
我们仍然惊讶于有如此多的客户来找我们,希望从HDFS迁移到现代对象存储,如MinIO。我们现在以为每个人都已经完成了过渡,但每周,我们都会与一个决定进行过渡的主要、高技术性组织交谈。
很多时候,在这些讨论中,他们希望在迁移后维护其基础设施的某些元素。HDFS 生态系统中的一些框架和软件得到了大量开发人员的支持,并且在现代数据堆栈中仍然占有一席之地。事实上,我们经常说 HDFS 生态系统带来了很多好处。根本问题在于存储和计算的紧密耦合,而不一定是大数据时代的工具和服务。
这篇博文将重点介绍如何在不淘汰和替换有价值的工具和服务的情况下进行迁移。现实情况是,如果你不对你的基础架构进行现代化改造,你就无法在组织所需的AI/ML方面取得进步,但你不必为了实现这一目标而抛弃一切。
使用 Spark 和 Hive 分解存储和计算
我们已经经历了一些完全撕裂和替换迁移的策略,在某些情况下,这是前进的道路。但是,让我们看一下实现 HDFS 实现现代化的另一种方法。
此架构涉及 Kubernetes 管理用于数据处理的 Apache Spark 和 Apache Hive 容器;Spark 与 MinIO 原生集成,而 Hive 使用 YARN。MinIO 处理有状态容器中的对象存储,在此架构中,它依赖于多租户配置进行数据隔离。

架构概述:
-
计算节点:Kubernetes 高效管理计算节点上的无状态 Apache Spark 和 Apache Hive 容器,确保资源利用率和动态扩展。
-
存储层:MinIO纠删码和BitRot保护意味着您可能会丢失多达一半的驱动器数量,但仍然可以恢复,所有这些都不需要维护Hadoop所需的每个数据块的三个副本。
-
访问层:对 MinIO 对象存储的所有访问都通过 S3 API 统一,为与存储的数据交互提供无缝接口。
-
安全层:数据安全至关重要。MinIO 使用每个对象的密钥加密所有数据,确保对未经授权的访问提供强大的保护。
-
