在之前的文章 "使用 Llama 3 开源和 Elastic 构建 RAG",我们讲到了如何使用 Liama3 来结合 Elastic ELSER 来进行 RAG。在今天的文章里,我们来详细使用一个 notebook 来展示如何在本地 Elasticsearch 部署中进行实现。
此交互式 notebook 使用 Langchain 处理虚构的工作场所文档,并使用在 Elasticsearch 中运行的 ELSER v2 将这些文档转换为嵌入并将它们存储到 Elasticsearch 中。然后我们提出一个问题,从 Elasticsearch 中检索相关文档,并使用在本地运行的 Llama3 使用 Ollama 提供响应。
注意:预计 Llama3 将在你运行此笔记本的同一台机器上使用 Ollama 运行。

安装
Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考如下的链接来进行安装:
- 如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
- Kibana:如何在 Linux,MacOS 及 Windows上安装 Elastic 栈中的 Kibana
在安装的时候,我们选择 Elastic Stack 8.x 来进行安装。特别值得指出的是:ES|QL 只在 Elastic Stack 8.11 及以后得版本中才有。你需要下载 Elastic Stack 8.11 及以后得版本来进行安装。
在首次启动 Elasticsearch 的时候,我们可以看到如下的输出:
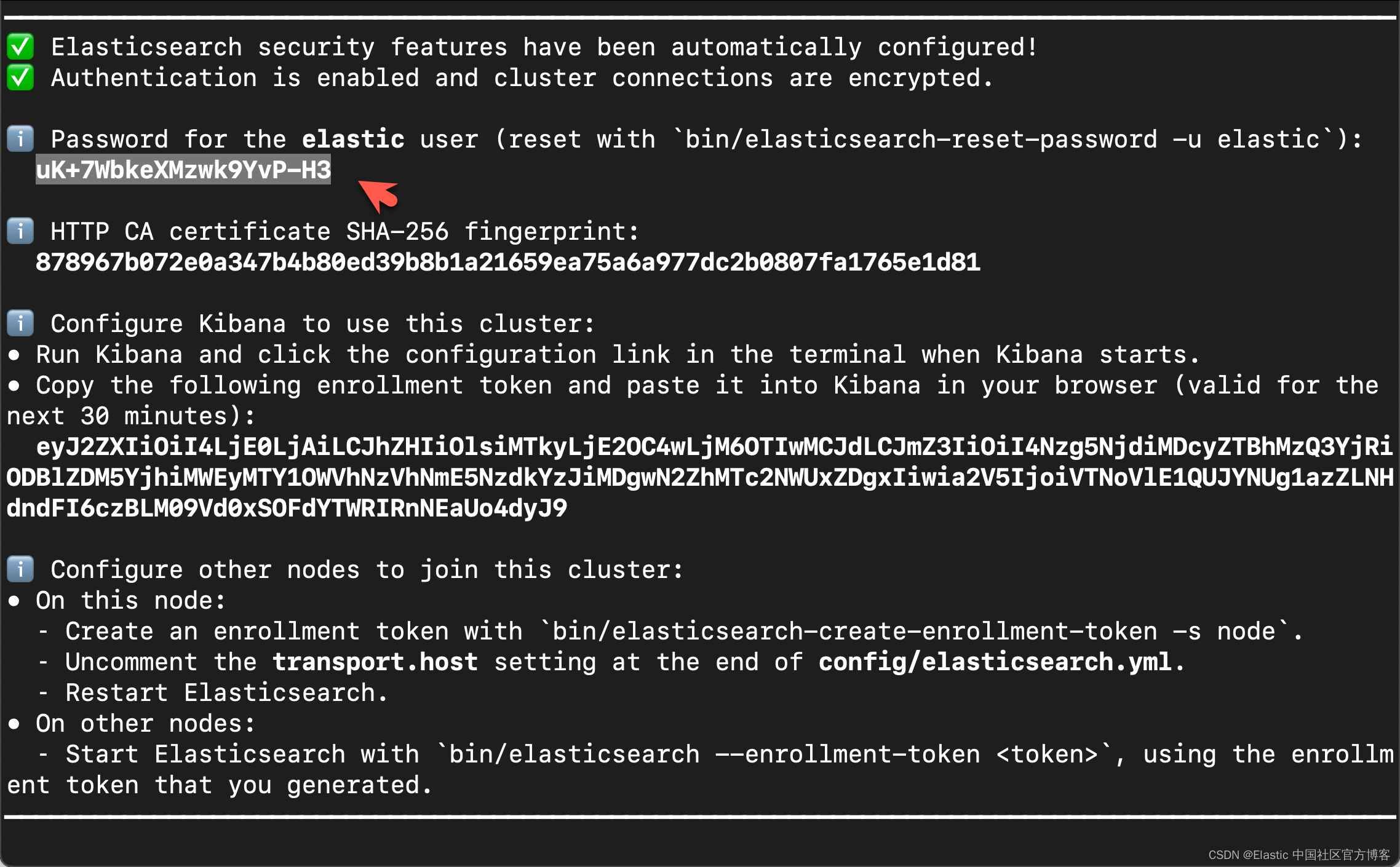
在上面,我们可以看到 elastic 超级用户的密码。我们记下它,并将在下面的代码中进行使用。
我们还可以在安装 Elasticsearch 目录中找到 Elasticsearch 的访问证书:
$ pwd
/Users/liuxg/elastic/elasticsearch-8.14.1/config/certs
$ ls
http.p12 http_ca.crt transport.p12在上面,http_ca.crt 是我们需要用来访问 Elasticsearch 的证书。
