YOLO 的全称是 You Only Look Once,是一种单阶段(one-stage)的目标检测算法。其核心思想是将目标检测任务作为一个回归问题来处理,只需"看"一次图像(通过一个神经网络)就能预测出图像中所有目标的边界框和类别概率。
yolov3前置知识:
1.目标检测:
目标检测是计算机视觉的一个非常重要的核心方向,它的主要任务主要包括两个即目标分类 和目标定位
即:我们需要知道,我这张图片中的事物,是什么,判断出他的类别后我们还需要框出这个事物的具体位置在哪里:

"是什么","在哪里"的问题我们可以用我们之前学的卷积神经网路CNN很好的解决,
但是在解决问题之前,我们必须定义一些基础的出发点:
1.如何定义位置?:
我这里只介绍我们在YOLO里所要用到的位置的表达方式:
即:用一个中心点(x_center, y_center, w, h)来表示图像中物体的中心,用w, h来表示以(x_center, y_center, w, h)为中心点的矩形的高度和宽度:
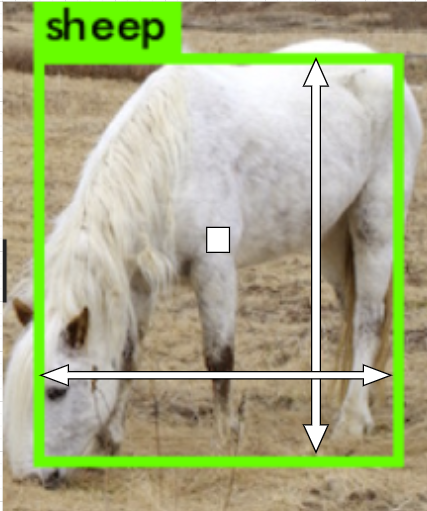
如图所示:我们通过中心点的像素和宽高就可以判断图像的位置
2.COCO数据集:
COCO 数据集 因其规模大、标注质量高、任务多样而成为计算机视觉领域的事实标准基准。它极大地推动了目标检测、分割等相关领域的发展,几乎所有最先进的模型都会在 COCO 数据集上报告其性能以进行比较。对于任何从事相关领域研究和应用的人来说,熟悉和使用 COCO 数据集都是必不可少的

COCO 使用 JSON 文件格式来组织所有标注信息。其结构非常清晰但略微复杂,主要包含以下顶级字段:
-
images: 图像信息列表(id, file_name, width, height等)。 -
annotations: 最重要的字段,包含所有实例的标注信息(类别id、分割多边形、边界框、面积、是否拥挤、对应图像id等)。 -
categories: 类别信息列表(id, name, 对于关键点任务还有关键点名称和骨架连接关系)。
官方提供了完善的 Python API (pycocotools) 来帮助用户轻松地加载、解析和可视化这些标注数据
