代码仓库
代码我已经上传到 Github,大家需要的可以顺手点个 Star!
https://github.com/turbo-duck/biquge_fiction_spider

背景介绍
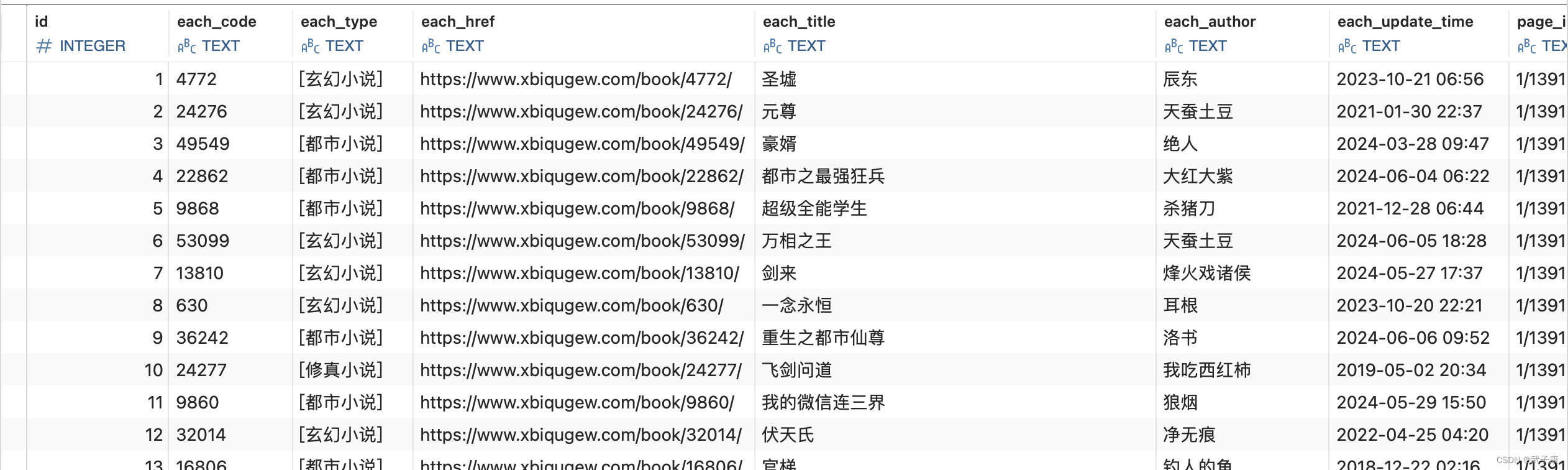
上一节已经拿到了每个小说的编码:fiction_code,并且写入了数据库表。
接下来,我们写一个小工具,将数据表中的数据,都推送到 RabbitMQ 中。
为了保证我们不丢数据,在消费的时候,我们将手动进行 ACK 确认。
目前,现在库工具和RabbitMQ的配合比较差,不知道为什么, 所以就手搓了一部分代码, 来实现 RabbitMQ 和 Scrapy 的结合。
使用技术
- RabbitMQ
- Scrapy
- SQLite
生产者代码
先写一个生产者,从数据库中拿到数据,然后将URL推送到RabbitMQ中。后续将用Scrapy对该队列进行消费。
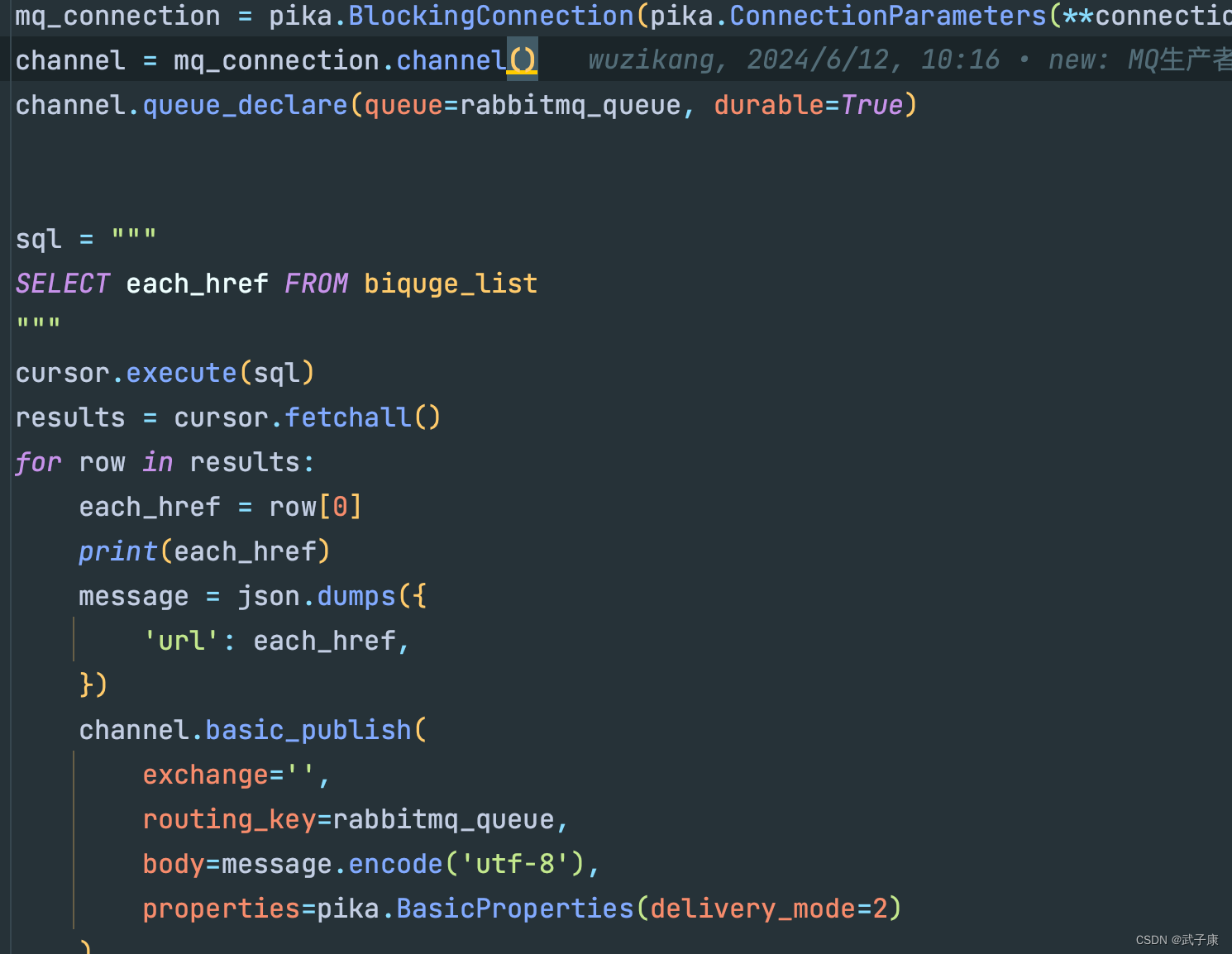
完整代码如下
python
import pika
import json
import sqlite3
import os
from dotenv import load_dotenv
load_dotenv()
sql_connection = sqlite3.connect('../db/biquge.db')
cursor = sql_connection.cursor()
rabbitmq_queue = os.getenv('RABBITMQ_QUEUE', 'default_queue')
rabbitmq_host = os.getenv('RABBITMQ_HOST', 'localhost')
rabbitmq_port = os.getenv('RABBITMQ_PORT', '5672')
virtual_host = os.getenv('RABBITMQ_VHOST', '/')
username = os.getenv('RABBITMQ_USERNAME', 'guest')
password = os.getenv('RABBITMQ_PASSWORD', 'guest')
credentials = pika.PlainCredentials(
username,
password
)
connection_params_result = {
'host': rabbitmq_host,
'port': rabbitmq_port,
'virtual_host': '/',
'credentials': credentials,
}
mq_connection = pika.BlockingConnection(pika.ConnectionParameters(**connection_params_result))
channel = mq_connection.channel()
channel.queue_declare(queue=rabbitmq_queue, durable=True)
sql = """
SELECT each_href FROM biquge_list
"""
cursor.execute(sql)
results = cursor.fetchall()
for row in results:
each_href = row[0]
print(each_href)
message = json.dumps({
'url': each_href,
})
channel.basic_publish(
exchange='',
routing_key=rabbitmq_queue,
body=message.encode('utf-8'),
properties=pika.BasicProperties(delivery_mode=2)
)
print(f"Send MQ: {message}")
mq_connection.close()
sql_connection.close()消费者代码
由于市面上的包不太我符合我的需求,所以这里是手搓的,比较长!
