一、智谱API
申请和使用
登录智谱AI开放平台,点击右上角的开发者工作台,然后查看自己的API
glm-4 接口
conda create -n zhipuai python==3.10 -y二、如何使用
这边的介绍是根据官方文档的接口文档来进行介绍。
首先先安装SDK包
pip install zhipuai -i https://pypi.mirrors.ustc.edu.cn/simple 如之前安装过,需要更新的请输入下面这行命令
pip install --upgrade zhipuai1、同步调用(调用后即可一次获得最终结果)
from zhipuai import ZhipuAI
client = ZhipuAI(api_key="") # 填写自己的APIKey
response = client.chat.completions.create(
model="glm-4", # 填写需要调用的模型名称
messages=[
{"role": "user", "content": "作为一名营销专家,请为我的产品创作一个吸引人的slogan"},
{"role": "assistant", "content": "当然,为了创作一个吸引人的slogan,请告诉我一些关于您产品的信息"},
{"role": "user", "content": "智谱AI开放平台"},
{"role": "assistant", "content": "智启未来,谱绘无限一智谱AI,让创新触手可及!"},
{"role": "user", "content": "创造一个更精准、吸引人的slogan"}
],
)
print(response.choices[0].message)2、实际
python zhipuai01.py
from zhipuai import ZhipuAI
client = ZhipuAI(api_key="") # 填写您自己的APIKey
while True:
prompt = input("user:")
response = client.chat.completions.create(
model="glm-4", # 填写需要调用的模型名称
messages=[
{"role": "user", "content": prompt}
],
)
answer = response.choices[0].message.content
print("ZhipuAI:",answer)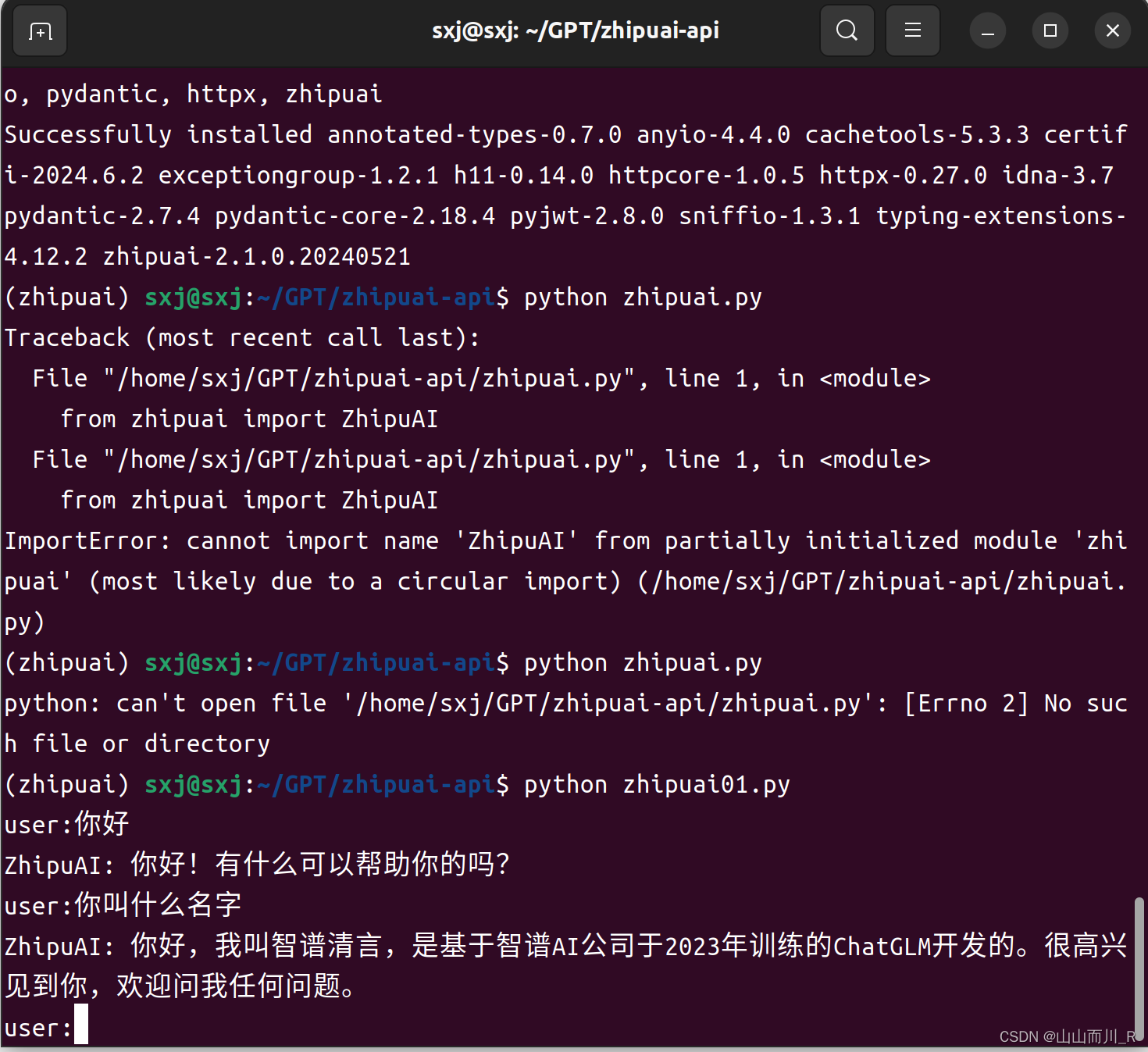
接口请求参数
|-------------|-----------------|---|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| model | String | 是 | 所要调用的模型编码 |
| messages | List<Object> | 是 | 调用语言模型时,将当前对话信息列表作为提示输入给模型, 按照 {"role": "user", "content": "你好"} 的json 数组形式进行传参; 可能的消息类型包括 System message、User message、Assistant message 和 Tool message。 |
