Flink 和 SparkStreaming的区别
设计理念方面
SparkStreaming:使用微批次来模拟流计算,数据已时间为单位分为一个个批次,通过RDD进行分布式计算
Flink:基于事件驱动,是面向流的处理框架,是真正的流式计算
架构方面
SparkStreaming:角色包括 Master、Worker、Driver、Executor
Flink:角色包括 Jonmanager、Taskmanager和slot
窗口计算方面
SparkStreaming:只支持基于处理时间的窗口操作
Flink:可以支持时间窗口,也支持基于事件的窗口如滑动、滚动、会话窗口等
时间机制方面
SparkStreaming:只支持处理时间,产生数据堆积时候,处理时间和事件时间误差明显
Flink:支持事件时间、注入时间、处理时间,同事支持watermark机制处理迟到的数据,在处理大乱序的实时数据更有优势
容错机制方面
SparkStreaming:基于RDD或对宽依赖添加CheckPoint,利用 SparkStreaming的 direct方式与kafka保证 exactly once
Flink:基于状态添加CheckPoint,通过俩阶段提交协议来保证 exactly once
吞吐量与延迟方面
SparkStreaming:基于微批次的处理使得吞吐量是最大的 ,但付出了延迟的代价,只能做到秒级处理
Flink:数据是逐条处理,容错机制很轻量级,兼顾了吞吐量的同时又有很低的延迟 ,支持毫秒级处理
Flink 运行时组件
作业管理器(JobManager)
- 控制一个应用程序执行的主进程,也就是说,每个应用程序都会被一个唯一的Jobmanager所控制执行
- Jobmanager会先接收到要执行的应用程序,这个应用程序会包括:作业图( Job Graph)、逻辑数据流图( ogical dataflow graph)和打包了所有的类、库和其它资源的JAR包。
- Jobmanager会把Jobgraph转换成一个物理层面的数据流图,这个图被叫做"执行图" (Executiongraph),包含了所有可以并发执行的任务。Job Manager会向资源管理器(Resourcemanager)请求执行任务必要的资源,也就是任务管理器(Taskmanager)上的插槽slot。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的 Taskmanager上 。而在运行过程中Jobmanagera会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调。
任务管理器(TaskManager)
