torch.nn - PyTorch中文文档 (pytorch-cn.readthedocs.io)
RNN --- PyTorch 2.3 documentation
torch.nn---nn.RNN()
python
nn.RNN(input_size=input_x,
hidden_size=hidden_num,
num_layers=1,
nonlinearity='tanh', #默认'tanh'
bias=True, #默认是True
batch_first=False,
dropout=0,
bidirectional=False #默认为False
)参数说明:
-
input_size -- 输入
x的特征数量。 -
hidden_size -- 隐层的特征数量。
-
num_layers -- RNN的层数。
-
nonlinearity -- 激活函数。指定非线性函数使用
tanh还是relu。默认是tanh。 -
bias -- 是否使用偏置。
-
batch_first -- 如果True的话,那么输入
Tensor的shape应该是batch_size, time_step, feature,输出也是这样。默认是 False,就是这样形式,(seq(num_step), batch, input_dim),也就是将序列长度放在第一位,batch 放在第二位 -
dropout -- 默认不使用,如若使用将其设置成一个0-1的数字即可。如果值非零,那么除了最后一层外,其它层的输出都会套上一个
dropout层。 -
是否使用双向的 rnn,默认是 False
输入输出shape
RNN的输入:input_shape = 时间步数, 批量大小, 特征维度 = num_steps(seq_length), batch_size, input_dim=input (seq_len, batch, input_size)保存输入序列特征的tensor。RNN的隐藏层:h_0 (num_layers * num_directions, batch, hidden_size): 保存着初始隐状态的tensor。RNN的输出: (output, h_n)。 在前向计算后会分别返回输出和隐藏状态h,其中输出指的是隐藏层在各个时间步上计算并输出的隐藏状态,它们通常作为后续输出层的输⼊。- output (seq_len, batch, hidden_size * num_directions) 形状为**(时间步数, 批量大小, 隐藏单元个数)** : 保存着
RNN最后一层的输出特征。如果输入是被填充过的序列,那么输出也是被填充的序列。 - 隐藏状态h的形状为(层数, 批量大小,隐藏单元个数)=h_n (num_layers * num_directions, batch, hidden_size) : 保存着最后一个时刻隐状态。隐藏状态指的是隐藏层在最后时间步的隐藏状态:当隐藏层有多层时,每⼀层的隐藏状态都会记录在该变量中。
RNN模型参数:
-
weight_ih_lk -- 第
k层的input-hidden权重, 可学习,形状是(input_size x hidden_size)。 -
weight_hh_lk -- 第
k层的hidden-hidden权重, 可学习,形状是(hidden_size x hidden_size) -
bias_ih_lk -- 第
k层的input-hidden偏置, 可学习,形状是(hidden_size) -
bias_hh_lk -- 第
k层的hidden-hidden偏置, 可学习,形状是(hidden_size)
计算过程
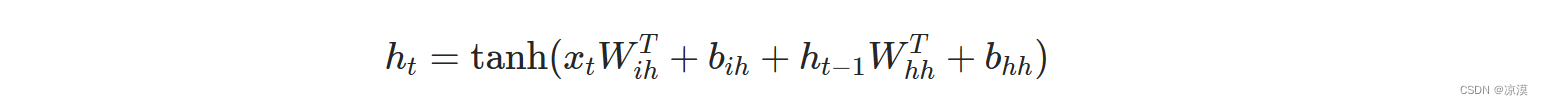 h_t是时刻t的隐状态。
h_t是时刻t的隐状态。
x_t是上一层时刻t的隐状态,或者是第一层在时刻t的输入。
如果nonlinearity='relu',那么将使用relu代替tanh作为激活函数。