一、简介
副本功能只支持 MergeTree Family 的表引擎,参考文档:https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/replication/
ClickHouse 副本的目的主要是保障数据的高可用性,即使一台 ClickHouse 节点宕机,那么也可以从其他服务器获得相同的数据。
二、原理
主要依赖 Zookeeper 来进行多个 ClickHouse 节点间数据的同步,各节点间没有主从关系
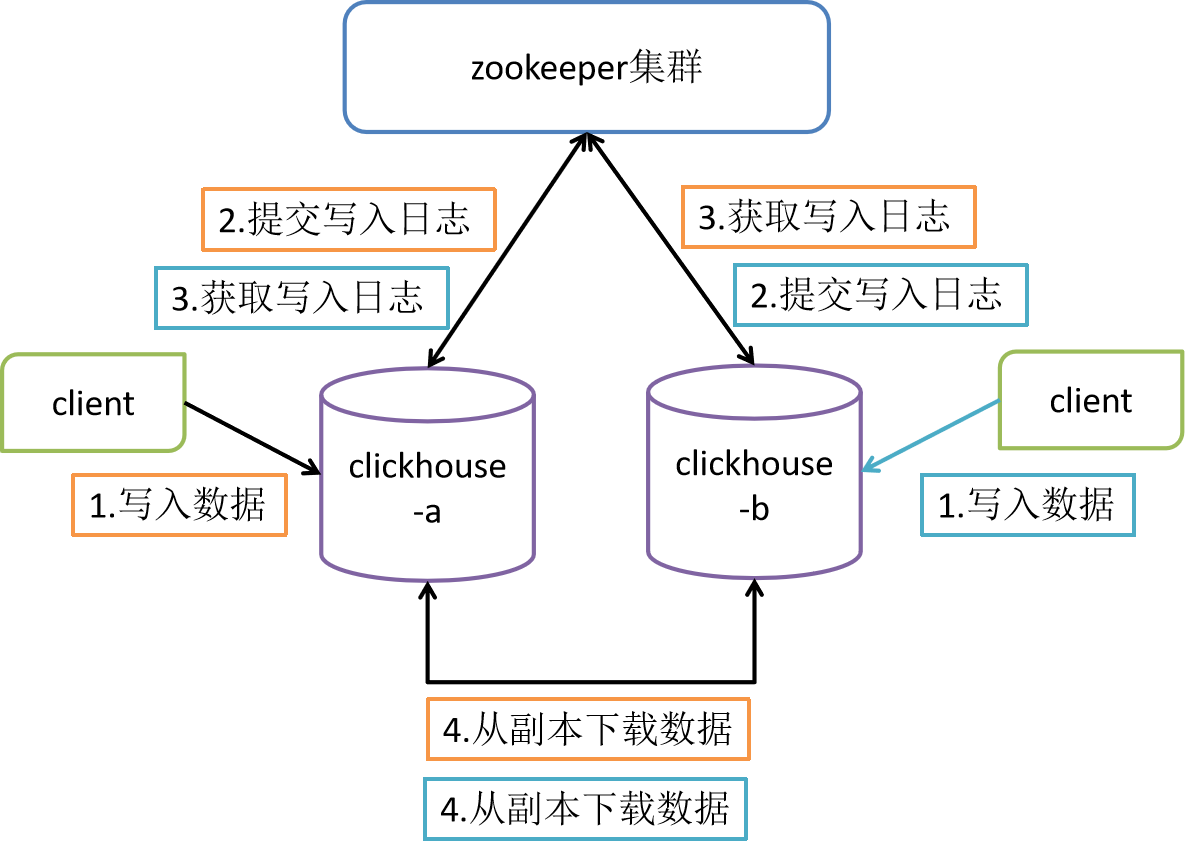
三、配置
以 3 台虚拟机节点集群为例
-
在集群的一台节点 hadoop102 上修改配置文件
shell#1. 使用外部文件进行配置 su root cd /etc/clickhouse-server/config.d vim metrika.xml #添加zookeeper信息 <?xml version="1.0"?> <yandex> <zookeeper-servers> <node index="1"> <host>hadoop102</host> <port>2181</port> </node> <node index="2"> <host>hadoop103</host> <port>2181</port> </node> <node index="3"> <host>hadoop104</host> <port>2181</port> </node> </zookeeper-servers> </yandex> #修改metrika.xml文件的所属用户及组 chown clickhouse:clickhouse metrika.xml cd /etc/clickhouse-server vim config.xml #查找zookeeper位置,添加配置 <zookeeper incl="zookeeper-servers" optional="true" /> <include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from> #2. 直接在 config.xml 中进行配置 su root cd /etc/clickhouse-server vim config.xml #查找zookeeper位置,去掉<zookeeper></zookeeper>的注释并修改 <zookeeper> <node> <host>hadoop102</host> <port>2181</port> </node> <node> <host>hadoop103</host> <port>2181</port> </node> <node> <host>hadoop104</host> <port>2181</port> </node> </zookeeper> -
同步配置文件到其他节点
shell/etc/clickhouse-server/config.d/metrika.xml /etc/clickhouse-server/config.xml -
启动 zookeeper 集群服务
-
分别在 clickhouse 对应的节点启动服务
shellsudo clickhouse start
四、使用
-
在集群一台节点 hadoop102 上进入 clickhouse 客户端并创建表
sqlcreate table t_order_rep2 ( id UInt32, sku_id String, total_amount Decimal(16,2), create_time Datetime ) engine=ReplicatedMergeTree('/clickhouse/table/01/t_order_rep','rep_102') partition by toYYYYMMDD(create_time) primary key (id) order by (id,sku_id); --ReplicatedMergeTree中的参数说明: --1. '/clickhouse/table/01/t_order_rep':指定表的分片在 zookeeper 中的地址,一般按照 /clickhouse/table/{shard}/{table_name} 的格式,只有一个分片就写 01 --2. 'rep_102':指定副本名称,相同的分片副本名称不能相同 -
在集群另一台节点 hadoop103 上进入 clickhouse 客户端并创建表
sqlcreate table t_order_rep2 ( id UInt32, sku_id String, total_amount Decimal(16,2), create_time Datetime ) engine=ReplicatedMergeTree('/clickhouse/table/01/t_order_rep','rep_103') partition by toYYYYMMDD(create_time) primary key (id) order by (id,sku_id); -
在 hadoop102 上向表中插入数据
sqlinsert into t_order_rep2 values (101,'sku_001',1000.00,'2020-06-01 12:00:00'), (102,'sku_002',2000.00,'2020-06-01 12:00:00'), (103,'sku_004',2500.00,'2020-06-01 12:00:00'), (104,'sku_002',2000.00,'2020-06-01 12:00:00'), (105,'sku_003',600.00,'2020-06-02 12:00:00'); -
在 hadoop103 上查询表中数据,能正确返回则表示副本配置成功
sqlselect * from t_order_rep2;