3.resnet 残差网络
ResNet的核心目标就是 :让超深的网络至少能不差于较浅的网络 。换言之 ,解决网络退化问题 。ResNet 的内容我之前的博客有写到:ResNet(详细易懂解释):残差网络的革命性突破
没有学习ResNet 的宝子不必担心,我们可以先往下去学,回来再补充这个知识点
YOLOV3 算法:
直接上图肯定会路易十六抬手----摸不着头脑

不急,我将逐步把这个网络和网络背后的原理刨析出来
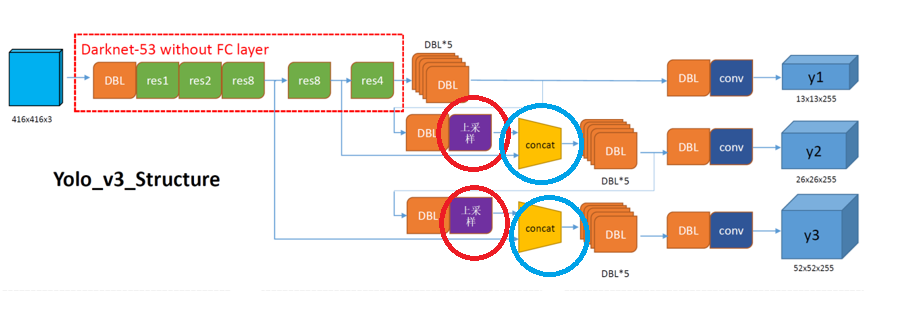
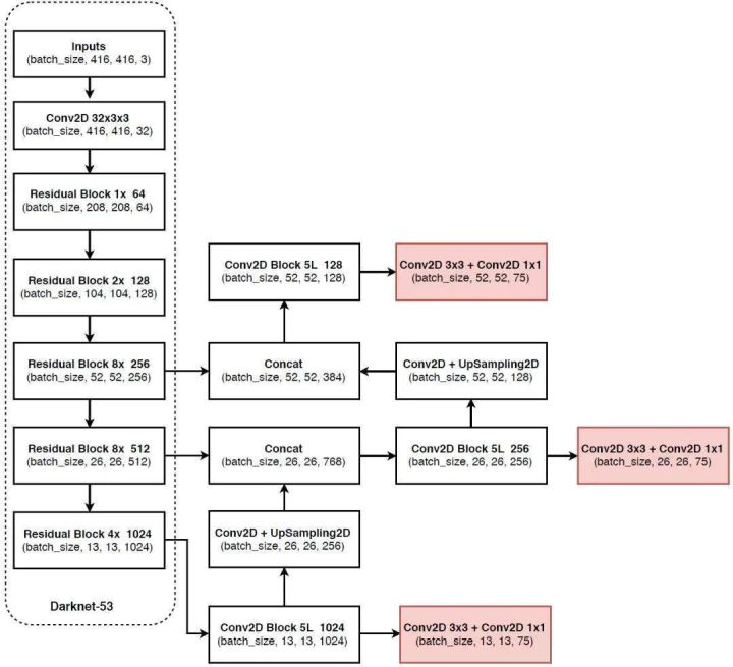
1.网络结构分析:
如果你还不清楚YOLOV3讲的什么,别着急,我们可以先站在表面,先吧YOLOV3 的框架看一遍,
当你了解了这里面的框架后,我们再讲原理:(所以我们现在先把下面这张图的框架认清)
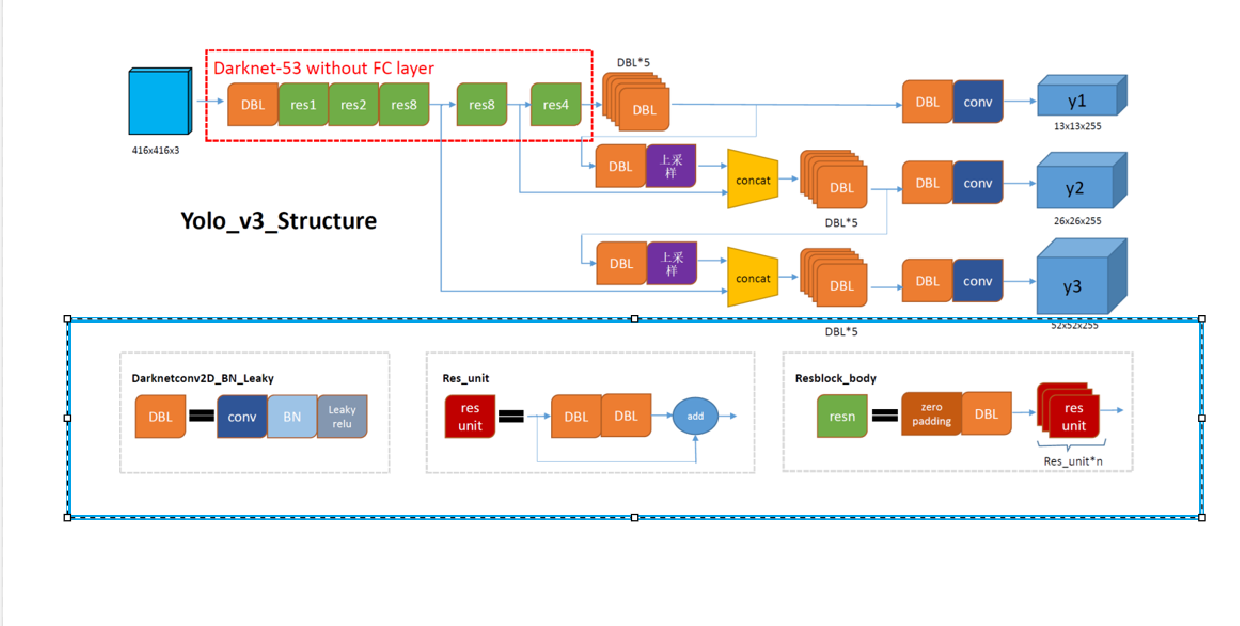
首先看图上的几个基本组件:(蓝色框住的部分)
DBL(Darknet2D_BN_Leaky):该结构由Darknet的卷积层 、批归一化(BN) 和LeakyReLU激活函数组成。在YOLOv3中,除了最后一层卷积层外,BN与LeakyReLU已成为卷积层的标配组件,共同构成网络的基础单元
ResUnit:YOLOv3借鉴了ResNet的残差结构,主干网络中使用了5个resn结构(n代表数字,如res1,res2,...,res8)。这允许网络结构更深,同时缓解梯度消失问题。
resblock_body(也就是图中的res n (res 1, res 2......)) :zero-padding +DBL +n 个ResUnit
层数结构具体分析
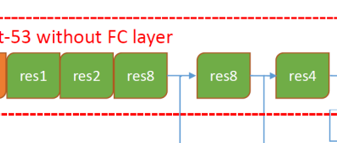
YOLOv3的整体网络结构(Yolo_body)包含252层:这些层分别为:
1.Res_unit层+add
- 23(1+2+8+8+4)个Res_unit ,对应23个add层
2.BN+LeakyReLU
-
