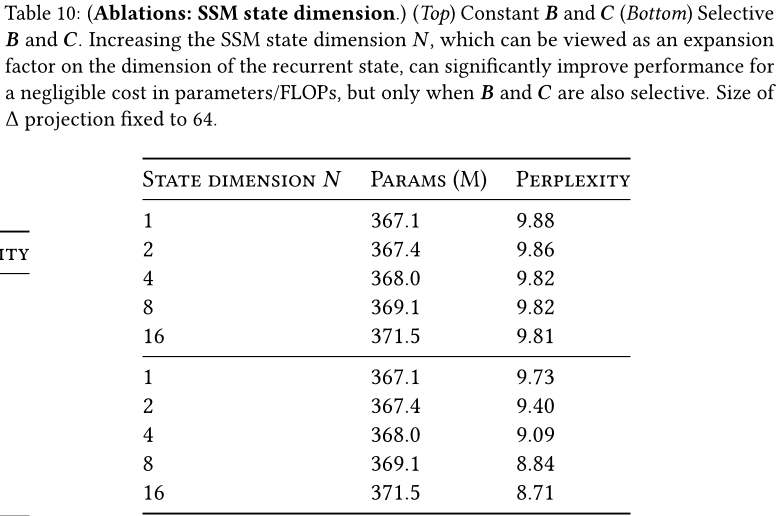
表9和表10分别考虑了A和(B,C)投影的维度变化。从静态到选择性进行更改可以带来最大的好处,而进一步增加维度通常会适度提高性能,并且参数数量的增加很小。
特别值得注意的是,当状态大小N增加时,选择性SSM 的显著改善,仅以额外1%的参数代价换取了超过1.0个困惑度的提高。这验证了我们在第3.1节和第3.3节中的核心动机。
5 讨论
我们讨论了相关工作、局限性和一些未来方向。
相关工作。附录A 讨论了选择机制与类似概念的关系。附录B 提供了对状态空间模型 (SSMs) 和其他相关模型的更深入讨论。
没有免费午餐:连续与离散光谱。 结构化时序模型最初被定义为连续系统(1)的离散化,并且对诸如感知信号(例如音频、视频)等连续时间数据模式具有很强的归纳偏见。 如第 3.1 和 3.5 节所述,选择机制克服了文本和 DNA 等离散模态上的缺点;但是这反过来可能会阻碍它们在 LTI 时序模型擅长的数据上的性能。 我们对音频波形进行的消融研究更详细地检查了这种权衡。
下游能力。基于变压器的基础模型(尤其是 LLM)具有丰富的与预训练模型交互的属性和模式,例如微调、适应、提示、上下文学习、指令调整、RLHF、量化等。我们特别感兴趣的是,像 SSM 这样的变压器替代品是否具有类似的性质和功能。
缩放。我们的经验评估仅限于小模型大小,低于大多数强大的开源语言模型(例如Llama (Touvron等人,2023年))以及诸如RWKV (B.Peng等人,2023年) 和RetNet (Y.Sun等人,2023年)等其他递归模型的阈值,这些模型已在70亿参数规模及更大范围内进行了评估。我们仍需要评估Mamba在这些较大尺寸下是否仍然具有优势。我们还指出,扩展SSMs可能涉及进一步的工程挑战和未在此论文中讨论的对模型的调整。
6 结论
我们为结构化状态空间模型引入了一种选择机制,使其能够在序列长度线性扩展的情况下执行上下文相关的推理。当集成到一个简单的无注意力架构中时,Mamba 在各种领域取得了最先进的结果,在这些领域它与或超过了强大的变压器模型的性能。我们对选择性状态空间模型在不同领域的基础模型中的广泛应用感到兴奋,特别是在需要长上下文的新兴模态(如基因组学、音频和视频)中。我们的结果表明,Mamba 是一种通用序列模型骨干的强大候选者。
鸣谢
我们感谢Karan Goel、Arjun Desai 和 Kush Bhatia 对草稿提出的宝贵反馈。
参考文献
Martin Arjovsky、Amar Shah 和 Yoshua Bengio。《单向演化递归神经网络》。在:国际机器学习会议 (ICML)。2016 年,第 1120-1128 页。
齐加·阿夫塞克,维克拉姆·阿加瓦尔,丹尼尔·维森廷,约瑟夫·R·莱德萨姆,阿格涅什卡·格拉布斯卡-巴温斯卡,凯尔·R·泰勒,扬尼斯·阿萨伊,约翰·朱珀,普梅特·科尔希和大卫·R·凯利。《通过整合长程相互作用从序列中有效预测基因表达》。在:Nature Methods 18.10 (2021 年) 第 10 页,第 1196-1203 页。
Jimmy Ba, Geoffrey E Hinton, Volodymyr Mnih, Joel Z Leibo 和 Catalin Ionescu。《使用快速权重来关注近期过去》。《神经信息处理系统会议(NeurIPS)》第29卷(2016年)。
吉米·雷·巴,杰米·瑞恩·柯罗斯和杰弗里·E·辛顿。《 层归一化》。arXiv e-print arXiv:1607.06450 (2016 年)。
Dzmitry Bahdanau,Kyunghyun Cho 和 Yoshua Bengio。《通过联合学习对齐和翻译的神经机器翻译》。在:国际学习表示会议 (ICLR)。2015 年。
David Balduzzi 和 Muhammad Ghifary。《强类型递归神经网络》。在:国际机器学习会议,PMLR,2016 年,第 1292 至 1300 页。
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O'Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, EdwardRaff 等。《Pythia:用于训练和扩展分析大型语言模型的工具包》。在国际机器学习会议 (ICML) 上发表。PMLR,2023 年,第 2397-2430 页。
Yonatan Bisk,Rowan Zellers,Jianfeng Gao,Yejin Choi 等人。《PIQA:自然语言中关于物理常识的推理》。在第34届人工智能协会会议上发表论文。2020年。
9 西德·布莱克,斯特拉·比德曼,埃里克·霍尔汉恩,昆廷·安东尼,雷奥·高,劳伦斯·戈尔丁,霍勒斯·何,康纳·莱利,凯尔·麦当劳,杰森·方格等。《GPT-NeoX-20B:一种开源自回归语言模型》。arXiv预印本arXiv:2204.06745(2022)。
10盖伊·E·布雷洛奇(Guy E. Blelloch)。"前缀求和及其应用"。在:(1990年)。
11 詹姆斯·布拉德伯里、斯蒂芬·默里提、蔡明雄、理查德·索彻。《准循环神经网络》。收录于:arXiv preprint arXiv:1611.01576 (2016)。
汤姆·布朗,本杰明·曼恩,尼克·莱德,梅勒妮·苏比亚,贾里德·卡普兰,普拉尔·达尔瓦尔,阿林德·尼拉坎塔南,普拉纳夫·希亚姆,吉里许·萨斯特里,阿曼达·阿斯克尔等人。《语言模型是少量样本学习者》。在:神经信息处理系统会议(NeurIPS)第33卷(2020),第1877-1901页。
Aydar Bulatov,Yuri Kuratov 和 Mikhail S Burtsev。《使用自适应学习率方法训练 1M 个标记及更多》。arXiv e-print arXiv:2304.11062 (2023 年)。
Rewon Child、Scott Gray、Alec Radford 和 Ilya Sutskever。《使用稀疏变压器生成长序列》。arXiv eprint arXiv:1904.10509 (2019 年)。
Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiudddin, Lukasz Kaiser 等人。《使用表演者重新思考注意力》。在:国际学习表示大会 (ICLR)。2021 年。
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann 等。《PaLM:使用通路扩展语言建模》。在《机器学习研究杂志》第 24 卷,第 240 页(2023 年),第 1-113 页。网址:http://jmlr.org/papers/v24/22-1144.html。
17 钟俊荣,Caglar Gulcehre,KyungHyun Cho 和 Yoshua Bengio。《门控循环神经网络在序列建模中的经验评估》。arXiv预印本,arXiv:1412.3555(2014 年)。
彼得·克拉克,艾萨克·考伊,奥伦·埃齐蒂,图沙尔·科特,阿希什·萨巴哈尔,卡丽莎·肖尼克和奥韦因德·塔夫约德。"您认为自己已经解决了问答问题吗?尝试ARC,AI2推理挑战"。在:arXiv预印本arXiv:1803.05457(2018)。
19 《Tri Dao. "FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning"。在:国际学习表征会议(ICLR)。2024。
Tri Dao,Daniel Y. Fu,Stefano Ermon,Atri Rudra 和 Christopher Ré。《FlashAttention:一种具有 I/O 意识的快速且内存效率高的精确注意力》。在:神经信息处理系统会议(NeurIPS)论文集,2022 年。
21 丁道,Daniel Y Fu,Khaled K Saab,Armin W Thomas,Atri Rudra 和 Christopher Ré。《饥饿的饥饿河马:使用状态空间模型进行语言建模》。在:国际学习表示会议(ICLR)。2023。
Yann N Dauphin,Angela Fan,Michael Auli 和David Grangier。《带门控卷积网络的语言建模》。在:国际机器学习会议(ICML)。PMLR。2017 年,第 933-941 页。
23 DeepSound. SampleRNN. https://github.com/deepsound-project/samplernn-pytorch. 2017年。
24 荣宇丁,马书明,董立东,张兴星,黄绍涵,王文辉,魏福如。《长网:将 Transformer 扩展到十亿个标记》。arXiv 预印本,arXiv:2307.02486(2023 年)。
25 克里斯·唐纳修、朱利安·麦考莱和米勒·帕克特,《对抗式音频合成》,在国际学习表示会议(ICLR)上,2019年。
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold 和 Sylvain Gelly 等人。《一张图片价值 16 x 16 个单词:大规模图像识别中的 Transformer》。在国际学习表示会议 (ICLR) 上发表于 2020 年。
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, 深 Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish 和 Chris Olah。"基于变压器电路的数学框架"。在:变压器电路论坛(2021)。https://transformer-circuits.pub/2021/framework/index.html。
Mahan Fathi、Jonathan Pilault、Pierre-Luc Bacon、Christopher Pal、Orhan Firat 和 Ross Goroshin。《块状状态转换器》。arXiv preprint arXiv:2306.09539 (2023)。
Yassir Fathullah, Chunyang Wu, Yuan Shangguan, Junteng Jia, Wenhan Xiong, Jay Mahadeokar, Chunxi Liu, Yangyang Shi, Ozlem Kalinli, Mike Selzter 和 Mark J. F. Gales。《用于语音识别的多头状态空间模型》。在:Proc. INTERSPEECH 2023。2023 年,第 241-245 页。DOI: 10.21437/Interspeech.2023-1036。
