节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学。
针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
合集:
《大模型面试宝典》(2024版) 正式发布!
《AIGC 面试宝典》已圈粉无数!
Meta 推出了一个基于深度学习的AI音频处理库 AudioCraft,其中包含了音乐生成模型MusicGen。相对于不久前Google也推出了MusicML,Meta 这个音频库真的是强得离谱!
Audiocraft 采用了最先进的EnCodec音频压缩器/标记器技术,用于音频数据的处理和压缩。同时引入了MusicGen,这是一个简单可控的音乐生成大模型。MusicGen使用了Transformer架构,能够从文本输入中生成新的音乐作品。
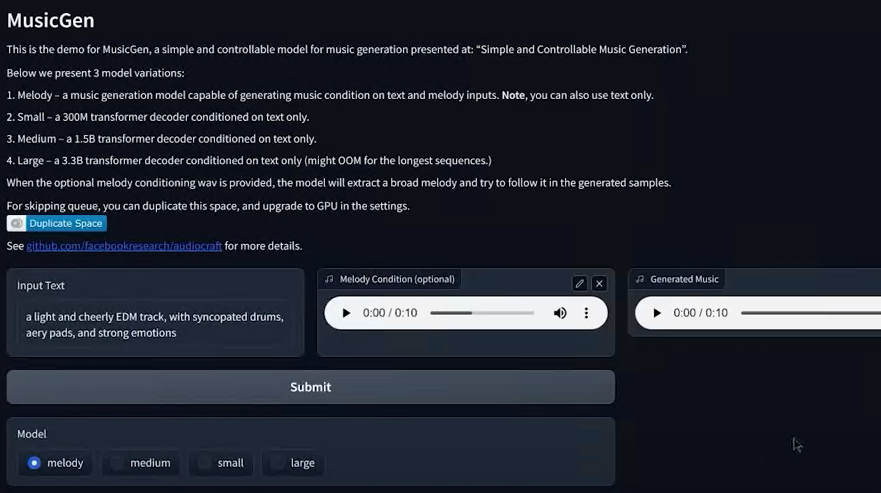
项目地址
github.com/facebookresearch/audiocraft
在线体验
huggingface.co/spaces/facebook/MusicGen
MusicGen 提供了4种音乐生成方式:
-
无条件生成
-
旋律+文本:输入音频文件的旋律,配以prompt,生成新的音乐,能够将现有的旋律转化成新的歌曲
-
节奏+文本:可以用程序生成一段周期音,配以prompt,生成节奏相同的全新音乐
-
文本生成音乐:提供一段prompt指定不同的风格,转化为全新的音乐作品
这次开源了四个级别的模型,其中中等模型(medium, melody)可以在16GB显存的显卡里运行:
-
small: 300M model, text to music only (huggingface.co/facebook/musicgen-small)
-
medium: 1.5B model, text to music only (huggingface.co/facebook/musicgen-medium)
-
melody: 1.5B model, text to music and text+melody to music (huggingface.co/facebook/musicgen-melody)
-
large: 3.3B model, text to music only (huggingface.co/facebook/musicgen-large)
目前用户还不能自己训练模型,但官方已预告,很快会开源训练代码。
接下来安装体验。
安装环境
AudioCraft安装起来非常简单: 这里选用了 Python 3.9 + torch 2.0.0 + torchaudio 2.0.0
bash
conda create -n audiocraft python=3.9
activate audiocraft
pip install d:\pylib\torch-2.0.0+cu117-cp39-cp39-win_amd64.whl
pip install d:\pylib\torchaudio-2.0.0+cu117-cp39-cp39-win_amd64.whl
pip install ffmpeg
cd d:\aiworkflow
git clone https://github.com/facebookresearch/audiocraft.git
cd audiocraft
pip install -e .下载模型
添加windows环境变量,如果不添加,则模型默认会下载到位于C盘的用户的.cache目录下,:
bash
MUSICGEN_ROOT = D:\AIWorkFlow\audiocraft\models编辑并运行以下代码
python
import torchaudio
from audiocraft.models import MusicGen
# 选择模型,四选一 small/medium/melody/large
# 如果没有则会从 huggingface 自动下载
# 请先设置系统环境变量 MUSICGEN_ROOT
model = MusicGen.get_pretrained('melody')当上述模型为melody时,需下载的模型文件为:
-
compression_state_dict.bin 225MB
-
state_dict.bin 2.58GB
-
955717e8-8726e21a.th 80MB
-
pytorch_model.bin 850MB
无条件生成
python
import torchaudio
from audiocraft.models import MusicGen
from audiocraft.data.audio import audio_write
# 选择模型,四选一 small/medium/melody/large
# 如果没有则会从 huggingface 自动下载
# 请先设置系统环境变量 MUSICGEN_ROOT
model = MusicGen.get_pretrained('melody')
# 音乐时长设为12秒
model.set_generation_params(duration=12)
wav = model.generate_unconditional(num_samples=3, progress=True)
for idx, one_wav in enumerate(wav):
