第1关:基于集成学习模型的应用案例
任务描述
本次任务我们将会使用银行营销数据集(来源于UCI数据集:UCI Machine Learning Repository ),该数据集共45211条数据,涉及葡萄牙银行机构的营销活动,通过一些与葡萄牙银行机构营销活动(电话)有关的数据,来预测客户是否会订阅定期存款(变量Y)。这在真实场景下是有意义的,可以通过这个预测结果对未来的工作进行一个初步规划,即对某些用户是否会订阅定期存款提供一个预测参照; 我们整个课程会建立一个分类模型,实现是否订阅产品的预测,该过程包括数据处理与特征工程,模型选取与训练,指标衡量与测试几个部分。
相关知识
数据处理与特征工程
首先,我们来了解一下我们的数据,从而进一步明确任务,并作出针对性的分析。银行营销数据集是一个分类问题,目的是确认客户是否会订阅银行推出的产品,对应我们所需要的标签,这在数据集中以yes,no来进行表示;除此之外,数据包含了用于判断该决定的相关信息,对应我们所需要的特征,这些特征一共有16个。特征与标签的表示如下:
- Age:年龄
- Job:工作,工作类型(分类:"行政管理"、"蓝领"、"企业家"、"女佣"、"管理"、 "退休"、"个体户"、"服务"、"学生"、"技术员"、"失业"、"未知")
- Marital:婚姻,婚姻状况(分类:离婚,已婚,单身,未知)(注:"离婚"指离婚或丧偶)
- Education:教育(分类:'基本.4y','Basy.6y','Basy.9y'','Health.学校','文盲','专业'课程,'大学学位','未知')
- Default:违约,信用违约吗?(分类:"不","是","不知道")
- Housing:房,有住房贷款吗?(分类:"不","是","不知道")
- Loan:贷款,有个人贷款吗?((分类:"不","是","不知道")
- Contact:接触方式(分类:"移动电话","固定电话")
- Month:月,最后一个联系月份(分类:'MAR',...,'NOV','DEC')
- Day_of_week:每周的天数,最后一周的联系日(分类):"Mon"、"Tee"、"We"、"TUU"、"FRI"
- Duration:持续时间,最后的接触持续时间,以秒为单位
- Campaign:在这次战役和这个客户联系的执行人数量
- Pdays:客户上次从上次活动中联系过去之后的天数(数字;999表示以前没有联系过客户)
- Previous:本次活动之前和本客户端的联系人数(数字)
- Proutcome:前一次营销活动的结果(分类:失败,不存在,成功)
Y -客户是否会定期存款?"是"、"否" 我们可以通过以下代码,进行数据预览:
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom matplotlib.pyplot import MultipleLocatorimport seaborn as snsdata_path ='/data/shixunfiles/e6b0ca77f3f200ec5428e04dd104da53_1612443396928.csv'df = pd.read_csv(data_path,sep=';')print(df.head(5)) # 用于查看前五行数据df.info()df.describe()# 用于查看各个特征的统计分布信息
结果如下图:
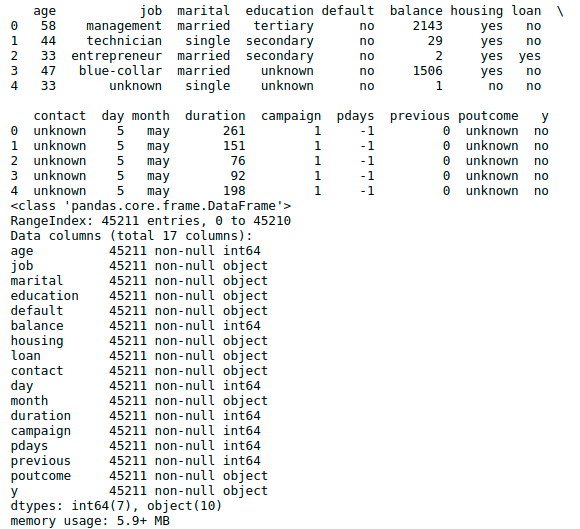
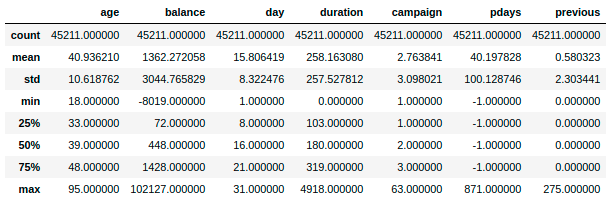
从上述对数据的预览我们可以看到得到这样的几个问题:
- 字符型特征中存在unkwown值,unknown值是缺失值。
- 部分特征为字符串格式,无法放到模型训练,后期需要该字段需要进行离散型特征编码。
- 我们观察到days(最后一次联系的时间(几号))和month(最后一次联系的时间(月份))与pdays(距离上次活动最后一次联系该客户,过去了多久(999表示没有联系过))之间存在特征重合,因此我们之后使用中只保留pdays特征即可。
在分析出这些问题后我们使用代码逐步对数据进行处理:
#查找字符型属性缺失情况for col in df.columns:if df[col].dtype == object:print("Percentage of \"unknown\" in %s:" %col ,df[df[col] == "unknown"][col].count(),"/",df[col].count())
结果输出如图:
以上就是对缺省值进行的处理,在处理完之后我们便可以开始进行探究特征与结果之间的相互联系。 首先我们先对label进行分析:
# 将label编码df['y'] = df['y'].replace(to_replace=['no', 'yes'], value=[0, 1])# 对label的取值进行统计分析client_purchase=df[df.loc[:,'y']==1].copy()client_not_purchase=df[df.loc[:,'y']==0].copy()pie_data = {'purchase': client_purchase.shape[0],'': df.shape[0]-client_purchase.shape[0]}explode = (0.2, 0) # 突出购买率fig1, ax = plt.subplots()sizes=pie_data.values()labels =['{}:{}'.format(key,value) for key,value in pie_data.items()]ax.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%',shadow=True, startangle=90)ax.axis('equal') # 确保圆形plt.show()
结果如图:
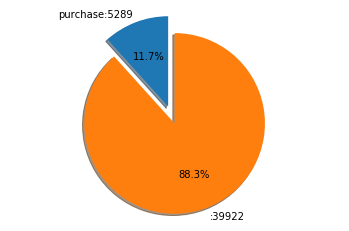
可以看出,定期理财产品的购买率不高,同时训练样本中购买与不购买的比例极其不均衡。后边可以使用过采样解决样本不均衡问题。
下面我们对各特征进行分析,观察单个特征与结果之间的关系,这里以职业和受教育程度进行示例分析:
fg=sns.catplot(data=df,x='job',kind='bar',y='y',ci=None)
fg=(fg.set_xticklabels(rotation=90)
set_axis_labels('','purchase rate')
despine(left=True))
运行结果如图:
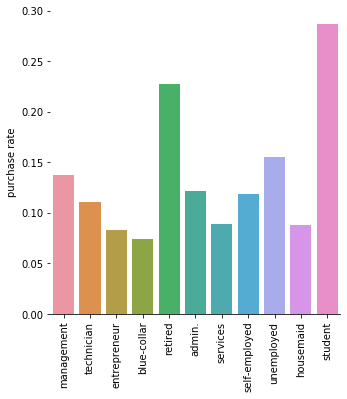
通过职业分类查看观察到:
- 退休人员和学生最青睐定期理财,其次是失业人员
- 蓝领定期理财的比率最低
通过可视化图标进一步分析:
g = sns.catplot(x='job', y='y', col='education',
data=df, saturation=.5,
kind='bar', col_order=['primary','secondary','tertiary'],
aspect=1.2,ci=None)
g = (g.set_axis_labels('job', 'purchase rate')
set_xticklabels(rotation=90)
set_titles('{col_name} {col_var}')
despine(left=True))
运行结果如图:
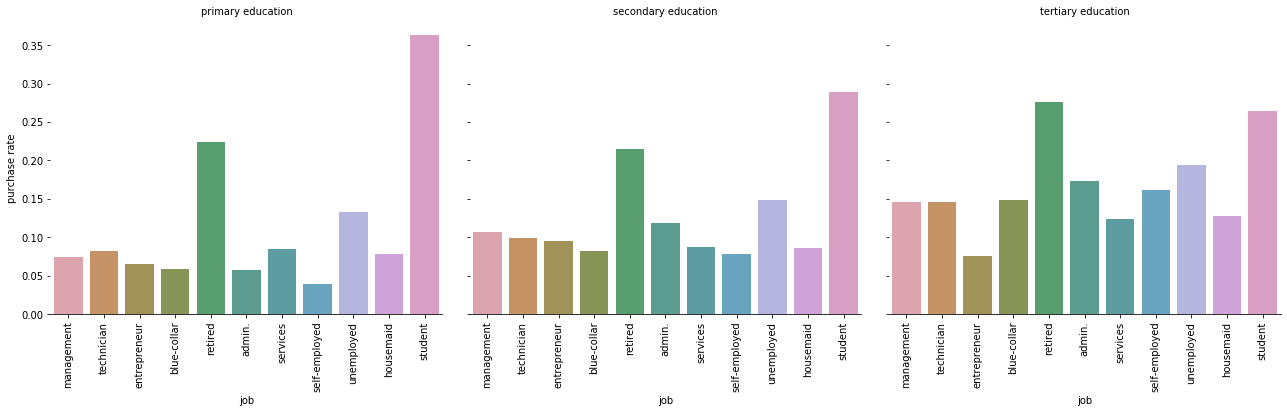
从上图我们观察到:
- 无论接受教育的程度如何,进行定期理财的人主要是退休人员和学生,其次是失业人员。
- 随着教育程度的提高,管理人员、技术人员、行政人员、蓝领、企业家、自由职业者、事业人员越来越倾向接受定期理财。
我们再从两个特征之间的相关性观察一下数据:
# 将相关性数值化sns.heatmap(data=df.corr(),annot=True)
运行结果如图:

根据相关系数的数值化,我们可以看出,duration(最后一次联系的交流时长)与预测值成弱相关性 (0.39),pdays(距离上次活动最后一次联系该客户,过去了多久)和previous(在本次活动之前,与该客户交流过的次数)成相关性 (0.45)。
模型选取与训练
从上述的数据分析,我们可以得知我们所要解决的是一个二分类问题,由已知的特征来推断结果的取值(0或者1),这里我们使用随机森林的方法解决该问题。随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支------集成学习(Ensemble Learning)方法。
在随机森林中,每棵决策树都是一个分类器(假设现在针对的是分类问题),那么对于一个输入样本,N棵树会有N个分类结果。而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出,这就是一种最简单的 Bagging 思想。其工作流程如下:
-
从数据集中随机选择k个特征(列),共m个特征(其中k小于等于m)。然后根据这k个特征建立决策树。
-
重复n次,这k个特性经过不同随机组合建立起来n棵决策树(或者是数据的不同随机样本,称为自助法样本)。
-
对每个决策树都传递随机变量来预测结果。存储所有预测的结果(目标),你就可以从n棵决策树中得到n种结果。
-
计算每个预测目标的得票数再选择模式(最常见的目标变量)。即将得到高票数的预测目标作为随机森林算法的最终预测。