卡尔·J·弗里斯顿、李·哈里森和威尔·彭尼。《动态因果模型》。发表于:神经影像学杂志,卷19,第4期(2003),页码为1273至1302。
Daniel Y. Fu,Elliot L. Epstein,Eric Nguyen,Armin W. Thomas,Michael Zhang,Tri Dao,Atri Rudra 和 Christopher Ré。《针对序列建模的简单高效硬件卷积》。在:国际机器学习会议(ICML)(2023)。
32 越智 賢一,中村 優一。《连续时间递归神经网络对动力系统近似》。《神经网络》,第6卷,第6期(1993年),第801-806页。
高磊,比德曼斯特拉,布莱克西德,戈尔丁特拉斯,霍普,福斯特查尔斯,方杰森,赫,蒂特安尼什,纳贝希马诺亚,普雷斯肖恩,莱利康纳。"Pile:一个用于语言建模的 800GB 多样化文本数据集"。arXiv 预印本。arXiv:2101.00027(2020 年)。
高磊,托尼·陶,斯特拉·比德曼,西德·布莱克,安东尼·迪波菲,查尔斯·福斯特,劳伦斯·戈尔丁,杰弗里·许,凯尔文·麦当纳,尼克拉斯·穆恩尼霍夫,杰森·方格,阿拉娜·雷诺兹,埃里克·唐,阿尼什·蒂特,本·王,凯文·王,安迪·邹。用于少量样本语言模型评估的框架。版本v0.0.1。2021年9月。DOI:10.5281 / zenodo.5371628。URL:https://doi.org / 10.5281 / zenodo.5371628。
Karan Goel、Albert Gu、Chris Donahue 和 Christopher Ré。《使用状态空间模型进行音频生成》。在:国际机器学习会议(ICML)上。2022 年。
36 阿尔伯特·古、Tri Dao、斯蒂法诺·埃尔蒙、阿特里·鲁德拉和克里斯托弗·雷。《HIPPO:具有最优多项式投影的递归记忆》。在神经信息处理系统会议(NeurIPS)上。2020年。
37 阿尔伯特·古、卡兰·戈埃尔和克里斯托弗·勒。《高效建模具有结构化状态空间的长序列》。在:国际学习表示会议(ICLR)。2022年。
38 阿尔伯特·古,Caglar Gulcehre,汤姆·勒佩恩,马特·霍夫曼和Razvan Pascanu。《改进循环神经网络的门控机制》。在:国际机器学习会议(ICML)。2020年。
Albert Gu、Ankit Gupta、Karan Goel 和 Christopher Ré。《关于对角状态空间模型参数化与初始化》。在:神经信息处理系统会议 (NeurIPS)。2022 年。
Albert Gu, Isys Johnson, Karan Goel, Khaled Saab, Tri Dao, Atri Rudra 和 Christopher Ré。《结合递归、卷积和连续时间模型与线性状态空间层》。在:神经信息处理系统会议 (NeurIPS) 2021年会议论文集中。
Albert Gu, Isys Johnson, Aman Timalsina, Atri Rudra 和 Christopher Ré。《如何训练你的HIPPO:带有广义基投影的状态空间模型》。在国际学习表示会议 (ICLR) 上,2023 年。
Ankit Gupta, Albert Gu 和 Jonathan Berant。《对角状态空间与结构化状态空间一样有效》。在:神经信息处理系统会议论文集,第 35 卷(2022 年),第 22982-22994 页。
Ankit Gupta, Harsh Mehta 和 Jonathan Berant。《使用带偏移线性递归神经网络简化和理解状态空间模型》。arXiv:2212.00768 cs.LG, 2022 年 12 月 5 日。
David Ha、Andrew Dai 和 Quoc V. Le。《超网络》。在:国际学习表示会议 (ICLR) 上。2017 年。
Danijar Hafner、Timothy Lillicrap、Jimmy Ba 和 Mohammad Norouzi。《Dream to Control: Learning Behaviors by Latent Imagination》。在:国际学习表示会议 (ICLR) 上。2020 年。
Ramin Hasani、Mathias Lechner、Tsun-Hsuan Wang、Makram Chahine、Alexander Amini 和 Daniela Rus。《流体结构状态空间模型》。在:国际学习表示会议 (ICLR) 2023 年。
Mikael Henaff、Arthur Szlam 和Yann LeCun。《循环正交网络与长记忆任务》。在国际机器学习会议(ICML)上,2016 年。
Dan Hendrycks 和 Kevin Gimpel。《高斯误差线性单元 (GELUs)》。在:arXiv 预印本,卷 1606.08415(2016 年)。
49 Sepp Hochreiter. "对动态神经网络的研究". 在: 学位论文,慕尼黑工业大学,第91卷,第1期(1991),第31页。
50 Sepp Hochreiter, Yoshua Bengio, Paolo Frasconi, Jürgen Schmidhuber 等人。 循环网络中的梯度流:学习长期依赖性的困难性。 2001 年。
51 Sepp Hochreiter 和 Jurgen Schmidhuber。《长短期记忆》。神经计算,卷9,第8期(1997 年),1735-1780 页。
52 琼达·霍夫曼,塞巴斯蒂安·博尔盖德,亚瑟·门什,埃琳娜·布恰茨卡娅,特雷弗·蔡,伊丽莎白·拉瑟福,迭戈·德拉斯·卡萨斯,莉莎·安妮·亨德里克斯,约翰内斯·韦尔布,艾丹·克拉克等人。《计算最优的大语言模型训练:实证分析》。在:神经信息处理系统会议(NeurIPS)第35卷(2022 年),第30016-30030页。
Weizhe Hua,Zihang Dai,Hanxiao Liu 和 Quoc Le。《在常数时间内实现的变压器质量》。在国际机器学习会议(ICML)上。PMLR。2022 年,第 9099-9117 页。
哈桑·伊斯梅尔·法瓦兹、杰勒德·福雷斯特、乔纳森·韦伯、拉赫萨尼·伊杜姆加和皮埃尔-阿兰·穆勒。《时间序列分类的深度学习:综述》。《数据挖掘与知识发现》,第33卷,第4期(2019 年),第917-963页。
Andrei Ivanov、Nikoli Dryden、Tal Ben-Nun、Shigang Li 和 Torsten Hoefler。《数据移动就是你需要的一切:优化变压器案例研究》。机器学习与系统会议论文集,第3卷(2021 年),第 711-732 页。
李静,Caglar Gulcehre,John Peurifoy,Yichen Shen,Max Tegmark,Marin Soljacic 和 Yoshua Bengio。《门控正交循环单元:学习遗忘》。《神经计算》,第31卷,第4期(2019 年),第 765-783 页。
鲁道夫·埃米尔·卡尔曼。《线性滤波和预测问题的新方法》。(1960)。
58 安杰洛斯·卡塔罗普洛斯,阿波尔维·维亚斯,尼科拉奥斯·帕帕斯和弗朗索瓦·弗勒特。《变压器是循环神经网络:具有线性注意力的快速自回归变压器》。在国际机器学习会议上。 PMLR。 2020 年,第 5156-5165 页。
Shiva Kaul。《线性动力学系统作为核心计算基本元素》。在:神经信息处理系统会议论文集,第33卷(2020 年),第 16808-16820 页。
孔志峰,魏平,黄家吉,赵克新,布莱恩·卡塔纳佐。《DiffWave:一种适用于音频合成的通用扩散模型》。在国际学习表示会议(International Conference on Learning Representations)上,2021年。
Chrysoula Kosma、Giannis Nikolentzos 和 Michalis Vazirgiannis。《针对不规则采样时间序列的时间参数化卷积神经网络》。arXiv eprint arXiv:2308.03210 (2023 年)。
62 Alex Krizhevsky, Ilya Sutskever 和 Geoffrey E Hinton。《使用深度卷积神经网络进行 ImageNet 分类》。出自:Advances in Neural Information Processing Systems (NIPS) 25(2012)。
陶磊。《当注意力遇到快速递归:降低计算量的语言模型训练》。在:2021年自然语言处理实验方法会议论文集,2021年,第7633-7648页。
陶雷,于章,石达伊万,戴慧,约阿夫·阿尔茨。《用于高度并行化的递归的简单循环单元》。arXiv预印本:arXiv:1709.02755(2017年)。
马里奥·莱扎诺 - 卡萨多 (Mario Lezcano-Casado) 和大卫·马丁内斯 - 瑞博 (David Martínez-Rubio)。《神经网络中的廉价正交约束:正交群和酉群的简单参数化》。国际机器学习会议(ICML)。2019年。
李玉红、蔡天乐、张逸、陈德明、Debadeepta Dey。《什么让卷积模型在长序列建模中表现得如此出色?》发表于:国际学习表示会议(ICLR)。2023 年。
67 Vasileios Lioutas 和 Yuhong Guo。《时间感知的大核卷积》。在:国际机器学习会议(ICML)。PMLR。2020 年,第 6172-6183 页。
克里斯·卢、扬尼克·舒洛克、阿尔伯特·古、埃米利奥·帕里斯托、雅各布·福尔斯特、萨蒂德·辛格和费里亚尔·贝哈巴尼。《结构化状态空间模型用于上下文强化学习》。发表于:神经信息处理系统会议(NeurIPS)2023年。
沙哈尔·鲁塔蒂、伊塔玛尔·齐默曼和利亚尔·沃尔夫。《集中注意力(带自适应IIR滤波器)》。在:arXiv 预印本,卷 arXiv:2305.14952(2023)。
70 马雪哲,周纯亭,孔翔,何俊贤,桂良科,格雷厄姆·纽比,乔纳森·梅,卢克·泽特勒摩尔。" Mega:带移动平均值的门控注意力"。在国际学习表示年会 (ICLR)。2023。
71 埃里克·马丁 和 克里斯·康迪。《并行化线性递归神经网络》。在:国际学习表示会议(ICLR)。2018年。
Soroush Mehri,Kundan Kumar,Ishaan Gulrajani,Rithesh Kumar,Shubham Jain,Jose Sotelo,Aaron Courville 和 Yoshua Bengio。《SampleRNN:一个无条件端到端神经音频生成模型》。在国际学习表示会议 (ICLR) 上发表于 2017 年。
哈什·梅赫塔、安尼克特·古普塔、阿肖克·库尔科斯基和贝赫纳姆·内希巴鲁。《通过门控状态空间进行长程语言建模》。在:国际学习表示会议(ICLR)。2023年。
