前言
行专列,列转行是数开不可避免的一步,尤其是在最初接触Hive的时候,看到什么炸裂函数,各种udf,有点发憷,无从下手,时常产生这t怎么搞,我不会啊?
好吧,真正让你成长的,还得是甩给你一个需求,然后你自己绞尽脑汁的去实现。
列转行
SparkSQL中Hive_STACK函数列转行原理
Hive中的STACK函数,可以将多个列转换为多行,每行包含两个值:第一个值是指定的列名,第二个值是该列的值。
stack(INT n, v1, v2, ..., vk)
-----把M列转换成N行,每行有M/N个字段,其中n必须是个常数
生产中的案例
我以我在sparksql开发过程中遇到的实例为例,简单介绍一下用法。
给一frame表:我这里只拿出一写字段和数据,不过足够演示了这个函数的用法了
bash
+--------+--------+--------+--------+--------+
| fzl0000| fzl0100| fzl0200| max_fzl| fzl |
+--------+--------+--------+--------+--------+
| 0.9 | 0.8 | 0.7 | 0.6 | 0.5 |
+--------+--------+--------+--------+--------+我要将上面的几列数据进行列转行,比较粗暴
HiveSQL代码
sql
SELECT stack(4,
'fzl0000', fzl0000,
'fzl0100', fzl0100,
'fzl0200', fzl0200,
'max_fzl', max_fzl) AS (stat_time, mfzl)
FROM frame;丢到集群跑程序然后我们得到的结果就出来
bash
+--------------+------+
|stat_time | mfzl |
+--------------+------+
| fzl0000 | 0.9 |
| fzl0100 | 0.8 |
| fzl0200 | 0.7 |
| max_fzl | 0.6 |
+--------------+------+注意,hue是不能直接跑这个代码的,impala也不行,会报错,不知道你的会不会报错。所以还是老老实实写spark程序搞吧。
Spark代码
Scala
// 使用PIVOT函数进行列转行操作
val df_pivot = df.groupBy().pivot("stat_time").agg(expr("first(mfzl)"))你也可以在stack函数里头做一些函数操作比如一些转换啊啥的,自己去摸索一下吧。
行转列
还是以上面的数据为例,行转列列转行就像我们学过的高数中的矩阵转置,也就是线性代数中的矩阵,这个可以了解一下,计算机底层皆是数学。
SparkSQL中Hive_PIVOT函数行转列原理
一、PIVOT函数是Spark SQL中的一个聚合函数,用于将一列的值转换为多列。它将行数据中的某一列作为列名,将该列对应的值作为新的列的值,并将其他列的值保持不变,完成咱们得行转列操作,下图是一个很好的例子。
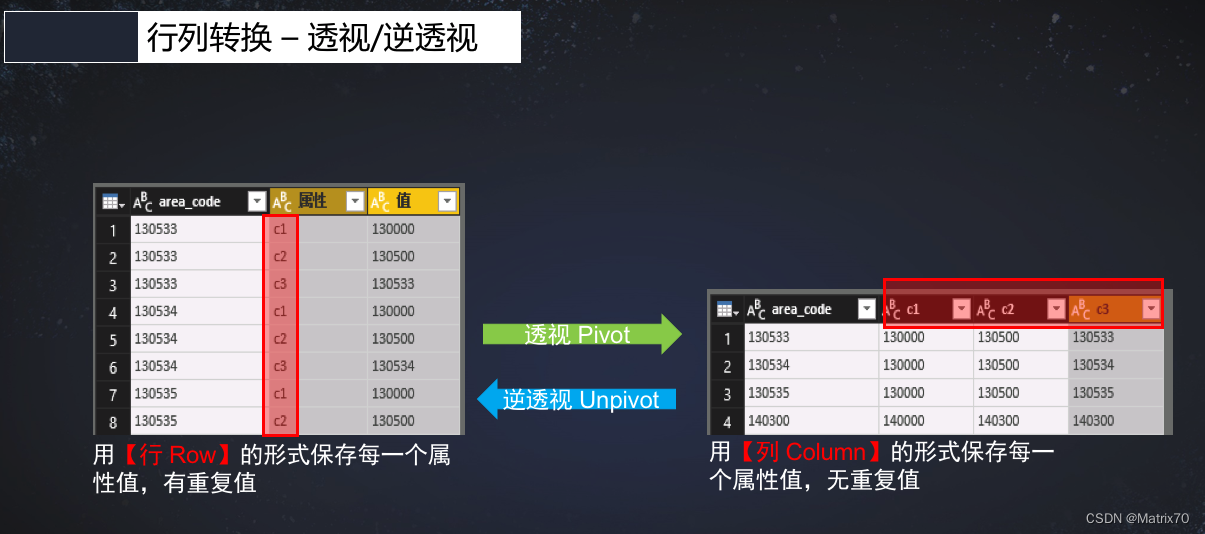
图片来源:https://juejin.cn/post/6844903619171631117
二、PIVOT函数接受三个参数:要进行聚合的列,要作为新列的列名,以及可选的要聚合的函数,这里头要聚合的列是把可能有重复的列聚合成一列。比如上图中多次重复出现的c1,c2,c3,我们要保证唯一值进行聚合,不能出现重复的列。
dataFrame数据
bash
+--------------+------+
|stat_time | mfzl |
+--------------+------+
| fzl0000 | 0.9 |
| fzl0100 | 0.8 |
| fzl0200 | 0.7 |
| max_fzl | 0.6 |
+--------------+------+行转列
bash
+--------+--------+--------+--------+--------+
| fzl0000| fzl0100| fzl0200| max_fzl| fzl |
+--------+--------+--------+--------+--------+
| 0.9 | 0.8 | 0.7 | 0.6 | 0.5 |
+--------+--------+--------+--------+--------+Spark代码
Scala
val transformedDF = df.groupBy().pivot("stat_time").agg(first("mfzl"))部分参考文章
1、行转列参考文章:https://juejin.cn/post/6844903619171631117,这篇文章很好,讲解的条理清晰,忍不住推荐一波!