- Flink中的工作进程。通常在 Flink中会有多个Taskmanager运行,每个Taskmanager都包含了一定数量的插槽(slots) 。插槽的数量限制了Taskmanager能够执行的任务数量。
- 启动之后,Taskmanager会向资源管理器注册它的插槽;收到资源管理器的指令后, Taskmanager就会将一个或者多个插槽提供给Jobmanager调用。Jobmanager就可以向插槽分配任务(tasks)来执行了。
- 在执行过程中,一个Taskmanager可以跟其它运行同一应用程序的Taskmanager交换数据。
资源管理器(ResourceManager)
- 主要负责管理任务管理器(TaskManager)的插槽(slot) Taskmanger插槽是Flink中定义的处理资源单元。
- Flink为不同的环境和资源管理工具提供了不同资源管理器,比如YARN、K8s,以及 standalone部署。
- 当Jobmanager申请插槽资源时,Resourcemanager会将有空闲插槽的Taskmanager分配给Jobmanager。如果 Resourcemanager没有足够的插槽来满足 Jobmanager的请求,它还可以向资源提供平台发起会话,以提供启动 Taskmanager进程的容器。
分发器(Dispatcher)
- 可以跨作业运行,它为应用提交提供了REST接口。
- 当一个应用被提交执行时,分发器就会启动并将应用移交给Jobmanage。
- Dispatcher他会启动一个WebUi,用来方便地展示和监控作业执行的信息。
Flink作业提交流程 on Yarn
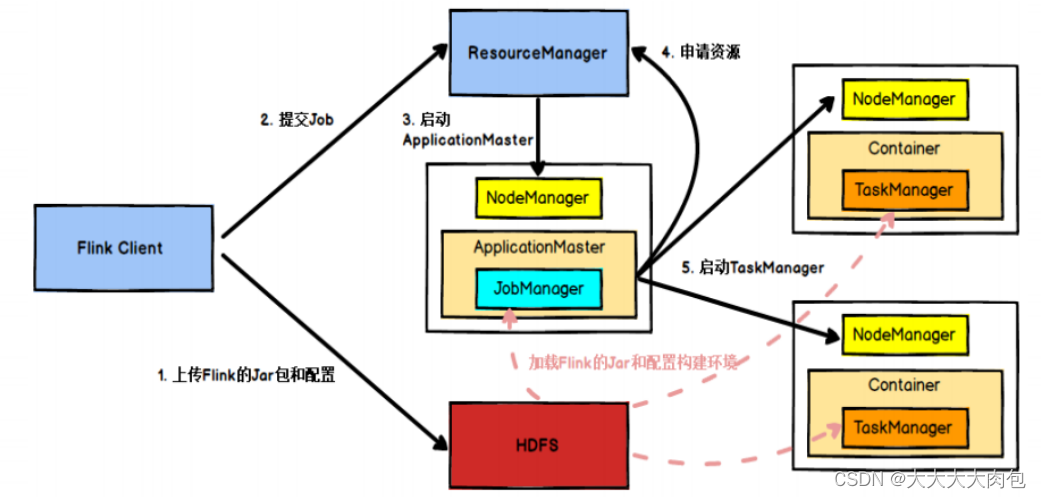
- Flink任务提交后,Client向HDFS上传Flink的Jar包和配置
- 向ResourceManager请求一个YARN容器启动ApplicationMaster,ApplicationMaster启动后加载Flink的Jar包和配置构建环境
- 启动JobManager,JobManager和ApplicationMaster(AM)运行在同一个容器中
- ApplicationMaster向ResourceManager申请启动TaskManager所需资源
- ResourceManager分配Container资源后,由ApplicationMaster通知资源所在节点的NodeManager启动TaskManager
- NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager
- TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务。
Flink的执行图
Flink 中任务调度执行的图,按照生成顺序可以分成四层:
