目录
- 背景
- 三个经典的缓存模式
-
- Cache-Aside
- Read-Through/Write-Through
- [Write Behind](#Write Behind)
- 方案抉择
背景
-
我们在日常开发中,为了提高数据响应速度,可能会将一些热点数据保存在缓存中,这样就不用每次都去数据库中查询了,可以有效提高服务端的响应速度,那么目前我们最常使用的缓存就是 Redis 了。
-
以电商项目为例,主要有三个主要环节:
- 订单数据和支付流水数据:这两块数据对实时性和精确性要求很高,所以一般是不需要添加缓存的,直接操作数据库即可。
- 用户相关数据:这些数据和用户相关,具有读多写少的特征,所以我们使用 redis 进行缓存。
- 支付配置信息:这些数据和用户无关,具有数据量小,频繁读,几乎不修改的特征,所以我们使用本地内存进行缓存。
-
选中合适的数据存入 Redis 之后,接下来,每当要读取数据的时候,就先去 Redis 中看看有没有,
- 如果有就直接返回;
- 如果没有,则去数据库中读取,并且将从数据库中读取到的数据缓存到 Redis 中,
问题
大致上就是上面这样一个流程,读取数据的这个流程实际上是比较清晰也比较简单的,然而,当数据存入缓存之后,如果需要更新的话,往往会来带另外的问题:
- 当有数据需要更新的时候,先更新缓存还是先更新数据库?
- 如何确保更新缓存和更新数据库这两个操作的原子性?
- 更新缓存的时候该怎么更新?修改还是删除?
思路
正常来说,我们有四种方案:
- 先更新缓存,再更新数据库。
- 先更新数据库,再更新缓存。
- 先淘汰缓存,再更新数据库。
- 先更新数据库,再淘汰缓存。
三个经典的缓存模式
- Cache-Aside
- Read-Through/Write through
- Write Behind
Cache-Aside
- Cache-Aside,中文也叫旁路缓存模式,如果我们能够在项目中采用 Cache-Aside,那么就能够尽可能的解决缓存与数据库数据不一致的问题,注意是尽可能的解决,并无法做到绝对解决。
- Cache-Aside 又分为读缓存和写缓存两种情况,我们分别来看。
读缓存
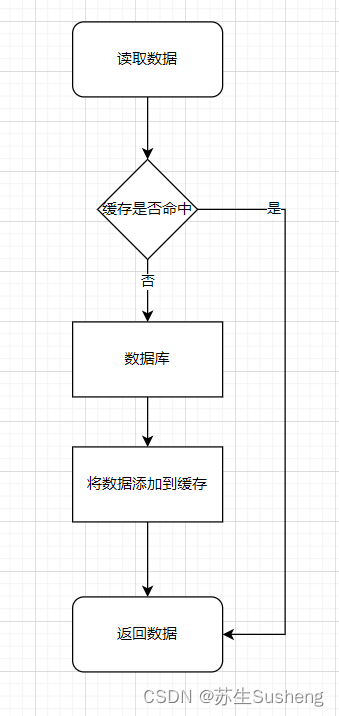
- 其实对于读缓存的流程而言,一般没什么数据影响,有影响的主要是写流程
写缓存
- 流程:写缓存------更新数据------删除旧缓存
- 两个问题:
- 为什么是删除旧缓存而不是更新旧缓存?
- 为什么不先删除旧的缓存,然后再更新数据库?
为什么是删除旧缓存而不是更新旧缓存?