身份管理:MinIO Enterprise 与 WSO2、Keycloak、Okta、Ping Identity 等身份提供商完全集成,以允许应用程序或用户进行身份验证。
Hadoop的完全现代化替代品,使您的组织能够保留Hive,YARN和任何其他Hadoop生态系统数据产品,这些产品可以与对象存储集成,对象存储几乎是现代数据堆栈中的所有内容。
接入层中的互操作性
S3a是寻求从Hadoop过渡的应用程序的重要端点,它提供了与Hadoop生态系统中各种应用程序的兼容性。自 2006 年以来,兼容 S3 的对象存储后端已作为默认功能无缝集成到 Hadoop 生态系统中的众多数据平台中。这种集成可以追溯到将 S3 客户端实施整合到新兴技术中。
在所有与Hadoop相关的平台上,采用该 hadoop-aws 模块是 aws-java-sdk-bundle 标准做法,确保了对S3 API的强大支持。这种标准化方法有助于应用程序从 HDFS 和 S3 存储后端平稳过渡。只需指定适当的协议,开发人员就可以毫不费力地将应用程序从Hadoop切换到现代对象存储。S3 的协议方案用 s3a:// 表示,而 HDFS 的协议方案用 hdfs:// 表示。
迁移的好处
可以详细讨论从Hadoop迁移到现代对象存储的好处。如果你正在阅读这篇文章,你已经在很大程度上意识到,如果不从Hadoop等传统平台迁移,人工智能和其他现代数据产品的进步可能会被排除在外。原因归结为性能和规模。
毫无疑问,现代工作负载需要出色的性能来与正在处理的数据量和现在所需的任务复杂性竞争。当性能不仅仅是虚荣的基准测试,而是一个硬性要求时,Hadoop替代品的竞争者领域就会急剧下降。
推动迁移的另一个因素是云原生规模。当云的概念不再是物理位置,而更像是一种操作模型时,就可以做一些事情,比如在几分钟内从单个 .yaml 文件部署整个数据堆栈。如此迅速的实现会让任何Hadoop工程师从椅子上摔下来。