逻辑流图(StreamGraph)→ 作业图(JobGraph)→ 执行图(ExecutionGraph)→ 物理图(Physical Graph)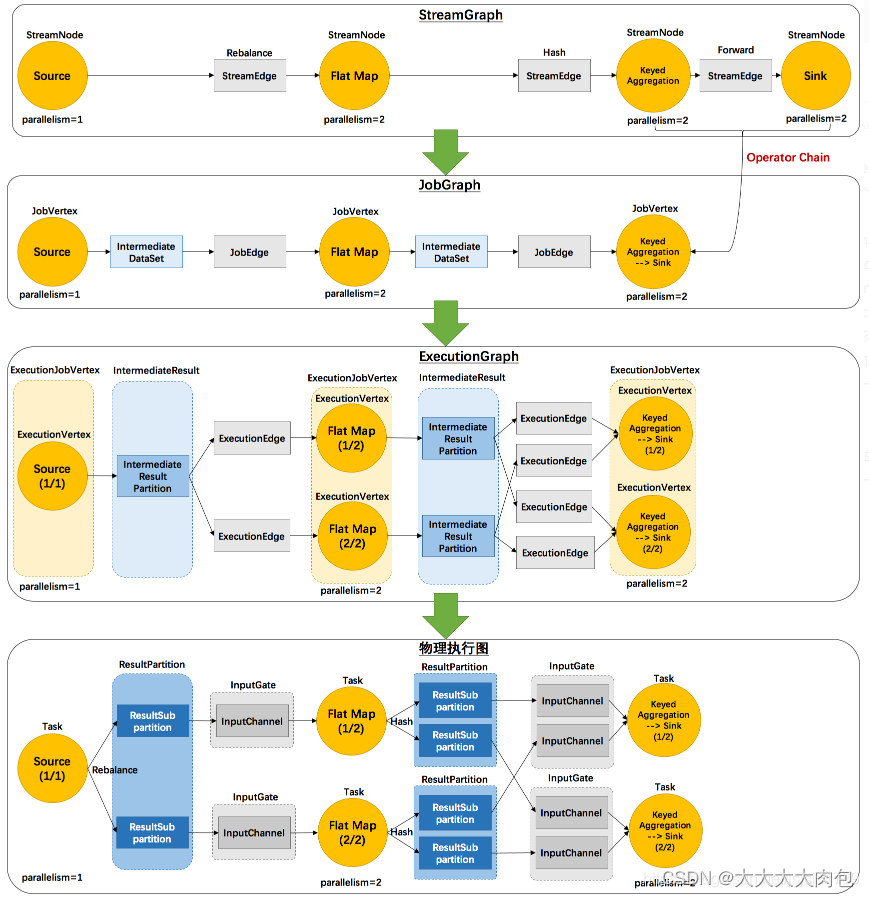
逻辑流图(StreamGraph)
这是根据用户通过 DataStream API 编写的代码生成的最初的 DAG 图 ,用来表示程序的拓扑结构。这一步一般在客户端完成。
作业图(JobGraph)
StreamGraph 经过优化后生成的就是作业图(JobGraph) ,这是提交给 JobManager 的数据结构,确定了当前作业中所有任务的划分。主要的优化为: 将多个符合条件的节点链接在一起合并成一个任务节点,形成算子链 ,这样可以减少数据交换的消耗。JobGraph 一般也是在客户端生成的,在作业提交时传递给 JobMaster。
执行图(ExecutionGraph)
JobMaster 收到 JobGraph 后,会根据它来生成执行图(ExecutionGraph) 。ExecutionGraph是 JobGraph 的并行化版本,是调度层最核心的数据结构。ExecutionGraph 更进一步细化了 JobGraph 中的任务,并考虑了容错、调度等因素。
物理图(Physical Graph)
JobMaster 生成执行图后, 会将它分发给 TaskManager;各个 TaskManager 会根据执行图
部署任务,最终的物理执行过程也会形成一张"图",一般就叫作物理图(Physical Graph) 。
这只是具体执行层面的图,并不是一个具体的数据结构。
Flink中的并行度(Parallelism)
在 Flink 程序执行过程中,每一个算子(operator)可以包含一个或多个子任务 (operator subtask),这些子任务在不同的线程、不同的物理机或不同的容器中完全独立地执行 。每个算子的子任务(subtask)的个数被称之为其并行度 (parallelism)。一般情况下,程序的并行度,可以认为就是其所有算子中最大的并行度。一个程序中,不同的算子可能具有不同的并行度。
任务槽和并行度的关系
- task slot 是静态的概念 ,是指TaskManager具有的并发执行能力,可以通过参数taskmanager.numberOfTaskSlots进行配置;
- 并行度(parallelism)是动态概念,也就是TaskManager运行程序时实际使用的并发能力,可以通过参数parallelism.default进行配置。
- 换句话说,并行度如果小于等于集群中可用slot的总数,程序是可以正常执行的,因为slot不一定要全部占用 ,有十分力气可以只用八分;而如果并行度大于可用slot总数 ,导致超出了并行能力上限,那么心有余力不足,程序就只好等待资源管理器分配更多的资源了。