我们首先克隆已经写好的代码:
git clone https://github.com/liu-xiao-guo/elasticsearch-labs我们然后进入到该项目的根目录下:
$ pwd
/Users/liuxg/python/elasticsearch-labs/notebooks/integrations/llama3
$ ls
README.md rag-elastic-llama3-elser.ipynb rag-elastic-llama3.ipynb如上所示,rag-elastic-llama3-elser.ipynb 就是我们今天想要工作的 notebook。
我们通过如下的命令来拷贝所需要的证书:
$ pwd
/Users/liuxg/python/elasticsearch-labs/notebooks/integrations/llama3
$ cp ~/elastic/elasticsearch-8.14.1/config/certs/http_ca.crt .
$ ls
README.md rag-elastic-llama3-elser.ipynb
http_ca.crt rag-elastic-llama3.ipynb安装所需要的 python 依赖包
pip3 install langchain langchain-elasticsearch langchain-community tiktoken python-dotenv我们可以通过如下的命令来查看 elasticsearch 安装包的版本:
$ pip3 list | grep elasticsearch
elasticsearch 8.14.0
langchain-elasticsearch 0.2.2
llama-index-embeddings-elasticsearch 0.1.2
llama-index-readers-elasticsearch 0.1.4
llama-index-vector-stores-elasticsearch 0.2.0创建环境变量
为了能够使得下面的应用顺利执行,在项目当前的目录下运行如下的命令:
export ES_ENDPOINT="localhost"
export ES_USER="elastic"