这一概念的一部分是摆脱供应商锁定带来的经济效益,它允许组织为特定工作负载选择一流的选项。更不用说,无需维护三个单独的数据副本来保护它,这已成为过去,具有主动-主动复制和纠删编码。投资于面向未来的技术通常也意味着更容易找到和招募有才华的专业人员来从事您的基础设施工作。人们希望从事推动业务发展的事情,而几乎没有比数据做得更好的了。这些因素共同促成了数据堆栈,该堆栈不仅更快、更便宜,而且更适合当今和未来的数据驱动需求。
开始
在深入了解我们架构的细节之前,您需要启动并运行一些组件。要从Hadoop迁移,显然必须首先安装它。如果要模拟此体验,可以通过在此处设置 Hadoop 的 Hortonworks 发行版来开始本教程。
否则,您可以从以下安装步骤开始:
1 . 设置 Ambari:接下来,安装 Ambari,它将通过自动为你配置 YARN 来简化服务的管理。Ambari提供了一个用户友好的仪表板,用于管理Hadoop生态系统中的服务,并保持一切顺利运行。
2 . 安装 Apache Spark:Spark 对于处理大规模数据至关重要。按照标准安装过程启动并运行 Spark。
3 . 安装 MinIO:根据您的环境,您可以在两种安装方法之间进行选择:Kubernetes 或 Helm Chart。
成功安装这些元素后,可以将 Spark 和 Hive 配置为使用 MinIO 而不是 HDFS。导航到 Ambari UI http://:8080/ 并使用默认凭据登录: username: admin, password: admin ,
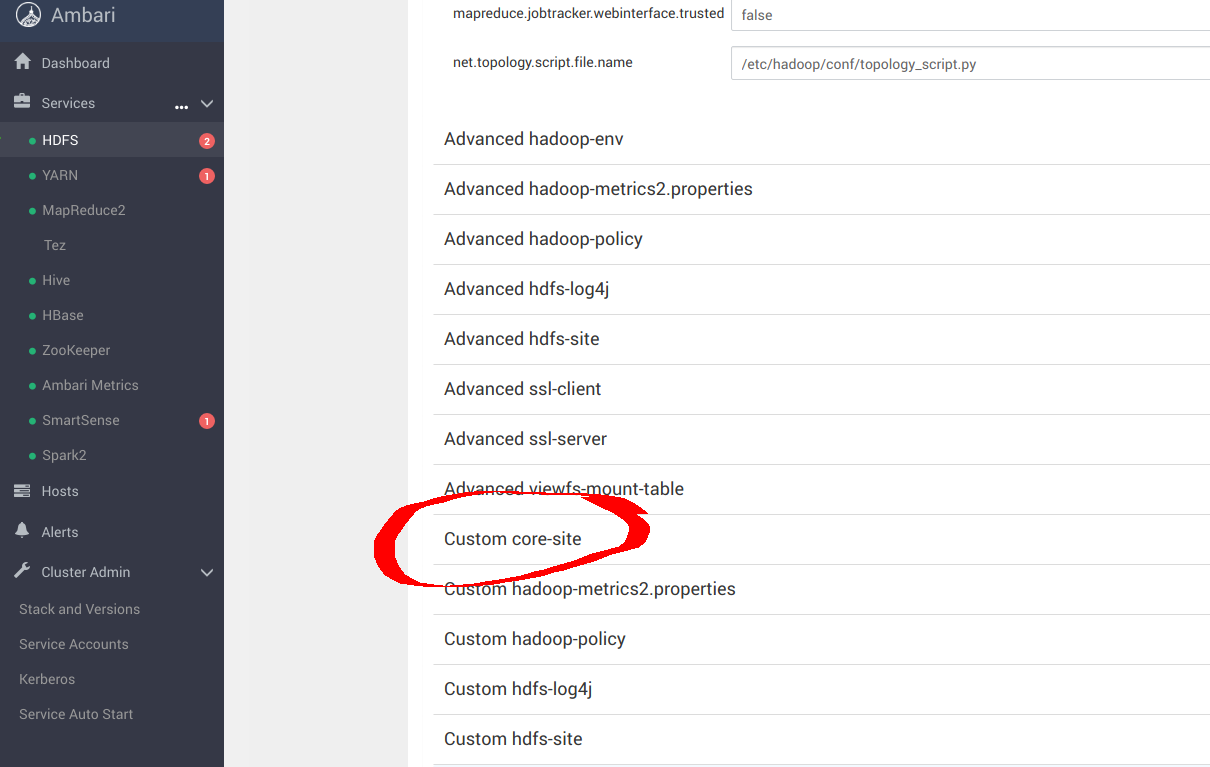
在 Ambari 中,导航到"services",然后导航到 HDFS,然后导航到"配置"面板,如下面的屏幕截图所示。在本部分中,您将 Ambari 配置为将 S3a 与 MinIO 结合使用,而不是 HDFS。

向下滚动并导航到 Custom core-site 。您将在此处配置 S3a。
sudo pip install yq
alias kv-pairify='yq ".configuration[]" | jq ".[]" | jq -r ".name + \"=\" + .value"'从这里开始,您的配置将取决于您的基础结构。但是,下面可能代表了 core-site.xml 一种配置 S3a 的方法,其中 MinIO 在 12 个节点和 1.2TiB 内存上运行。