- 更新缓存,说着容易做起来并不容易。很多时候我们更新缓存并不是简简单单更新一个 Bean。很多时候,我们缓存的都是一些复杂操作或者计算(例如大量联表操作、一些分组计算)的结果,如果不加缓存,不但无法满足高并发量,同时也会给 MySQL 数据库带来巨大的负担。那么对于这样的缓存,更新起来实际上并不容易,此时选择删除缓存效果会更好一些。
- 对于一些写频繁的应用,如果按照更新缓存->更新数据库的模式来,比较浪费性能,因为首先写缓存很麻烦,其次每次都要写缓存,但是可能写了十次,只读了一次,读的时候读到的缓存数据是第十次的,前面九次写缓存都是无效的,对于这种情况不如采取先写数据库再删除缓存的策略。
- 在多线程环境下,这样的更新策略还有可能会导致数据逻辑错误,来看如下一张流程图:
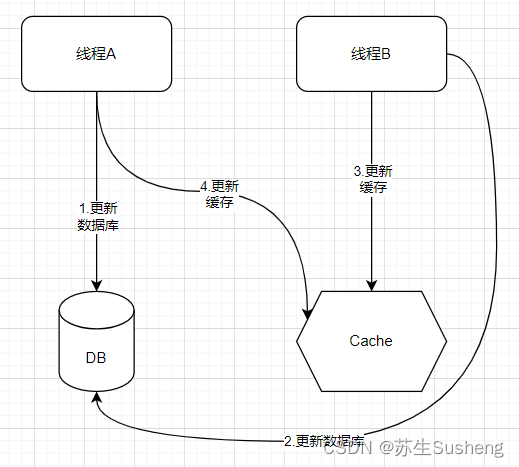
当有两个并发的线程 A 和 B:
- 首先 A 线程更新了数据库。
- 接下来 B 线程更新了数据库。
- 由于网络等原因,B 线程先更新了缓存。
- A 线程更新了缓存。
那么此时,缓存中保存的数据就是不正确的,而如果采用了删除缓存的方式,就不会发生这种问题了。
为什么不先删除旧的缓存,然后再更新数据库?
- 同样考虑到并发请求,假设我们先删除旧的缓存,然后再更新数据库,那么就有可能出现如下这种情况:
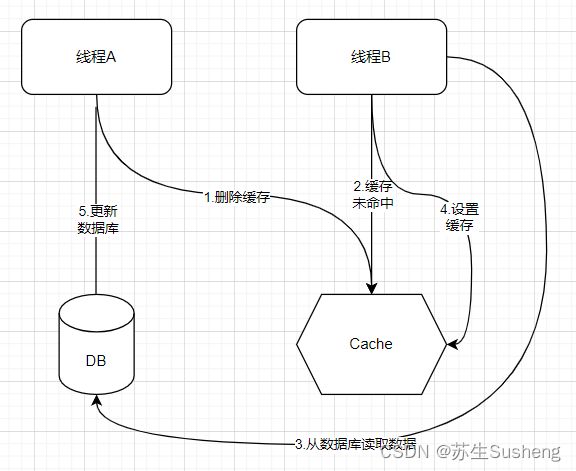
线程A 和 B,其中 A 写数据,B 读数据,具体流程如下:
- A 线程首先删除缓存。
- B 线程读取缓存,发现缓存中没有数据。
- B 线程读取数据库。
- B 线程将从数据库中读取到的数据写入缓存。
- A 线程更新数据库。
一套操作下来,我们发现数据库和缓存中的数据不一致了!所以,在 Cache-Aside 中是先更新数据库,再删除缓存。
延迟双删
-
其实无论是先更新数据库再删除缓存,还是先删除缓存再更新数据库,在并发环境下都有可能存在问题:
- 假设有 A、B 两个并发请求:
- 先更新数据库再删除缓存:当请求 A 更新数据库之后,还未来得及进行缓存清除,此时请求 B 查询到并使用了 Cache 中的旧数据。
- 先删除缓存再更新数据库:当请求 A 执行清除缓存后,还未进行数据库更新,此时请求 B 进行查询,查到了旧数据并写入了 Cache。
- 假设有 A、B 两个并发请求:
-
前面已经分析过了,尽量先操作数据库再操作缓存,但是即使这样也还是有可能存在问题,解决问题的办法就是延迟双删。
-
延迟双删的处理流程:先执行缓存清除操作,再执行数据库更新操作,延迟 N 秒之后再执行一次缓存清除操作,这样就不用担心缓存中的数据和数据库中的数据不一致了。
-
那么这个延迟 N 秒,N 是多大比较合适呢?一般来说,N 要大于一次写操作的时间,如果延迟时间小于写入缓存的时间,会导致请求 A 已经延迟清除了缓存,但是此时请求 B 缓存还未写入,具体是多少,就要结合自己的业务来统计这个数值了。
如何确保原子性
- 其实说到底更新数据库和删除缓存毕竟不是一个原子操作,要是数据库更新完毕后,删除缓存失败了咋办?