72层BN层 和72层LeakyReLU层(每层BN后接一层LeakyReLU):"72"怎么来的?:下面我为大家计算一下:首先这个计算过程分为2部分:
-
第一部分:Darknet-53主干网络
-
第二部分:检测头网络(FPN结构)
-
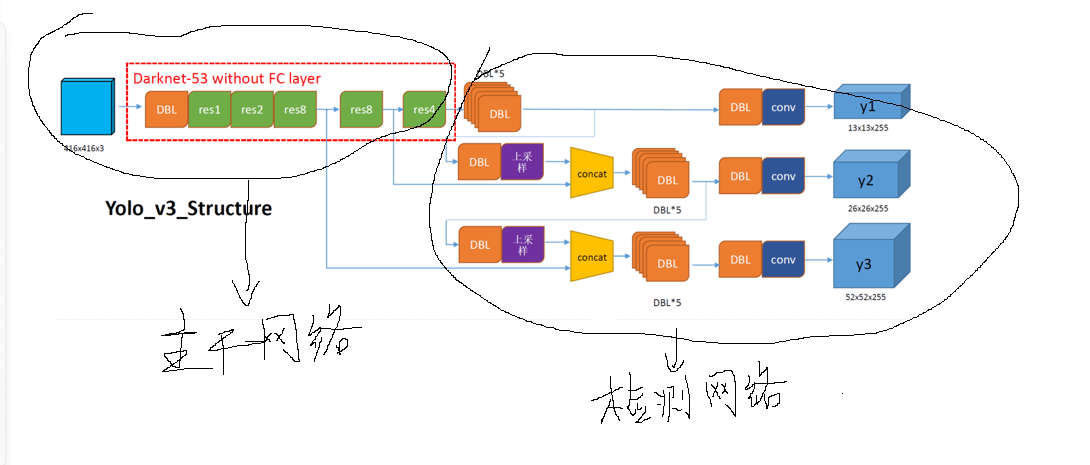
1.主干网络计算:
计算过程:
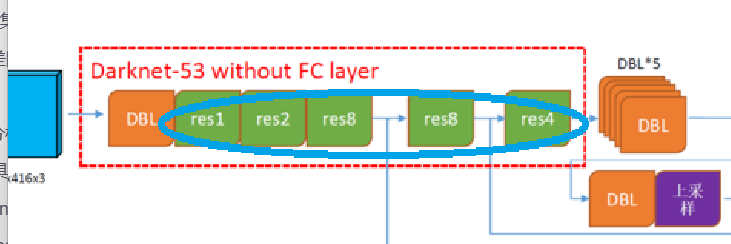
1.主干网络(Darknet-53 without FC layer)的DBL层数:
1+1+2+1+4+1+16+1+16+1+8 = 52个DBL:

根据上述计算流程,网络首先通过一个3×3的卷积层(DBL结构) ,该卷积层包含32个通道,步长为1。接着进入Res1模块 ,其中包含一个零填充层(Zero Padding)。完成填充后,网络通过第二个卷积层 ,该层采用3×3卷积核、64个通道和步长2的设置。随后进入Res Unit模块 ,该模块包含两个DBL层(如先前分析所示)和一个加法操作。
后续处理流程相似:网络先进入Res n模块,其中包含零填充层和卷积层;然后转入Res Unit模块,同样包含两个DBL层结构
2.检测头网络计算:
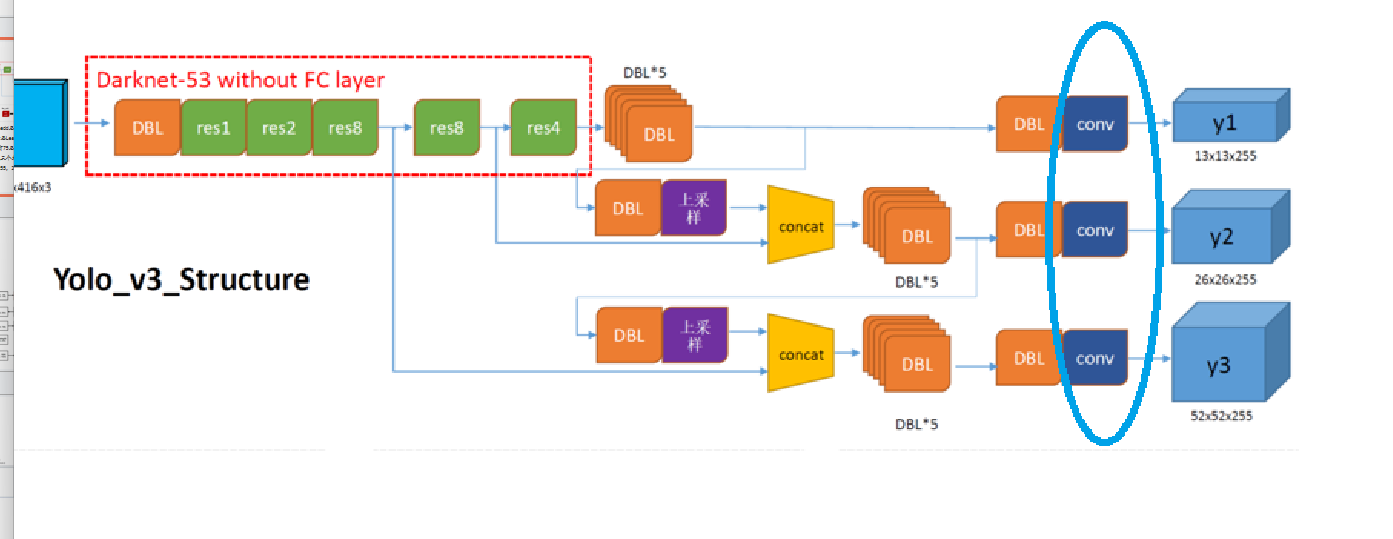
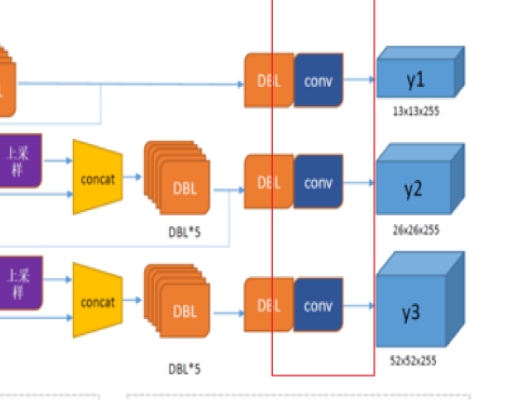
第一个检测尺度(y1 - 13×13)路径:
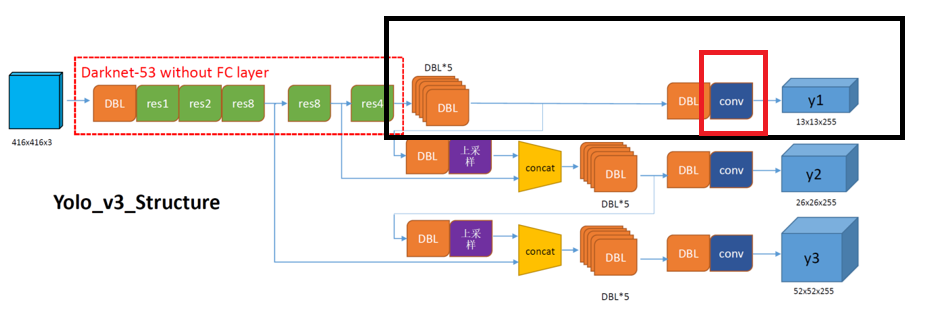
6个DBL → 6个DBL(如图黑色框里面)
输出卷积层(红色实线框)(无BN/LeakyReLU) → 0个DBL第二个检测尺度(y2 - 26×26)路径:
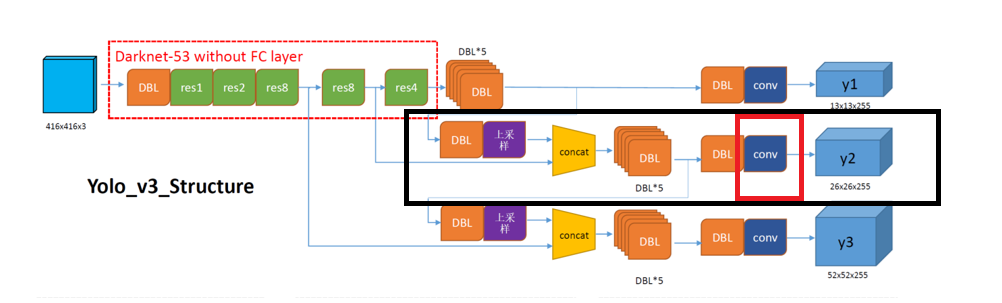
上采样 → 无DBL
1个DBL(上采样后的卷积) → 1个DBL
Concat操作 → 无DBL
6个DBL → 6个DBL
输出卷积层(无BN/LeakyReLU) → 0个DBL(上图红色实线框)第三个检测尺度(y3 - 52×52)路径:
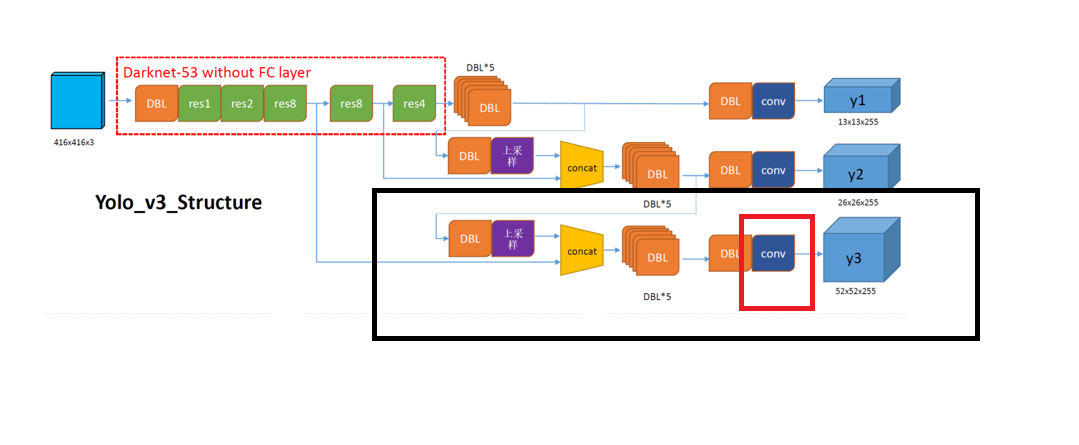
上采样 → 无DBL
1个DBL(上采样后的卷积) → 1个DBL
Concat操作 → 无DBL
6个DBL → 6个DBL
输出卷积层(无BN/LeakyReLU) → 0个DBLSO,检测头网络DBL总数 :6 + 1 + 6 + 1 + 6 = 20个DBL
3.其他:
相信你听了我上面对层数的统计,对整个网络有了大致的理解那么下面的层数的计算相比也清楚了
- 2个上采样操作和2个张量拼接操作
- 5个零填充对应5个res_block
零填充在resblock 里面(不清楚的话看咱们上面的对resn 的介绍)
- 75个卷积层,其中72层后面接BN和LeakyReLU构成的DBL
我们这里在之前算的72个DBL的基础上加了3个全连接卷积:
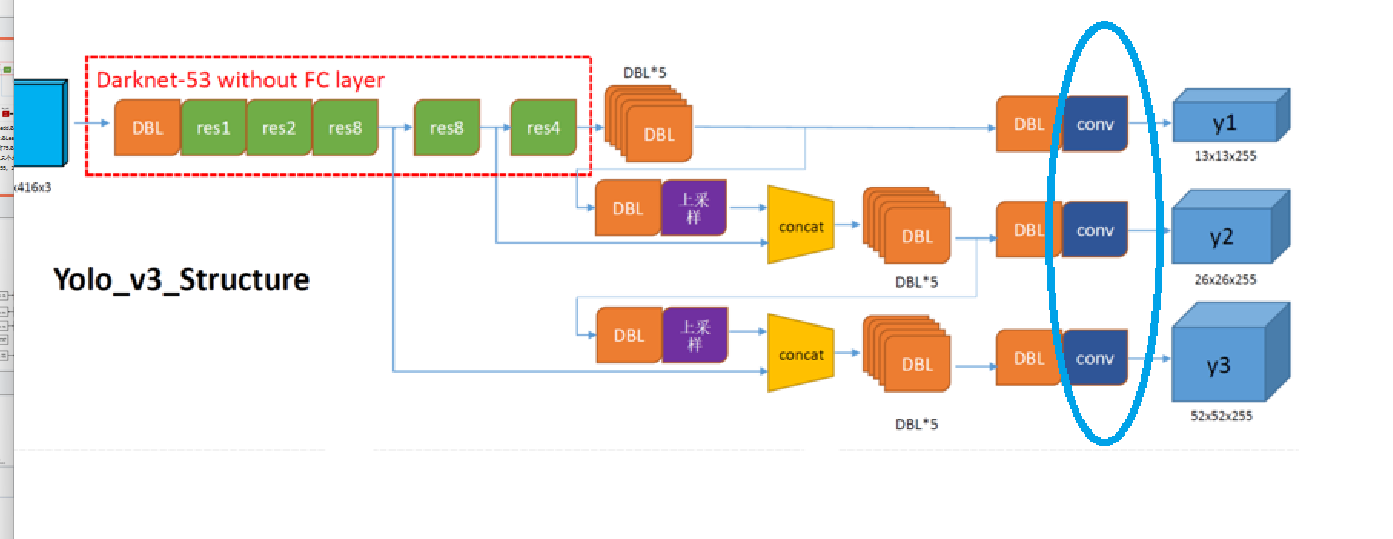
- 3个不同尺度的输出对应3个卷积层
4.总体框架再次总结:
YOLOV3 原理:
刚刚我们研究了YOLOV3 的基本框架:我们想必会有很多疑惑:
1.为啥我们的网络架构在主干网络之后,要分成三个分支来得到三个输出:y1,y2,y3呢?
2.第二个需要解决的问题是:如何理解训练得到的三个输出(y1,y2,y3)的含义?
而且,我们知道,在目标检测任务中,我们需要检测出物体的类别 及其位置(通过边界框标注) 。因此,模型的输出必须包含两类关键信息:一是物体类别,二是物体位置坐标。那么,这些信息具体应该如何体现在输出(y1,y2,y3)中呢?
3.接下来我们需要解决一个更关键的问题:我们通过卷积神经网络可以逐层提取特征并识别类别,这容易理解。但问题是,物体的框(检测框)如何进行反向传播?这些框的参数该如何训练呢?
那么接下来我们来介绍YOLOV3的原理:
首先我们之前的网络结构图可以简化为下面的图像:
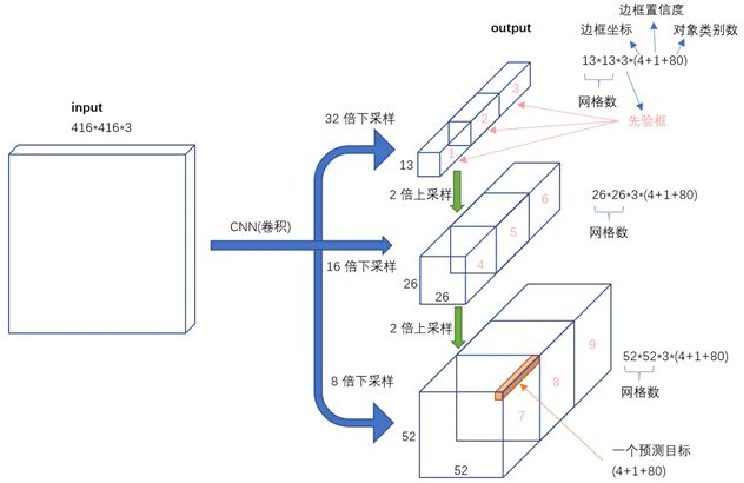
我们知道,我们的这个图像要检测这个图,经过主干网络和检测,网络之后被输出为三个检测图,y1,y2,y3。其中,这三个检测结果的尺寸分别为13×13,26×26,52×52,为什么要输出为三个呢?
