目录
[1、先理清关系:Transformer、BERT、RoBERTa 是啥?](#1、先理清关系:Transformer、BERT、RoBERTa 是啥?)
[2、RoBERTa 和 BERT、Transformer 的关键区别](#2、RoBERTa 和 BERT、Transformer 的关键区别)
[2.1、和 BERT 的核心差异](#2.1、和 BERT 的核心差异)
[2.2、和 Transformer 的关系](#2.2、和 Transformer 的关系)
[3、从 0 到 1 预训练 RoBERTa,到底咋做?](#3、从 0 到 1 预训练 RoBERTa,到底咋做?)
[3.1、词元处理:字节对编码(BPE)------ 文本变 "模型能懂的码"](#3.1、词元处理:字节对编码(BPE)—— 文本变 “模型能懂的码”)
[3.2、模型初始化:搭好 Transformer "骨架",配置参数](#3.2、模型初始化:搭好 Transformer “骨架”,配置参数)
[3.3、数据准备:喂给模型 "超级语料大餐"](#3.3、数据准备:喂给模型 “超级语料大餐”)
[3.4、预训练核心:动态掩码 + 疯狂训练,让模型 "学透语言"](#3.4、预训练核心:动态掩码 + 疯狂训练,让模型 “学透语言”)
[3.5、下游任务:预训练模型 "变现",解决实际问题](#3.5、下游任务:预训练模型 “变现”,解决实际问题)
[4.13.1、 先 "教模型认字":训练专属词元分析器(Tokenizer)](#4.13.1、 先 “教模型认字”:训练专属词元分析器(Tokenizer))
[4.13.2、搭 "模型骨架":定义 RoBERTa 模型的结构](#4.13.2、搭 “模型骨架”:定义 RoBERTa 模型的结构)
[4.13.3、让模型 "学说话":用康德文本训练模型](#4.13.3、让模型 “学说话”:用康德文本训练模型)
[5.1、什么是 BPE(字节对编码)?](#5.1、什么是 BPE(字节对编码)?)
[5.2、为什么是 ByteLevelBPETokenizer?](#5.2、为什么是 ByteLevelBPETokenizer?)
[8、为什么用 RobertaForMaskedLM?](#8、为什么用 RobertaForMaskedLM?)
在大语言模型的世界里,Transformer 是地基,BERT 是经典,而 RoBERTa 则是站在 BERT 肩膀上的 "优化版选手"。今天咱们用大白话,从 0 到 1 拆解RoBERTa 预训练全流程,顺道讲清它和 Transformer、BERT 的核心区别,让你读完就懂!
1、先理清关系:Transformer、BERT、RoBERTa 是啥?
- Transformer:是 NLP 里的 "万能积木",靠注意力机制(Attention)处理文本,能高效捕捉词与词的关系。不管是 BERT、RoBERTa,还是 GPT,底层都用它做 "骨架"。
- BERT :基于 Transformer 的 "初代预训练明星",用 "掩码语言模型(MLM)+ 下一句预测(NSP)" 学文本规律,但有不少可优化的点。
-
掩码语言模型(MLM) 就像做 "填空题":
比如给你一句话 "我今天____了一杯奶茶",中间挖个空(掩码),让你猜空里该填 "喝" 还是 "买"。
模型练多了这种题,就知道 "奶茶" 搭配 "喝""买" 更合理,慢慢懂了词语之间的关系。 -
下一句预测(NSP) 就像做 "连线题":
给你两句话,比如 "小明出门带了伞" 和 "外面下雨了",让你判断这两句话是不是前后脚发生的(是不是一对儿)。
模型练多了就知道,"带伞" 和 "下雨" 通常是连着的,而 "我爱吃西瓜" 和 "地球是圆的" 就没啥关系,慢慢懂了句子之间的逻辑。
-
- RoBERTa :BERT 的 "升级版",核心是优化训练策略,把 BERT 的缺点(比如训练不充分、数据利用差)狠狠改掉,性能直接拉满!
2、RoBERTa 和 BERT、Transformer 的关键区别
2.1、和 BERT 的核心差异
- 训练更 "猛" :
- BERT 训练时,掩码(Mask)是 "static(静态)" 的 ------ 一份文本的掩码方式固定,模型容易 "记答案"。
- RoBERTa 改成 "dynamic(动态) " 掩码 ------同一段文本,每次训练都换掩码方式,逼着模型学透语言规律,鲁棒性更强!