- 对于这种情况,一种常见的解决方案就是使用消息中间件来实现删除的重试。众所周知,MQ 一般都自带消费失败重试的机制,当我们要删除缓存的时候,就往 MQ 中扔一条消息,缓存服务读取该消息并尝试删除缓存,删除失败了就会自动重试。
Read-Through/Write-Through
-
Read-Through/Write-Through(读写全程)是一种计算机缓存策略,用于管理内存和磁盘之间的数据传输。
-
在这种策略中,当计算机需要从磁盘读取数据时,它会首先检查缓存中是否存在该数据。
- 如果缓存中有数据,就直接从缓存读取,这称为"读取全程"。
- 如果缓存中没有数据,计算机会从磁盘读取数据,并将数据复制到缓存中,这称为"写入全程"。
-
在写入全程过程中,当计算机更新缓存中的数据时,它会同时将数据写入磁盘,以保持缓存和磁盘中数据的一致性。这样可以确保在缓存中的数据在发生故障时,仍然能够从磁盘中恢复。
-
Read-Through/Write-Through策略的优点是可以确保数据的实时一致性,并且在发生故障时能够快速恢复。
-
然而,由于每次读取操作都要检查缓存,读取性能可能会受到一定影响。
Read-Through
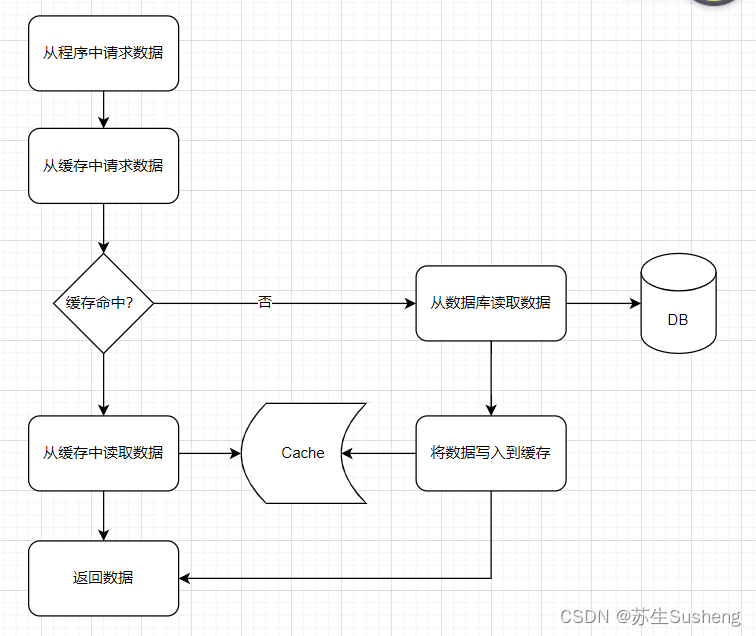
- Read-Through 是一种类似于 Cache-Aside 的缓存方法,区别在于
- 在 Cache-Aside 中,由应用程序决定去读取缓存还是读取数据库,这样就会导致应用程序中出现了很多业务无关的代码;
- 而在 Read-Through 中,相当于多出来了一个中间层 Cache Middleware,由它去读取缓存或者数据库,应用层的代码得到了简化,
- 和 Cache-Aside 相比,其实就相当于是多了一个缓存中间件(处理判断缓存并设置缓存的操作),这样我们在应用程序中就只需要正常的读写数据就行了,并不用管底层的具体逻辑,相当于把缓存相关的代码从应用程序中剥离出来了,应用程序只需要专注于业务就行了。
Write-Through
-
Write-Through 其实也是差不多,所有的操作都交给缓存中间件来完成,应用程序中就是一句简单的更新就行了
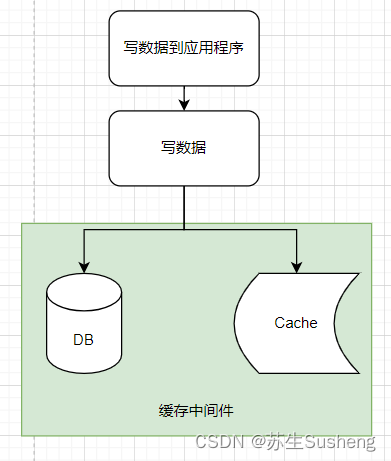
-
在 Write-Through 策略中,所有的写操作都经过 缓存中间件,每次写入时,Cache Middleware 会将数据存储在 DB 和 Cache 中,这两个操作发生在一个事务中,因此,只有两个都写入成功,一切才会成功。