cat ${HADOOP_CONF_DIR}/core-site.xml | kv-pairify | grep "mapred"
mapred.maxthreads.generate.mapoutput=2 # Num threads to write map outputs
mapred.maxthreads.partition.closer=0 # Asynchronous map flushers
mapreduce.fileoutputcommitter.algorithm.version=2 # Use the latest committer version
mapreduce.job.reduce.slowstart.completedmaps=0.99 # 99% map, then reduce
mapreduce.reduce.shuffle.input.buffer.percent=0.9 # Min % buffer in RAM
mapreduce.reduce.shuffle.merge.percent=0.9 # Minimum % merges in RAM
mapreduce.reduce.speculative=false # Disable speculation for reducing
mapreduce.task.io.sort.factor=999 # Threshold before writing to drive
mapreduce.task.sort.spill.percent=0.9 # Minimum % before spilling to drive通过查看有关此迁移模式的文档,以及 Hadoop 关于 S3 的文档,可以探索相当多的优化 此处 和 此处.
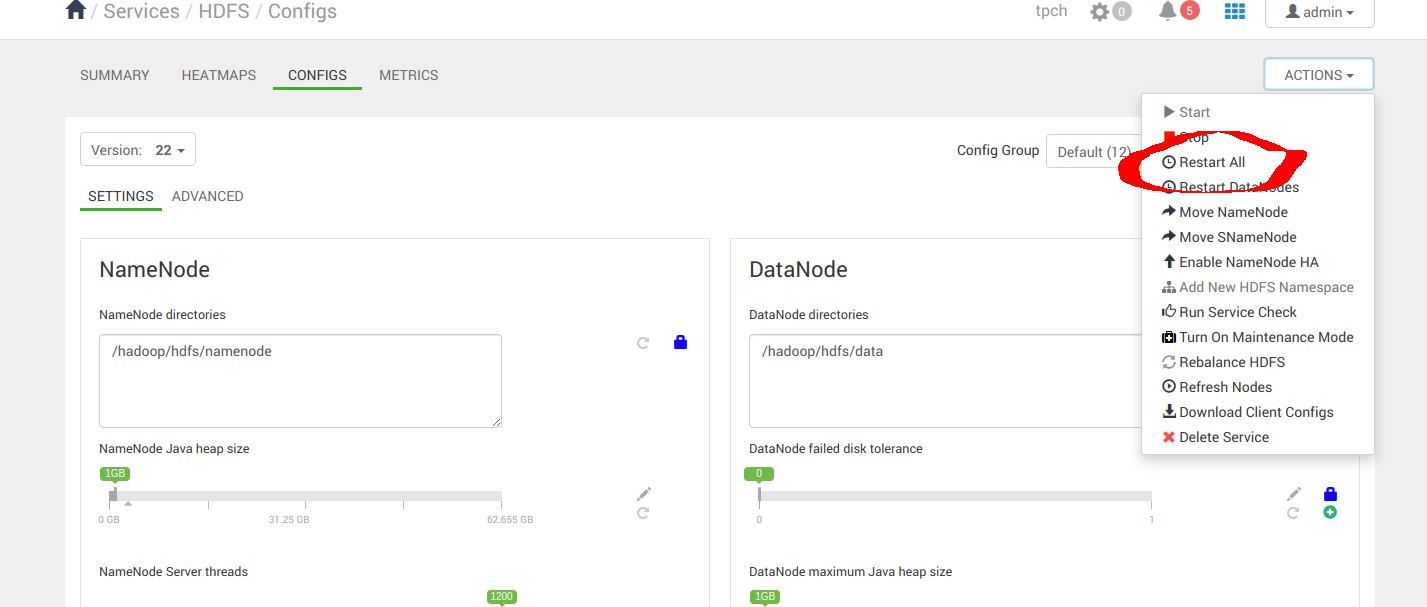