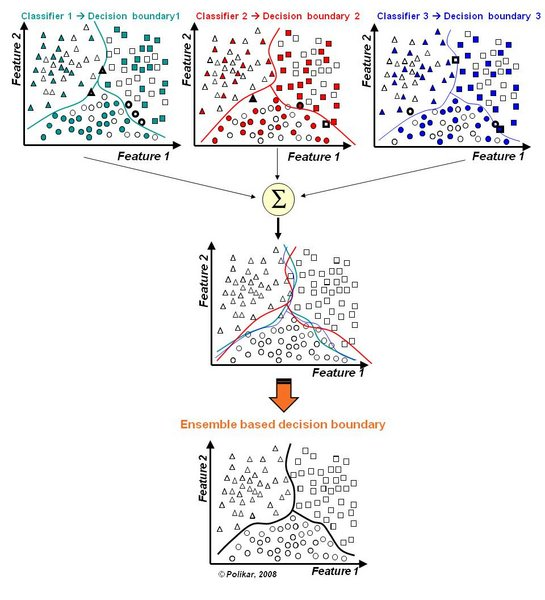
图一 随机森林的原理
sklearn做为一个强大机器学习工具,为我们提供了随机森林的函数接口:sklearn.ensemble.RandomForestClassifier。不仅如此,我们还可以使用它进行训练集和测试集的划分。下面我们便使用该工具完成上述数据集的训练,来探究各特征与预测结果之间存在的内在联系。我们的训练过程将包含以下几个方面:
- 数据处理
- 训练测试集的划分
- 模型训练
- 预测和对比
这里着重说明一下数据处理时需要将特征属性里的字符变量转化为整形变量以适应于模型学习
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier # 导入随机森林模型
from sklearn.model_selection import train_test_split # 导入数据集划分模块
import matplotlib.pyplot as plt
# 数据的读入与处理
data_path ='/data/shixunfiles/e6b0ca77f3f200ec5428e04dd104da53_1612443396928.csv'
df = pd.read_csv(data_path,sep=';')
print("这是原始的数据")
df.info()
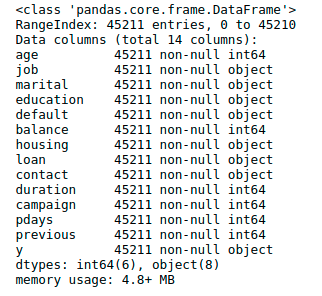
# 去除'day','month','poutcome'特征属性
df.drop(['day','month','poutcome'], axis=1, inplace=True)
# 替换部分样本值
df['job'].replace(['unknown'],df['job'].mode(),inplace=True)
df['job'].isin(['unknown']).sum()
df['education'].replace(['unknown'],df['education'].mode(),inplace=True)
df['education'].isin(['unknown']).sum()
print("\n这是处理过缺省值的数据")
df.info()
# 将特征采用哑变量进行编码,字符型特征经过转化可以进行训练
features=pd.get_dummies(df.iloc[:,:-1])
print("\n这是编码后的特征")
features.info()
# 将label编码
df['y'] = df['y'].replace(to_replace=['no', 'yes'], value=[0, 1])
labels=df.loc[:,'y']
print("\n这是标签的形式")
print(labels.head())
# 按4:1的比例划分训练和测试集
x_train, x_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=1)
# 构建模型
RFC=RandomForestClassifier(n_estimators=164,random_state=90)
#对训练集X_train训练
RFC.fit(x_train,y_train)
#给出训练的精度
print('\n训练集上的得分为:{}'.format(RFC.score(x_train,y_train)))
代码输出为:
这是原始的数据<class 'pandas.core.frame.DataFrame'>RangeIndex: 45211 entries, 0 to 45210Data columns (total 17 columns):age 45211 non-null int64job 45211 non-null objectmarital 45211 non-null objecteducation 45211 non-null objectdefault 45211 non-null objectbalance 45211 non-null int64housing 45211 non-null objectloan 45211 non-null objectcontact 45211 non-null objectday 45211 non-null int64month 45211 non-null objectduration 45211 non-null int64campaign 45211 non-null int64pdays 45211 non-null int64previous 45211 non-null int64poutcome 45211 non-null objecty 45211 non-null objectdtypes: int64(7), object(10)memory usage: 5.9+ MB