-
这种写数据的优势在于,应用程序只与 缓存中间件 对话,所以它的代码更加干净和简单。
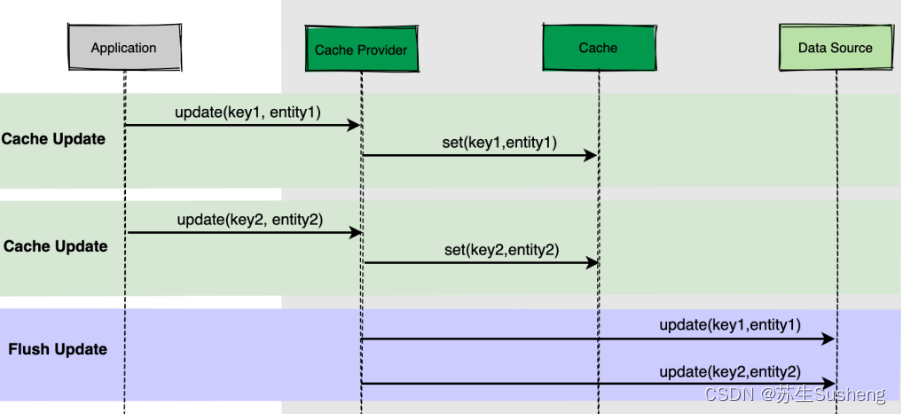
Write Behind
- Write-Behind 缓存策略类似于 Write-Through 缓存,应用程序仅与 缓存中间件 通信,缓存中间件 会预留一个与应用程序通信的接口。
- Write-Behind 与 Write-Through 最大的区别在于,前者是数据首先写入缓存,一段时间后(或通过其他触发器)再将数据写入 Database,并且这里涉及到的写入是一个异步操作。
- 这种方式下,Cache 和 DB 数据的一致性不强,对一致性要求高的系统要谨慎使用
- 如果有人在数据尚未写入数据源的情况下直接从数据源获取数据,则可能导致获取过期数据
- 不过对于频繁写入的场景,这个其实非常适用。
- 将数据写入 DB 可以通过多种方式完成:
- 一种是收集所有写入操作,然后在某个时间点(例如,当 DB 负载较低时)对数据源进行批量写入。
- 另一种方法是将写入合并成更小的批次,例如每次收集五个写入操作,然后对数据源进行批量写入。
流程图如下
方案抉择
在选择具体方式来保证缓存和数据库的一致性时,可以考虑以下几个因素:
-
数据一致性要求:首先,明确应用对数据一致性的要求。如果数据一致性是绝对必要且不可容忍任何差异,那么使用事务是最可靠的选择。如果数据一致性要求较低,可以考虑使用缓存更新策略或消息队列。
-
系统性能需求:考虑应用的性能需求。事务可能会对性能产生较大的影响,因为它需要加锁、提交和回滚等操作。如果应用对性能有较高的要求,可以选择使用缓存更新策略或消息队列,并对缓存的更新进行优化。缓存更新策略可以在写入数据库之前更新缓存,减少数据库访问次数。
-
并发控制:在多线程或分布式环境下,需要考虑并发控制的问题。事务提供了强大的并发控制机制,但也会带来性能开销。如果并发操作较少或可以容忍一定程度的冲突,可以使用缓存更新策略或消息队列。
-
可靠性和容错性:考虑可靠性和容错性。事务通常提供较高的可靠性和容错性,因为它们可以回滚操作以确保数据一致性。缓存更新策略和消息队列需要额外的措施来处理故障或消息丢失的情况,例如使用缓存失效机制或消息重试机制等。
-
开发和维护复杂性:最后,考虑实现和维护所需的复杂性。事务管理着复杂的并发控制和回滚机制,可能需要更多的代码和配置。缓存更新策略和消息队列可能需要额外的逻辑和配置来确保一致性。