算子链(Operator Chain)
一个数据流在算子之间传输数据的形式 可以是一对一(one-to-one)的直通 (forwarding)模式 ,也可以是打乱的重分区(redistributing)模式 ,具体是哪一种形式,取决于算子的种类。
一对一直通(One-to-one,forwarding)
数据流维护着分区以及元素的顺序 。source算子读取数据之后,可以直接发送给 map 算子做处理,它们之间不需要重新分区,也不需要调整数据的顺序 。这就意味着 map 算子的子任务,看到的元素个数和顺序跟 source 算子的子任务产生的完全一样,保证着"一对一"的关系。
重分区(Redistributing)
数据流的分区会发生改变 。每一个算子的子任务,会根据数据传输的策略,把数据发送到不同的下游目标任务。例如,keyBy()是分组操作,本质上基于键(key)的哈希值(hashCode)进行了重分区;而当并行度改变时,比如从并行度为 2 的 window 算子,要传递到并行度为 1 的 Sink 算子,这时的数据传输方式是再平衡(rebalance),会把数据均匀地向下游子任务分发出去。
合并算子链
在 Flink 中,并行度相同的一对一(one to one)算子操作,可以直接链接在一起形成一个"大"的任务(task),这样原来的算子就成为了真正任务里的一部分。这样的技术被称为合并算子链。
Flink中的状态
算子状态(Operator State)

Operator State可以用在所有算子上 ,每个算子子任务或者说每个算子实例共享一个状态,流入这个算子子任务的数据可以访问和更新这个状态。
算子状态的实际应用场景不如 Keyed State 多,一般用在 Source 或 Sink 等与外部系统连接
的算子上 ,或者完全没有 key 定义的场景。比如 Flink 的 Kafka 连接器中,就用到了算子状态 。 在我们给 Source 算子设置并行度后,Kafka 消费者的每一个并行实例,都会为对应的主题( topic)维护一个偏移量, 作为算子状态保存起来。
对于 Operator State 来说因为不存在 key,所有数据发往哪个分区是不可预测的;也就是说,当发生故障重启之后,我们不能保证某个数据跟之前一样,进入到同一个并行子任务、访问同一个状态。所以 Flink 无法直接判断该怎样保存和恢复状态,而是提供了 接口,让我们根据业务需求自行设计状态的快照保存(snapshot)和恢复(restore)逻辑。
支持的结构类型
广播状态(BroadcastState):有时我们希望算子并行子任务都保持同一份"全局"状态,用来做统一的配置和规则设定。这时所有分区的所有数据都会访问到同一个状态,状态就像被"广播"到所有分区一样,这种特殊的算子状态,就叫作广播状态(BroadcastState)。