扎卡里亚·M·哈迈德米,安德鲁·赫利卡尔,阿什法克·拉赫曼和詹姆斯·贝利。《使用Householder反射高效正交参数化递归神经网络》。在:国际机器学习会议。PMLR。2017年,第2401-2409页。
Eric Nguyen, Karan Goel, Albert Gu, Gordon Downs, Preey Shah, Tri Dao, Stephen Baccus 和 Christopher Ré。《S4ND:使用状态空间建模图像和视频为多维信号》。在《神经信息处理系统会议(NeurIPS)》上发表于2022年。
76 Eric Nguyen,Michael Poli,Marjan Faizi,Armin Thomas,Callum Birch-Sykes,Michael Wornow,Aman Patel,Clayton Rabideau,Stefano Massaroli,Yoshua Bengio 等。《HyenaDNA:单核苷酸分辨率的长程基因组序列建模》。在《神经信息处理系统会议(NeurIPS)》上发表于2023年。
Catherine Olsson、Nelson Elhage、Neel Nanda、Nicholas Joseph、Nova DasSarma、Tom Henighan、Ben Mann、Amanda Askell、Yuntao Bai、Anna Chen、Tom Conerly、Dawn Drain、Deep Ganguli、Zac Hatfield-Dodds、Danny Hernandez、Scott Johnston、Andy Jones、Jackson Kernion、Liane Lovitt、Kamal Ndousse、Dario Amodei、Tom Brown、Jack Clark、Jared Kaplan、Sam McCandlish 和 Chris Olah。"在上下文中学习和归纳头"。在:Transformer电路线程(2022)。https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html。
Aaron van den Oord,Sander Dieleman,Heiga Zen,Karen Simonyan,Oriol Vinyals,Alex Graves,Nal Kalchbrenner,Andrew Senior 和 Koray Kavukcuoglu。《WaveNet:Raw Audio 的生成模型》。arXiv e-print arXiv:1609.03499 (2016 年)。
79 安东尼奥·奥尔维耶托、塞缪尔·L·史密斯、阿尔伯特·古、阿努山·范德、卡格拉尔·古尔切赫雷、拉兹万·帕斯坎乌和苏哈姆·德。"复活 循环神经网络 来处理长序列"。 在:国际机器学习会议 (ICML)。 2023 年。
Denis Paperno、Germán Kruszewski、Angeliki Lazaridou、Ngọc Quan Pham、Raffaella Bernardi、Sandro Pezzelle、Marco Baroni、Gemma Boleda 和 Raquel Fernández。《LAMBADA 数据集:需要广泛话语背景的单词预测》。在:第 54 届计算语言学协会年会论文集中。2016 年,第 1525-1534 页。
Razvan Pascanu,Tomas Mikolov 和 Yoshua Bengio。《关于训练递归神经网络的困难》。在:国际机器学习会议论文集中。2013 年,第 1310-1318 页。
82 鲍鹏,埃里克·阿尔凯德,昆廷·安东尼,阿隆·阿尔巴拉克,塞缪尔·阿拉西迪诺,胡安基·曹,辛成,迈克尔·钟,马泰奥·格雷拉,克兰蒂·吉兰·g v,等。《rwkv:为变压器时代重塑循环神经网络》。在arXiv预印本上。arXiv:2305.13048(2023)。
Hao Peng, Nikolaos Pappas, Dani Yogatama, Roy Schwartz, Noah A Smith 和 Lingpeng Kong。《随机特征注意力》。在:国际学习表示会议 (ICLR)。2021 年。
Michael Poli, Stefano Massaroli, Eric Nguyen, Daniel Y Fu, Tri Dao, Stephen Baccus, Yoshua Bengio, Stefano Ermon 和 Christopher Ré。《猎豹分层:向更大卷积语言模型发展》。在:国际机器学习会议 (ICML) 上。2023 年。
85 陈真秦,韩小东,孙维轩,何 Bowen,李东,李冬雪,戴玉超,孔令鹏,钟怡然。《序列建模中的 Toeplitz 神经网络》。在:国际学习表示会议 (ICLR)。2023 年。
真秦,肖东韩,韦宣孙,东旭李,凌鹏孔,尼克·巴恩斯和伊兰钟。"线性变换器中的恶魔"。 在:arXiv 预印本 arXiv:2210.10340(2022)。
87 郑钦,孙维轩,邓辉,李东旭,魏云森,吕宝红,严俊杰,孔令鹏,钟以冉。《CosFormer:重新思考注意力中的Softmax》。在国际学习表示会议 (ICLR) 上发表于 2022 年。
88 阿里·拉赫米和本杰明·雷希特。《大规模核方法的随机特征》。在神经信息处理系统会议(NeurIPS)20(2007)。
Prajit Ramachandran、Barret Zoph 和 Quoc V Le。《Swish:一种自适应激活函数》。arXiv preprint arXiv:1710.05941 (2017) ,第 7 部分,第 5 页。
David W. Romero、Anna Kuzina、Erik J. Bekkers、Jakub M. Tomczak 和 Mark Hoogendoorn。《CKConv:用于序列数据的连续核卷积》。arXiv preprint arXiv:2102.02611 (2021 年)。
91 桑原 敬,勒布拉斯 罗兰,昌达 巴格瓦塔拉,崔叶静。《"Winogrande:大规模的对抗性Winograd Schema挑战"》。《通讯》第64卷。9(2021 年),第99 - 106 页。
George Saon,Ankit Gupta 和 Xiaodong Cui。《对角状态空间增强变换器进行语音识别》。在:IEEE 国际音频、语音与信号处理会议 (ICASSP) 2023,第 1 至 5 页。
Imanol Schlag、Kazuki Irie 和 Jürgen Schmidhuber。《线性变换器秘密地快速权重编程》。在:国际机器学习会议(ICML)。PMLR,2021 年,第 9355-9366 页。
94 Jurgen Schmidhuber。"学习控制快速权重记忆:动态递归网络的一种替代方案。" 在:神经计算,卷. 4,第1期。(1992 年),第131 - 139页。
Noam Shazeer。《GLU变体改进了transformer》。arXiv预印本,arXiv:2002.05202(2020)。
弗雷达·石,辛云陈,卡尼什卡·米斯拉,内森·萨克斯,大卫·多汉,埃德·希·奇,纳撒尼尔·舍尔利 和丹尼·周。《大型语言模型可以很容易地被不相关的上下文分心》。在:国际机器学习会议(ICML)。PMLR。2023 年,第 31210-31227 页。
贾信石,凯·亚历山大·王,艾米丽·福克斯。"使用多分辨率卷积记忆进行序列建模"。在:国际机器学习会议(ICML)。PMLR。2023 年,第 31312-31327 页。
98 詹米·T·H·史密斯、安德鲁·沃灵顿和斯科特·W·林德曼。《用于序列建模的简化状态空间层》。在:国际学习表示会议(ICLR)。2023年。
孙建林,陆雨露,潘胜峰,穆尔塔达·艾哈迈德,文博,刘运丰。《RoFormer:带旋转位置嵌入的增强版变压器》。arXiv e-print arXiv:2104.09864(2021)。
孙玉涛,董丽,黄少涵,马顺明,夏宇清,薛吉龙,王建勇和魏福如。《保留网络:大型语言模型的变压器后继者》。arXiv预印本,arXiv:2307.08621(2023)。
101 Ilya Sutskever, Oriol Vinyals 和 Quoc V Le。《神经网络在序列到序列的学习》。收录于:《神经信息处理系统会议(NeurIPS)》第27卷(2014年)。
102 核心任务。科芒·塔勒克和雅恩·奥利维尔。"循环神经网络能否扭曲时间?"在:国际学习表示会议 (ICLR) 上。2018 年。
Yi Tay, Mostafa Dehghani, Samira Abnar, Yikang Shen, Dara Bahri, Philip Pham, Jinfeng Rao, Liu Yang, Sebastian Ruder 和 Donald Metzler. "长距离竞技场:一种有效变压器的基准." 在国际学习表示会议 (ICLR) 上。2021 年。
Yi Tay、Mostafa Dehghani、Dara Bahri 和 Donald Metzler。《高效变压器:综述》。《ACM 计算机调查》,卷 55,第 6 集(2022 年),第 1 至 28 页。
Hugo Touvron、Thibaut Lavril、Gautier Izacard、Xavier Martinet、Marie-Anne Lachaux、Timothée Lacroix、Baptiste Rozière、Naman Goyal、Eric Hambro 和 Faisal Azhar 等人。《llama:开放高效的基础语言模型》。arXiv eprint arXiv:2302.13971 (2023 年)。
Ashish Vaswani、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Llion Jones、Aidan N. Gomez、Lukasz Kaiser 和 Illia Polosukhin。《注意力就是一切》。在:神经信息处理系统会议(NeurIPS)论文集,2017 年。
Eugene Vorontsov、Chiheb Trabelsi、Samuel Kadoury 和 Chris Pal。《关于长时依赖关系下学习递归网络的正交性》。在:国际机器学习会议,PMLR 卷 70,2017 年,第 3570---3578 页。
108 决王,文涛朱,皮超王,向宇,琳达刘,穆罕默德·奥马尔,拉斐·哈米德。"选择性结构化状态空间用于长视频理解"。 在:计算机视觉和模式识别会议论文集。 2023 年,第 6387-6397 页。
109 彼得·沃登。《语音命令:用于有限词汇语音识别的数据集》。arXiv:1804.03209 cs.CL (2018年).