- 举个🌰:"我喜欢吃苹果",BERT 可能固定把 "苹果" 掩码,RoBERTa 会随机选 "喜欢""吃" 等不同词掩码,训练更灵活。
- 数据玩得更溜 :
- BERT 用的数据集小,还加了 "下一句预测(NSP)" 任务,但这任务容易误导模型(比如两句来自不同文档时)。
- RoBERTa 直接干掉 NSP 任务,只用 MLM;还疯狂扩容数据集(比如用更大的新闻、书籍语料),让模型见多识广。
- 训练更持久 :
- BERT 训练步数少,模型没 "学透"。RoBERTa拉长训练时间、加大 batch size,让模型把语言规律挖到骨子里。
2.2、和 Transformer 的关系
Transformer 是 "骨架",RoBERTa 是 "精装修版":
- Transformer 是基础架构(就像汽车的发动机 + 底盘),RoBERTa 则是在 Transformer 之上,加了预训练流程、优化了训练策略的完整模型(相当于给汽车做了内饰、调了性能,直接能上路跑任务)。
3、从 0 到 1 预训练 RoBERTa,到底咋做?
3.1、词元处理:字节对编码(BPE)------ 文本变 "模型能懂的码"
简单说,BPE 是把文本拆成 "子词单元" 的方法,让模型处理生僻词、复杂词更灵活。
- 比如 "苹果手机",可能拆成 "苹果"+"手机";遇到没见过的词(比如 "蘋菓"),也能拆成 "蘋"+"菓" 等子词,保证模型能处理。
- RoBERTa 的词表比 BERT 大(50K vs 30K),能覆盖更多生僻表达,处理文本更细腻。
3.2、模型初始化:搭好 Transformer "骨架",配置参数
- 抄作业式配置:直接用 RoBERTa 的标准参数(比如隐藏层维度 768、注意力头数 12 等),把 Transformer 的 "积木" 搭成 RoBERTa 的 "身子"。
- 区别 BERT:BERT 初始化时带着 NSP 任务的 "包袱",RoBERTa 直接去掉,轻装上阵,只用 MLM 任务学文本。
3.3、数据准备:喂给模型 "超级语料大餐"
- 搞到海量文本:新闻、小说、网页内容...... 啥文本都往里头塞,让模型见多识广。
- 清洗 + 切分:去掉乱码、重复内容,把文本切成模型能吃的 "小批次"(batch),方便训练。
3.4、预训练核心:动态掩码 + 疯狂训练,让模型 "学透语言"
- 动态掩码:同一句话,每次训练都换掩码位置(比如这次遮 "喜欢",下次遮 "苹果"),逼着模型理解语义,而不是 "死记硬背"。
- 干掉 NSP:只保留 "掩码预测" 任务,让模型专注学单句 / 长文本的语义,避免 NSP 任务的干扰。
- 猛训到底:加大训练步数、batch size,让模型把语言规律 "刻进 DNA",比 BERT 学得更扎实。
3.5、下游任务:预训练模型 "变现",解决实际问题
比如做文本分类(垃圾邮件识别) 、情感分析(商品评论好坏判断):
- 微调模型:拿预训练好的 RoBERTa,在具体任务数据上 "接着训",让模型适应新任务。
- 对比 BERT:因为 RoBERTa 预训练更充分,微调后在很多任务(比如长文本理解)上效果比 BERT 好。
4、完整实现
4.1、加载数据集
python
"""查看数据集是否加载成功"""
try:
# 直接按行读取文件
with open('kant.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
# 转为DataFrame
df = pd.DataFrame({'text': lines})
print(f"数据加载成功,行数: {df.shape[0]}")
# 检查每行的分隔符数量
df['tabs'] = df['text'].str.count('\t')
df['commas'] = df['text'].str.count(',')
print("分隔符统计:")
print(df[['tabs', 'commas']].describe())
# 检查异常行
abnormal_lines = df[df['tabs'] > 1]
print(f"包含多个制表符的行数: {len(abnormal_lines)}")
if len(abnormal_lines) > 0:
print("异常行预览:")
print(abnormal_lines.head())
print("随机样本:")
print(df['text'].sample(5).str.strip()) # 显示时去除首尾空白
except Exception as e:
print(f"加载数据时出错: {e}")数据加载成功,行数: 188287
分隔符统计:
tabs commas
count 188287.000000 188287.000000
mean 0.000351 0.798759
std 0.032426 0.891635
min 0.000000 0.000000
25% 0.000000 0.000000
50% 0.000000 1.000000
75% 0.000000 1.000000
max 4.000000 13.000000
包含多个制表符的行数: 24
异常行预览:
text tabs commas
24646 \t\t\t\t 1788\n 4 0
24648 \t\t THE CRITIQUE OF PRACTICAL REASON\n 2 0
24650 \t\t\t by Immanuel Kant\n 3 0
24652 \t\ttranslated by Thomas Kingsmill Abbott\n 2 0
56027 \t\t\t\t 1788\n 4 0
随机样本:
11698 an clement, the term atomus would be more appr...