这里有一些主要的逻辑判断:
- 查询数据是否存在,存在则直接ACK确认
- 消费MQ如果失败将会重连
- 由于重连后确认的tag将会失效,所以会有一个version_id的机制来判断 比较提交错误
这个Spider中有两个主要的部分:
- 爬取小说的详细介绍
- 爬取小说的章节列表
这是两个不同的Item
Spider.py

这里做一些介绍:
初始化方法中定义了一些实例变量
python
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.queue_name = None
self.channel = None
self.db_params = None
self.conn = None
self.cursor = None
self.tcp_uuid = 0建立 RabbitMQ 连接
python
def establish_connection(self):
try:
connection_params = self.settings.get('RABBITMQ_PARAMS', None)
self.queue_name = connection_params['queue']
credentials = pika.PlainCredentials(
connection_params['username'],
connection_params['password']
)
connection_params_result = {
'host': connection_params['host'],
'port': connection_params['port'],
'virtual_host': connection_params['virtual_host'],
'credentials': credentials,
'heartbeat': 3600,
'connection_attempts': 5,
}
connection = pika.BlockingConnection(pika.ConnectionParameters(**connection_params_result))
self.channel = connection.channel()
self.channel.basic_qos(prefetch_count=1)
self.tcp_uuid = int(self.tcp_uuid) + 1
except Exception as e:
print(f"连接MQ失败: {str(e)}")
print("等待5秒后重试...")
time.sleep(5)
self.establish_connection()建立数据库的链接
python
def connect_db(self):
try:
self.conn = sqlite3.connect("../db/biquge.db")
self.cursor = self.conn.cursor()
except Exception as e:
print("Error connecting to DB: ", e)
print("等待5秒后重试...")
time.sleep(5)
self.connect_db()处理需要抓取的请求
python
def callback(self, url, delivery_tag, fiction_code):
meta = {
"url": url,
"fiction_code": fiction_code,
"delivery_tag": delivery_tag,
"tcp_uuid": int(self.tcp_uuid),
}
print(url)
return scrapy.Request(
url=url,
meta=meta,
callback=self.parse_list,
)确认消费和拒绝消费
python
def ack(self, delivery_tag):
self.channel.basic_ack(delivery_tag=delivery_tag)
print(f"提交ACK确认: {delivery_tag}")
def no_ack(self, delivery_tag):
self.channel.basic_reject(delivery_tag=delivery_tag, requeue=True)对内容进行解析处理
python
def parse_list(self, response):
meta = response.meta
# ==== 解析 小说基本信息 ====
fiction_code = meta['fiction_code']
fiction_name = response.xpath(".//div[@id='info']/h1/text()").extract_first()
fiction_info = response.xpath(".//p[contains(text(), '更新时间:')]/text()").extract_first()
fiction_introduce = response.xpath(".//div[@id='intro']/text()").extract()
fiction_author = response.xpath(".//p[contains(text(), '作者:')]/a/text()").extract_first()
fiction_type = response.xpath(".//div[@class='con_top']/text()").extract_first()
fiction_type = re.sub(" ", "", str(fiction_type))
fiction_type = re.sub(re.escape(fiction_name), "", str(fiction_type))
fiction_type = re.sub(">", "", str(fiction_type))
fiction_image_url = response.xpath(".//div[@id='fmimg']/img/@src").extract_first()
fiction_count = response.xpath(".//p[contains(text(), '更新时间:')]/text()").extract_first()
fiction_count = re.sub("更新时间:", "", str(fiction_count))
item = BiqugeChapterSpiderFictionItem()
item['fiction_code'] = str(fiction_code)
item['fiction_name'] = str(fiction_name)
item['fiction_info'] = str(fiction_info)
item['fiction_introduce'] = str(fiction_introduce)
