
一个认为一切根源都是"自己不够强"的INTJ
 个人主页:用哲学编程-CSDN博客
个人主页:用哲学编程-CSDN博客
专栏:每日一题------举一反三
Python编程学习
Python内置函数
目录
[DRY(Don't Repeat Yourself)](#DRY(Don't Repeat Yourself))
[KISS(Keep It Simple, Stupid)](#KISS(Keep It Simple, Stupid))
[YAGNI(You Aren't Gonna Need It)](#YAGNI(You Aren't Gonna Need It))
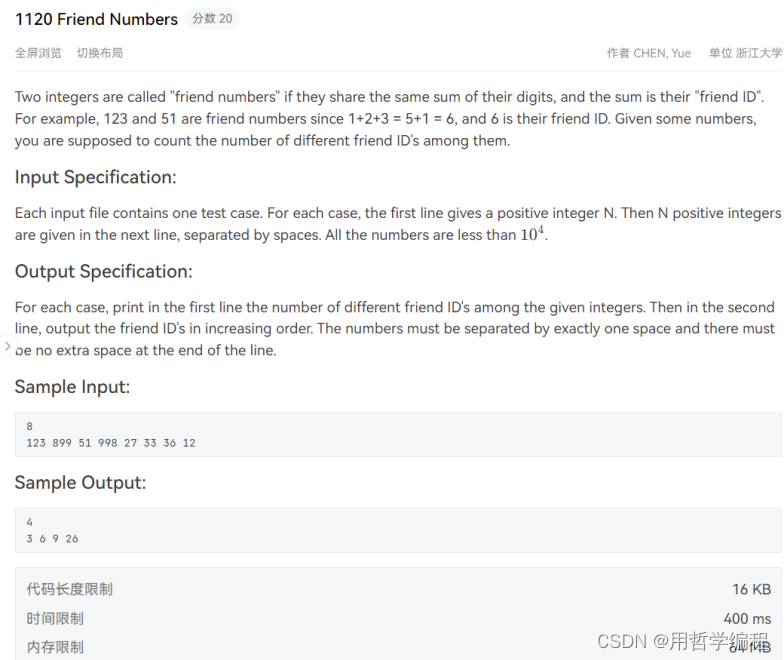
我的写法
python
N = int(input()) # 从标准输入读取一个整数,表示元素数量
nums = list(map(int, input().split())) # 从标准输入读取一行数字,并用空格分隔这些数字,转换成整数列表
def sum_of_digits(num):
output = 0 # 初始化输出为0
while num:
output += num % 10 # 将num的最后一位数字加到输出中
num //= 10 # 去掉num的最后一位数字
return output # 返回计算得到的所有位数之和
ids = set() # 初始化一个空的集合,用于存储每个数字的位数和
for num in nums: # 遍历nums列表中的每一个数字
tmp = sum_of_digits(num) # 计算当前数字的位数和
if tmp in ids: # 如果位数和已经在集合中
continue # 跳过该数字
else:
ids.add(tmp) # 否则,将位数和添加到集合中
print(len(ids)) # 打印集合中不同位数和的数量
print(*sorted(list(ids))) # 将集合转换成列表,排序后打印出来,用空格分隔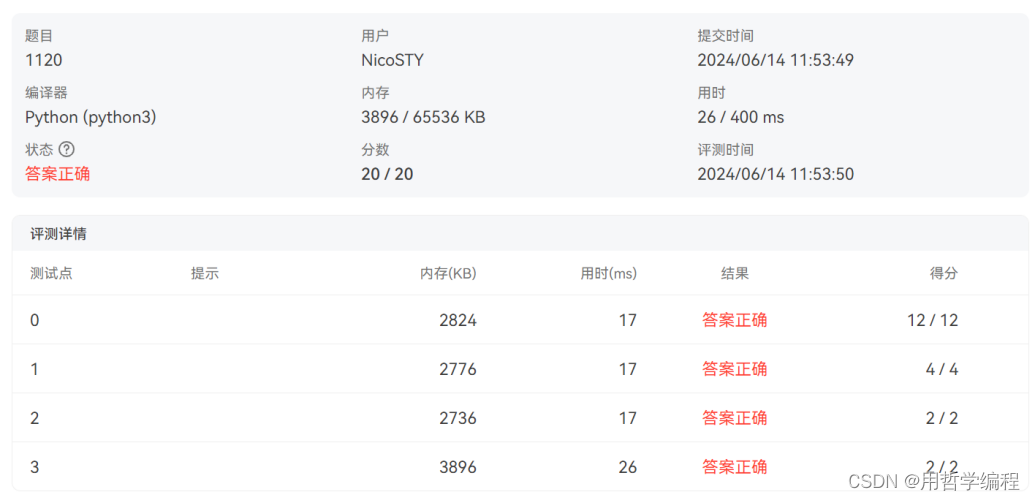
时间复杂度分析
- 输入处理:
- 读取整数 N 和一行数字,并将其转换为整数列表。时间复杂度为 O(N),其中 N 是输入数字的数量。
- sum_of_digits 函数:
- 计算单个数字的各个位数之和。每次循环处理一位数字。时间复杂度为 O(d),其中 d 是数字的位数。对于最大值 M,位数 d 可近似为 log10(M)。
- 主逻辑:
- 遍历 nums 列表中的每一个数字,调用 sum_of_digits 函数,并将结果存储到集合中。时间复杂度为 O(N * log10(M)),其中 N 是数字的数量, M 是数字的大小。
- 输出结果:
- 计算集合的长度和排序集合。计算长度的时间复杂度为 O(1),排序的时间复杂度为 O(K * log K),其中 K 是不同的位数和的数量, K 的最大值为 9 * log10(M)。
空间复杂度分析
- 输入处理:
- 需要 O(N) 的空间来存储输入的整数列表 nums。
- sum_of_digits 函数:
- 该函数使用常数空间,因此空间复杂度为 O(1)。
- 主逻辑:
- 使用集合 ids 存储不同的位数和。最坏情况下,集合中会包含所有可能的位数和,其数量与最大整数的位数有关。空间复杂度为 O(K),其中 K 的最大值为 9 * log10(M)。
- 输出结果:
- 需要 O(K) 的额外空间来存储排序后的列表。
综上所述
- 时间复杂度:
- 总体时间复杂度为 O(N * log10(M))。