这个很好理解,因为我们检测的目标可能是大目标或者是小目标,针对于大目标和小目标,如果都放在同一个检测输出下是十分不合适的,我们现在要做的就是针对大目标,我们可以有一个适合大目标的检测,输出来把它框住。针对于小目标,我们可以有一个更精确的一个检测输出

如图所示,在检测较大目标如一只狗时,我们可以使用13×13的检测框来完整框住目标。但对于图中更细小的物体,由于目标尺寸可能小于13×13的检测框,此时就需要采用更精确的52×52检测框来进行识别和定位。
OK ,那么我们已经知道我们要分成三个输出了,既然需要分成三个输出,我们有必要重新梳理一下网络结构。
让我们回顾一下我们是如何通过主干网络处理图像后实现三路输出的设计的呢?
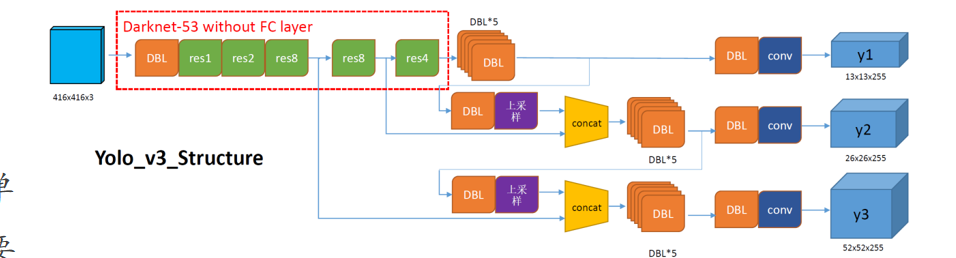
我们提供了这两张对比图供大家对比。首先观察主干网络部分:在第一个Res8操作时,网络会输出一个结果并连接到下方的矩阵拼接模块concat;随后进行第二个Res8操作时,网络会再次输出并连接到Y2的矩阵拼接(CONCAT)模块;最后res4 会输出到上方的Y1模块。
在第一个分支中,我们首先进行了五次dbl卷积操作。随后将输出传递到第二个分支,依次进行卷积和上采样处理。接着将结果与前一层的特征矩阵拼接,形成第二个分支的输出特征,再进行卷积操作。第三个分支的处理流程与上述过程相同。
这样子,我们就得到了三个不同尺度的输出
输出Y1,Y2,Y3 值的含义:
我们采用了三种不同尺度的输出(13×13、26×26、52×52),但这些输出结果具体代表什么?通过多通道卷积层处理后,输出通道数增加到255个。那么,每个尺度下的通道具体对应什么含义?为何需要如此多的通道划分?
1.结构:
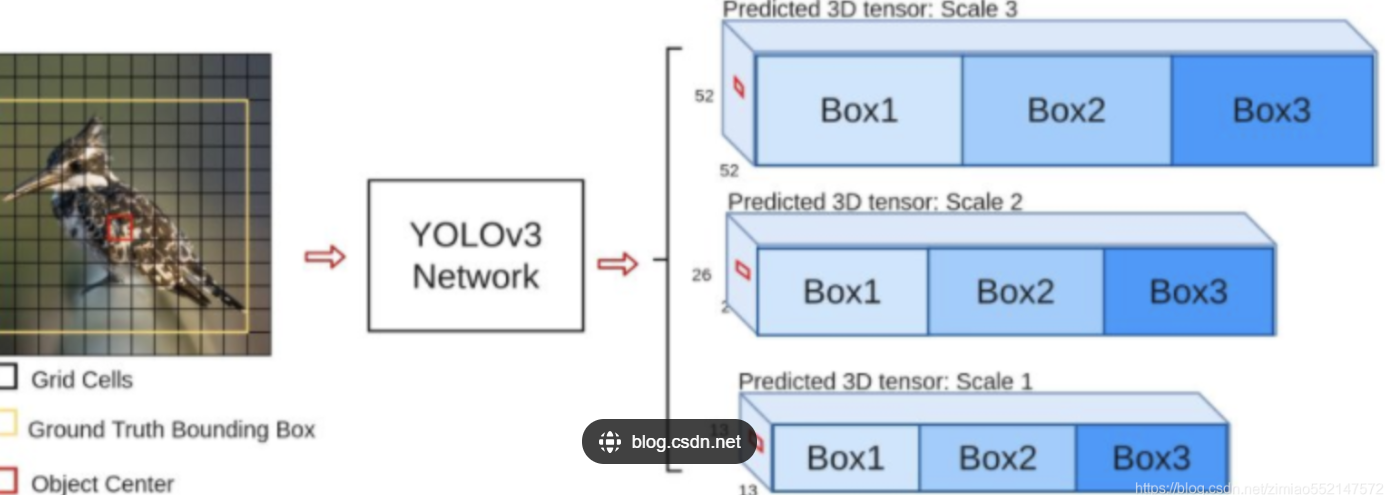
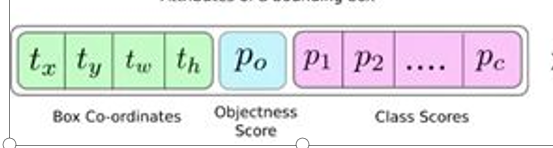
首先,这三个输出,每个输出都会分为三份,分成box 1,box 2,box 3
则每一个box 占有的通道数为255/3==85个 ,这85 个通道数里面的内容为:
COCO数据集里面有80 个类,所以我们就有P1,P2,......P80的类别打分情况,在加上tx,ty.tw.th 这 4个预测信息来预测框的位置,再加上一个置信度P0
一共是80+4+1=85
为什么这样设计呢?