110塞缪尔·威廉姆斯,安德鲁·沃特曼,大卫·帕特森。《屋顶线:多核体系结构中直观的性能模型》。《通讯》,2009 年 4 月(卷 52,第 4 期),第 65-76 页。
111 布兰登杨、加布里埃尔·本德、Quoc V Le 和 Jiquan Ngiam。《条件参数化卷积:用于高效推理》。在神经信息处理系统会议 (NeurIPS) 32 上发表(2019 年)。
罗文·泽勒斯,阿里·霍尔茨曼,约坦·比克斯克,阿里·法哈迪和耶真·崔。《地狱狂潮:机器真的能完成你的句子吗?》在第57届计算语言学会年会论文集中。2019 年。
113双飞紫海,沃尔特·塔尔博特,尼蒂什·斯里瓦斯塔瓦,陈黄,韩林高,瑞祥张,乔希苏斯金德。"无需关注的变压器"。 在:arXiv 预印本 arXiv:2105.14103(2021 年)。
张迈克尔,Khaled K Saab,Michael Poli,Tri Dao,Karan Goel 和 Christopher Ré。《使用简单的离散状态空间有效建模时间序列》。在:国际学习表示会议(ICLR)。2023年。
林正、董旺和孔令鹏。《线性复杂度随机自注意力机制》。国际机器学习会议。PMLR。2022 年,第 27011-27041 页。
116 赛缪尔·左,刘小东,焦健,查尔斯·德尼,厄伦·马纳沃格鲁,赵图,高剑峰。《通过增强状态空间自回归转换器实现高效长序列建模》。arXiv 预印本,arXiv:2212.08136(2022 年)。
讨论:选择机制
我们的选择机制受到了门控、超网络和数据依赖等概念的启发。它也可以被看作与"快速权重"(Ba等人,2016年;Schmidhuber,1992年)有关,该方法将经典的循环神经网络与线性注意力机制(Schlag,Irie和Schmidhuber,2021)联系起来。然而,我们认为这是一个值得澄清的独特概念。
门控。 门控最初指的是RNN的门控机制,如长短期记忆(Hochreiter 和 Schmidhuber,1997)或门控循环单元(J. Chung等人,2014),或者定理1中的门控方程(5)。 这被解释为一种控制是否允许输入进入RNN隐藏状态的特殊机制。 特别地,这会影响信号随时间传播,并导致输入在序列长度维度上相互作用。
然而,自那以后,"门控"一词在流行用法中已经被放松,简单地指代任何具有乘性交互作用(通常带有激活函数)的概念。例如,神经网络架构中的逐元素乘积组件(不与序列长度进行交互),现在通常被称为门控架构(Hua等人,2022;Mehta等人,2023),尽管它们的含义与最初的RNN意义大不相同。因此,我们认为最初的RNN门控概念与流行的乘性门控概念实际上具有非常不同的语义含义。
超网络。超网络是指其参数本身由较小的神经网络生成的神经网络。最初的想法(Ha、Dai 和 Quoc V. Le,2017 年)狭义地将其定义为具有由较小的循环神经网络生成的循环参数的大循环神经网络,而其他变体已经存在了很长一段时间(Schmidhuber,1992 年)。
数据依赖性。与超网络类似,数据依赖性可以指模型的一些参数取决于数据(Poli等人,2023)。
GLU 激活。为了说明这些概念的问题,考虑一个简单的对角线线性层 y=Dx,其中 D 是一个对角权重参数。现在假设 D 本身是由一个可选非线性的线性变换产生的:D =σ(Wx)。由于它是对角阵,乘法就变成了逐元素乘法:y=σ(Wx)·x。
这是一个相当微不足道的转换,但技术上它满足了门控(因为它有一个乘法的"分支")、超网络(因为参数D由另一个层生成)和数据依赖性(因为D取决于x的数据)的常见含义。然而,这实际上只是定义了一个GLU函数,它非常简单,通常被认为只是一个激活函数(Dauphin等人,2017;Shazeer,2020),而不是一个有意义的层。
选择。因此,虽然选择机制可以被认为是架构门控、超网络或数据依赖等思想的一个特例,但也可以考虑范围广泛的其他结构------基本上任何具有乘法的东西,包括标准注意力机制(Bahdanau、Cho 和 Bengio 2015;Vaswani 等人。2017年)也是如此------我们发现将它们视为如此是没有信息量的。
相反,我们认为它最接近传统循环神经网络的门控机制,这是特殊情况(定理1),并且通过变量(输入依赖)离散化△与隐马尔可夫模型之间也有更深层的历史联系(Funahashi 和Nakamura 1993;Gu、Dao等人。2020;Tallec和Ollivier 2018)。我们还避免使用"门"的术语,而选择"选择",以澄清前者的过度使用。具体而言,我们用选择来指代模型选择或忽略输入并沿着序列长度促进数据交互的机制(第3.1节)。除了选择性隐马尔可夫模型和门控循环神经网络之外,其他例子可能包括输入相关的卷积(Kosma、Nikolentzos和Vazirgiannis 2023;Lioutas和Guo 2020;Lutati、Zimerman和Wolf 2023;Yang等人。2019年),甚至注意力。
相关工作
我们概述了与我们的方法相关的几篇论文。 我们提到一些最密切相关的模型包括带有循环层的S4、S5和准RNN;以及端到端架构H3、RetNet和RWKV。
B.1 S4 变异株和衍生株
我们简要描述了来自过去工作的某些结构化隐马尔可夫模型,特别是与我们的方法有关的一些模型。
• S4 (Gu、Goel 和 Ré,2022;Gu、Johnson、Goel 等人,2021) 引入了第一个结构化的 SSM,描述了对角线结构和对角线加低秩(DPLR)。由于与连续时间在线记忆(HIPPO)(Gu、Dao 等人,2020) 的联系,它专注于 DPLR SSM 的高效卷积算法。
• DSS (Gupta、Gu 和 Berant 2022) 首先通过近似 HIPPO 初始化发现了对角结构 SSM 的经验有效性。 这在 S4D (Gu、Gupta 等人,2022) 中得到了理论扩展。
• S5 (Smith, Warrington 和 Linderman,2023 年) 独立地发现了对角 SSM 近似,并且是第一个使用并行扫描进行递归计算的 S4 模型。然而,这需要降低有效状态维度,他们通过从 SISO(单输入单输出)转换为 MIMO(多输入多输出)来实现这一点。我们提出的 S6 共享了扫描,但不同之处在于(i)保留了 SISO 维度,从而提供了更大的有效循环状态,(ii)使用了一种针对硬件设计的算法来克服计算问题,(iii)添加了选择机制。
Lu等人(2023)使用S5对元强化学习中的重置状态进行建模。他们的机制可以视为选择机制的一个特殊硬编码实例,其中A被手动设置为0,而不是我们基于输入的学习机制。在这一背景下一般地应用选择性SSM并探查模型是否已学会在时间步边界自动重置其状态将会很有趣。
• Mega(Ma等人,2023年)引入了S4的一种简化形式,使其可以是实值而不是复值,从而将其解释为指数移动平均线(EMA)。他们还建立了SSM离散化步骤与EMA阻尼项之间的有趣联系。与原始S4论文中的发现相反,这是第一个模型表明实值SSM在某些情况下或与其他架构组件结合使用时在经验上有效。
• Liquid S4 (Hasani等人,2023年) 的动机也是通过基于输入的状态转换来增强S4。从这个角度来看,它与选择机制具有相似性,尽管形式有限,仍然是卷积计算的,并且接近LTI。
SGConv (Y. Li等人,2023),Hyena(Poli等人,2023),LongConv(Fu等人,2023),MultiresConv(J. Shi,K. A. Wang,Fox,2023)和Toeplitz神经网络(Qin,Han,W. Sun,B. He等人,2023)都关注S4的卷积表示,并使用不同的参数化创建全局或长卷积核。然而,这些方法不能直接进行快速自回归推理。
值得注意的是,所有这些方法以及我们所知道的所有其他结构化状态空间模型都是非选择性的,并且通常是严格的LTI(线性时不变)。
B.2 SS M体系结构
我们使用 SSM 架构或状态空间神经网络 (SSNN) 来指代深度神经网络架构,其中包含一个以前的 SSM 作为黑盒层。