列表状态(ListState)
联合列表状态(UnionListState)
按键分区状态(Keyed State)
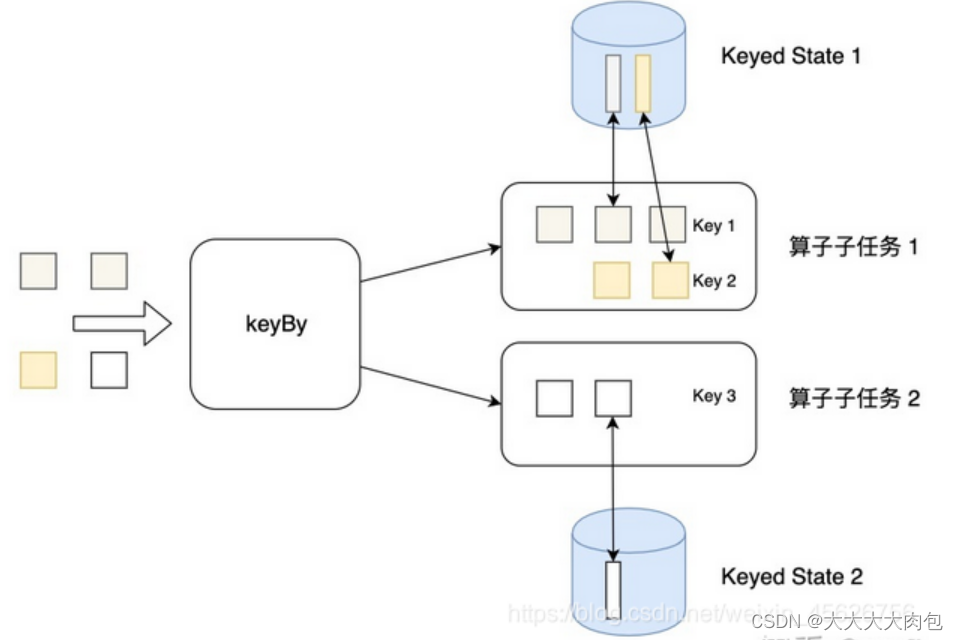
状态是根据输入流中定义的键(key)来维护和访问的,相当于用key来进行物理隔离 ,所以只能定义在按键分区流(KeyedStream)中,也就 keyBy 之后才可以使用。
不同 key 对应的 Keyed State可以进一步组成所谓的键组(key groups),每一组都对应着一个并行子任务。键组是 Flink 重新分配 Keyed State 的单元 ,键组的数量就等于定义的最大并行 度。当算子并行度发生改变时,Keyed State 就会按照当前的并行度重新平均分配,保证运行时各个子任务的负载相同。
支持的结构类型
- 比较常用的:ValueState、ListState、MapState
- 不太常用的:ReducingState 和 AggregationState
Flink的状态持久化checkpoint和savepoint
在Flink流处理应用中的任务都是有状态的,而为了快速访问这些状态一般会直接放在堆内存 里,为了发生故障Flink可以恢复应用的状态 ,就需要对某个时间点所有的状态状态进行持久化 ,而Flink的状态持久化分为俩种,checkpoint和savepoint。
检查点(Checkpoint)
检查点其实就是所有任务的状态在某个时间点的一个快照 。简单来讲,就是一次"存盘",让我们之前处理数据的进度不要丢掉 。在一个 流应用程序运行时,Flink 会定期保存检查点 ,在检查点中会记录每个算子的 id 和状态;如果发生故障,Flink 就会用最近一次成功保存的检查点来恢复应用的状态,重新启动处理流程, 就如同"读档"一样。
ckeckpoint流程
检查点分界线(Barrier)
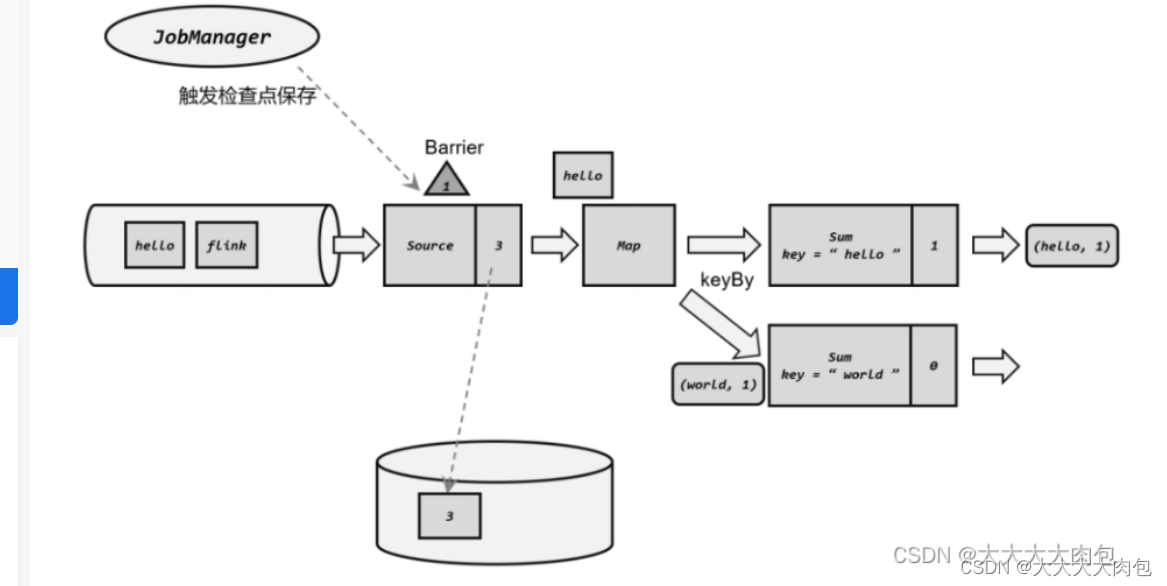
当进行checkpoint时,TaskManager 会让所有的 Source 任务把自己的偏移量(算子状态)保存起来 ,并将带有检查点 ID 的分界线(barrier)插入到当前的数据流 中,然后像正常的数据一样像下游传递 ,之后 Source 任务就可以继续读入新的数据了。
Barrier是种特殊的数据形式 ,把一条流上的数据按照不同的检查点分隔开 ,所以就叫作检查点的"分界线"(Checkpoint Barrier)。当收到Barrier这个特殊数据的时候,当前算子就把当前的状态进行快照 。所以barrier 可以理解为"之前所有数据的状态更改保存入当前检查点"
分布式快照算法