72360 (as many have really done) that, which at best...
169930 After this proof of the viciousness of the arg...
38017 contains an occurrence, I call the antecedent ...
33862 to objects as things in themselves never can b...
Name: text, dtype: object
4.2、训练词元分析器
python
"""训练词元分析器"""
# 让模型适配特定数据的语言规律
paths = [str(x) for x in Path(".").glob("**/*.txt")]
tokenizer = ByteLevelBPETokenizer()
# files=paths 数据集的路径
# vocab_size=52_000 词元分析器词表的大小
# min_frequency=2 最小频率阈值
# special_tokens=[]特殊词元列表
tokenizer.train(files=paths, vocab_size=52_000, min_frequency=2, special_tokens=[
"<s>", #开始词元
"<pad>", #填充词元
"</s>", #结束词元
"<unk>",#未知词元
"<mask>",#用于语言建模的掩码词元
])4.3、将词元结果保存到磁盘上
python
"""将词元结果保存到磁盘上"""
token_dir = '/Chapter04/KantaiBERT' # 定义保存目录路径
if not os.path.exists(token_dir): # 检查目录是否存在
os.makedirs(token_dir) # 若不存在则创建目录
tokenizer.save_model(token_dir) # 将词元分析器保存到该目录
4.4、加载预训练词元分析器文件
python
"""加载预训练词元分析器文件"""
# 加载预训练的分词器
tokenizer = ByteLevelBPETokenizer(
"./KantaiBERT/vocab.json",
"./KantaiBERT/merges.txt",
)
# 测试分词器
print(tokenizer.encode("The Critique of Pure Reason.").tokens)#分词后的词元列表
print(tokenizer.encode("The Critique of Pure Reason."))#完整的编码结果,包括词元 ID、注意力掩码等信息
# 配置后处理器
# 为编码后的文本添加特殊标记:在开头添加<s>,在结尾添加</s>
# 这是 Transformer 模型常用的格式,用于区分不同的句子
tokenizer._tokenizer.post_processor = BertProcessing(
("</s>", tokenizer.token_to_id("</s>")),
("<s>", tokenizer.token_to_id("<s>")),
)
# 启用序列截断
# 将输入文本截断为最大长度 512 个词元
# 这是因为 Transformer 模型通常对输入长度有限制
tokenizer.enable_truncation(max_length=512)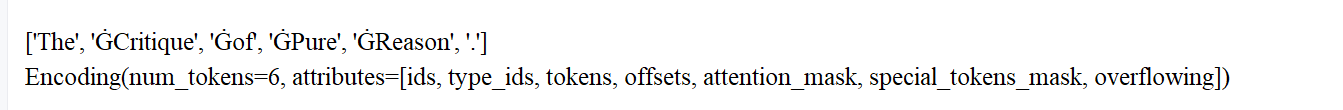
4.5、定义模型配置
python
"""定义模型配置"""
# RoBERTa 模型的配置
config = RobertaConfig(
vocab_size=52_000, #词汇表大小:模型能够处理的唯一词元(tokens)数量 这个值应与之前训练的分词器(Tokenizer)的词汇表大小一致
max_position_embeddings=514, #最大位置编码:模型能够处理的最大序列长度(包含特殊标记)
num_attention_heads=12,#注意力头数量:多头注意力机制中的并行注意力头数量。
num_hidden_layers=6,#隐藏层数:Transformer 编码器的层数(即堆叠的 Transformer 块数量)
type_vocab_size=1, #类型词汇表大小:用于区分不同类型的输入(例如,在问答任务中区分问题和答案)
)
print(config)RobertaConfig {
"attention_probs_dropout_prob": 0.1,
"bos_token_id": 0,
"classifier_dropout": null,
"eos_token_id": 2,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 514,
"model_type": "roberta",
"num_attention_heads": 12,
"num_hidden_layers": 6,
"pad_token_id": 1,
"position_embedding_type": "absolute",
"transformers_version": "4.53.2",
"type_vocab_size": 1,
"use_cache": true,
"vocab_size": 52000
}
4.6、为Transformer模型加载词元分析器
python
"""为Transformer模型加载词元分析器"""
# RobertaTokenizer:专为 RoBERTa 模型设计的分词器,继承自 ByteLevelBPETokenizer,支持 BPE 子词分词。
# from_pretrained():从指定路径或 Hugging Face 模型库加载预训练的分词器。
# "./KantaiBERT":本地路径,应包含以下文件:
# vocab.json:词元到 ID 的映射表(如 {"<s>": 0, "ĠHello": 468, ...})。
# merges.txt:BPE 合并规则(定义如何将字符组合成子词)。
# special_tokens_map.json:特殊标记(如 <s>, </s>, <pad>)的配置。
# tokenizer_config.json:分词器的配置参数(如是否使用小写、特殊标记列表)。
tokenizer = RobertaTokenizer.from_pretrained("./KantaiBERT", max_length=512)4.7、从头开始初始化RoBERTa模型