# Will save under {idx}.wav, with loudness normalization at -14 db LUFS.
audio_write(f'uncond_{idx}', one_wav.cpu(), model.sample_rate, strategy="loudness", loudness_compressor=True)音乐续写
python
import math
import torch
import torchaudio
from audiocraft.models import MusicGen
from audiocraft.data.audio import audio_write
from audiocraft.utils.notebook import display_audio
# 选择模型,四选一 small/medium/melody/large
# 如果没有则会从 huggingface 自动下载
# 请先设置系统环境变量 MUSICGEN_ROOT
model = MusicGen.get_pretrained('melody')
# 产生一段间歇的bip bip旋律
def get_bip_bip(bip_duration=0.125, frequency=440,
duration=0.5, sample_rate=32000, device="cuda"):
"""Generates a series of bip bip at the given frequency."""
t = torch.arange(
int(duration * sample_rate), device="cuda", dtype=torch.float) / sample_rate
wav = torch.cos(2 * math.pi * 440 * t)[None]
tp = (t % (2 * bip_duration)) / (2 * bip_duration)
envelope = (tp >= 0.5).float()
return wav * envelope
# 音乐时长设为12秒
model.set_generation_params(duration=12)
# 根据bipbip声的旋律,及两段prompt,生成新的音乐
wav = model.generate_continuation(
get_bip_bip(0.125).expand(2, -1, -1),
32000, ['Jazz jazz and only jazz',
'Heartful EDM with beautiful synths and chords'],
progress=True)
for idx, one_wav in enumerate(wav):
# Will save under {idx}.wav, with loudness normalization at -14 db LUFS.
audio_write(f'test3_{idx}', one_wav.cpu(), model.sample_rate, strategy="loudness", loudness_compressor=True)音乐+文本
python
import torchaudio
from audiocraft.models import MusicGen
from audiocraft.data.audio import audio_write
# 选择模型,四选一 small/medium/melody/large
# 如果没有则会从 huggingface 自动下载
# 请先设置系统环境变量 MUSICGEN_ROOT
model = MusicGen.get_pretrained('melody')
# 音乐时长设为12秒
model.set_generation_params(duration=12)
# 三段prompt
descriptions = [
"a piano playing a sad chambers music, canon style",
"a light and cheerly EDM track, with syncopated drums, aery pads, and strong emotions",
"A grand orchestral arrangement with thunderous percussion, epic brass fanfares, and soaring strings, creating a cinematic atmosphere fit for a heroic battle.",
]
# 参考旋律
melody, sr = torchaudio.load('./assets/bach.mp3')
wav = model.generate_with_chroma(descriptions, melody[None].expand(3, -1, -1), sr)
for idx, one_wav in enumerate(wav):
# Will save under {idx}.wav, with loudness normalization at -14 db LUFS.
audio_write(f'Melody_{idx}', one_wav.cpu(), model.sample_rate, strategy="loudness", loudness_compressor=True)文本生成音乐
python
import torchaudio
from audiocraft.models import MusicGen
from audiocraft.data.audio import audio_write
# 选择模型,四选一 small/medium/melody/large
# 如果没有则会从 huggingface 自动下载
# 请先设置系统环境变量 MUSICGEN_ROOT
model = MusicGen.get_pretrained('melody')
# 音乐时长设为12秒
model.set_generation_params(duration=12)
# 根据三段prompt生成音乐
descriptions = [
"a piano playing a sad chambers music, canon style",
"a light and cheerly EDM track, with syncopated drums, aery pads, and strong emotions",
"A grand orchestral arrangement with thunderous percussion, epic brass fanfares, and soaring strings, creating a cinematic atmosphere fit for a heroic battle.",
]
wav = model.generate(
descriptions,
progress=True
)
for idx, one_wav in enumerate(wav):
# Will save under {idx}.wav, with loudness normalization at -14 db LUFS.
audio_write(f'text_{idx}', one_wav.cpu(), model.sample_rate, strategy="loudness", loudness_compressor=True)通过上面的体验,可以感受到音乐的生成质量非常高。其中利用旋律+Prompt的方式非常实用,完全可以从现有歌曲中分离音乐,然后喂给 AudioCraft,再配以文本,生成新的音乐。
深度学习研究,这完全可以成为一个高生产力的AI工具。