item['fiction_author'] = str(fiction_author)
item['fiction_type'] = str(fiction_type)
item['fiction_image_url'] = str(fiction_image_url)
item['fiction_count'] = str(fiction_count)
print(f"获取{item['fiction_name']}信息")
yield item
# ==== 解析 小说章节 ====
chapter_list = response.xpath(".//div[@id='list']/dl/dd/a")
chapter_set = set()
chapter_only_one_list = list()
for each_chapter in chapter_list:
each_href = each_chapter.xpath("./@href").extract_first()
each_code = re.sub(".html", "", str(each_href))
if each_code in chapter_set:
continue
else:
chapter_set.add(each_code)
each_name = each_chapter.xpath("./text()").extract_first()
set_item = {
"each_code": str(each_code),
"each_name": str(each_name),
完整代码如下
python
import scrapy
import re
import pika
import json
import time
import scrapy
from urllib import parse
import logging
import sqlite3
from biquge_chapter_spider.items import BiqugeChapterSpiderFictionItem, BiqugeChapterSpiderChapterItem
logger = logging.getLogger(__name__)
class SpiderSpider(scrapy.Spider):
name = "spider"
# allowed_domains = ["spider.com"]
start_urls = []
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.queue_name = None
self.channel = None
self.db_params = None
self.conn = None
self.cursor = None
self.tcp_uuid = 0
def establish_connection(self):
try:
connection_params = self.settings.get('RABBITMQ_PARAMS', None)
self.queue_name = connection_params['queue']
credentials = pika.PlainCredentials(
connection_params['username'],
connection_params['password']
)
connection_params_result = {
'host': connection_params['host'],
'port': connection_params['port'],
'virtual_host': connection_params['virtual_host'],
'credentials': credentials,
'heartbeat': 3600,
'connection_attempts': 5,
}
connection = pika.BlockingConnection(pika.ConnectionParameters(**connection_params_result))
self.channel = connection.channel()
self.channel.basic_qos(prefetch_count=1)
self.tcp_uuid = int(self.tcp_uuid) + 1
except Exception as e:
print(f"连接MQ失败: {str(e)}")
print("等待5秒后重试...")
time.sleep(5)
self.establish_connection()
def connect_db(self):
try:
self.conn = sqlite3.connect("../db/biquge.db")
self.cursor = self.conn.cursor()
except Exception as e:
print("Error connecting to DB: ", e)
print("等待5秒后重试...")
time.sleep(5)
self.connect_db()
def extract_last_number(self, text):
# 使用正则表达式查找所有的数字
numbers = re.findall(r'.*?/(\d+)/', text)
# print(numbers)
if numbers:
# 返回最后一个数字
return str(numbers[-1])
else:
return ""
def start_requests(self):
self.establish_connection()
self.connect_db()
while True:
try:
method, header, body = self.channel.basic_get(self.queue_name)
except Exception as e:
print("--- ---")
print(e)
print("--- establish_connection ---")
self.establish_connection()
time.sleep(1)
continue
if not method:
continue
delivery_tag = method.delivery_tag
body = body.decode()
body = parse.unquote(body)
json_data = json.loads(body)
print(body)
url = json_data['url']
if url is None or url == "":
self.ack(delivery_tag)
continue
fiction_code = self.extract_last_number(url)
# 检验数据库中是否有数据 有则跳过
sql = "SELECT COUNT(id) AS count FROM fiction_list WHERE fiction_code = ?"