export ES_PASSWORD="uK+7WbkeXMzwk9YvP-H3"配置 Ollama 和 Llama3
由于我们使用 Llama 3 8B 参数大小模型,我们将使用 Ollama 运行该模型。按照以下步骤安装 Ollama。
- 浏览到 URL https://ollama.com/download 以根据你的平台下载 Ollama 安装程序。
在我的电脑上,我使用 macOS 来进行安装。你也可以仿照文章 "Elasticsearch:使用在本地计算机上运行的 LLM 以及 Ollama 和 Langchain 构建 RAG 应用程序" 在 docker 里进行安装。
- 按照说明为你的操作系统安装和运行 Ollama。
- 安装后,按照以下命令下载 Llama3 模型。
点击上面的 "Finish" 按钮,并按照上面的提示在 terminal 中运行:
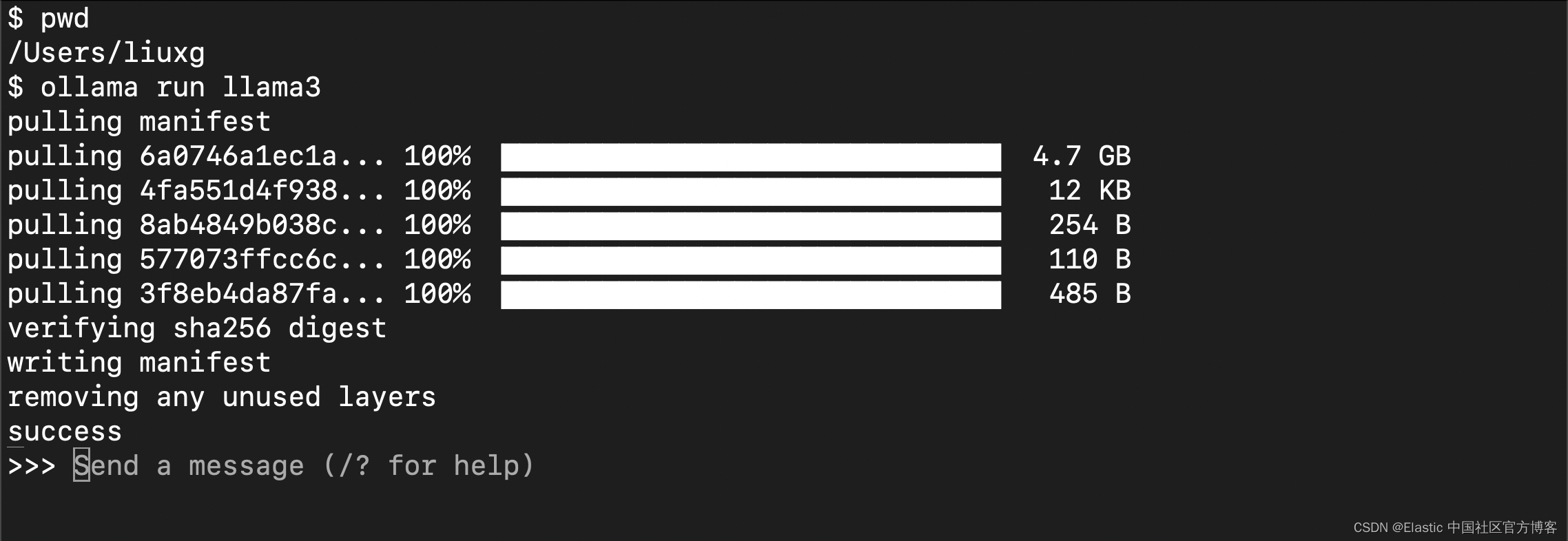
这可能需要一些时间,具体取决于你的网络带宽。运行完成后,你将看到如上的界面。
要测试 Llama3,请从新终端运行以下命令或在提示符下输入文本。
curl -X POST http://localhost:11434/api/generate -d '{ "model": "llama3", "prompt":"Why is the sky blue?" }'
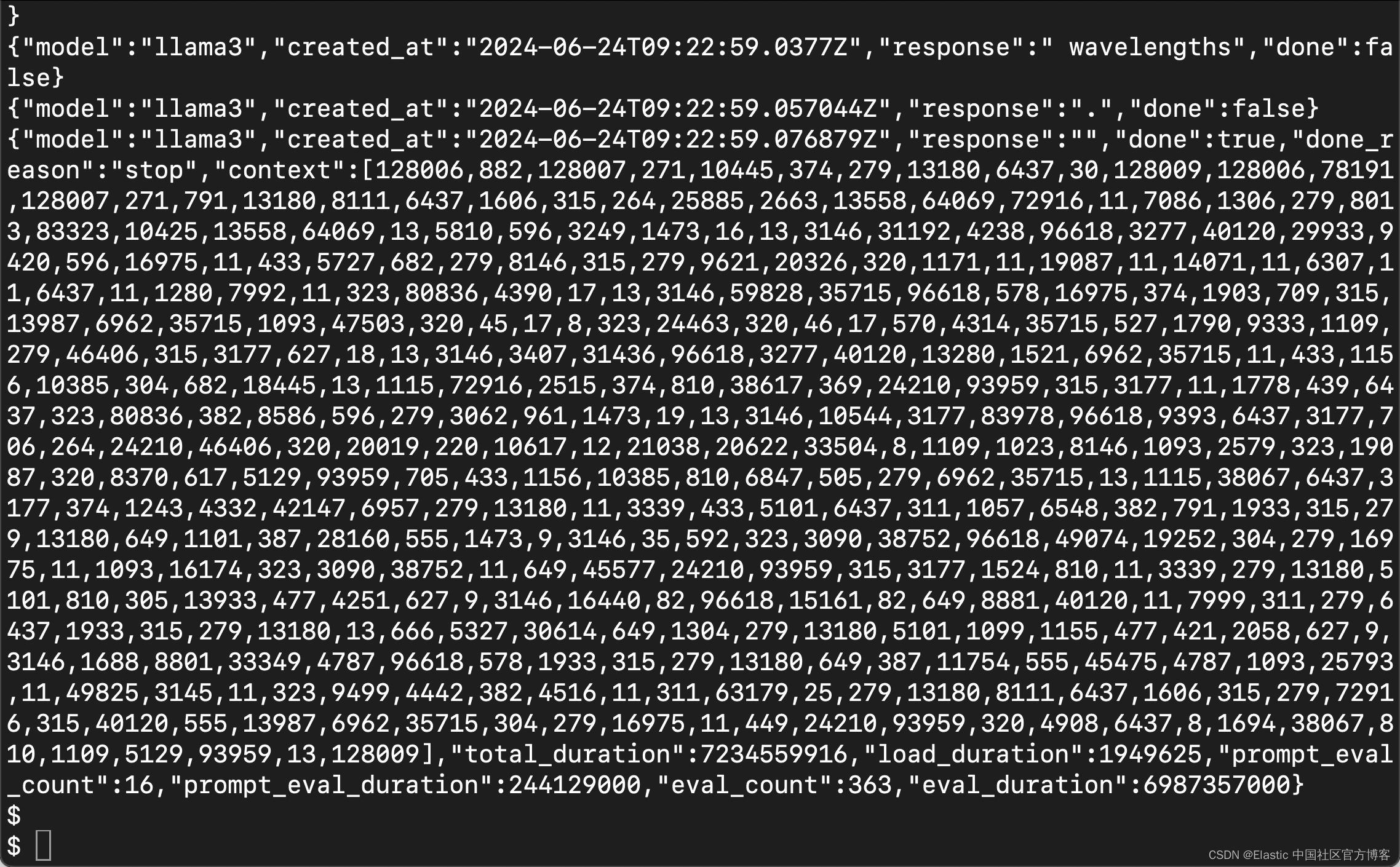
在提示符下,输出如下所示。
我们现在使用 Ollama 在本地运行 Llama3。
安装所需要的 python 依赖包
pip3 install langchain langchain-elasticsearch langchain-community tiktoken python-dotenv我们可以通过如下的命令来查看 elasticsearch 安装包的版本:
$ pip3 list | grep elasticsearch
elasticsearch 8.14.0
llama-index-embeddings-elasticsearch 0.1.2
llama-index-readers-elasticsearch 0.1.4