python
"""从头开始初始化RoBERTa模型"""
# 基于 RoBERTa 架构的掩码语言模型
model = RobertaForMaskedLM(config=config)
print(model)RobertaForMaskedLM(
(roberta): RobertaModel(
(embeddings): RobertaEmbeddings(
(word_embeddings): Embedding(52000, 768, padding_idx=1)
(position_embeddings): Embedding(514, 768, padding_idx=1)
(token_type_embeddings): Embedding(1, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): RobertaEncoder(
(layer): ModuleList(
(0-5): 6 x RobertaLayer(
(attention): RobertaAttention(
(self): RobertaSdpaSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): RobertaSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): RobertaIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): RobertaOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
)
(lm_head): RobertaLMHead(
(dense): Linear(in_features=768, out_features=768, bias=True)
(layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(decoder): Linear(in_features=768, out_fe
atures=52000, bias=True)
)
)
4.8、构建数据集
python
"""构建数据集"""
# 它会逐行读取文本文件,并使用分词器将每行文本转换为模型可接受的格式
dataset = LineByLineTextDataset(
tokenizer=tokenizer, #指定用于处理文本的分词器,会将文本转换为词元 (token) 序列
file_path="./kant.txt", #指定要读取的文本文件路径
block_size=128, #指定每个样本的最大长度(词元数量)
)4.9、定义数据整理器
python
"""定义数据整理器"""
# 在训练时自动对输入文本进行随机掩码,并生成对应的标签,让模型学习预测被掩码的词元
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer, #指定使用的分词器,用于识别特殊标记(如 <mask>)和处理词元
mlm=True, #启用 掩码语言模型(MLM) 任务。 如果设为 False,则退化为 下一句预测(NSP) 或其他任务(取决于模型类型)
mlm_probability=0.15 #掩码比例:随机选择 15% 的词元进行掩码
)4.10、初始化训练器
python
"""初始化训练器"""
"""通过 TrainingArguments 和 Trainer 封装了复杂的训练流程,让用户可以专注于模型和数据的定义。
训练器会自动处理数据加载、批次处理、模型保存、梯度计算等细节,大大简化了训练过程"""
# output_dir:训练过程中模型和日志的保存路径
# overwrite_output_dir:如果输出目录已存在,是否覆盖
# num_train_epochs:训练的总轮数(整个数据集被训练的次数)
# per_device_train_batch_size:每个设备(GPU/CPU)的训练批次大小
# save_steps:每训练多少步保存一次模型
# save_total_limit:最多保存的模型检查点数量,超过会删除旧的
training_args = TrainingArguments(
output_dir="./KantaiBERT",
overwrite_output_dir=True,
num_train_epochs=1,
per_device_train_batch_size=64,
save_steps=10_000,
save_total_limit=2,
)
# model:要训练的模型(前面定义的 RobertaForMaskedLM)
# args:训练参数配置
# data_collator:数据整理器,负责处理输入数据(如添加掩码)
# train_dataset:训练数据集
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=dataset,
)4.11、结尾
python
"""预训练模型"""
trainer.train()
"""将最终模型+词元分析器+配置保存到磁盘"""
trainer.save_model("./KantaiBERT")
"""采用FillMaskPipeline进行语言建模"""
fill_mask = pipeline(
"fill-mask",
model="./KantaiBERT",
tokenizer="./KantaiBERT"
)
fill_mask("Human thinking involves human <mask>.")