try:
self.cursor.execute(sql, (fiction_code,))
result = self.cursor.fetchone()
count = result[0]
if count > 0:
print(f"SQL SELECT fiction_code: {fiction_code}, COUNT: {count}, ACK: {delivery_tag} 已跳过")
self.ack(delivery_tag)
continue
except Exception as e:
print(e)
print(sql)
print("--- reconnect_db ---")
self.no_ack(delivery_tag)
self.connect_db()
time.sleep(1)
continue
print(f"准备请求: {url}, ACK: {delivery_tag}")
yield self.callback(
url=url,
delivery_tag=delivery_tag,
fiction_code=fiction_code,
)
def callback(self, url, delivery_tag, fiction_code):
meta = {
"url": url,
"fiction_code": fiction_code,
"delivery_tag": delivery_tag,
"tcp_uuid": int(self.tcp_uuid),
}
print(url)
return scrapy.Request(
url=url,
meta=meta,
callback=self.parse_list,
)
def ack(self, delivery_tag):
self.channel.basic_ack(delivery_tag=delivery_tag)
print(f"提交ACK确认: {delivery_tag}")
def no_ack(self, delivery_tag):
self.channel.basic_reject(delivery_tag=delivery_tag, requeue=True)
def parse_list(self, response):
meta = response.meta
# ==== 解析 小说基本信息 ====
fiction_code = meta['fiction_code']
fiction_name = response.xpath(".//div[@id='info']/h1/text()").extract_first()
fiction_info = response.xpath(".//p[contains(text(), '更新时间:')]/text()").extract_first()
fiction_introduce = response.xpath(".//div[@id='intro']/text()").extract()
fiction_author = response.xpath(".//p[contains(text(), '作者:')]/a/text()").extract_first()
# > 都市小说 > 汴京小医娘
fiction_type = response.xpath(".//div[@class='con_top']/text()").extract_first()
fiction_type = re.sub(" ", "", str(fiction_type))
fiction_type = re.sub(re.escape(fiction_name), "", str(fiction_type))
fiction_type = re.sub(">", "", str(fiction_type))
fiction_image_url = response.xpath(".//div[@id='fmimg']/img/@src").extract_first()
fiction_count = response.xpath(".//p[contains(text(), '更新时间:')]/text()").extract_first()
fiction_count = re.sub("更新时间:", "", str(fiction_count))
item = BiqugeChapterSpiderFictionItem()
item['fiction_code'] = str(fiction_code)
item['fiction_name'] = str(fiction_name)
item['fiction_info'] = str(fiction_info)
item['fiction_introduce'] = str(fiction_introduce)
item['fiction_author'] = str(fiction_author)
item['fiction_type'] = str(fiction_type)
item['fiction_image_url'] = str(fiction_image_url)
item['fiction_count'] = str(fiction_count)
print(f"获取{item['fiction_name']}信息")
yield item
# ==== 解析 小说章节 ====
chapter_list = response.xpath(".//div[@id='list']/dl/dd/a")
# 用来去重的 页面上有不少重复内容
chapter_set = set()
chapter_only_one_list = list()
for each_chapter in chapter_list:
# 40726662.html
each_href = each_chapter.xpath("./@href").extract_first()
# 40726662
each_code = re.sub(".html", "", str(each_href))
if each_code in chapter_set:
continue
else:
chapter_set.add(each_code)
each_name = each_chapter.xpath("./text()").extract_first()
set_item = {
"each_code": str(each_code),
"each_name": str(each_name),
}
# print(f"set_item: {set_item}")
chapter_only_one_list.append(set_item)
# 去重后的
for each_chapter in chapter_only_one_list:
chapter_code = each_chapter.get('each_code')
chapter_name = each_chapter.get('each_name')
# 通过code进行排序
chapter_order = int(chapter_code)
item = BiqugeChapterSpiderChapterItem()
item['fiction_code'] = str(fiction_code)
item['chapter_code'] = str(chapter_code)
item['chapter_name'] = str(chapter_name)
item['chapter_order'] = int(chapter_order)
# print(f"获取 {fiction_name} 章节信息: {chapter_name}")
yield item
# ack
delivery_tag = meta['delivery_tag']
tcp_uuid = meta['tcp_uuid']
if int(tcp_uuid) == self.tcp_uuid:
self.ack(delivery_tag)
else:
print(f"ACK 跳过: tcp_uuid: {tcp_uuid}, self.tcp_uuid: {self.tcp_uuid}, delivery_tag: {delivery_tag}")piplines.py

建立对数据库的链接
python
def open_spider(self, spider):
self.connection = sqlite3.connect("../db/biquge.db")
self.cursor = self.connection.cursor()对不同的 Item 进行处理,通过ItemAdapter,判断属于哪个,来走不同的SQL
python
def process_item(self, item, spider):
adapter = ItemAdapter(item)