当您对配置感到满意时,请重新启动 All。
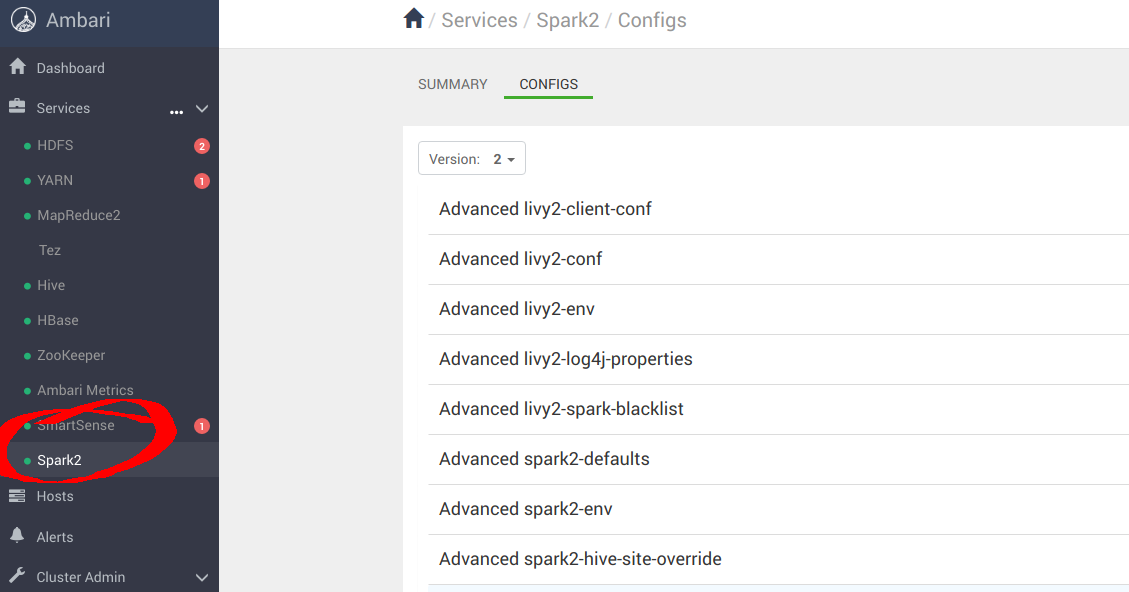
您还需要导航到 Spark2 配置面板。
向下滚动到 Custom spark-defaults 并添加以下属性以使用 MinIO 进行配置:
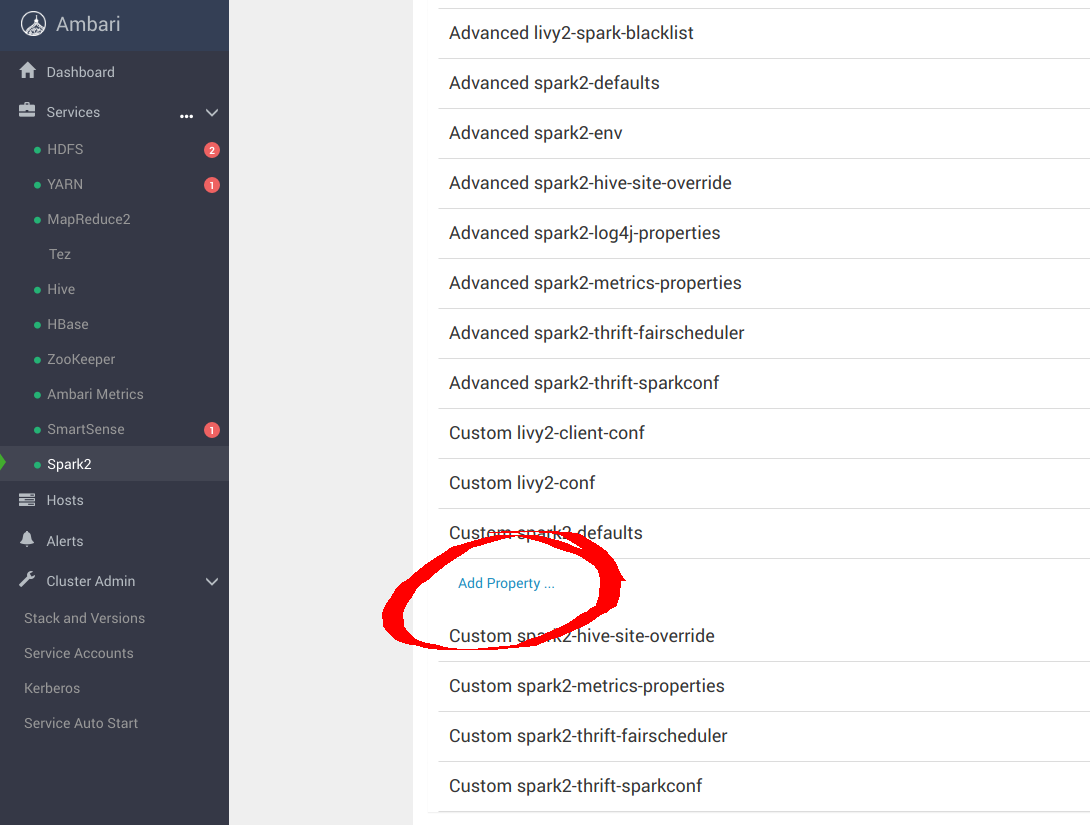
spark.hadoop.fs.s3a.access.key minio
spark.hadoop.fs.s3a.secret.key minio123
spark.hadoop.fs.s3a.path.style.access true
spark.hadoop.fs.s3a.block.size 512M
spark.hadoop.fs.s3a.buffer.dir ${hadoop.tmp.dir}/s3a
spark.hadoop.fs.s3a.committer.magic.enabled false
spark.hadoop.fs.s3a.committer.name directory
spark.hadoop.fs.s3a.committer.staging.abort.pending.uploads true
spark.hadoop.fs.s3a.committer.staging.conflict-mode append
spark.hadoop.fs.s3a.committer.staging.tmp.path /tmp/staging
spark.hadoop.fs.s3a.committer.staging.unique-filenames true
spark.hadoop.fs.s3a.committer.threads 2048 # number of threads writing to MinIO
spark.hadoop.fs.s3a.connection.establish.timeout 5000