• GSS (Mehta 等人,2023 年) 是第一个使用 SSM 的门控神经网络架构。它的动机来自于华等人(2022 年)的门控注意力单元(GAU),看起来与我们的块非常相似,只是额外的投影。最重要的是,它的投影将模型维度缩小以减少 SSM 的状态大小,而我们的扩展了模型维度以增加状态大小,如第 3.1 节所述。
• Mega(Ma等人,2023年)将上面描述的S4的EMA简化结合到一个使用有效注意力近似的混合架构中。
H3 (道、福、萨巴等,2023年) 的动机是结合 S4 和线性注意力(Katharopoulos 等,2020 年)。它是第一个将这种线性关注的形式推广到更一般的递归的方法,也是后来架构的基础。
• Selective S4(王等人,2023)将S4作为黑盒来生成一个二进制掩码,并将其应用于输入。虽然共享"选择"的名称,但我们将此视为一种更接近架构门控而不是选择机制的体系结构修改(附录A)。例如,我们假设它不会解决 Selective
复制任务,因为简单地屏蔽掉不相关的输入并不会影响相关输入之间的间距(事实上,如果噪声标记嵌入到零中,选择性复制任务甚至可以被视为预掩码)。
RetNet (孙等,2023年) 也基于线性注意力,并且与 H3 非常相似,但将其内部的 S4 层减少到一个特殊情况,其中状态维度为 N = 1。尽管没有以这种方式构造,但其递归可以视为线性 SSM 的特例。
其主要改进方式是使用具有大头维的线性注意力,这可以视为另一种输入相关状态扩展的方法。在各种线性注意力变体中使用更大的头维首次由H3完成,但由于需要相应的额外计算量,因此没有广泛使用。RetNet通过一种替代方法来避免这一点:使用标准多头注意力的一种变体而不是卷积并行化计算,这要归功于它们特殊的SSM特殊情况,它充当简单的EMA。
• RWKV (B. Peng等人,2023年) 是另一个用于语言建模的最近设计的循环神经网络。它基于 AFT(无关注力变形器)(S. Zhai 等人,2021),这是线性注意力的另一种变体。它的主要"Wkv"机制涉及LTI递归,并可以看作两个SSM的比率。
我们还强调了华等人(2022)提出的门控注意力单元(GAU),其灵感来自于将变压器的多头自注意块和全连接层组合在一起,并且它是我们的架构(第3节中的4段)中结合H3和MLP块的灵感来源。
B.3 与递归神经网络的关系
循环神经网络 (RNN) 和自回归状态模型 (SSM) 之间存在广泛的联系,因为它们都涉及对潜在状态进行递归的概念。
一些较旧的循环神经网络,如强类型循环神经网络(Balduzzi 和 Ghifary,2016 年)、准循环神经网络 (QRNN) (Bradbury 等人,2016 年)和简单递归单元 (SRU) (Lei,2021;Lei 等人,2017 年),涉及没有时间相关非线性的门控循环神经网络形式。由于门控机制和选择机制之间的连接,这些可以视为选择性 SSM 的情况,并且因此在某种意义上比上述 LTI 结构化 SSM 家族更强大。主要区别在于:
• 他们没有使用 状态扩展(N = 1)或选择性B、C参数,这两者对性能都非常重要(第4.6节)。
他们使用启发式门控机制,我们将其概括为选择机制+离散化(定理1)。与原则上正确的 SSM 理论的联系提供了更好的参数化和初始化(第 3.6 节)。
此外,早期的循环神经网络 (RNN) 著名地存在效率问题和消失梯度问题(Hochreiter 1991;Hochreiter、Bengio 等人,2001;Pascanu、Mikolov 和 Bengio,2013),这两者都是由它们的顺序性质引起的。通过利用并行扫描(Martin 和 Cundy,2018 年)可以解决上述一些 RNN 的前一个问题,但后一个问题在没有后来为隐马尔可夫模型开发的理论的情况下很难解决。例如,现代结构化隐马尔可夫模型 (SSMs) 在对递归动力学进行更仔细的参数化方面有所不同,灵感来自经典的隐马尔可夫模型理论(例如,通过离散化(Gu、Johnson、Goel 等人,2021 年;Gu、Johnson、Timalsina 等人,2023 年)或直接分析(Gupta、Mehta 和 Berant,2022 年;Kaul,2020 年;Orvieto 等人,2023 年)。
我们还注意到,有许多关于正交循环神经网络(Arjovsky、Shah 和 Bengio 2016;Henaff、Szlam 和 LeCun 2016;Lezcano-Casado 和 Martinez-Rubio 2019;Mhammedi 等人 2017;Vorontsov 等人 2017)的工作,这些工作都是为了约束 A 转换矩阵为正交或酉矩阵,以控制其特征值并防止梯度消失问题。然而,它们也有其他限制;我们认为这是因为正交/酉循环神经网络也是 LTI。例如,它们几乎总是在复制任务上进行评估,而在该任务中它们可以完美地解决问题,但观察到在选择性复制任务中遇到困难(Jing 等人 2019)。
B.4 线性注意力
线性注意力(LA)(Katharopoulos等人,2020) 是一个重要的框架,它推广了核注意力,并展示了它与递归自回归模型的关系。已经提出了许多变体来选择替代核和其他修改。随机特征注意力(RFA)(Peng等人,2021) 使用高斯核的随机傅里叶近似来近似softmax注意力(即指数特征映射)。Performer (Choromanski等人,2021) 找到了仅包含正的指数核的指数核的近似值。
还允许softmax规范项。 TransNormer (Qin, Han, W. Sun, D. Li等人,2022年) 表明LA分母项可能不稳定,并建议用 层归一化 来代替它。 cosFormer (Qin, W. Sun等人,2022年) 增加了具有位置信息强调局部性的余弦重权机制的RFA。 线性随机注意力(Zheng, C. Wang, 和L. Kong,2022)从重要抽样角度推广了RFA,并将其推广为提供对整个softmax核(而不仅仅是指数变换的分子)的更好估计。
除了内核注意力之外,还有许多其他有效的注意力变体;泰、德格哈尼、巴赫里等人。 (2022) 对其中许多进行了全面分类。
B.5 长上下文模型
长文本已成为一个热门话题,最近的一些模型声称能够处理越来越长的序列。然而,这些往往是从计算的角度来看,并没有得到广泛验证。其中包括:
• Recurrent Memory Transformer (Bulatov, Kuratov 和 Burtsev 2023),它是围绕 Transformer 主干的一个轻量级包装器。它展示了对高达一百万序列进行泛化的潜力,但仅限于合成记忆任务;他们的主要结果与我们的归纳头外推实验(表 2)类似。
• LongNet (Ding等人,2023),声称可以扩展到1亿长度,但仅在实际任务中对小于10万长度进行评估。
• 豹和豹 DNA (Nguyen, Poli 等人,2023;Poli 等人,2023),声称可以利用多达一百万种上下文。然而,他们的实验是在更长的上下文中按比例训练更多的数据,因此很难得出结论,即在一百万种上下文中的质量改进是由于上下文长度还是由于更多的数据和计算。
• Sparse Transformer (Child et al. 2019) 展示了使用稀疏分层注意力模型来建模长度为 220=1048576 的音频波形的概念证明,尽管在控制计算成本和模型大小时没有讨论性能权衡。
相比之下,我们认为这项工作提供了一种有意义的方式来展示随着语境变长而提高性能的方法。
选择性 SSM 的力学
定理1的证明。考虑一个选择性SSM(算法2),其中N = 1,A = -1,B = 1,sA = 线性(x),τa = softplus。相应的连续时间SSM(1)为
这被称为"泄漏积分器"。
离散化步长为
我们观察到这个参数可以看作一个可学习的偏差,并被折叠进线性投影中。
现在应用零阶保持(ZOH)离散化公式:
= 1 - sigma(Lin(x_t))
= 线性(xt)的结果。
如您所愿。
硬件感知的 选择性 SSM 算法
在没有输入相关选择性的情况下,SSMs 可以高效地实现为卷积(Dao等人,2023;Gu等人,2022),其中利用了快速傅里叶变换(FFT)作为基本操作。有了选择性,SSMs 不再等同于卷积,但我们将并行关联扫描用于训练具有选择性 SSMS 的基础模型时,需要它们在现代硬件(GPU)上也是高效的。我们描述了如何使用内核融合和重新计算使 SSMS 扫描变得更快、更节省内存。我们在第 4.5 节中比较了我们的扫描实现与卷积和注意力的速度,表明在序列长度为 32K 时,它比注意力快高达 7 倍,并且与最佳注意力实现(FlashAttention)一样节省内存。
