实例描述
一年一度毕业季,除开离别的不舍和四年大学时光的回忆,伴随而来的还有作为班委的无穷无尽的任务,班级里面各个同学的毕业照的套餐统计就是一项。
毕业照的套餐有四个,我们班一共拍了八张集体照,电子版的全发给同学们,不过照片塑装打印的服务需要收费,一共有四个套餐供大家选择,每个套餐对应相应的需要从八张照片中选择的张数。
|------|-----|-----|-----|-----|
| 套餐 | 套餐一 | 套餐二 | 套餐三 | 套餐五 |
| 数量/张 | 2 | 3 | 4 | 5 |
每张照片都会对应唯一的编号供每位同学确认挑选,如下图。

起初的解决思路就是直接用共享文档让大家填写就行,不过最后得到的结果是这样。。
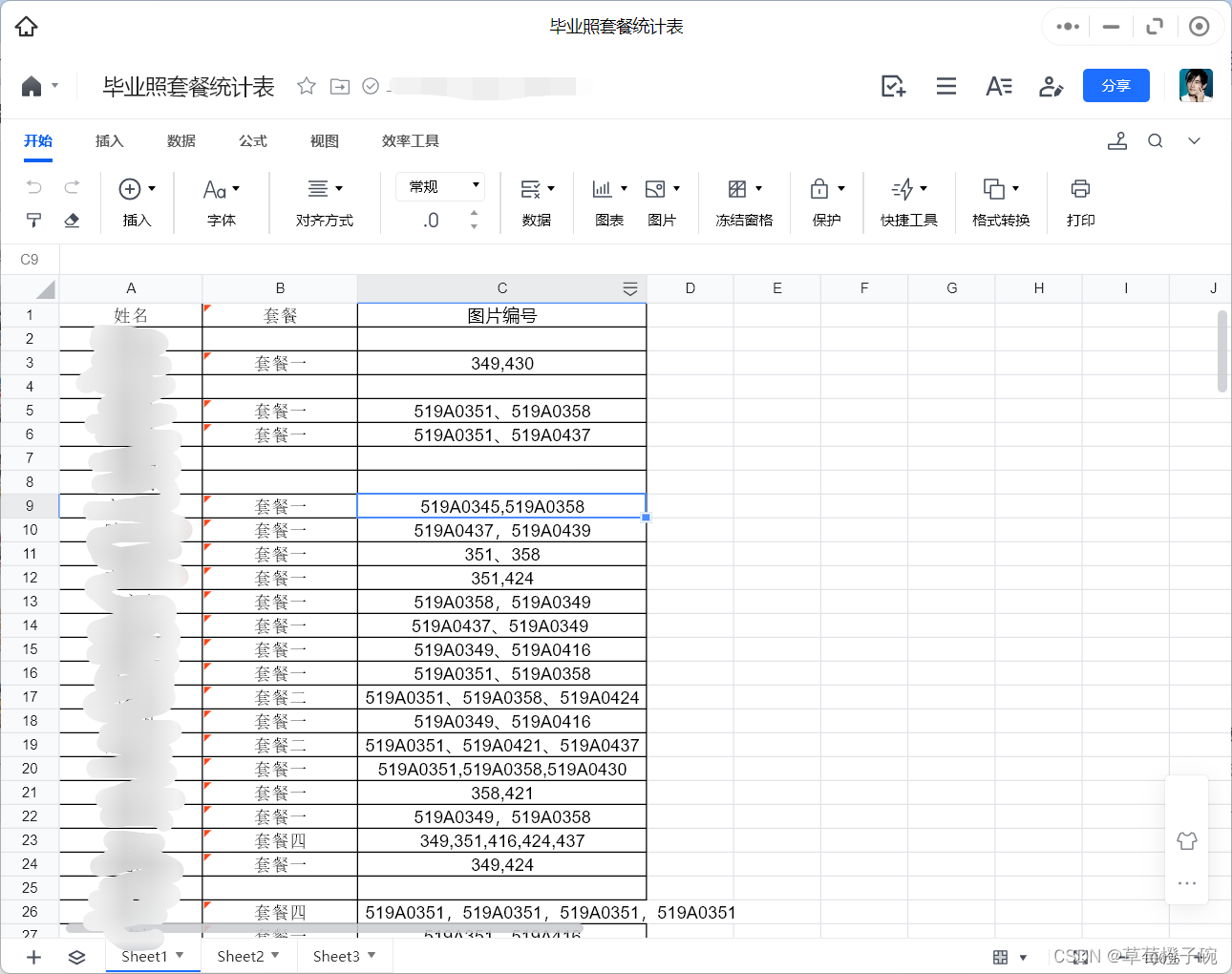
图片编号那一列真的是不堪入目,有填写完整编号的,有只填写后三位数字的,且分隔符有使用'、',也有使用','的,任务的目标是以班级为单位将每个编号的照片汇总数量上报给摄影楼进行塑装,使用Excel的筛选功能还是需要人工进行最后的统计,显得繁琐。
脚本解决思路设计
可以使用python的pandas模块对这些信息进行统计。
首先把共享文档的内容导出为本地的Excel文件格式,同时把表格内容中的','统一替换成'、',方便后续的字符串分割;
首先是对文件的读取,这是直接使用pandas模块进行读取;
python
import pandas as pd
file_path = r'D:\py-code\company\6_14_class\毕业照图片编号.xlsx'
data = pd.read_excel(file_path,keep_default_na=False)
photo_id_list = data['图片编号'] keep_default_na=False是表示读取的时候跳过存在空值的行,photo_id_list = data'图片编号' 是读取'图片编号'作为表头的列的信息,返回的是列表结构;
接下来需要考虑的是解决图标编号标准不一的问题,这里是构建映射表,通过哈希表的结果实现,统一把所有的编号映射成完整的图片序号;
python
true_list = ['519A0349','519A0351','519A0358','519A0416','519A0421','519A0424','519A0430','519A0437']
id_dict = {'349':'519A0349','351':'519A0351','358':'519A0358','416':'519A0416','421':'519A0421','424':'519A0424','430':'519A0430','437':'519A0437'}true_list是所有八张图片的编号,防止同学在填写的时候出现错误(在检查过程中发现有两位同学的编号出现了错误,damn!)
python
for single_id in photo_id_list: # 读取编号列的每一行的信息
if single_id != '': # 跳过空值
photo_id = single_id.split('、') # 以'、'作为分隔符号分隔获得多编号的信息
if photo_id[0] in id_dict.keys(): # 检查是否是编码在后三位的简写
photo_id_new = photo_id # 复制原编码
photo_id = [] # 清空原编码,准备下面的重新赋值
for photo_id_single in photo_id_new:
photo_id.append(id_dict[photo_id_single]) # 通过映射表复制新编码图片的统计也是通过字典的方法进行最终的统计,主键是图片的编号,值是该图片对应的汇总张数;
python
from collections import defaultdict