| request_id | String | 否 | 由用户端传参,需保证唯一性;用于区分每次请求的唯一标识,用户端不传时平台会默认生成。 |
| do_sample | Boolean | 否 | do_sample 为 true 时启用采样策略,do_sample 为 false 时采样策略 temperature、top_p 将不生效。默认值为 true。 |
| stream | Boolean | 否 | 使用同步调用时,此参数应当设置为 fasle 或者省略。表示模型生成完所有内容后一次性返回所有内容。默认值为 false。 如果设置为 true,模型将通过标准 Event Stream ,逐块返回模型生成内容。Event Stream 结束时会返回一条data: DONE消息。 注意:在模型流式输出生成内容的过程中,我们会分批对模型生成内容进行检测,当检测到违法及不良信息时,API会返回错误码(1301)。开发者识别到错误码(1301),应及时采取(清屏、重启对话)等措施删除生成内容,并确保不将含有违法及不良信息的内容传递给模型继续生成,避免其造成负面影响。 |
| temperature | Float | 否 | 采样温度,控制输出的随机性,必须为正数 取值范围是:(0.0, 1.0),不能等于 0,默认值为 0.95,值越大,会使输出更随机,更具创造性;值越小,输出会更加稳定或确定 建议您根据应用场景调整 top_p 或 temperature 参数,但不要同时调整两个参数 |
| top_p | Float | 否 | 用温度取样的另一种方法,称为核取样 取值范围是:(0.0, 1.0) 开区间,不能等于 0 或 1,默认值为 0.7 模型考虑具有 top_p 概率质量 tokens 的结果 例如:0.1 意味着模型解码器只考虑从前 10% 的概率的候选集中取 tokens 建议您根据应用场景调整 top_p 或 temperature 参数,但不要同时调整两个参数 |
| max_tokens | Integer | 否 | 模型输出最大 tokens,最大输出为8192,默认值为1024 |
| stop | List | 否 | 模型在遇到stop所制定的字符时将停止生成,目前仅支持单个停止词,格式为["stop_word1"] |
| tools | List | 否 | 可供模型调用的工具。默认开启web_search ,调用成功后作为参考信息提供给模型。注意:返回结果作为输入也会进行计量计费,每次调用大约会增加1000 tokens的消耗。 |
| tool_choice | String 或 Object | 否 | 用于控制模型是如何选择要调用的函数,仅当工具类型为function时补充。默认为auto,当前仅支持auto |
| user_id | String | 否 | 终端用户的唯一ID,协助平台对终端用户的违规行为、生成违法及不良信息或其他滥用行为进行干预。ID长度要求:最少6个字符,最多128个字符。 了解更多 |