这是处理过缺省值的数据<class 'pandas.core.frame.DataFrame'>RangeIndex: 45211 entries, 0 to 45210Data columns (total 14 columns):age 45211 non-null int64job 45211 non-null objectmarital 45211 non-null objecteducation 45211 non-null objectdefault 45211 non-null objectbalance 45211 non-null int64housing 45211 non-null objectloan 45211 non-null objectcontact 45211 non-null objectduration 45211 non-null int64campaign 45211 non-null int64pdays 45211 non-null int64previous 45211 non-null int64y 45211 non-null objectdtypes: int64(6), object(8)memory usage: 4.8+ MB
这是编码后的特征<class 'pandas.core.frame.DataFrame'>RangeIndex: 45211 entries, 0 to 45210Data columns (total 32 columns):age 45211 non-null int64balance 45211 non-null int64duration 45211 non-null int64campaign 45211 non-null int64pdays 45211 non-null int64previous 45211 non-null int64job_admin. 45211 non-null uint8job_blue-collar 45211 non-null uint8job_entrepreneur 45211 non-null uint8job_housemaid 45211 non-null uint8job_management 45211 non-null uint8job_retired 45211 non-null uint8job_self-employed 45211 non-null uint8job_services 45211 non-null uint8job_student 45211 non-null uint8job_technician 45211 non-null uint8job_unemployed 45211 non-null uint8marital_divorced 45211 non-null uint8marital_married 45211 non-null uint8marital_single 45211 non-null uint8education_primary 45211 non-null uint8education_secondary 45211 non-null uint8education_tertiary 45211 non-null uint8default_no 45211 non-null uint8default_yes 45211 non-null uint8housing_no 45211 non-null uint8housing_yes 45211 non-null uint8loan_no 45211 non-null uint8loan_yes 45211 non-null uint8contact_cellular 45211 non-null uint8contact_telephone 45211 non-null uint8contact_unknown 45211 non-null uint8dtypes: int64(6), uint8(26)memory usage: 3.2 MB
这是标签的形式0 01 02 03 04 0Name: y, dtype: int64训练集上的得分为:1.0
从上述得分来看,我们得到了一个较好的训练结果,接下来我们就在测试集上进行指标衡量。
测试与指标衡量
上述的训练过程中我们只能大概看出模型对训练结果的拟合程度,我们还需要使用一系列指标在测试集上进行模型的衡量。分类模型的一般评价有如下几种方式:
- 准确率acc
- 精准率pre
- 召回率recall
- f1-Score
- auc曲线
这几个指标可由混淆矩阵计算得到,我们先来看一下混淆矩阵的产生,它是由预测结果和标签值进行计算得到的,如下图所示:
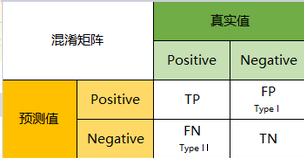
图二 混淆矩阵
下面我们使用混淆矩阵进行这几个指标的说明:
准确率:Accuracy = (TP+TN)/(TP+FN+FP+TN)
解释:(预测正确)/(预测对的和不对的所有结果),即预测正确的比例。
API:score()方法返回的就是模型的准确率
精确率:Precision = TP/(TP+FP)解释:预测结果为正例样本(TP+FP)中真实值为正例(TP)的比例。
API:accuracy_score
召回率:Recall = TP/(TP+FN)解释:真正为正例的样本中预测结果为正例的比例。正样本有多少被找出来了(召回了多少)
API:recall_score
综合精确率和召回率的指标 :f1-score解释:F1分数(F1-score)是分类问题的一个衡量指标 ,f1-score是精确率和召回率的调和平均数 ,最大为1,最小为0 。
API:f1_score
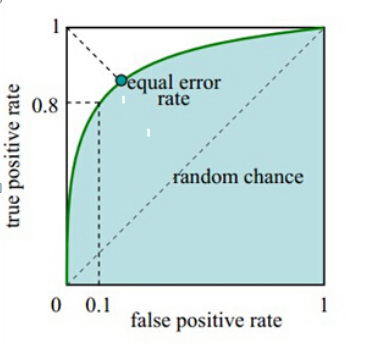
AUC:ROC曲线下的面积解释:在理想情况下,最佳的分类器应该尽可能地处于左上角,这就意味着分类器在伪反例率(预测错的概率FPR = FP / (FP + TN))很低的同时获得了很高的真正例率(预测对的概率TPR = TP / (TP + FN))。也就是说ROC曲线围起来的面积越大越好,因为ROC曲线面积越大,则曲线上面的面积越小,则分类器越能停留在ROC曲线的左上角。
API:
from sklearn.metrics import roc_auc_score
y_pre = predict_proba(x_test)
auc=roc_auc_score(y_test,y_pre[:,1])
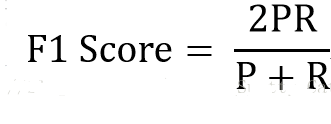
下面我们就使用这几个指标进行模型性能评估:
from sklearn.metrics import roc_auc_score
from sklearn.metrics import classification_report
#对于测试集x_test进行预测
x_pre_test=RFC.predict(x_test)
print("测试数据为:\n")
print(x_test)
print("\n预测结果为:\n")
print(x_pre_test)
# 其他指标计算
print(classification_report(y_test, x_pre_test))
# 预测测试集概率值
x_pro_test = RFC.predict_proba(x_test)
print("验证集的预测可能性:{}".format(x_pro_test))
#计算验证集的auc值,参数为预测值和概率估计
auc=roc_auc_score(y_test, x_pro_test[:, 1])
print("auc的值:{}".format(auc))
代码运行结果如下: 验证集的预测可能性:[[1. 0. ] [1. 0. ] [0.51829268 0.48170732] ... [0.90243902 0.09756098] [1. 0. ] [0.86585366 0.13414634]] auc的值:0.888028930075721
上述结果可以看出,我们最后测试集的auc达到了0.888,模型得到了很好训练。
代码介绍
想要对一个实际任务进行很好的建模,首先需要掌握数据集的处理。 因此首先使用drop()函数去除'day','month','poutcome'等特征属性。该函数的第一个参数为这三个属性特征列表,第二个参数代表需要删除的维度,本次任务中需要对维度1进行操作即axis=1,并且需要将处理好的数据替代原先的数据,因此将第三个参数inplace设置为true。
接着需要对特征进行one-hot编码,使用到函数get_dummies()。本次任务,使用iloc()函数来提取行数据,并作为get_dummies()函数的输入参数,进行one-hot编码,其他参数都选择默认即可。
最后,使用RandomForestClassifier()函数构建集成学习模型随机森林,并使用fit()函数进行训练。 RandomForestClassifier()函数参数如下:
- n_estimators : integer, optional (default=10)整数,可选择(默认值为10)。森林里(决策)树的数目,本次任务设置为164。
- random_state : int, RandomState instance or None, optional (default=None) 整数,RandomState实例,或者为None,可选(默认值为None)。是随机数生成器使用的种子,本次任务设置为90。