速度。在现代硬件加速器(GPU)上,除了矩阵乘法外,大多数操作都受到内存带宽限制(Dao等人,2022;Ivanov等人,2021;Williams,Waterman和Patterson,2009)。我们的扫描操作也是如此,我们使用内核融合来减少内存 I/O 次数,从而实现与标准实现相比显著的速度提升。
在第 3.2 节中实现扫描算法的标准方法是在 GPU HBM(高带宽内存,通常称为 GPU 内存)上准备大小为 (B, L, D, N) 的输入 A 和 B,调用并行关联扫描实现以将大小为 (B, L, D, N) 的扫描输出写入到 GPU HBM 中,然后将该扫描输出与 C 相乘以产生大小为 (B, L, D) 的输出。但是,这需要大约 O(BLDN) 次内存读/写操作。相反,我们可以将离散化步骤、扫描和与 C 的乘法合并为一个内核:
我们从慢HBM读取O(BLD+DN)字节的数据(来自A、A、B、C),并将它们存储到快SRAM中。
-
我们离散化产生大小为 (B, L, D, N) 的 SRAM 中的 A 和 B。
-
我们并行执行一个关联扫描,产生大小为 (B, L, D, N) 的 SRAM 中间状态。
-
我们用C进行乘法和求和,生成大小为 (B, L, D) 的输出,并将其写入 HBM。
这样,我们通过一个因数O(N)(状态维度)来减少IO,这在实践中使操作速度加快了20到40倍(见第4.5节)。
对于序列长度L太长,无法放入SRAM(它比HBM小得多)的情况,我们将序列拆分为块,并对每个块执行融合扫描。 只要我们有中间扫描状态,就可以使用下一个块继续扫描。
记忆。 我们描述了如何使用经典的重新计算技术来减少训练选择性SSM层所需的总内存。
由于我们以一种融合的方式进行前向传播,为了防止内存膨胀,我们不会保存大小为 (B, L, D, N) 的中间状态。然而,这些中间状态对于反向传播计算梯度是必要的。取而代之的是,我们在反向传播中重新计算这些中间状态。由于输入 A、A、B、C 和从 HBM 读取的输出梯度的大小均为 O(BLN+DN),而输入梯度的大小也是 O(BLN+DN),因此避免了从 HBM 读取 O(BLN D) 元素的成本。这意味着在反向传播中重新计算 SSM 状态比存储它们并从 HBM 读取要快。
除了优化仅针对扫描操作所需的内存之外,我们还使用重新计算来优化整个选择性 SSM 块(输入投影、卷积、激活、扫描、输出投影)的内存需求。具体来说,我们不会保存大量占用内存但可以快速重新计算的中间激活值(例如激活函数的输出或短卷积)。因此,选择性 SSM 层具有与一个
优化了带有 FlashAttention 的 Transformer 实现。具体来说,每个注意力层(FlashAttention)每种令牌存储约 12 字节的激活,每个 MLP 层每种令牌存储约 20 字节的激活,总共为 32 字节(假设在 FP16 或 BF16 中进行混合精度训练)。每个选择性 SSM 每个令牌存储约 16 字节的激活。因此,两个选择性 SSM 层具有与一个注意力层和一个 MLP 层大致相同的激活内存。
实验细节和额外结果
E.1 生成任务
选择性复制。我们的设置是在长度为 4096 的序列上,词汇大小为 16 个可能的标记(包括来自图 2 中的白色"噪声"标记),并要求模型记住 16 个"数据"标记。我们使用具有 64 个模型维度的两层模型。
模型在学习率为0.0001、批量大小为64的情况下训练了400,000步。
头。 训练过程包括每步随机生成数据,批量大小为 8。 我们选择一个包含 8192 步的"epoch"大小,并在每个目标序列长度的固定验证集(也是随机生成的)上跟踪准确率。 对于 MHA-Abs 和 Mamba 模型,在第 25 个 epoch (8192×25 = 204800 步) 后报告结果。对于 MHA-RoPE 和 MHA-xPos 模型,在第 50 个 epoch (8192×50 = 409600 步)后报告结果。对于 LTI H3 和 Hyena 模型,在第 10 个 epoch (81920 步) 后报告结果,因为它们已经收敛并且无法进一步提高。
我们使用没有权重衰减的Adam优化器。所有模型都以恒定的学习率2e−4和1e−3进行训练,每个模型都会报告更好的结果(除了Mamba为2e−4以外的所有模型)。注意力和Hyena模型在学习率为1e−3时没有学到任何东西。H3在两个学习率下都有所学习,但有趣的是,在较小的学习率2e−4下,它对较短序列的泛化能力更强。Mamba在两个学习率下都有所学习,但在较大的学习率1e−3下进行了更好的外推。
E.2 语言建模
E.2.1 比例律详情
缩放定律实验通常遵循GPT3的配方。所有模型都使用Pile进行训练,其中包含GPT2标记器。
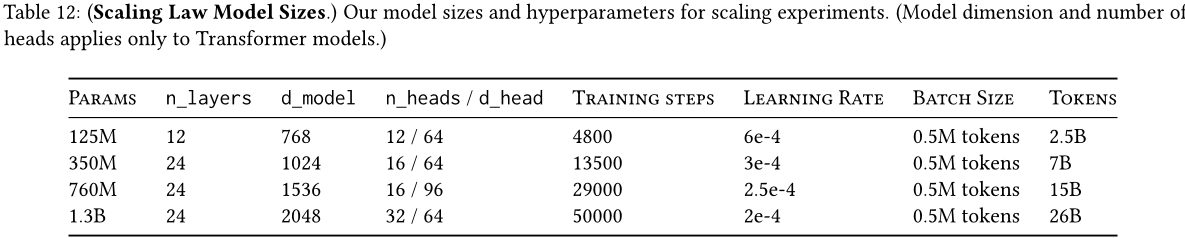
模型大小。表 12 指定了我们用于缩放定律的模型大小。此信息直接取自 GPT3 规范(Brown 等,2020 年),只进行了非常轻微的修改。首先,我们将 13 亿模型的批处理大小从 100 万个标记更改为 50 万个标记,因为我们没有使用足够的并行化来要求更大的批处理大小。其次,我们更改了训练步数和总标记数,以大致匹配 Chinchilla 的缩放法则(霍夫曼等人,2022 年),该法则规定训练标记应与模型大小成比例增加。
训练食谱。所有模型都使用AdamW优化器,并在 时进行微调
•梯度剪切值为1.0
• 权重衰减 0.1
• 没有辍学
• 线性学习率预热,余弦衰减
默认情况下,最大学习率是GPT-3的规格。
我们为几个模型提供了"改进版"配方,灵感来自像PaLM(Chowdhery等人,2023)和LLaMA(Touvron等人,2023)这样的流行大型语言模型所采用的变化。这些包括:
• 使用余弦衰减到 1e−5 的线性学习率预热,峰值为 GPT-3 值的 5 倍
• 没有线性偏差项
• 用 RMSNorm 替代 LayerNorm
• AdamW 优化器,超参数β=(.9, .95)(与 GPT-3 相同), 而不是PyTorch 默认值 β=(.9, .999)
架构与训练细节。我们的模型如下:
• Transformer:基于GPT-3的标准Transformer(表12)。
• Transformer ++: 带有改进架构的 Transformer,即旋转位置编码(Su 等人,2021 年)和 SwiGLU MLP(Shazeer,2020 年),以及上面提到的改进训练食谱。
• 豺狼:在标准MLP块中插入一个豺狼块(H3块,其中S4被全局卷积代替,该卷积由一个多层感知器参数化)。MLP块具有扩展因子2而不是4,并相应地增加1.5倍层数以保持参数数量。
H3++:带有几个修改的 H3 架构,包括(i) 使用上面相同的"瘦"Hyena 尺寸(ii) 上面改进的训练配方(iii) 线性注意力头维度为 8。
• RWKV:B.Peng等人(2023)的默认RWKV模型,包括其修改后的MLP块。我们还尽可能使用了它指定的所有训练配方,例如在某些参数上将学习率提高到原来的两倍或三倍。
• RetNet:Y. Sun等人(2023)的默认 RetNet 模型。我们还为它提供了上面改进后的训练方案。
• Mamba:标准Mamba架构,带有改进的训练配方。
E.2.2额外缩放法则消融
我们使用与图 4 (左) 中的 2k 长度比例法相同的协议对架构进行额外消融。
Mamba 架构:交错块。我们测试了不同架构块与 Mamba 块相结合的效果。我们的重点是,从 Mamba 块只是带有附加的 conv→SSM 路径的标准 SwiGLU 块的观点来看。这导致了两个自然的删除:
• 如果我们将 Mamba 块与标准 MLP 块交替,而不是均匀堆叠呢? 这也可以解释为使用 Mamba 并删除一半的 SSM。
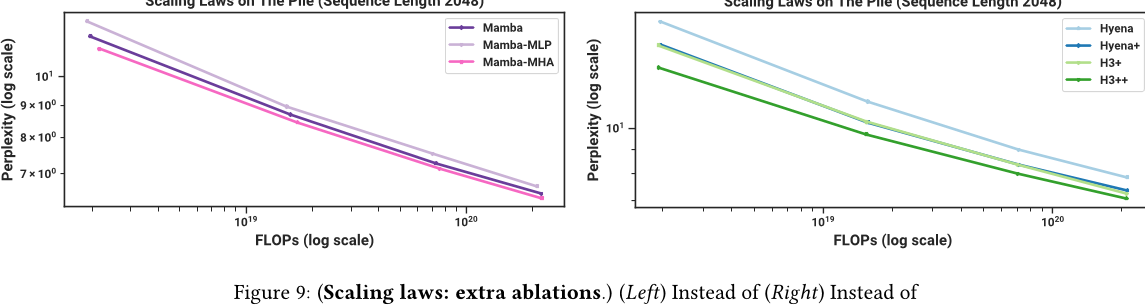
