上一次我们使用pytesseract.image_to_data(img)来检测文本,这次我们来只检测数字
项目演示
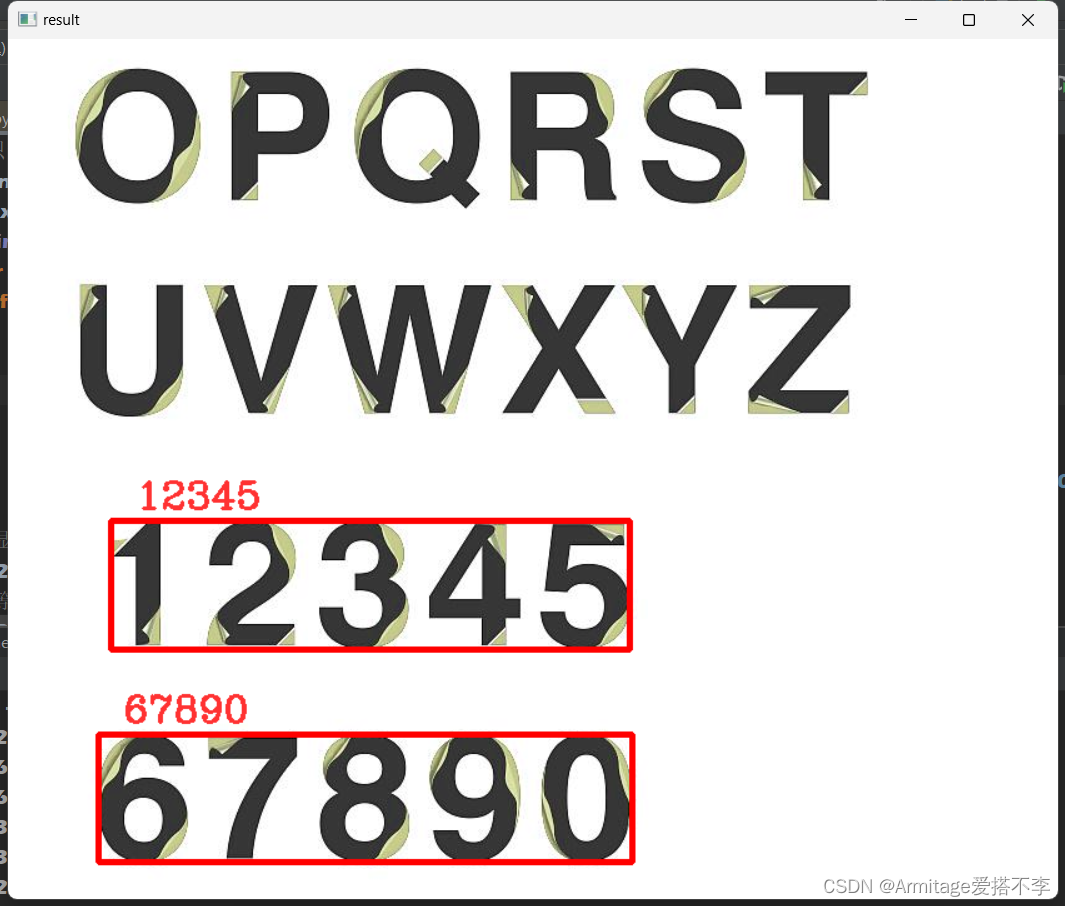
可以看到,我们只检测了数字其他的并没有检测出来
代码实现
前面两次介绍了opencv的画矩形和设置文本,这次就直接用了,不太明白的可以看之前的博客
import cv2
import pytesseract
pytesseract.pytesseract.tesseract_cmd = 'C:\\Program Files\\Tesseract-OCR\\tesseract.exe'
# 读取图像
img = cv2.imread('3.jpg')
# 将图像从 BGR 格式转换为 RGB 格式(因为 pytesseract 使用 RGB 格式)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
himg, wimg, _ = img.shape
#只读取数字
cong=r'--oem 3 --psm 6 outputbase digits'
boxes = pytesseract.image_to_data(img,config=cong)
print(boxes)
for x,b in enumerate(boxes.splitlines()):
if x!=0:
b = b.split()
print(b)
if (len(b)==12 and b[10]!='0.000000' ):
x,y,w,h = int(b[6]),int(b[7]),int(b[8]),int(b[9])
cv2.rectangle(img,(x,y),(w+x,h+y),(0,0,255),3)
cv2.putText(img,b[11],(x+20,y-10),cv2.FONT_HERSHEY_COMPLEX,1,(50,50,255),2)
# 显示带有文本框和识别结果的图像
cv2.imshow( 'result', img)
# 等待按键输入来关闭窗口
cv2.waitKey(0)
# 关闭所有打开的窗口
cv2.destroyAllWindows()在 Tesseract OCR 中,