count_photo_id = defaultdict(int)
count_combine = defaultdict(int)
# 以下是伪代码
for photo_id_single in photo_id:
if photo_id_single not in true_list: # 检查编号是否错误
print('wrong id:',photo_id_single)
# raise KeyError('something woring')
else:
count_photo_id[photo_id_single] +=1 # 图片编号作为主键的值加一
n+=1 # 统计总的图片张数对于套餐的统计使用count_combine字典完成,具体的方法与count_photo_id的统计相同,这里就不赘述了。
代码
python
import pandas as pd
from collections import defaultdict
true_list = ['519A0349','519A0351','519A0358','519A0416','519A0421','519A0424','519A0430','519A0437']
id_dict = {'349':'519A0349','351':'519A0351','358':'519A0358','416':'519A0416','421':'519A0421','424':'519A0424','430':'519A0430','437':'519A0437'}
file_path = r'D:\py-code\company\6_14_class\毕业照图片编号.xlsx'
data = pd.read_excel(file_path,keep_default_na=False)
count_photo_id = defaultdict(int)
count_combine = defaultdict(int)
# data.fillna(0)
photo_id_list = data['图片编号']
n=0
for single_id in photo_id_list:
if single_id != '':
photo_id = single_id.split('、')
if photo_id[0] in id_dict.keys():
photo_id_new = photo_id
photo_id = []
for photo_id_single in photo_id_new:
photo_id.append(id_dict[photo_id_single])
# print(photo_id)
# chenk
for photo_id_single in photo_id:
if photo_id_single not in true_list:
print('wrong id:',photo_id_single)
# raise KeyError('something woring')
else:
count_photo_id[photo_id_single] +=1
n+=1
print('\n')
print("图片统计:\n", count_photo_id)
print('all number:',n)
combine_infor = data['套餐']
for combine in combine_infor:
if combine != "":
count_combine[combine] += 1
print('\n')
print('套餐统计:', count_combine)最后得到的结果:

ok,完成统计。
总结
好吧我承认上面的脚本其实都可以通过Excel的功能完成,但对于大学生活最后的几项任务,我还是想增加一些技术含量,以致敬即将结束的校园生活。

毕业快乐~