{'score': 0.040214285254478455, 'token': 393, 'token_str': ' reason', 'sequence': 'Human thinking involves human reason.'}, {'score': 0.01567867584526539, 'token': 605, 'token_str': ' conceptions', 'sequence': 'Human thinking involves human conceptions.'}, {'score': 0.01390938088297844, 'token': 531, 'token_str': ' experience', 'sequence': 'Human thinking involves human experience.'}, {'score': 0.009885288774967194, 'token': 600, 'token_str': ' understanding', 'sequence': 'Human thinking involves human understanding.'}, {'score': 0.00963951088488102, 'token': 586, 'token_str': ' nature', 'sequence': 'Human thinking involves human nature.'}
4.12、完整代码
python
"""
文件名: KantaiBERT
作者: 墨尘
日期: 2025/7/28
项目名: llm_finetune
"""
import pandas as pd
from pathlib import Path
from transformers import pipeline
from tokenizers.implementations import ByteLevelBPETokenizer
from tokenizers.processors import BertProcessing
# RobertaForMaskedLM导入一个RoBERTa掩码模型
from transformers import RobertaTokenizer, RobertaConfig, RobertaForMaskedLM,LineByLineTextDataset,DataCollatorForLanguageModeling,Trainer, TrainingArguments
import os
os.environ['TF_ENABLE_ONEDNN_OPTS'] = '0' # 禁用 oneDNN 优化
if __name__ == '__main__':
"""查看数据集是否加载成功"""
try:
with open('kant.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
df = pd.DataFrame({'text': lines})
print(f"数据加载成功,行数: {df.shape[0]}")
print("随机样本:")
print(df['text'].sample(5).str.strip())
except Exception as e:
print(f"加载数据时出错: {e}")
# 获取语料库文件路径
paths = [str(x) for x in Path(".").glob("**/*.txt")]
# 初始化 tokenizer(0.21 版本兼容写法)
tokenizer = ByteLevelBPETokenizer()
# 训练 tokenizer
tokenizer.train(
files=paths,
vocab_size=52_000,
min_frequency=2,
special_tokens=[
"<s>", "<pad>", "</s>", "<unk>", "<mask>"
]
)
"""训练词元分析器"""
# 让模型适配特定数据的语言规律
paths = [str(x) for x in Path(".").glob("**/*.txt")]
tokenizer = ByteLevelBPETokenizer()
# files=paths 数据集的路径
# vocab_size=52_000 词元分析器词表的大小
# min_frequency=2 最小频率阈值
# special_tokens=[]特殊词元列表
tokenizer.train(files=paths, vocab_size=52_000, min_frequency=2, special_tokens=[
"<s>", #开始词元
"<pad>", #填充词元
"</s>", #结束词元
"<unk>",#未知词元
"<mask>",#用于语言建模的掩码词元
])
"""将词元结果保存到磁盘上"""
token_dir = '/Chapter04/KantaiBERT' # 定义保存目录路径
if not os.path.exists(token_dir): # 检查目录是否存在
os.makedirs(token_dir) # 若不存在则创建目录
tokenizer.save_model(token_dir) # 将词元分析器保存到该目录
"""加载预训练词元分析器文件"""
# 加载预训练的分词器
tokenizer = ByteLevelBPETokenizer(
"./KantaiBERT/vocab.json",
"./KantaiBERT/merges.txt",
)