config参数用于传递额外的配置选项,以控制 OCR 引擎的行为。r'--oem 3 --psm 6 outputbase digits'包含了三个选项,各自的作用如下:
--oem 3:
- 描述:选择 OCR 引擎模式(OEM)。
- 值 :
0: 仅使用传统的 Tesseract OCR 引擎。1: 仅使用基于 LSTM 的 OCR 引擎。2: 同时使用两种引擎,并结合结果。3: 自动选择最合适的引擎(默认)。- 作用 :
--oem 3表示让 Tesseract 自动选择最合适的 OCR 引擎。
--psm 6:
- 描述:设置页面分割模式(PSM)。
- 值 :
0: 方向和脚本检测(OSD)仅。1: 自动分页与 OSD。2: 自动分页,但不使用 OSD 或 OCR。3: 全自动分页,但不使用 OSD。4: 假设单列文本。5: 假设垂直对齐的单列文本。6: 假设统一间距的段落文本。7: 假设图像为单行文本。8: 假设图像为单个单词。9: 假设图像为单个单词的圆圈。10: 假设图像为单个字符。- 作用 :
--psm 6表示假设输入图像是一个有统一间距的段落文本。
outputbase digits:
- 描述:这种配置指示 Tesseract 仅识别数字。
- 作用 :
outputbase digits配置 Tesseract 只输出数字字符,而忽略字母和其他字符。通过组合这些选项,
r'--oem 3 --psm 6 outputbase digits'的作用是:
- 使用自动选择的最合适的 OCR 引擎。
- 假设输入图像包含一个有统一间距的段落文本。
- 仅识别和提取数字字符。
大家可以发现我在代码写了一句
if (len(b)==12 and b[10]!='0.000000' ):这个是因为读取数字文本时他将Z错认为"2"了,但是他的置信度为0,因此使用置信度为0将其筛出
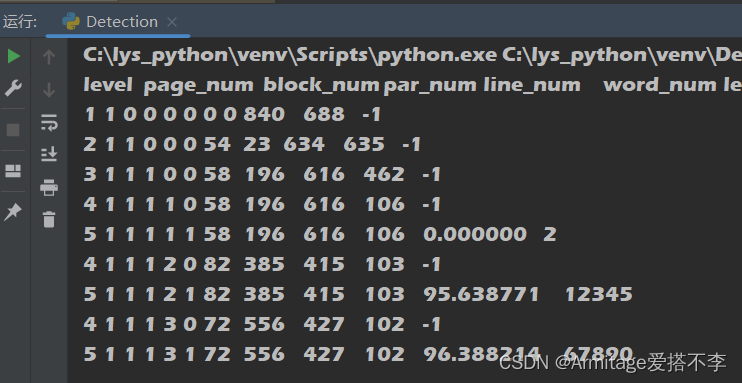
 如果不将其筛除则会出现这样的情况。
如果不将其筛除则会出现这样的情况。
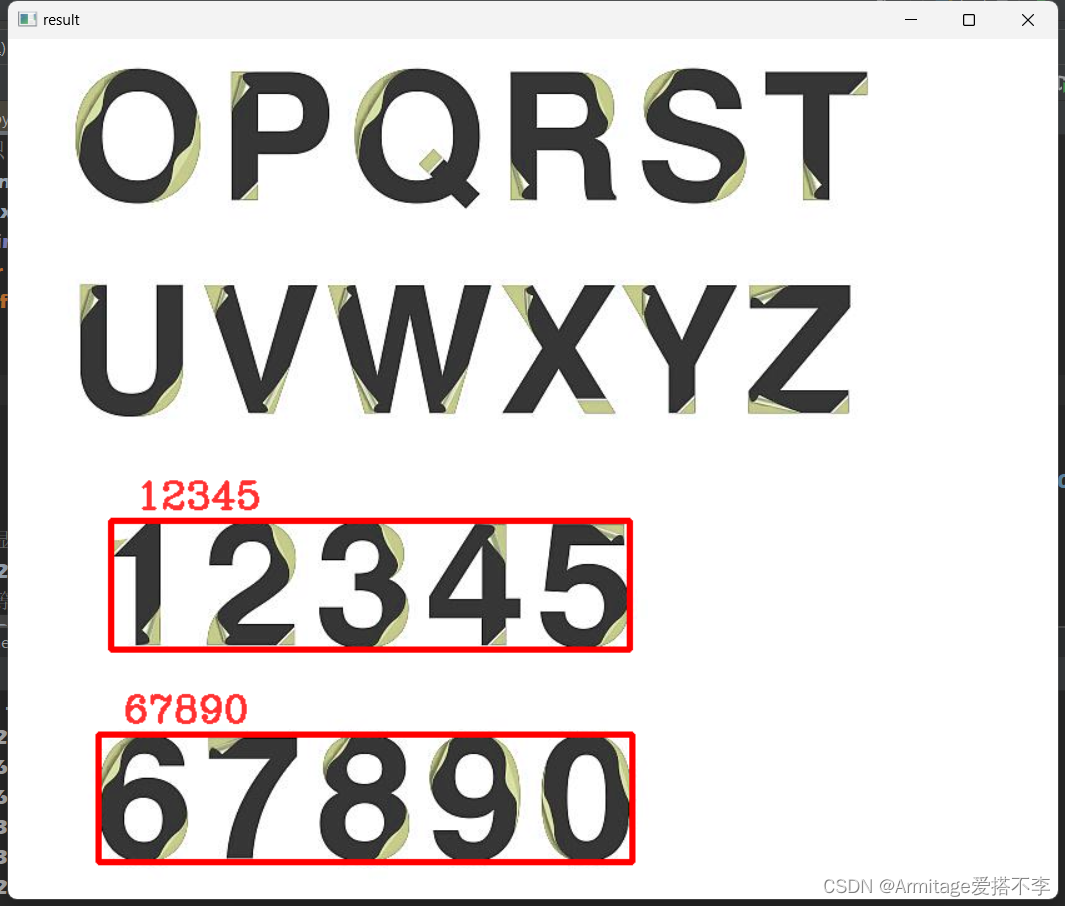
不过最后还是完美解决了,得到了只检测数字的结果
完成了,有兴趣的可以关注一下,近期一直更新,大佬勿喷