1、什么是消息队列
**消息队列:**应用之间传递消息的方式,允许应用程序异步发送和接收消息,不需要连接对方
**消息:**文本字符串,对象....
**队列:**存储数据。先进先出
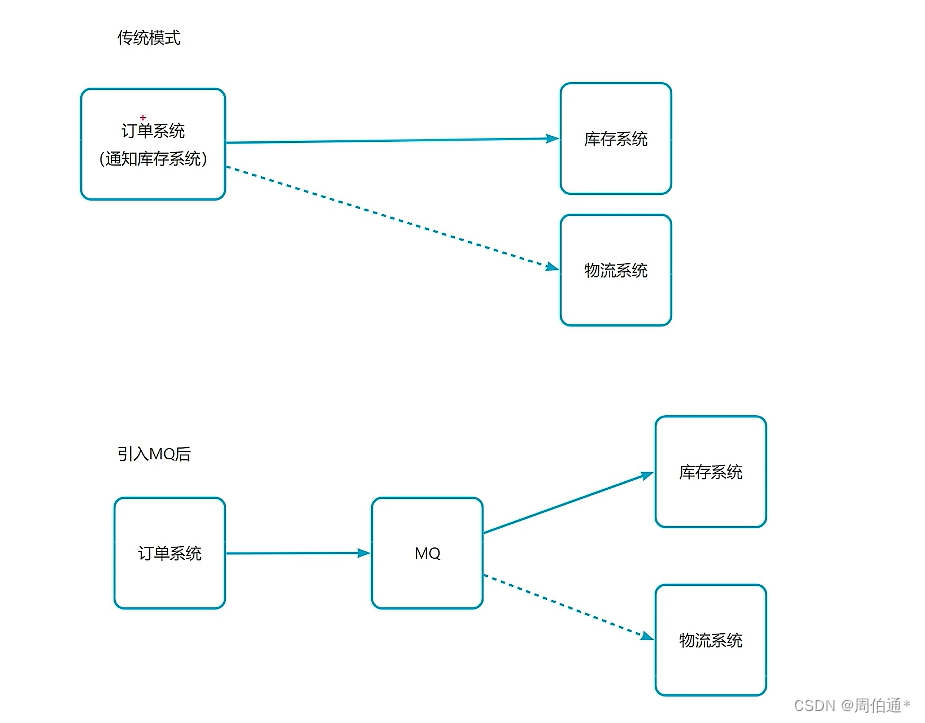
2、应用场景
①库存系统挂掉之后
MQ会等待,等库存系统号之后在发送
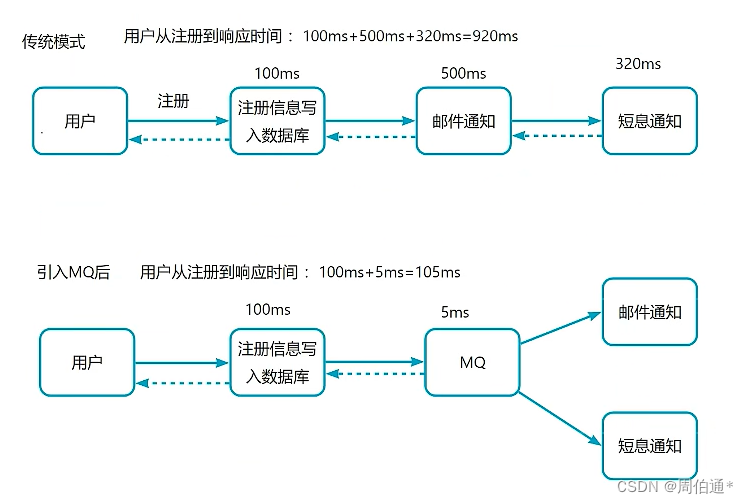
②用户注册到响应
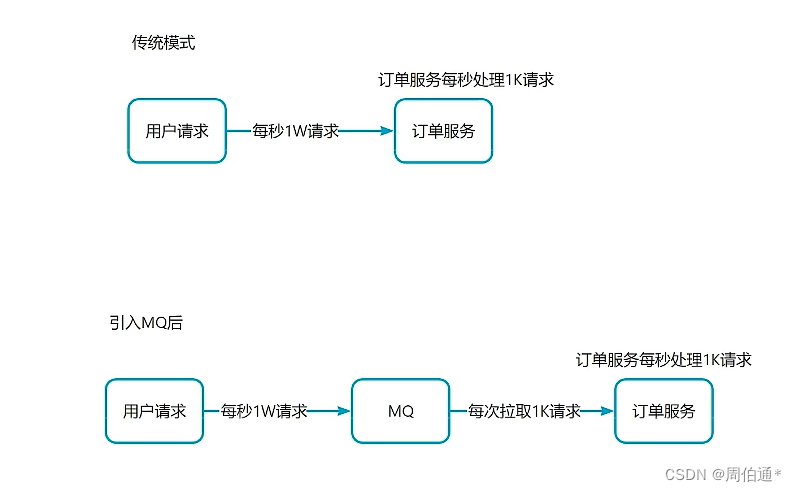