# 测试分词器
print(tokenizer.encode("The Critique of Pure Reason.").tokens)#分词后的词元列表
print(tokenizer.encode("The Critique of Pure Reason."))#完整的编码结果,包括词元 ID、注意力掩码等信息
# 配置后处理器
# 为编码后的文本添加特殊标记:在开头添加<s>,在结尾添加</s>
# 这是 Transformer 模型常用的格式,用于区分不同的句子
tokenizer._tokenizer.post_processor = BertProcessing(
("</s>", tokenizer.token_to_id("</s>")),
("<s>", tokenizer.token_to_id("<s>")),
)
# 启用序列截断
# 将输入文本截断为最大长度 512 个词元
# 这是因为 Transformer 模型通常对输入长度有限制
tokenizer.enable_truncation(max_length=512)
"""定义模型配置"""
# RoBERTa 模型的配置
config = RobertaConfig(
vocab_size=52_000, #词汇表大小:模型能够处理的唯一词元(tokens)数量 这个值应与之前训练的分词器(Tokenizer)的词汇表大小一致
max_position_embeddings=514, #最大位置编码:模型能够处理的最大序列长度(包含特殊标记)
num_attention_heads=12,#注意力头数量:多头注意力机制中的并行注意力头数量。
num_hidden_layers=6,#隐藏层数:Transformer 编码器的层数(即堆叠的 Transformer 块数量)
type_vocab_size=1, #类型词汇表大小:用于区分不同类型的输入(例如,在问答任务中区分问题和答案)
)
print(config)
"""为Transformer模型加载词元分析器"""
# RobertaTokenizer:专为 RoBERTa 模型设计的分词器,继承自 ByteLevelBPETokenizer,支持 BPE 子词分词。
# from_pretrained():从指定路径或 Hugging Face 模型库加载预训练的分词器。
# "./KantaiBERT":本地路径,应包含以下文件:
# vocab.json:词元到 ID 的映射表(如 {"<s>": 0, "ĠHello": 468, ...})。
# merges.txt:BPE 合并规则(定义如何将字符组合成子词)。
# special_tokens_map.json:特殊标记(如 <s>, </s>, <pad>)的配置。
# tokenizer_config.json:分词器的配置参数(如是否使用小写、特殊标记列表)。
tokenizer = RobertaTokenizer.from_pretrained("./KantaiBERT", max_length=512)
"""从头开始初始化RoBERTa模型"""
# 基于 RoBERTa 架构的掩码语言模型
model = RobertaForMaskedLM(config=config)
# print(model)
"""构建数据集"""
# 它会逐行读取文本文件,并使用分词器将每行文本转换为模型可接受的格式
dataset = LineByLineTextDataset(
tokenizer=tokenizer, #指定用于处理文本的分词器,会将文本转换为词元 (token) 序列
file_path="./kant.txt", #指定要读取的文本文件路径
block_size=128, #指定每个样本的最大长度(词元数量)
)
"""定义数据整理器"""
# 在训练时自动对输入文本进行随机掩码,并生成对应的标签,让模型学习预测被掩码的词元
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer, #指定使用的分词器,用于识别特殊标记(如 <mask>)和处理词元
mlm=True, #启用 掩码语言模型(MLM) 任务。 如果设为 False,则退化为 下一句预测(NSP) 或其他任务(取决于模型类型)
mlm_probability=0.15 #掩码比例:随机选择 15% 的词元进行掩码
)
"""初始化训练器"""
"""通过 TrainingArguments 和 Trainer 封装了复杂的训练流程,让用户可以专注于模型和数据的定义。
训练器会自动处理数据加载、批次处理、模型保存、梯度计算等细节,大大简化了训练过程"""
# output_dir:训练过程中模型和日志的保存路径
# overwrite_output_dir:如果输出目录已存在,是否覆盖
# num_train_epochs:训练的总轮数(整个数据集被训练的次数)
# per_device_train_batch_size:每个设备(GPU/CPU)的训练批次大小
# save_steps:每训练多少步保存一次模型
# save_total_limit:最多保存的模型检查点数量,超过会删除旧的
training_args = TrainingArguments(
output_dir="./KantaiBERT",
overwrite_output_dir=True,
num_train_epochs=1,
per_device_train_batch_size=64,
save_steps=10_000,
save_total_limit=2,
)