• 如果使用Mamba块与MHA(多头注意力)块进行交错呢? 这也可以解释为使用带有SwiGLU MLPs(即我们所称的Transformer ++)的Transformer,并简单地在MLP块中添加SSMs。
图9 (右) 比较了这些变体与原始(同质)Mamba架构。有趣的是,这两个变化都不太重要。Mamba-MLP 架构略差,但仍然优于所有模型,除了 Transformer++。Mamba-MHA 架构只略好一些,这在许多最近的研究中发现结合(LTI)自回归模型与注意力可以导致显著改进的情况下有些令人惊讶(Dao等人,2023;Fathi等人,2023;Fathullah等人,2023;Saon等人,2023;Zuo等人,2022)。
H3 架构:训练配方。接下来,我们将移除在 H3 ++ 模型与 Hyena 模型之间的差异,即除了 Transformer ++ 和 Mamba 之外我们最弱和最强的模型,特别是为了隔离训练配方的影响。
• 豺狼:豺狼块及其原始架构(与图4相同)和GPT3训练配方。
Hyena+:具有上述改进训练配方但具有相同架构。
• H3+:与Hyena+相同的架构,但用S4D卷积核替换了Hyena卷积核。
• H3+:与H3+相同,但线性注意力头的维度为8。这增加了内部SSM递归中的计算量,但不会增加参数数量。
我们的惯例是,"Model+"代表具有改进训练配方的基本模型,而"Model++"也允许架构更改。
图9(右)显示了
• 通过改进后的训练方案,如图 4 中的主要模型 (RetNet、H3++、Transformer++) 和 Mamba 取得了显著的改进。
• 内部LTI SSM的选择并不重要(例如,Hyena vs. S4),这与本文中的发现一致。
• 头部维度扩展提高了性能,与我们的主要主题之一一致,即扩展状态维度可以提高 SSM 的性能(第 3 节)。
E.2.3 下游评估细节
这个预训练过程与缩放定律协议相同,但扩展到 300B 个标记,并使用 GPT-NeoX 分词器(Black 等人,2022 年)而不是 GPT2 分词器。对于 13 亿模型,我们使用 100 万个标记的批次大小以保持与 GPT3 规格的一致性。我们在 Pile 验证集上报告困惑度,并且仅针对与该数据集和分词器相同的模型进行比较,特别是 Pythia 和 RWKV。
下游评估中,我们使用 EleutherAI 的语言模型评估工具包 (L. Gao, Tow, et al. 2021),这是该领域大多数工作的做法。我们在以下任务/数据集上进行评估,以衡量常识推理:
• LAMBADA (Paperno 等人,2016)
• HellaSwag (Zellers 等人,2019年)
• PIQA (Bisk 等人,2020)
• ARC 挑战(P. Clark 等人,2018 年)
• ARC-easy:ARC challenge 的一个简单子集
• WinoGrande (Sakaguchi 等人,2021)
我们报告了 LAMBADA、WinoGrande、PIQA 和 ARC-easy 的准确率,以及 HellaSwag 和 ARC-challenge(由于几乎所有模型在这些任务上的归一化准确率都更高)的归一化准确率。
E.3 DNA 模型
E.3.1 预训练细节
我们更详细地描述了 HG38 预训练任务的数据集和训练过程。
数据集遵循先前在基因组学中使用 Enformer 的工作(Avsec 等人,2021 年)中的拆分;训练拆分包含 S = 34021 段,长度为 217 = 131072,覆盖整个基因组,总共有大约 45 亿个标记(DNA碱基对)。这些段是 (染色体号、起始索引、结束索引) 的一对,并且可以根据需要进行扩展(例如,以获取更长的段)。
当训练序列长度不是 217 时,我们偏离了 HyenaDNA。HyenaDNA 总是取一个固定的子段(例如规定区域的开头或中间),因此对于任何给定的训练序列长度,每个周期都是固定为 34021 个样本,并不一定要覆盖整个基因组。另一方面,我们使用完整的训练数据:
• 当上下文长度 L 小于或等于 217 时,我们将每个段划分为非重叠的子段,其长度为 L,这样每个周期就有 S×217L 个样本和 S×217≈4.5B 个标记。
• 当上下文长度 L 大于 217 时,我们将每个段落转换为两个样本:一个以指定的段落开头,另一个以指定的段落结尾。因此,每个周期包含 2S 个项目和 2SL 个标记。例如,在序列长度为 218 = 262144 时,标记数是默认值的 4 倍,而在序列长度为 220 时,标记数是默认值的 16 倍。
其他训练细节通常遵循与我们的语言建模实验相同的协议(附录 E.2)。例如,我们使用带有 (β1, β2) = (0.9, 0.95) 的 AdamW、没有丢弃、权重衰减为 0.1。我们在总步数的 10% 上线性加热学习率调度器。
E.3.2 伸缩性:模型大小细节
模型。我们考虑的模型如下:
• Transformer ++: 带有改进架构的 Transformer,特别是使用 RoPE 位置编码 (Su等人,2021)。非正式地说,我们发现这些明显优于 (Vaswani 等人,2017) 的标准位置编码。
HyenaDNA: 由Nguyen、Poli等人(2023年)和Poli等人(2023年)提出的Hyena模型,它基本上是一个带有MLP参数化的全局卷积器替换掉MHA块的Transformer。
• Mamba:标准的Mamba架构。
模型大小。我们使用了以下模型大小。
请注意,Mamba 的块数翻了一番,因为一个 Transformer"层"包含 MHA 和 MLP 块(Hyena 类似),因此需要两个 Mamba 块来匹配参数(第 3.4 节)。
训练。对于每个模型(Transformer++,Hyena DNA,Mamba),我们在{1e−3,2e−3,4e−3,8e−3}中扫过学习率。所有尺寸的最佳 Transformer 和 Hyena DNA 学习率为 2e−3。最佳 Mamba 学习率为 8e−3;请注意,与匹配的学习率(2e−3)相比,Mamba 的表现更好,但在更高的学习率下更稳定,并且改进得更多。(此外,由于此学习率位于扫描范围的上限,因此我们的结果可能仍然不完美。)
请注意,与标准的 LMS 规则(表 12)相反,出于简单起见,我们的LR 在模型大小之间保持不变。对于较大的模型,最佳的LR 应该降低,但我们发现在我们考虑的小型模型中(最多数百万个参数),没有明显的这种效果。
E.3.3 放缩:上下文长度细节
我们使用总批次大小为 224,约等于 16M 个标记进行每个训练步骤。对于每种序列长度(例如,在长度为 220 的情况下,一批有 16 段;在长度为 210 的情况,一批有 16384 段)。相对于语言模型的标准,这是一个巨大的批次大小,但请注意,对于具有 8 台 GPU 和序列长度为 220 的机器来说,最小可能的批次大小为 223,而HyenaDNA 使用了更大的批次,其大小为 228。
Mamba 使用了学习率为 0.008,HyenaDNA 使用了学习率为 0.001;我们最初尝试使用上一节中介绍的 HyenaDNA 的相同学习率(0.002),但发现在最长的上下文长度下不稳定。
序列长度预热。根据 Nguyen、Poli 等人的 2023 年论文,我们在预训练过程中使用了序列长度预热(SLW)。我们选择了一个简单的进度表,在每个幂次数量级序列长度为 2^x 的前两个 epoch 进行调整,从 2^10 = 1024 开始。(请注意,由于数据集的构建方式,在最长的序列长度上,所花费的步数和标记数量成比例增加。具体来说,每个阶段处理相同数量的标记,但 218 处理的是 4 倍,219 处理的是 8 倍,220 处理的是 16 倍。)
与HyenaDNA不同,我们总是控制每个梯度更新中的标记数,因此在每个阶段中序列长度翻倍时,批量大小会连续减半。
注释E.1。我们还注意到,该时间表尚未调整,并且在这些预训练实验中,我们从未尝试过关闭序列长度预热。后来我们发现,在类似长度的音频预训练中,SLW并未明显提高性能(第4.4节),因此对于DNA预训练来说,这可能也不是必要的。
E.3.4 大猩猩分类