2.演示:

如图我开始传入了一个255*255*3的图片进行训练(如果你们眼力好的话,我上图给你们画好了255*255的小格子)
然后现在我们把它投入到我们的网络训练中,最后我们输出了三种图片,y1y2y3,其中y1是13×13,这里展示:
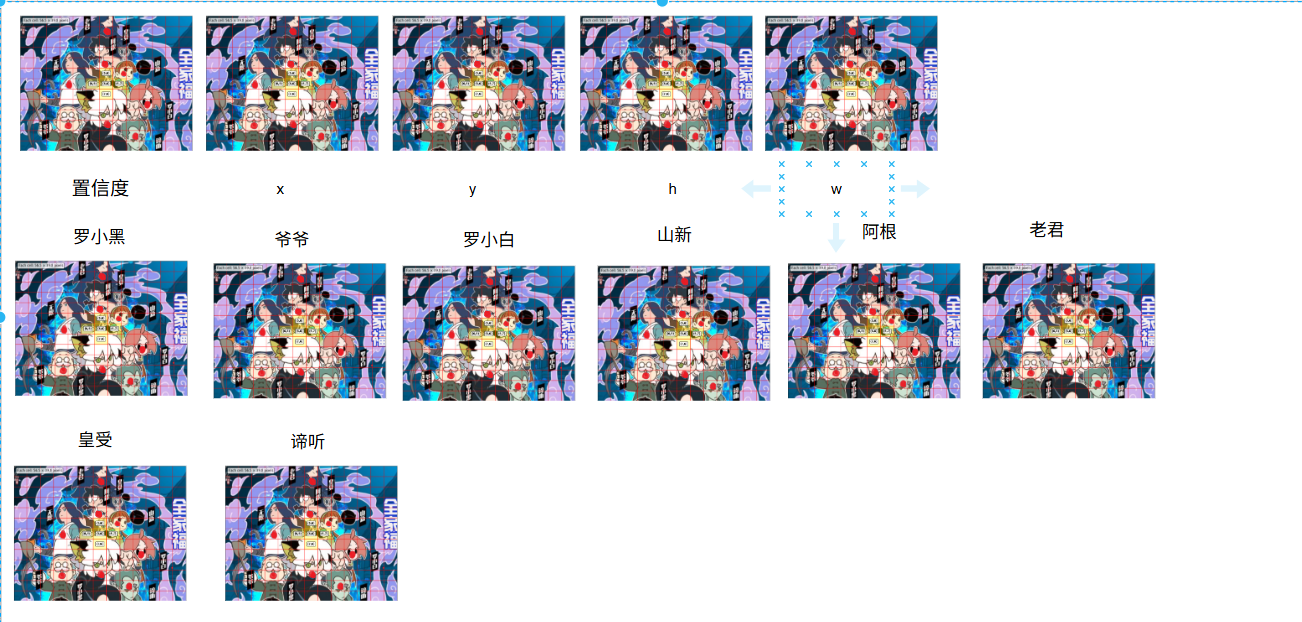
首先,图中有七个人,说明我们要检测的目标在一个图里面,需要标注七个,

在训练过程中,我们使用标注数据作为标签。每个物体的标注不仅需要标记中心点位置,还需包含位置信息和类别信息。位置信息由中心点坐标(x,y)和宽高(h,w)组成。由于每个网格单元只能存储一个数据,我们需要为x、y、h、w分别创建独立的通道来存储这些信息。对于类别信息处理更为简单:根据类别数量创建相应通道,当图像属于某个特定类别时,只需在该类别通道对应的中心点位置标记为1即可。
算一算根据我们的需求,这里不使用COCO数据集,仅有七种类别。那么需要多少通道呢?
首先,我们需要:
- 1个置信度通道(表示物体是否存在)
- 4个位置通道(x, y, w, h)
- 7个类别通道
总计:1 + 4 + 7 = 12个通道
由于y1、y2、y3三个分支各预测3个box,因此总通道数为12 × 3 = 36个。
对比COCO数据集的计算:
- 80个类别
- 1个置信度通道
- 4个位置通道
总计:80 + 1 + 4 = 85个通道
同样乘以3个box,最终输出为85 × 3 = 255个通道。因此,y1、y2、y3的输出结果采用255通道。
对于每一个box里面的数据集标注结果,我画了一张图:这一共就是13通道所呈现的内容
在训练过程中,我们通过标签数据进行反向传播,从而获取目标框的xywh坐标及类别信息。需要特别说明的是,YOLOv3的层次结构中,最后一层采用了全卷积层设计。这种结构能够有效保持特征在空间上的位置关系,确保图像中的类别信息能够与其他通道信息准确对应。因此,每个类别与其对应的物体边界框都保持着严格的一 一对应关系。
3.反向传播:
1.首先,对于中心点中它的类别,这个反向传播,咱们CNN已经讲的很透彻了,这里不做继续讨论
2.咱们着重讲目标检测中框的反向传播,也就是xywh这些该怎么传播?
(x,y)的反向传播:
首先,论文中对中心点坐标xy的反向传播公式是如下所示
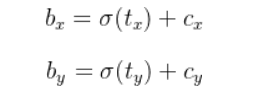