# model:要训练的模型(前面定义的 RobertaForMaskedLM)
# args:训练参数配置
# data_collator:数据整理器,负责处理输入数据(如添加掩码)
# train_dataset:训练数据集
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=dataset,
)
"""预训练模型"""
trainer.train()
"""将最终模型+词元分析器+配置保存到磁盘"""
trainer.save_model("./KantaiBERT")
"""采用FillMaskPipeline进行语言建模"""
fill_mask = pipeline(
"fill-mask",
model="./KantaiBERT",
tokenizer="./KantaiBERT"
)
print(fill_mask("Human thinking involves human <mask>."))4.13、整体流程
整体流程:从 "raw 文本" 到 " 能用的模型 "
可以分成 3 个核心阶段,一步步把原始文本变成能干活的模型:
4.13.1、 先 "教模型认字":训练专属词元分析器(Tokenizer)
- 输入 :原始文本文件(
kant.txt,康德的著作内容)。- 过程 :
- 代码先检查文本是否能正常读取(确保数据没问题)。
- 然后用 "字节对编码(BPE)" 算法,从文本里学 "认字规则":比如哪些字符经常一起出现(比如 "reason""critique" 这些康德文本里的高频词),把它们变成模型能理解的 "词元"(类似给模型做一本 "专属字典")。
- 最后把这本 "字典"(
vocab.json等文件)保存到本地,方便后续用。- 目的:让模型认识康德文本里的特殊术语、表达习惯,避免把 "纯理性" 拆成没意义的碎片。
4.13.2、搭 "模型骨架":定义 RoBERTa 模型的结构
- 过程 :
- 设定模型的 "骨架参数":比如词汇表大小(和上面的 "字典" 匹配)、模型能处理的最长句子长度(514 个词元)、用多少层 "Transformer 块"(6 层)、多少个 "注意力头"(12 个)等。
- 基于这些参数,初始化一个 "掩码语言模型(RoBERTaForMaskedLM)"------ 这是一种能通过上下文猜缺失词的模型(类似人做 "完形填空")。
- 目的:搭一个适合处理康德文本的 "模型架子",既不能太简单(学不会复杂语义),也不能太复杂(训练起来费劲)。
4.13.3、让模型 "学说话":用康德文本训练模型
- 过程 :
- 把原始文本转换成模型能 "吃" 的格式:按行切割文本,用前面的 "字典" 把文字变成数字(词元 ID),每段最长 128 个词元(方便批量训练)。
- 训练时用 "掩码策略":随机盖住 15% 的词(比如把 "Human thinking involves human <mask>." 里的
<mask>盖住),让模型猜被盖住的词是什么。- 设定训练规则:比如用多大的批次训练(每次喂 64 句话)、训练多少轮(1 轮,把整本康德文本学一遍)、多久保存一次模型等。
- 启动训练:模型通过不断 "猜词 - 改错",慢慢学会康德文本的语言规律(比如 "纯粹理性" 常和 "批判" 搭配,"思考" 常和 "理性" 关联)。
- 目的:让模型从 "认识字" 升级到 "懂语义",能根据康德文本的上下文,精准猜出缺失的词。
4.13.4、测试模型:看看学得怎么样
- 训练完后,用
fill_mask工具测试:比如输入 "Human thinking involves human <mask>.",模型会输出最可能的词(比如 "reason""reasoning" 等,符合康德文本中 "思考与理性" 的关联)。4.13.5、这个模型能干什么?
训练好的模型是 "懂康德文本" 的专家,主要用途有:
- 文本补全:给一句不完整的康德名言,补全缺失的词(比如 "纯粹理性的<mask>",模型可能会填 "批判")。
- 理解特殊文本:因为专门学了康德的术语和表达,比通用模型更懂这类哲学文本的语义(比如区分 "现象""本体" 这些哲学概念)。
- 后续还能扩展:在这个基础上继续训练,让它做更复杂的事(比如给康德文本分类、提取核心观点等)。
补充知识:
5、字节对编码
5.1、什么是 BPE(字节对编码)?
BPE 是一种流行的子词(Subword)分词算法,核心思想是:
- 从最小单位(字节 / 字符)开始,逐步合并出现频率最高的字符对,形成更大的词元。
- 动态构建词汇表 ,高频词会被保留为完整词元,低频词会被拆分为有意义的子词(如
unhappiness→un+happiness)。 - 处理未登录词(OOV):通过字节级别处理,任何文本都能被拆分为已知词元的组合,避免出现未知词。
通俗理解:
就像教模型 "拼字"
- 一开始,模型只认识最小的 "零件"(比如单个字母或汉字,像 "h""e""欢""乐")。
- 然后它会统计文本里哪些 "零件组合" 出现得最多(比如 "he""欢乐" 经常一起出现),就把这些组合变成新的 "大零件"。
- 重复这个过程,高频的组合会被拼成更大的 "块"(比如 "hello""快乐"),低频的词就拆成已有的 "零件"(比如 "unhappiness" 拆成 "un"+"happiness",因为这两个部分在其他词里也常见)。
这样做的好处:
- 遇到没见过的词(比如生僻词 "魑魅魍魉"),能拆成认识的 "零件"("魑""魅""魍""魉"),不会卡壳。
- 词汇表不会无限大(兼顾高频词完整保存,低频词拆分),模型学得动。
5.2、为什么是 ByteLevelBPETokenizer?