- 空间复杂度:
总体空间复杂度为 O(N + K),其中 K 的最大值为 9 * log10(M)。
我要更强
优化这段代码的关键在于减少不必要的操作和使用更高效的数据结构。以下是一些可能的优化方法:
- 提前去重:在计算每个数字的位数和之前,先使用集合 nums 进行去重,这样可以避免对重复的数字进行冗余计算。
- 减少集合操作:由于集合本身会处理重复项,所以可以直接添加到集合中,不需要先检查是否存在。
- 优化sum_of_digits函数:虽然当前实现已经很高效,但可以考虑用字符串处理的方法来简化代码,虽然在性能上差别可能不大。
这里是优化后的代码:
python
# 从标准输入读取整数,表示元素数量
N = int(input())
# 从标准输入读取一行数字,并用空格分隔这些数字,转换成整数列表
nums = list(map(int, input().split()))
# 定义一个函数,用于计算一个整数的各个位数之和
def sum_of_digits(num):
return sum(int(digit) for digit in str(num))
# 初始化一个空的集合,用于存储每个数字的位数和
ids = set()
# 使用集合去重后的数字列表
unique_nums = set(nums)
# 遍历去重后的数字列表中的每一个数字
for num in unique_nums:
# 计算当前数字的位数和,并添加到集合中
ids.add(sum_of_digits(num))
# 打印集合中不同位数和的数量
print(len(ids))
# 将集合转换成列表,排序后打印出来,用空格分隔
print(*sorted(ids))优化点详细说明
- 提前去重:
- 使用集合 unique_nums 去重,这样可以减少后续对重复元素的处理。
- 直接添加到集合:
- 直接将位数和添加到集合 ids 中,避免了不必要的存在性检查。
- 简化sum_of_digits函数:
- 使用字符串转换的方式计算位数和,使代码更加简洁。
时间复杂度分析
- 输入处理:
- 读取整数 N 和一行数字,并将其转换为整数列表。时间复杂度为 O(N)。
- sum_of_digits 函数:
- 计算单个数字的各个位数之和。每次循环处理一个字符。时间复杂度为 O(d),其中 d 是数字的位数。对于最大值 M,位数 d 可近似为 log10(M)。
- 主逻辑:
- 遍历 unique_nums 集合中的每一个数字,调用 sum_of_digits 函数,并将结果存储到集合中。时间复杂度为 O(U * log10(M)),其中 U 是唯一数字的数量, M 是数字的大小。由于集合去重后的数量 U <= N,所以总体时间复杂度为 O(N * log10(M))。
- 输出结果:
- 计算集合的长度和排序集合。计算长度的时间复杂度为 O(1),排序的时间复杂度为 O(K log K),其中 K 是不同的位数和的数量, K 的最大值为 9 * log10(M)。
空间复杂度分析
- 输入处理:
- 需要 O(N) 的空间来存储输入的整数列表 nums。
- sum_of_digits 函数:
- 该函数使用常数空间,因此空间复杂度为 O(1)。
- 主逻辑:
- 使用集合 ids 存储不同的位数和。最坏情况下,集合中会包含所有可能的位数和,其数量与最大整数的位数有关。空间复杂度为 O(U + K),其中 U 是唯一数字的数量, K 的最大值为 9 * log10(M)。
- 输出结果:
- 需要 O(K) 的额外空间来存储排序后的列表。
综上所述
- 时间复杂度:
