在《RabbitMQ实践------交换器(Exchange)和绑定(Banding)》一文中,我们实验了各种交换器。我们可以把交换器看成消息发布的入口,而消息路由规则则是由"绑定关系"(Banding)来定义,最终消息会被路由到"绑定关系"指定的队列中。我们可以把队列看成这个过程的出口。
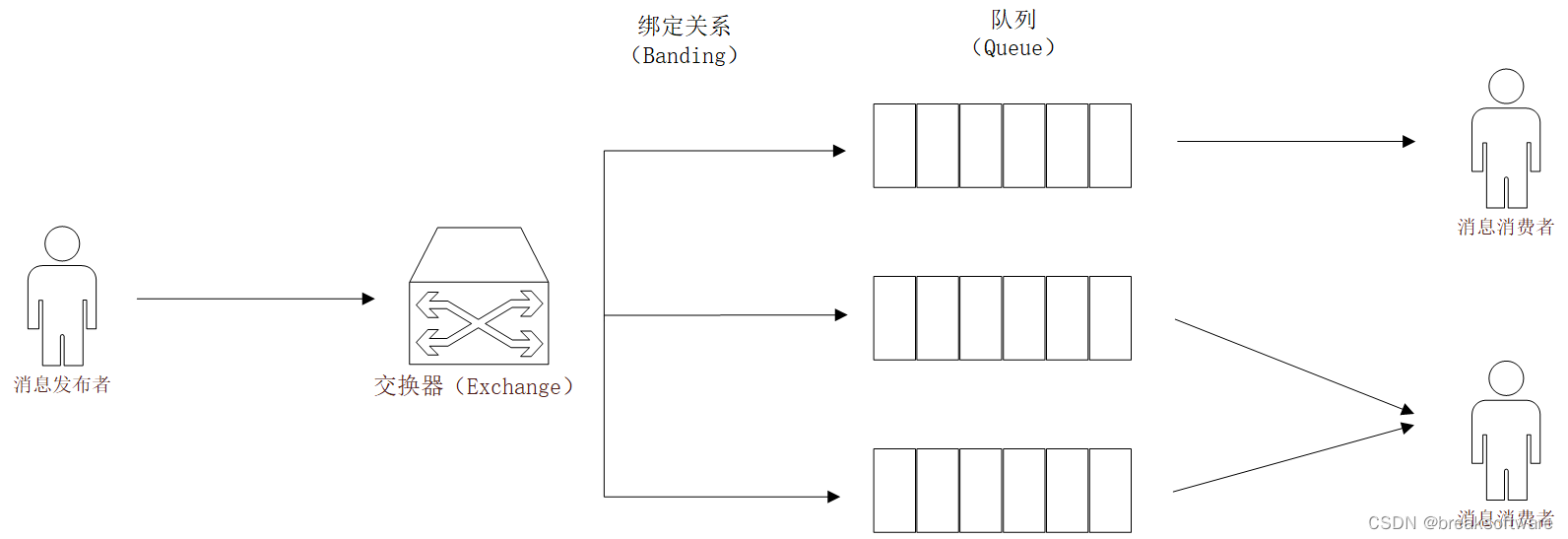
RabbitMQ还实现了一种非常有意思的"绑定关系"(Banding),我们可以让其出口不再是队列,而是另外一个交换器。这样我们就可以通过一批交换器组合出复杂的消息路由关系。

我们可以沿用《RabbitMQ实践------交换器(Exchange)和绑定(Banding)》一文的案例,给amq.direct交换器新增一个绑定关系。

最后形成如下的绑定关系

这样,如果给amq.direct交换器发送的的消息的Routing key是to_all,则消息会被路由到amq.fanout交换器,然后通过它扇出。

这样和amq.fanout绑定的每个队列都会收到该条消息