在一条单一的流上,数据依次进行处理,顺序保持不变 ,可是对于处理多个分区的传递时数据的顺序就会出现乱序的问题。
算法的核心就是两个原则:
- 当上游任务向多个并行下游任务发送 barrier 时,需要广播出去;
- 而当多个上游任务向同一个下游任务传递 barrier 时 ,需要在下游任务执行"分界线对齐"(barrier alignment)操作,也就是需要等到所有并行分区的 barrier 都到齐,才可以开始状态的保存。
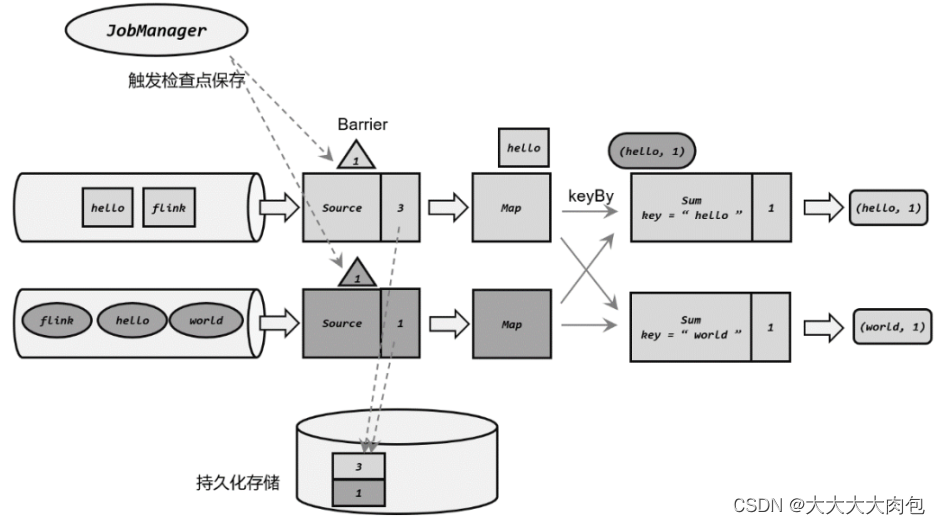
检查点保存的算法具体过程如下:
- JobManager 会周期性地向每个 TaskManager 发送一条带有新检查点 ID 的消息 ,通过这种方式来启动检查点 。收到指令后,TaskManger 会在所有 Source 任务中插入一个分界线(barrier),并将偏移量保存到远程的持久化存储中;
- 状态存入持久化存储之后,会返回通知给 Source 任务 。Source 任务就会向 JobManager 确认检查点完成,然后像数据一样把 barrier 向下游任务传递;
- Map 任务没有状态,所以直接将 barrier 继续向下游传递 。这时由于进行了 keyBy 分区, 所以需要将 barrier 广播到下游并行的两个 Sum 任务 。同时,Sum 任务可能收到来自上游两个并行 Map 任务的 barrier,所以需要执行"分界线对齐"操作;
- 各个分区的分界线都对齐后 ,就可以对当前状态做快照 ,保存到持久化存储了。存储完成之后,同样将barrier 向下游继续传递,并通知 JobManager 保存完;
- 应用程序的所有任务的状态保存完成 ,将各个状态组成一个完整的快照(相当于很多碎片组成一个完整的拼图),本次检查点已完成。
注意 :分界线对齐要求先到达的分区做缓存等待,一定程度上会影响处理的速度。当出现背压( backpressure )时,下游任务会堆积大量的缓冲数据,检查点可能需要很久才可以保存完毕;
分界线对齐
当有多个数据流输入的情况下 ,假设有三个输入流a、b、c,首先从a中接收到了barriers n,但是b/c的barriers n还没到,如果他继续处理a流的barriers n后面的数据,就会导致在处理b/c的barriers n的数据的同时,还会处理了a的barriers n+1的数据 ,计算状态会混在一起,这个checkpoint也就不合理了,所以要等b、c的barriers n到了,再进快照,这个等待所有分界线到达的过程,称为"分界线对齐"(barrier alignment)
任务从检查点恢复状态步骤
- 重启应用 :遇到故障之后,第一步当然就是重启。我们将应用重新启动后,所有任务的状态会清空;