编程要求
依据上述相关知识点及示例,对银行营销数据集进行分析,完成去除异常值,将属性值和标签进行转换。
测试说明
平台会对你编写的代码进行测试。 无输入; 预期输出:
训练集上的得分为:1.0precision recall f1-score support0 0.92 0.97 0.94 79931 0.57 0.34 0.43 1050micro avg 0.89 0.89 0.89 9043macro avg 0.75 0.65 0.68 9043weighted avg 0.88 0.89 0.88 9043
验证集的预测可能性:[[1. 0. ][1. 0. ][0.51829268 0.48170732]...[0.90243902 0.09756098][1. 0. ][0.86585366 0.13414634]]auc的值:0.888028930075721
第1关任务------代码题
python
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier # 导入随机森林模型
from sklearn.model_selection import train_test_split # 导入数据集划分模块
import matplotlib.pyplot as plt
from sklearn.metrics import roc_auc_score
from sklearn.metrics import classification_report
# 数据的读入与处理
data_path ='/data/bigfiles/6e36e995-2472-4362-8f4e-bae6da732da2'
df = pd.read_csv(data_path,sep=';')
######Begin ######
# 任务1. 去除'day','month','poutcome'特征属性
df.drop(['day','month','poutcome'], axis=1, inplace=True)
###### End ######
######Begin ######
# 任务2. 替换部分样本值
df['job'].replace(['unknown'],df['job'].mode(),inplace=True)
df['job'].isin(['unknown']).sum()
df['education'].replace(['unknown'],df['education'].mode(),inplace=True)
df['education'].isin(['unknown']).sum()
###### End ######
######Begin ######
# 任务3. 将特征采用哑变量进行编码,字符型特征经过转化可以进行训练
features=pd.get_dummies(df.iloc[:,:-1])
###### End ######
df['y'] = df['y'].replace(to_replace=['no', 'yes'], value=[0, 1])
labels=df.loc[:,'y']
x_train, x_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=1)# 按4:1的比例划分训练和测试集
######Begin ######
# 任务4. 构建模型, 并对训练集X_train训练
#RFC = RandomForestClassifier(n_estimators=100, max_depth=2, random_state=0)
RFC=RandomForestClassifier(n_estimators=164,random_state=90)
RFC.fit(x_train, y_train)
###### End ######
print('\n训练集上的得分为:{}'.format(RFC.score(x_train,y_train)))# 给出训练的精度
x_pre_test=RFC.predict(x_test)# 对于测试集x_test进行预测
print(classification_report(y_test, x_pre_test))# 其他指标计算
x_pro_test = RFC.predict_proba(x_test)# 预测测试集概率值
print("验证集的预测可能性:{}".format(x_pro_test))
auc=roc_auc_score(y_test, x_pro_test[:, 1])#计算验证集的auc值,参数为预测值和概率估计
print("auc的值:{}".format(auc))