spark.hadoop.fs.s3a.connection.maximum 8192 # maximum number of concurrent conns
spark.hadoop.fs.s3a.connection.ssl.enabled false
spark.hadoop.fs.s3a.connection.timeout 200000
spark.hadoop.fs.s3a.endpoint http://minio:9000
spark.hadoop.fs.s3a.fast.upload.active.blocks 2048 # number of parallel uploads
spark.hadoop.fs.s3a.fast.upload.buffer disk # use disk as the buffer for uploads
spark.hadoop.fs.s3a.fast.upload true # turn on fast upload mode
spark.hadoop.fs.s3a.impl org.apache.hadoop.spark.hadoop.fs.s3a.S3AFileSystem
spark.hadoop.fs.s3a.max.total.tasks 2048 # maximum number of parallel tasks
spark.hadoop.fs.s3a.multipart.size 512M # size of each multipart chunk
spark.hadoop.fs.s3a.multipart.threshold 512M # size before using multipart uploads
spark.hadoop.fs.s3a.socket.recv.buffer 65536 # read socket buffer hint
spark.hadoop.fs.s3a.socket.send.buffer 65536 # write socket buffer hint
spark.hadoop.fs.s3a.threads.max 2048 # maximum number of threads for S3A应用配置更改后,全部重新启动。
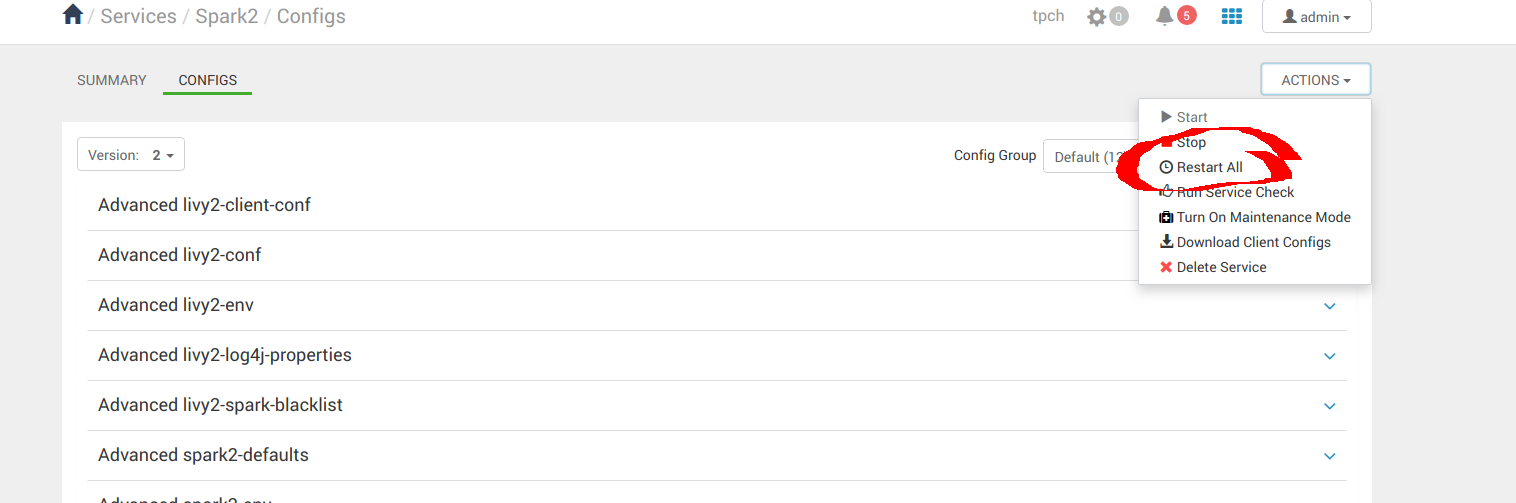
导航到 Hive 面板以完成配置。
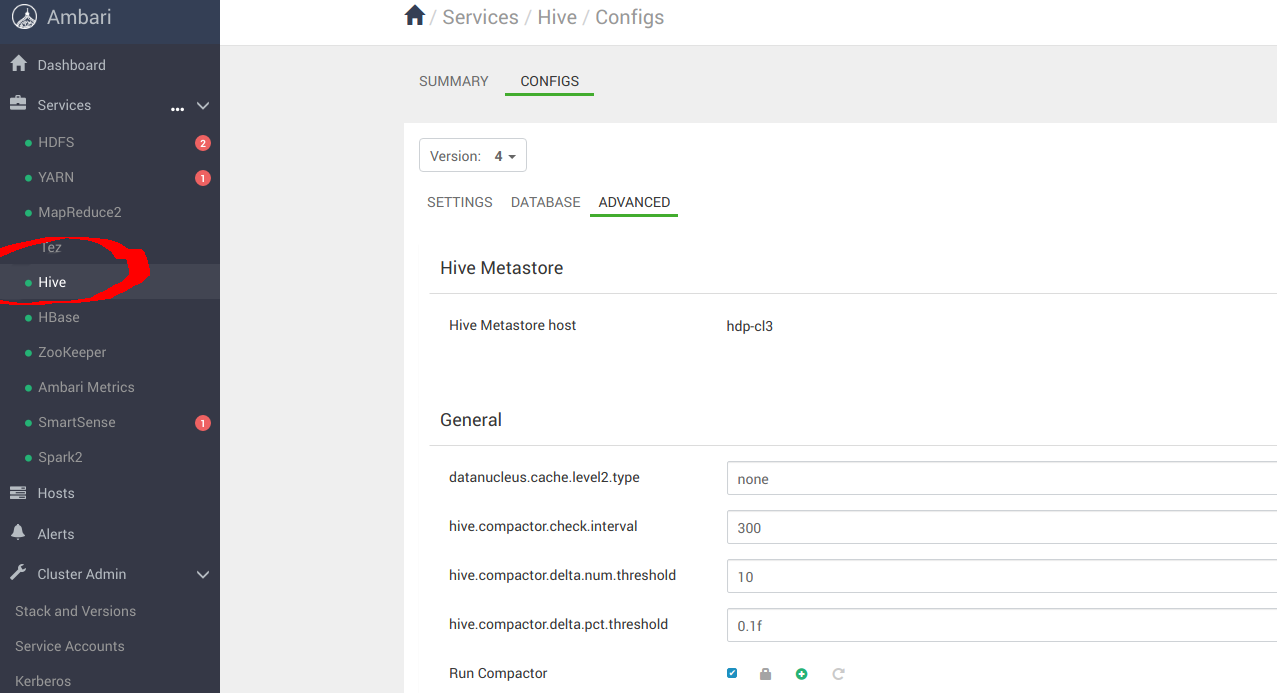
向下滚动到 Custom hive-site 并添加以下属性:
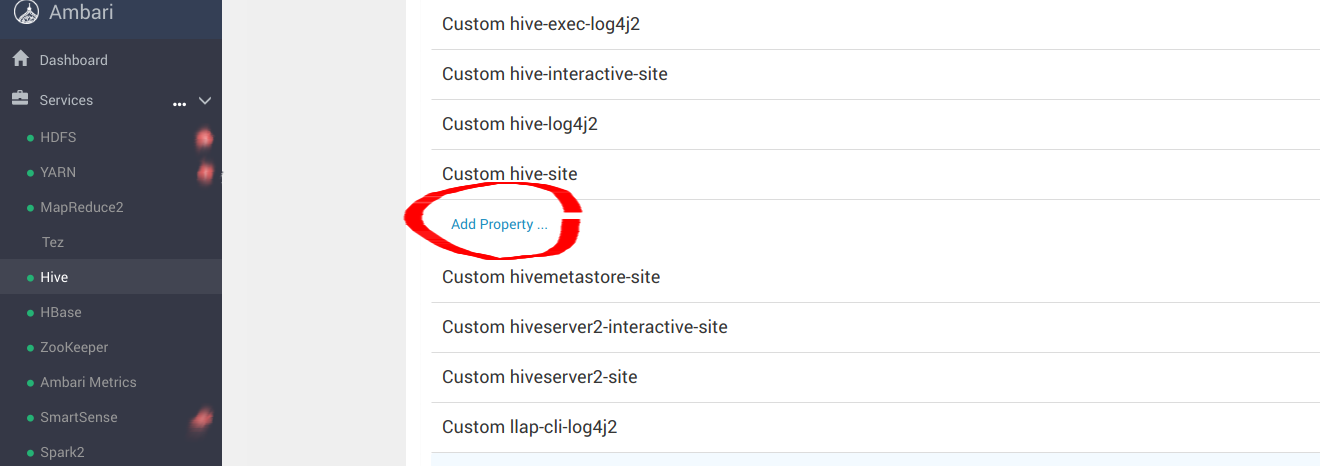
hive.blobstore.use.blobstore.as.scratchdir=true
hive.exec.input.listing.max.threads=50
hive.load.dynamic.partitions.thread=25
hive.metastore.fshandler.threads=50
hive.mv.files.threads=40
mapreduce.input.fileinputformat.list-status.num-threads=50您可以在此处找到更多微调配置信息。在进行配置更改后重新启动所有。
就是这样,您现在可以测试您的集成。
自行探索
这篇博文概述了一种从Hadoop迁移的现代方法,而无需彻底检修现有系统。通过利用 Kubernetes 管理 Apache Spark 和 Apache Hive,并集成 MinIO 进行有状态对象存储,组织可以实现支持动态扩展和高效资源利用的平衡架构。此设置不仅保留了数据处理环境的功能,而且增强了数据处理环境的功能,使其更加强大且面向未来。
借助 MinIO,您可以受益于在商用硬件上提供高性能的存储解决方案,通过纠缠编码(消除 Hadoop 数据复制的冗余)降低成本,并绕过供应商锁定和基于 Cassandra 的元数据存储等限制。这些优势对于希望在不丢弃现有数据系统核心元素的情况下利用高级 AI/ML 工作负载的组织至关重要。