- 总体时间复杂度为 O(N * log10(M))。
- 空间复杂度:
总体空间复杂度为 O(N + K),其中 K 的最大值为 9 * log10(M)。
哲学和编程思想
在优化这段代码的过程中,运用了多种哲学和编程思想。这些思想帮助编写更高效、更简洁和更可维护的代码。以下是具体的思想及其在代码中的应用:
编程思想和哲学
- DRY(Don't Repeat Yourself)
- 解释:DRY原则强调代码中不应该有重复的逻辑。每一块知识都应该在代码中有且只有一个明确的表示。
- 应用:
- KISS(Keep It Simple, Stupid)
- 解释:KISS原则提倡保持代码的简单性,避免不必要的复杂性。
- 应用:
- YAGNI(You Aren't Gonna Need It)
- 解释:YAGNI原则建议程序员不应该添加当前不需要的功能。这有助于保持代码的简洁,并减少不必要的复杂性。
- 应用:
- 早期优化(Premature Optimization)是万恶之源
- 解释:这条原则提醒我们不要在没有明确性能瓶颈的地方进行过早或不必要的优化。
- 应用:尽管我们进行了优化,但每个优化都是基于明确的瓶颈和需求,而不是盲目地优化每一行代码。
- 空间换时间
- 解释:有时可以通过增加空间复杂度来降低时间复杂度,从而提升程序的整体性能。
- 应用:通过使用集合去重,增加了一些空间消耗,但显著减少了后续操作的时间复杂度。
具体代码中的应用
- DRY和KISS:
- 使用集合 unique_nums 进行去重,避免了重复计算,简化了代码:
- KISS和YAGNI:
- 直接添加计算结果到集合中,避免不必要的存在性检查:
- 早期优化是万恶之源:
- 对于优化 sum_of_digits 函数使用字符串转换的方法,简化了代码,但没有进行过度优化:
- 空间换时间:
- 使用集合去重操作 unique_nums = set(nums),虽然增加了一点空间消耗,但大大减少了处理重复元素的时间。
通过这些编程思想的应用,不仅优化了代码的性能,还提升了代码的可读性和可维护性。每一个优化点都是基于明确的需求和瓶颈,而不是盲目的追求性能,这也符合现代软件工程的最佳实践。
举一反三
理解和应用编程哲学和思想不仅能让代码更高效,还能提升其可读性和可维护性。以下是一些技巧和示例,帮助你在实际编程中举一反三:
DRY(Don't Repeat Yourself)
技巧:
- 抽取公共逻辑:识别出代码中的重复部分,将其抽取成函数或模块。
- 使用参数化:通过参数化配置让函数或模块更具通用性。
示例:
- 如果你发现多个地方都在执行类似的字符串操作,可以抽取成一个函数:
python
def process_string(s):
return s.strip().lower()
result1 = process_string(input1)
result2 = process_string(input2)KISS(Keep It Simple, Stupid)
技巧:
- 拆分复杂问题:将复杂的问题拆分成多个简单的小问题,并分别解决。
- 避免过度设计:只实现当前需要的功能,不要过度设计和实现未来可能需要的功能。
示例:
- 在处理复杂数据结构时,先将其转换成更简单的形式再处理:
python
# 复杂数据结构
complex_data = [{"name": "Alice", "age": 30}, {"name": "Bob", "age": 25}]
# 简化处理
names = [person["name"] for person in complex_data]