if isinstance(item, BiqugeChapterSpiderFictionItem):
self.process_fiction_item(adapter, spider)
elif isinstance(item, BiqugeChapterSpiderChapterItem):
self.process_chapter_item(adapter, spider)
return item完整代码如下
python
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import sqlite3
from .items import BiqugeChapterSpiderFictionItem, BiqugeChapterSpiderChapterItem
class BiqugeChapterSpiderPipeline:
def process_item(self, item, spider):
return item
class SQLitePipeline:
def __init__(self):
self.cursor = None
self.connection = None
def open_spider(self, spider):
# 连接到 SQLite 数据库
self.connection = sqlite3.connect("../db/biquge.db")
self.cursor = self.connection.cursor()
def close_spider(self, spider):
# 关闭数据库连接
self.connection.close()
def process_item(self, item, spider):
adapter = ItemAdapter(item)
if isinstance(item, BiqugeChapterSpiderFictionItem):
self.process_fiction_item(adapter, spider)
elif isinstance(item, BiqugeChapterSpiderChapterItem):
self.process_chapter_item(adapter, spider)
return item
def process_fiction_item(self, adapter, spider):
self.cursor.execute('''
INSERT INTO
fiction_list(
fiction_code, fiction_name, fiction_info,
fiction_introduce, fiction_author, fiction_type,
fiction_image_url, fiction_count,
create_time, update_time)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, CURRENT_TIMESTAMP, CURRENT_TIMESTAMP)
''', (
adapter.get('fiction_code'),
adapter.get('fiction_name'),
adapter.get('fiction_info'),
adapter.get('fiction_introduce'),
adapter.get('fiction_author'),
adapter.get('fiction_type'),
adapter.get('fiction_image_url'),
adapter.get('fiction_count')
))
self.connection.commit()
print(f"数据库入库: fiction_list {adapter.get('fiction_name')}")
return adapter
def process_chapter_item(self, adapter, spider):
self.cursor.execute('''
INSERT INTO
chapter_list(
fiction_code, chapter_code, chapter_name,
chapter_order, create_time, update_time)
VALUES(?, ?, ?, ?, CURRENT_TIMESTAMP, CURRENT_TIMESTAMP)
''', (
adapter.get('fiction_code'),
adapter.get('chapter_code'),
adapter.get('chapter_name'),
adapter.get('chapter_order')
))
self.connection.commit()
# print(f"数据库入库: chapter_list {adapter.get('chapter_name')}")
return adaptersettings.py
RabbitMQ 的连接配置在这里
python
# Scrapy settings for biquge_chapter_spider project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
import os
from dotenv import load_dotenv
load_dotenv()
BOT_NAME = "biquge_chapter_spider"
SPIDER_MODULES = ["biquge_chapter_spider.spiders"]
NEWSPIDER_MODULE = "biquge_chapter_spider.spiders"
LOG_LEVEL = "ERROR"
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = "biquge_chapter_spider (+http://www.yourdomain.com)"
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 0.2
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# "biquge_chapter_spider.middlewares.BiqugeChapterSpiderSpiderMiddleware": 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# "biquge_chapter_spider.middlewares.BiqugeChapterSpiderDownloaderMiddleware": 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# "scrapy.extensions.telnet.TelnetConsole": None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
"biquge_chapter_spider.pipelines.SQLitePipeline": 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = "httpcache"
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = "scrapy.extensions.httpcache.FilesystemCacheStorage"
# Set settings whose default value is deprecated to a future-proof value
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
# RabbitMQ settings
RABBITMQ_PARAMS = {
'queue': os.getenv('RABBITMQ_QUEUE', 'default_queue'),
'host': os.getenv('RABBITMQ_HOST', 'localhost'),
'port': os.getenv('RABBITMQ_PORT', '5672'),
'virtual_host': os.getenv('RABBITMQ_VHOST', '/'),
'username': os.getenv('RABBITMQ_USERNAME', 'guest'),
'password': os.getenv('RABBITMQ_PASSWORD', 'guest'),
'auto_ack': os.getenv('RABBITMQ_AUTO_ACK', False)
}运行代码
运行生产者
shell
python producer.py运行消费者
shell
scrapy crawl spider