第一篇: System Introduction
第二篇:State of the Art
第三篇:localization
第四篇:Submapping and temporal weighting
第五篇:Mapping of Point-shaped landmark data
第六篇:Clustering of landmark data
第七篇:fusion of point-shaped landmark data
第八篇:fusion of complex landmark data
第九篇:fusion of areal data
第十篇:instaniation at the vehicle and backend sid
第十一篇:future work
第十二篇:Mathematical Nomenclature

序言
对于自动驾驶汽车和下一代驾驶辅助系统来说,代表道路网络及其当前状态的数字地图变得越来越重要。数字地图可以被视为一种具有广泛远见的附加虚拟传感器,它以合理的方式扩展了现代车辆的典型传感器集。这种虚拟传感器的一个特殊优势是它不会暴露在遮挡或恶劣的天气条件下。但是,它直接受到它所依据的地图数据的质量和新鲜度的影响。因此,高质量和最新的地图是强制性的,特别是如果将地图纳入安全关键系统,例如自动驾驶系统。
难点
在当今时代,由知名地图数据提供商的专门装备的车辆绘制道路网络地图导致通常每季度更新一次地图。这种低更新频率对于自动驾驶汽车来说尤其是一个问题。
现代车辆包含多种类型的传感器,可用于获取 CVD,从而用于道路网络的协作映射以及通过传感器数据融合获取有关其当前状态的信息。
此外,地图通常缺乏具体的细节,例如环形交叉路口的确切几何形状,或有关具有快速时间衰减的道路网络的信息,例如路段湿滑。

解决这一问题的一种方法是利用当今常见车辆中包含的多种类型的不同传感器,例如摄像头、超声波传感器、激光雷达、雷达、照明/雨量/温度传感器、惯性传感器和 GNSS 接收器。道路网络和有关其当前状态的信息可以由普通车辆使用这些传感器协作收集,并传输到公共后端,然后将它们融合到详细的最新地图上,并附有补充信息,这些信息被反向传播到车辆以供进一步使用。例如,由于商业限制,普通车辆的传感器并不总是达到测绘车辆昂贵、高度专业化设备的质量。然而,由于普通车辆能够协同获取大量相应的传感器数据,因此希望在实践中通过利用测量的冗余来弥补数据的缺陷。这种基于CVD的高精度和高度最新的地图数据和补充信息的推导方式可以被认为是一种非常有前途的方法,它将支持下一代驾驶和驾驶辅助功能。
提取、定位和融合
三个关键步骤对于道路网络的协作测绘和通过普通车辆获取有关其当前状态的信息至关重要:从车队中提取传感器数据、准确定位以及精确而强大的融合
提取是指从车辆中获取CVD并将其传播到公共后端的过程。到达后端的数据可以直接来自传感器,也可以由ECU在车辆端进行预处理。然而,由于蜂窝网络施加的带宽限制和后端计算资源的限制,传感器原始数据的传播通常被认为是不可行的。相反,更简洁地表示这些数据的替代方法是非常可取的。定位是指检测车辆的当前地理位置。准确的定位对于采集的传感器数据的精确地理参考至关重要。通常认为,定位的质量直接影响融合的质量。从大地测量学中可以知道高精度的定位方法,通常提供厘米范围内的绝对精度。然而,由于经济限制,这些方法通常不能直接纳入普通车辆。不幸的是,这现在不包括双频和多频 GNSS 接收机以及高级 IMU。因此,需要其他方法来获得精确的车辆导航。Fusion关注的是以一种获得高精度和大比例尺地图的方式组合协作获取和随后引用的传感器数据。不同类型的真实世界工件(例如交通标志或摩擦数据)通常需要不同的方法。另一方面,CVD融合的通用方法将最大限度地减少新用例和工件类型的适应时间。将这两种主要相反的要求结合起来是一个挑战。
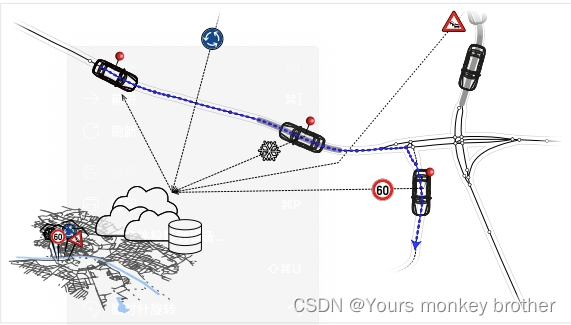
上图 中可视化了包括 CVD 的采集、融合和反向传播在内的说明性场景。检测到的环形交叉路口、湿滑的路段、走走停停的交通和交通标志观察结果通过蜂窝网络向后端报告。在后端,接收到的CVD被融合并作为先验数据提供给后续车辆。
通用性 Universality
通用性意味着合并的采集、传播和处理步骤适用于不同类型的 CVD。这样,可以显著降低开发和维护成本,并减轻对新用例和CVD类型的适应。普遍性的要求可以被认为影响到整个CVD链。
可扩展性 Scalability
CVD的处理是解决大规模问题所必需的。为此,用于处理 CVD 的管道需要具有可扩展性。水平缩放特别令人感兴趣,因为它能够将通常计算成本高昂的处理扩展到理论上无限数量的计算单元。相比之下,在大量获得性心血管疾病的背景下,垂直规模的影响是有限的,但仍然不应忽视。
增量 Incrementality
通常,在新的 CVD 输入的情况下,增量允许重新利用以前的计算结果来确定后续聚合。通常,这样可以节省宝贵的计算资源。特别是在具有大量数据的应用程序的情况下,增量性非常重要
高精度和稳健性 High-Precision and Robustness
高精度和鲁棒性 由于衍生的地图数据和信息主要用于自动驾驶汽车和下一代驾驶辅助系统,因此必须特别考虑融合的精度和鲁棒性。精度通常可以通过确定与地面实况的偏差来衡量。鲁棒性的测量通常更复杂,通常需要为每个应用单独定义。例如,融合算法的鲁棒性可以根据其发散风险来确定,而聚类算法的鲁棒性可以根据其不希望的聚类拆分风险来确定。
时间衰减补偿 Compensation for Temporal Decay
道路网络及其当前状态的信息暴露在环境动态中。因此,CVD受时间衰减的显著影响,应仅以适当的加权方式融合。然而,时间加权可以被认为是一项具有挑战性的任务,因为实际衰减率实际上受到流形方面的影响。