如下图所示,当输出结果图中仅含一个物体时,其中心点落在某个网格内。此时,我们反向传播的数值就是该网格内的中心点坐标值。
将255×255的图像转换为13×13的图像后,每个网格对应原图中的多个像素格。因此,物体中心点在该网格内的偏移量(x、y)可作为反向传播的数值。
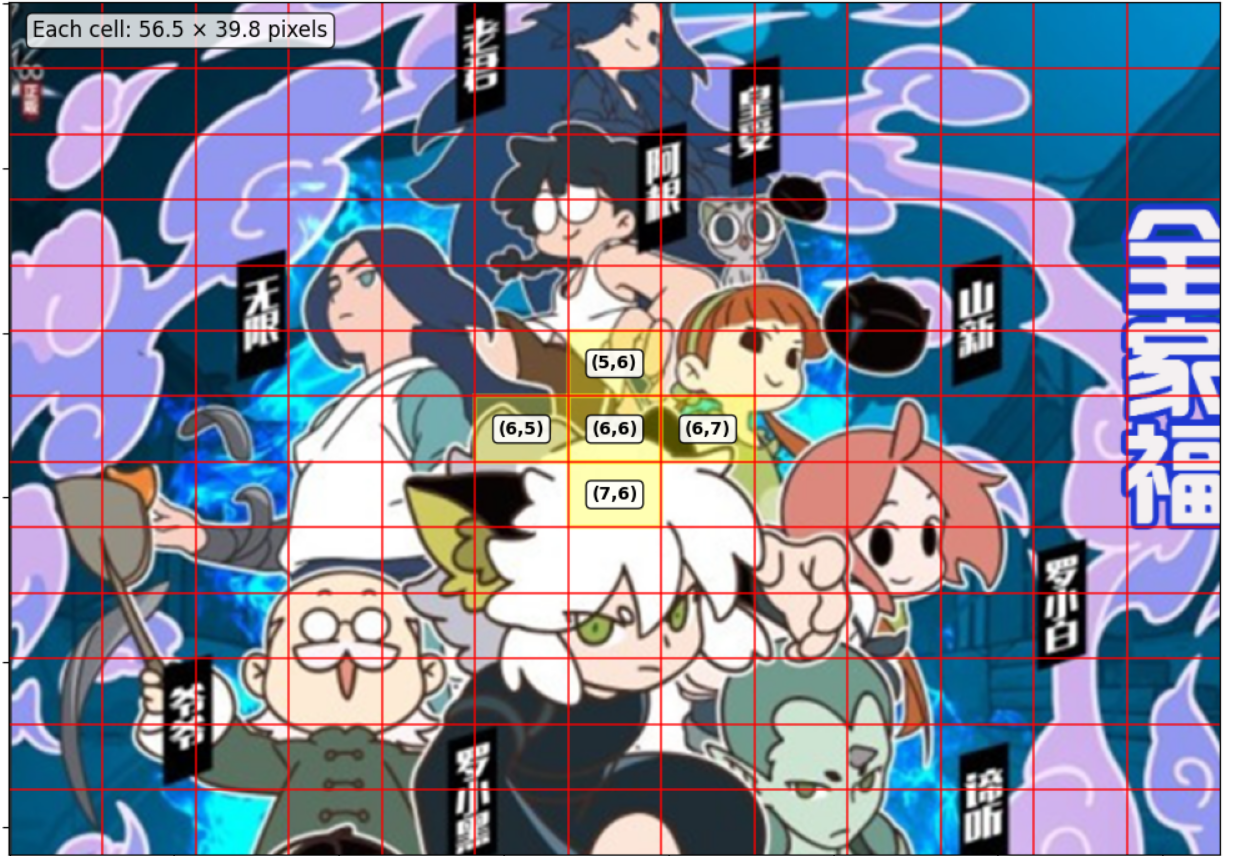
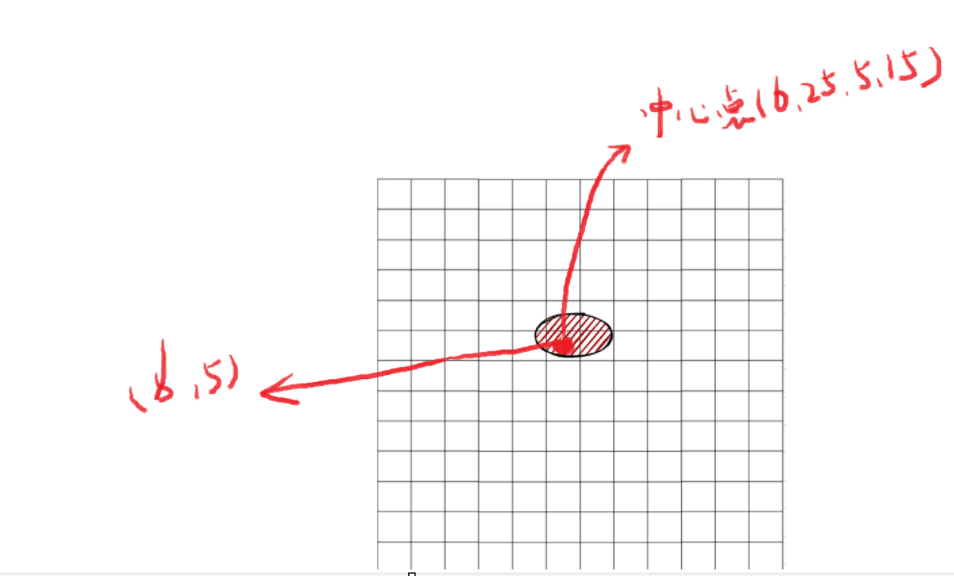
在之前给出的公式中,tx和ty表示中心点在网格(cx,cy)内的偏移量。公式中的σ(sigmoid函数)用于将tx和ty的数值范围压缩到0到1之间,以优化反向传播过程。下图中的cx cy是6和5,那它的偏移量应该是0.25和0.15
所以:在正向传播过程中,该中心点的值代表偏移量。进行反向传播时,我们会将网格坐标与中心点位置相加,得到预测位置,再与真实标注位置进行对比,通过反向传播来优化模型参数。
请注意,图中需要绘制两个图表,分别代表两个通道:一个通道专门对应x值,另一个通道专门对应y值。由于每个格子只能存储一个值用于反向传播,因此需要分开表示。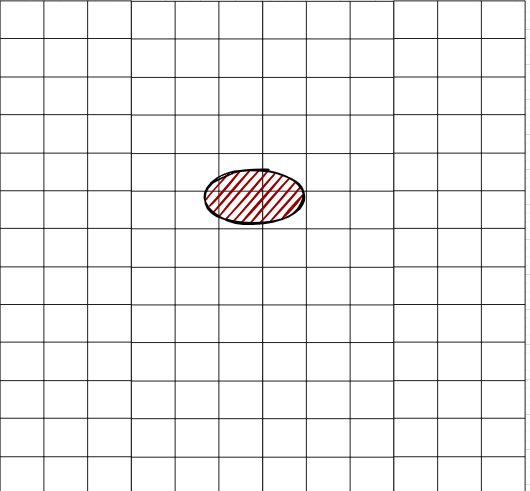
W,H的反向传播:
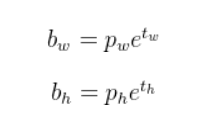
YOLOv3论文中关于w和h反向传播的公式设计颇具巧思。我们发现,Tw和Th作为e的指数参数出现,这促使我们需要先理解"先验框"这一关键概念。
如上图:
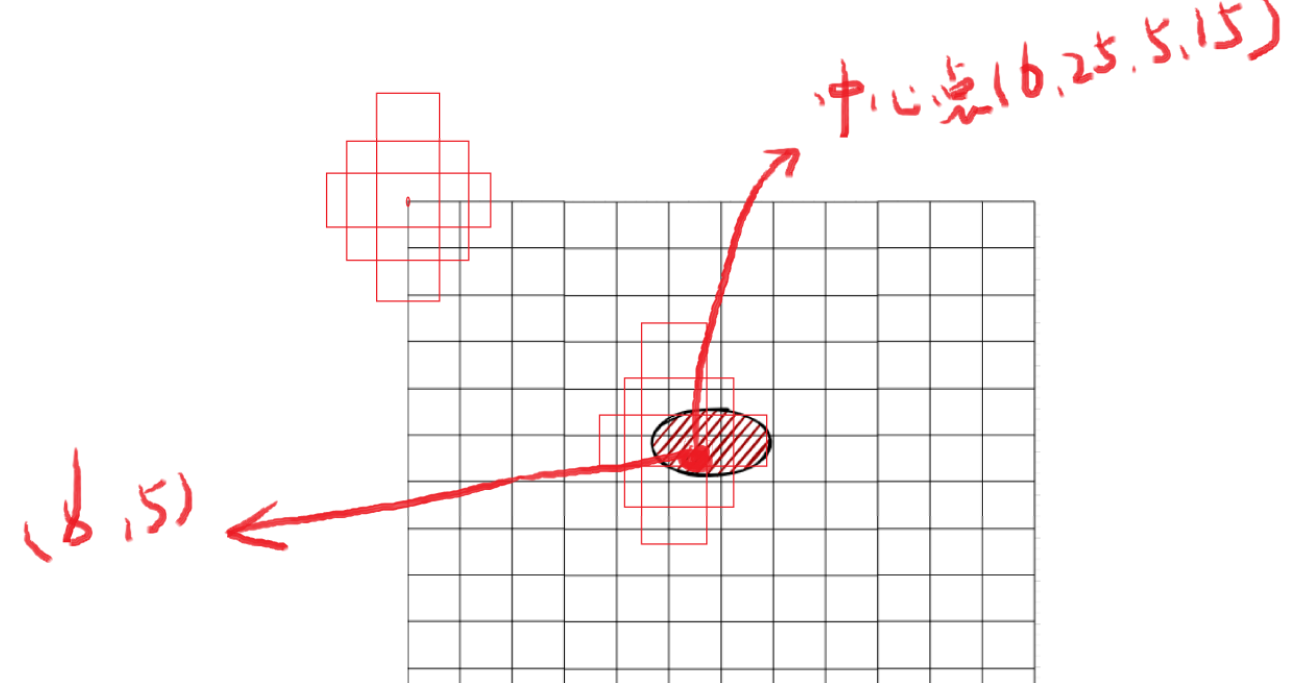
为了提高反向传播效率,我们不建议直接将中心点坐标和宽高作为参数进行反向传播。为此,我们预先设置了三个锚框。以上面13×13的输出网格为例,每个网格的左上角作为基准点,每个点都关联三个预定义的锚框(注意每个格子的左上角都有一组锚框,图中我只画了两组锚框,其实有13×13个格子的锚框)。
设置三个锚框的原因是:物体通常具有不同形状特征,如细长、宽扁或矮胖等。这三个锚框可以更好地覆盖这些形状变化。具体实现方法如下:
假设上图中心点位于(6,5)的网格中,该网格左上角点已预先配置三个锚框。我们让这三个锚框分别与真实框计算交并比(IoU),选取IoU最大的锚框作为该中心点的初始参考框。然后基于这个参考框进行长宽的微调计算。
这种方法显著提高了反向传播效率,因为我们不需要直接预测物体的绝对尺寸,只需在预设锚框基础上进行微调即可获得物体的长宽信息。