- 字节级别 :将文本视为字节序列(如
hello→h,e,l,l,o),支持所有语言(包括无空格的中文、日文等)。 - 无需预分词:直接处理原始文本,适用于多语言混合或特殊符号(如表情符号)。
- RoBERTa 等模型的基础:许多现代预训练模型(如 GPT、RoBERTa)使用字节级 BPE 作为词元化方法。
通俗理解:
简单说,就是更 "万能" 的拼字工具:
- 啥语言都能处理:不管是中文(没空格)、英文(有空格),还是表情符号😂、特殊符号 #,它都能按 "字节"(最基础的字符单位)拆成零件,不用先按空格分词。
- 不用提前教规则:比如中文不用先分词(不像 "结巴分词" 需要预定义词库),直接拿原始文本就能学,适合乱七八糟的混合文本(比如 "我爱吃 apple")。
- 大模型都爱用:GPT、RoBERTa 这些厉害的模型,都靠它来 "拆字",因为灵活又通用。
6、Transformer模型的隐藏层
一个隐藏层(Transformer 编码器块)的组成可以拆解为以下关键部分,按计算顺序排列:
隐藏层的核心组成
| 组成部分 | 作用原理 | 通俗理解 |
|---|---|---|
| 多头自注意力机制 | 将输入文本拆分为多个 "子空间" 并行计算注意力,捕捉不同角度的语义关联(如词语间的依赖、指代、修饰关系)。输出是融合了上下文信息的特征向量。 | 像多人同时阅读文本,每个人关注不同的词语关联(比如 "苹果" 是水果还是公司),最后汇总大家的发现。 |
| 残差连接 + 层归一化 | 1. 残差连接:将注意力机制的输入与输出相加(输入 + 注意力输出) 2. 层归一化:调整数据分布,让训练更稳定。 |
1. 残差连接:保留原始信息,避免深层网络的 "信息丢失" 2. 层归一化:让数据 "标准化",防止计算数值波动过大。 |
| 前馈神经网络(FFN) | 对注意力输出进行非线性变换,包含: 1. 线性层(升维) 2. 激活函数(如 GELU) 3. 线性层(降维) | 对注意力提取的 "关联特征" 进行进一步加工,捕捉更复杂的模式(比如从词语关联中提炼句子情感、逻辑)。 |
| 残差连接 + 层归一化 | 与注意力机制后的结构相同,对前馈网络的输出进行处理(注意力输出 + FFN输出 再归一化)。 |
再次保留中间信息并标准化,确保数据能稳定传递到下一层。 |
7、为什么需要这行代码?
python
tokenizer = RobertaTokenizer.from_pretrained("./KantaiBERT", max_length=512)-
复用预训练配置
如果之前训练了自定义分词器(如通过
ByteLevelBPETokenizer),使用from_pretrained()可以确保模型和分词器的词汇表一致。 -
简化编码流程
分词器封装了复杂的文本处理逻辑(如子词拆分、添加特殊标记),让你可以直接将文本输入模型:
pythoninputs = tokenizer("文本示例", return_tensors="pt") # 返回 PyTorch 张量 outputs = model(**inputs) # 直接输入模型 -
统一输入格式
通过
max_length参数确保所有输入长度一致,避免因序列过长导致的内存溢出或模型错误。
8、为什么用 RobertaForMaskedLM?
简单说,它是让模型 "先学基础语法,再练专项技能" 的工具。
-
"打基础" 专用
就像学英语先背单词、练语法(基础能力),
RobertaForMaskedLM专门用来训练模型的 "语言基本功"------ 通过 "猜掩码词"(比如 "我爱吃<mask>",让模型猜 "苹果"),让模型理解词语搭配、句子结构、上下文逻辑。不管你之后想让模型做什么(翻译、分类、问答),先练这个能让模型 "更懂语言"。
-
"一专多能"
基础打好了,就能灵活应对各种任务:
- 想做 "情感分析"?在基础模型上再练几句 "这电影真棒""太烂了" 就行。
- 想做 "翻译"?再教它中英互译的对应规律就行。
不用每次都从零开始训练,省时间、省资源。
-
"大小按需调"
就像买衣服能选尺码,你可以通过改配置(比如层数、注意力头数),让模型 "变小"(快但能力弱)或 "变大"(慢但能力强)。
比如手机端用小模型,服务器端用大模型,灵活适配不同场景。