模型是因果关系,因此仅使用模型输出中的最后一个元素(跨序列长度)进行分类。注意,在每个梯度步骤中,我们控制损失函数中总元素的数量。预训练目标包括整个序列长度的所有位置,所以 批次大小×序列长度 保持不变;换句话说,当序列长度增加时,批次大小会减少。但是,对于一个分类任务,由于只有最后一个位置进入损失,批次大小本身保持不变。请注意,这也意味着对具有更长序列长度的模型进行微调在计算上更加昂贵。
训练包含 10 个 epoch,每个 epoch 都有 1024 步梯度。每个梯度步骤使用大小为 64 的批次,由独立随机抽取一个物种、独立随机抽取一个染色体并独立随机抽取一段连续的 DNA 序列得到。
根据 Nguyen、Poli 等人(2023),具有超过 2^21 = 214 = 16384 的最大上下文长度的模型使用序列长度预热,其中在长度为 2^21 = 16384 处进行 1 个时期,在长度为 2^22 = 32768 处进行 1 个时期,在长度为 2^23 = 65536 处进行 1 个时期,依此类推直到达到最大序列长度。例如,具有 2^20 = 1048576 上下文的模型在达到其最大序列长度之前经历了 6 个时期长度的预热,然后又进行了 4 个时期的训练。
所有猎豹模型的学习率均为 4e−5,而所有眼镜蛇模型的学习率为 1e−4。通过在较小序列长度(210、212、214 和 216)下对每个模型执行学习率扫掠来确定这些值,这些值被一致地发现对于每个模型都是最佳的。在长度为 218 的情况下进行了简化的学习率扫掠,结果与上述值一致,并且在长度为 220 的情况下进行了一次运行(如上所述,这些实验的计算成本与序列长度成比例)。学习率遵循带有暖化阶段的余弦衰减计划,在达到最大学习率前进行 5 轮线性暖化,然后在 5 轮余弦衰减速率后降低到 1e−6。选择这种非常长的学习率暖化时间表是因为序列长度
预热也很长(例如,对于上下文长度为220的模型,占总迭代次数的6/10);我们没有尝试这种选择。
物种分类任务的结果在表 13 中。
E.4 音频详情
E.4.1 YouTubeMix 音频预训练
模型。我们使用一个具有每个阶段 3 个块(3×5 = 15 个总曼巴块)、池化因子 p=16 和外部维度 D=64 的模型,大约有 350 万个参数。
数据集。 数据使用 8 位 Mu-Law 编码,因此模型正在对具有词汇大小为 256 的离散标记进行建模。
数据集由最长 1 分钟或长度为 960000 的片段组成,这些片段被子采样并划分为任何所需的序列长度。由于架构涉及两个阶段的池化因子为 16,我们希望结果序列长度是 8 的倍数以提高硬件效率,因此可能的最长序列长度是 468×2048 = 958464。其余的序列长度是由这个值除以二并向上舍入到最接近的 2048 的倍数来定义的。
表14列出了图7中使用的规格。除了变化的批大小之外,训练集中的有效片段数也因序列长度的不同而有所不同(例如,在图表的不同点上,每个周期的训练步长并不恒定),这可能是导致缩放曲线出现折角的原因。
训练。模型在学习率为0.002、最大训练步长为200k,20k(10%)的预热步骤以及权重衰减0.1(与我们在多个领域进行的通用预训练方案相似)的条件下进行了训练。
附加消融:SSM 参数化。我们在图 7 中描述的设置中研究了 SSMParameterization 的长音频波形预训练。稍作修改以使用更大的模型(8 层,D=64,参数量为 6M,SaShiMi 默认值)、更短的序列(211=2048 到 218=262144,而不是 213 到 220)以及更低的学习率(0.001 从 0.002)。以及更短的训练周期(100k 步而非 200k)。
图10显示,从S4到S6(即选择机制)的变化并不总是有益的。在长音频波形上,它实际上显著降低了性能,这可能从音频的角度来看是直观的
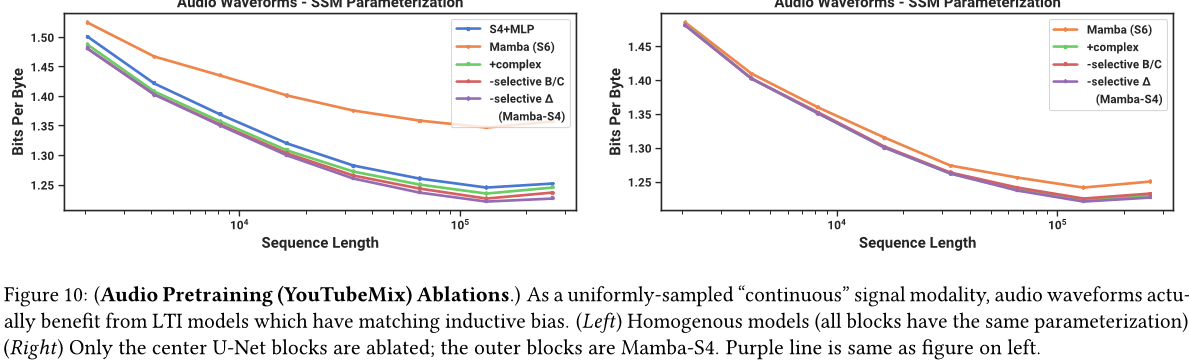
它是均匀采样且非常平滑,因此受益于连续线性不变(LTI)方法。在消除选择机制后,请注意结果模型是Mamba块中的S4层。为了澄清,我们将其称为 Mamba-S4 而不是默认的 Mamba 架构 Mamba-S6。
然而,在右侧,我们保留了 U-Net Mamba-S4 的外层,并仅消除了内层。性能差异急剧缩小;这进一步证实了这样一种假设:接近原始音频信号的层应该是LTI,但一旦它们被外层"标记化"和压缩,内层就不再需要是LTI。然而,在这种情况下,实值SSM仍然不如复值SSM表现好。
E.4.2 SC09 语音生成
自回归训练主要遵循自回归语言建模协议,例如:
• 权重衰减:0.1
• 总步数的 10% 进行学习率预热
• AdamW 优化器,β=(0.9, 0.95)
•梯度剪切值为0.1
我们使用了学习率为 0.002 和训练步数为 200,000 的批次大小为 16。
表4中的大型Mamba模型每层有15个阶段,外径D = 96,池化因子为4。我们注意到这个数据集很小(训练经过了100个时期),对于这个大模型,BPB或NLL存在显著过拟合。然而,在整个训练过程中,生成样本的自动度量不断改善。
表5中所列架构消融实验中的模型每个阶段都有8层,外维度为D = 64,池化因子为4。S4 + MLP块有大约2D 2 + 4D 2个参数(MLP中的扩张系数为2)。变压器块具有4D 2 + 2D 2个参数(MLP中的扩张系数为1)。Mamba块具有正常的约6D 2个参数。所有模型的总参数约为6M。
E.5 效率基准测试
扫描操作。我们在 A100 80GB PCIe GPU 上比较了选择性自注意力模型的核心操作,即并行扫描(第 3.3 节),与卷积和注意力的成本。请注意,这些成本不包括不在核心操作之外的其他操作,例如计算全局卷积模型中的卷积核或计算注意力中的 QKV 投影。
作为基准,我们在PyTorch中实现了一个标准并行扫描,没有内核融合。 这需要在HBM上实例化参数A、B和C。
我们的扫描实现将离散化步骤与并行扫描相结合,避免了在 HBM 中对所有大参数进行显式化所造成的开销。
对于 卷积,我们使用PyTorch中的标准实现。它对输入和滤波器分别进行FFT、在频率域中相乘,然后进行反傅里叶变换以获得结果。 理论复杂度为 O(LlogL)O(L \log L)O(LlogL),其中 LLL 是序列长度。
为了对比,我们使用最快的方法(道2024年)与因果遮挡进行比较。注意,具有因果遮挡的FlashAttention-2比没有因果遮挡的快约1.7倍,因为大约只有一半的注意力条目被计算。
我们使用批量大小为 1,并从 2^9 = 512,2^10 ≈ 1K,2^11 ≈ 2K 增加到 2^19 ≈ 500K(一些基准在达到 500K 之前就已经耗尽了内存)。我们使用模型维度 D=1024 和状态维数 N=16。我们使用BF16输入进行测量,这是用于大规模训练最常用的数据类型。
端到端推理。我们在标准的 GPT-3 架构 (大小为 13亿和 67亿) 下,对一个训练好的 Mamba 14B 模型和一个未经训练的 Mamba 69B 模型的推理吞吐量进行了衡量。我们使用了 Huggingface 的 transformers 库中的标准 Transformer 实现。
我们将提示长度设置为 2048,生成长度设置为 128。我们从 1、2、4、8、16、32、64 到 128 不等的批大小变化,并测量生成 128 个标记所花费的时间。然后,我们计算吞吐量(token/s)作为批大小×128/时间。我们重复了三次测量并取平均值。在 A100 80GB PCIe GPU 上进行测量。
内存基准。与大多数深度序列模型一样,内存使用量与激活张量的大小成正比。我们在 1 台 A100 80GB GPU 上报告了具有 125M 参数的模型在训练期间所需的内存。每个批次包含长度为 2048 的序列。我们将其与我们所知的最节省内存的 Transformer 实现进行了比较(来自 torch.compile 的内核融合以及来自 FlashAttention-2 的实现)。表 15 显示,Mamba 的内存需求与一个类似大小但经过极端优化的 Transformer 相当,并且预计 Mamba 在未来的内存占用会进一步减少。