ages = [person["age"] for person in complex_data]YAGNI(You Aren't Gonna Need It)
技巧:
- 按需开发:只实现当前所需的功能,不要为了"以后可能用到"而开发额外的功能。
- 迭代增加功能:通过迭代开发逐步增加功能,每次都只增加当前需要的部分。
示例:
- 在开发初期,只实现基本的功能,待需求明确后再扩展:
python
# 初期只实现基础功能
def calculate_area(length, width):
return length * width
# 之后需求增加,再扩展功能
def calculate_area(length, width, shape="rectangle"):
if shape == "rectangle":
return length * width
elif shape == "triangle":
return 0.5 * length * width早期优化是万恶之源
技巧:
- 明确性能瓶颈:在进行优化前,先通过分析工具找出代码中的性能瓶颈。
- 逐步优化:从最大的瓶颈开始,逐步进行优化,每次优化后都进行性能测试。
示例:
- 先写出功能正确的代码,再根据性能瓶颈逐步优化:
python
# 功能正确的代码
def find_max(nums):
max_num = nums[0]
for num in nums:
if num > max_num:
max_num = num
return max_num
# 根据性能瓶颈优化
def find_max(nums):
return max(nums)空间换时间
技巧:
- 使用缓存:对于重复计算的结果,可以使用缓存来提升性能。
- 预处理数据:通过预处理数据,将复杂计算提前完成,减少实时计算的负担。
示例:
- 使用缓存来提升递归函数的性能:
python
# 原始递归代码
def fibonacci(n):
if n <= 1:
return n
return fibonacci(n-1) + fibonacci(n-2)
# 使用缓存优化
from functools import lru_cache
@lru_cache(maxsize=None)
def fibonacci(n):
if n <= 1:
return n
return fibonacci(n-1) + fibonacci(n-2)结合应用
技巧:
- 综合考虑多个思想:在实际编程中,常常需要综合考虑多个编程思想,例如在保证代码简单的同时,确保不重复和不过度设计。
- 代码评审和重构:通过代码评审和重构,不断优化和提升代码质量,确保各个编程思想得到合理应用。
示例:
- 综合考虑多个编程思想,编写高质量代码:
python
def sum_of_digits(num):
# 使用字符串转换简化计算(KISS)
return sum(int(digit) for digit in str(num))
def main():
N = int(input())
nums = list(map(int, input().split()))
# 使用集合去重(DRY和空间换时间)
unique_nums = set(nums)
ids = set()
for num in unique_nums:
ids.add(sum_of_digits(num))
print(len(ids))
print(*sorted(ids))通过这些技巧,可以在实际编程中灵活应用各种编程思想和哲学,写出高效、简洁、可维护的代码。