这些预定义锚框的尺寸是通过k-means聚类方法确定的。我们统计了训练数据中所有物体的长宽分布,经过大量数据分析后得到这些经验值(先验框),从而确定在13×13网格中物体可能的长宽比例。
需要注意的是,上文涉及两个专有名词:最大交并比(IoU)和k-means聚类方法。
1.最大交并比(IoU):
上面就是最大交并比,很简单,IoU 就是两个图形面积的交集和并集的比值
2. k-means聚类方法:它的作用就是聚类,在这里面,我们可以用这个方法来得出一个常用的长和宽,具体的这个方法实现我在我的博客已经写了:点击此观看~~~
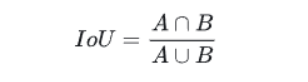
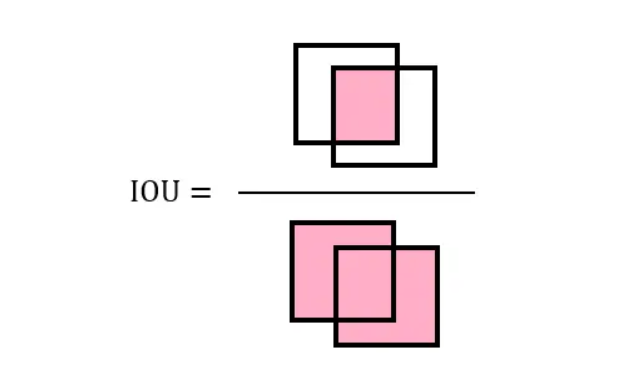
所以我们就可以通过这个思路来再看一下我们YOLOv3论文里面的那个公式:
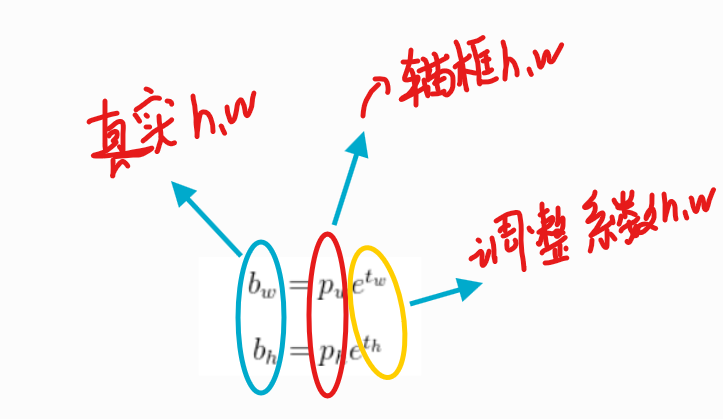
在训练网络时,我们只需优化调整系数。但为什么要在调整系数中使用指数e呢?这是因为网络训练过程中可能出现负值,而指数函数能有效处理这些负值,使调整结果更利于训练。因此,我们需要引入e作为底数。
重新审视之前的架构设计,我们发现输出结果中生成了3个box。这一现象背后的原因是什么?
原因在于我们预设的三个锚框。这些锚框分别与真实边界框计算最大交并比(IoU),从而确定匹配关系。因此,我们需要准备三组数据,每组包含边界框的坐标信息(x,y,w,h)以及对应的类别标签(如COCO数据集中的80个类别)。
所以我允许我重新说明一下输出的结构
对于特征图上的每一个网格细胞(Grid Cell),YOLOv3 都会预测 3 个边界框(box)。
每个边界框的预测输出包括:
-
(tx, ty, tw, th):4个坐标偏移量。模型并不直接预测框的绝对位置和大小,而是预测相对于分配给该尺度的那个锚框的偏移量。-
(tx, ty)用于微调中心点位置。 -
(tw, th)用于微调宽度和高度。
-
-
置信度(Objectness Score):表示这个框内包含一个物体的概率。 -
类别概率:如果框内有物体,它属于各个类别的概率。
所以,一个网格细胞预测 3 个 box,本质上就是让这个细胞有机会检测到 3 种不同形状(由该尺度的 3 个锚框定义)的物体。
OK,有关于YOLOV3的核心知识点就到此结束了,中秋快乐家人们!
还有,写博客真的不易,可以点一个关注吗! 