- 读取检查点,重置状态:找到最近一次保存的检查点,从中读出每个算子任务状态的快照,分别填充到对应的状态 中。这样,Flink 内部所有任务的状态,就恢复到了保存检查点的那一时刻;
- 重放数据 :为了不丢数据,我们应该从保存检查点后开始重新读取数据,这可以通过 Source 任务向外部数据源重新提交偏移量(offset)来实现;
- 继续处理数据:接下来,我们就可以正常处理数据了;
保存点(savepoint)
保存点在原理和形式上跟检查点完全一样 ,也是状态持久化保存的一个快照;区别在于,保存点是自定义的镜像保存 ,所以不会由 Flink 自动创建,而需要用户手动触发。这在有计划地停止、重启应用时非常有用。
状态后端
在 Flink 中,状态的存储、访问以及维护,都是由一个可插拔的组件决定的 ,这个组件就 叫作状态后端(state backend)。状态后端主要负责两件事:一是本地的状态管理,二是将检查点(checkpoint)写入远程的持久化存储 。
状态后端是一个"开箱即用"的组件,可以在不改变应用程序逻辑的情况下独立配置。 Flink 中提供了两类不同的状态后端,一种是"哈希表状态后端"(HashMapStateBackend ),另 一种是**"内嵌 RocksDB 状态后端"(EmbeddedRocksDBStateBackend)** 。如果没有特别配置, 系统默认的状态后端是 HashMapStateBackend。
哈希表状态后端(HashMapStateBackend)
这种方式就是我们之前所说的,把状态存放在内存里 。具体实现上,哈希表状态后端在内
部会直接把状态当作对象(objects),保存在 Taskmanager 的 JVM 堆(heap)上 。普通的状态, 以及窗口中收集的数据和触发器(triggers),都会以键值对(key-value)的形式存储起来,所 以底层是一个哈希表(HashMap),这种状态后端也因此得名。
HashMapStateBackend 是将本地状态全部放入内存的,这样可以获得最快的读写速度,使
计算性能达到最佳,代价则是内存的占用。
内嵌 RocksDB 状态后端(EmbeddedRocksDBStateBackend)
RocksDB 是一种内嵌的 key-value 存储介质,可以把数据持久化到本地硬盘 。配置 EmbeddedRocksDBStateBackend 后,会将处理中的数据全部放入 RocksDB 数据库中RocksDB
默认存储在 TaskManager 的本地数据目录里。数据被存储为序列化的字节数组(Byte Arrays),读写操作需要序列化/反序列化,因此状态的访问性能要差一些。
由于它会把状态数据落盘,而且支持增量化的检查点,所以在状态非常大、窗口非常长、
键/值状态很大的应用场景中是一个好选择,同样对所有高可用性设置有效。