③秒杀场景
3、缺点
①降低系统可用性
系统引入的外部依赖越多,越容易挂掉
②系统复杂度提高
使用MQ之后可能需要保证消息没有被重复消费,处理消息丢失的情况、保证消息传递的顺序性等等。
③一致性问题
A 系统处理完了直接返回成功了,但问题是:要是 B、C、D 三个系统那里,B 和 D 两个系统写库成功了,结果C系统写库失败了,就造成数据不一致了。
4、设置Rabbitmq
①创建用户管理员
sbin目录下输入cmd
添加admin账户
在命令行里面输入命令
rabbitmqctl add_user admin admin
添加玩之后,发现还是登陆不了,为什么呢?
因为不是管理员!!!
那么怎么设置为管理员呢? 很简单,再来一条命令:
rabbitmqctl set_user_tags admin administrator
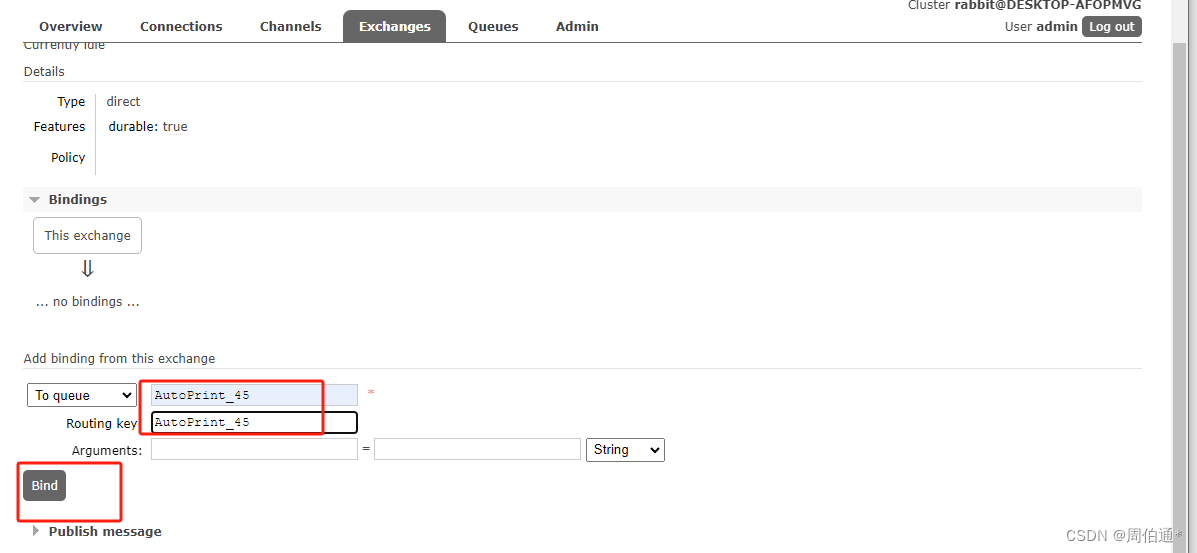
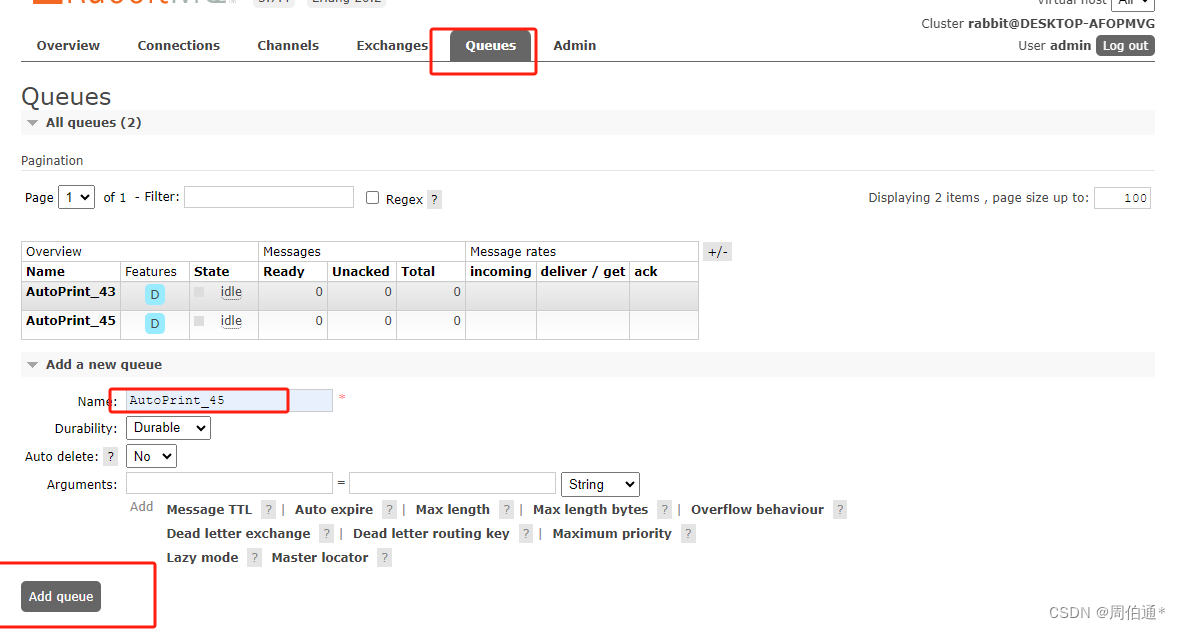
②声明队列
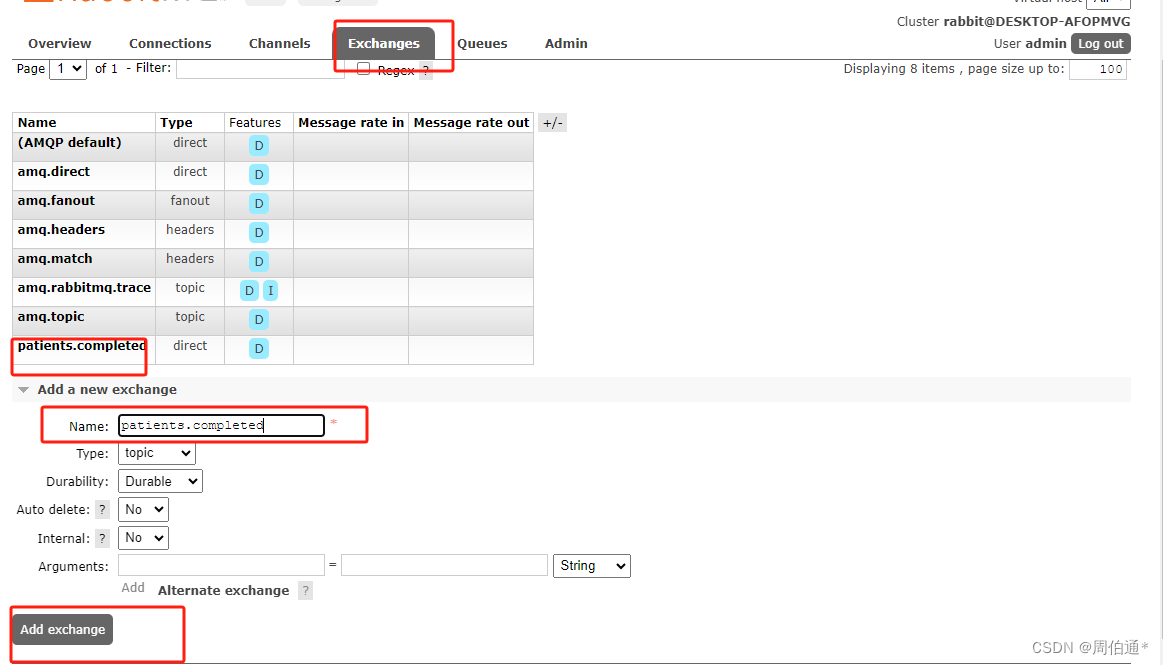
③创建交换机
④队列绑定交换机