llama-index-vector-stores-elasticsearch 0.2.0下载数据集文档
我们可以使用如下的命令来下载文档:
wget https://raw.githubusercontent.com/elastic/elasticsearch-labs/main/datasets/workplace-documents.json
$ pwd
/Users/liuxg/python/elasticsearch-labs/notebooks/integrations/llama3
$ ls
README.md rag-elastic-llama3-elser.ipynb
http_ca.crt rag-elastic-llama3.ipynb
$ wget https://raw.githubusercontent.com/elastic/elasticsearch-labs/main/datasets/workplace-documents.json
--2024-06-25 10:54:01-- https://raw.githubusercontent.com/elastic/elasticsearch-labs/main/datasets/workplace-documents.json
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.110.133
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.110.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 52136 (51K) [text/plain]
Saving to: 'workplace-documents.json'
workplace-documents.jso 100%[=============================>] 50.91K 260KB/s in 0.2s
2024-06-25 10:54:02 (260 KB/s) - 'workplace-documents.json' saved [52136/52136]
$ ls
README.md rag-elastic-llama3-elser.ipynb workplace-documents.json
http_ca.crt rag-elastic-llama3.ipynb安装 ELSER
如果你还没有安装过 ELSER,那么请阅读文章 "Elasticsearch:部署 ELSER - Elastic Learned Sparse EncoderR"。
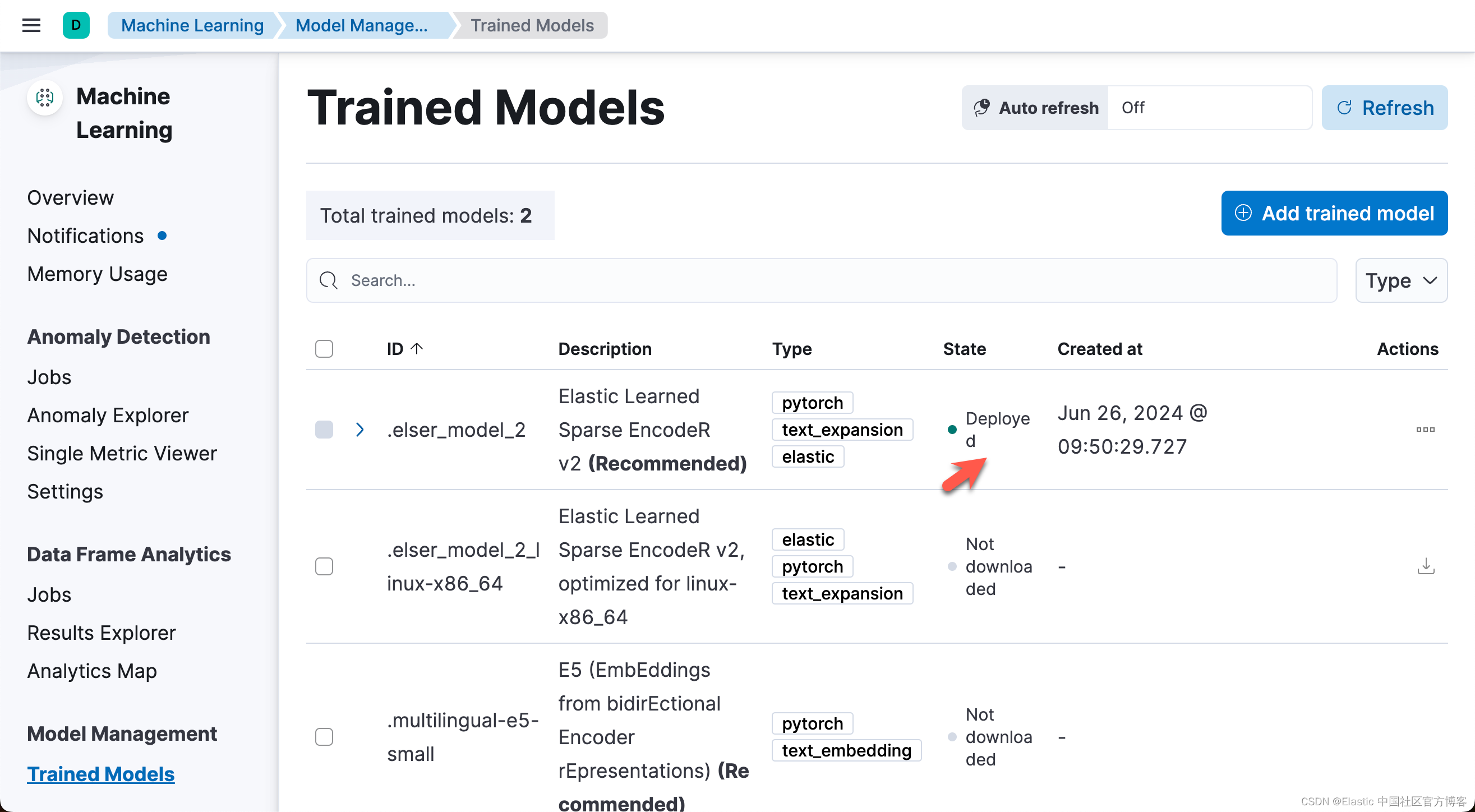
展示
我们在项目当前的目录下打入如下的命令:
jupyter notebook rag-elastic-llama3-elser.ipynb读入变量并连接到 Elasticsearch
from elasticsearch import Elasticsearch, AsyncElasticsearch, helpers
from dotenv import load_dotenv
import os
load_dotenv()
ES_USER = os.getenv("ES_USER")
ES_PASSWORD = os.getenv("ES_PASSWORD")
ES_ENDPOINT = os.getenv("ES_ENDPOINT")
COHERE_API_KEY = os.getenv("COHERE_API_KEY")
url = f"https://{ES_USER}:{ES_PASSWORD}@{ES_ENDPOINT}:9200"
print(url)
client = Elasticsearch(url, ca_certs = "./http_ca.crt", verify_certs = True)
# info = await client.info()
print(client.info())
准备要分块和提取的文档
现在我们准备要提取到 Elasticsearch 中的数据。我们使用 LangChain 的 RecursiveCharacterTextSplitter,将文档的文本拆分为 512 个字符,重叠部分为 256 个字符。
# from urllib.request import urlopen
import json
from langchain.text_splitter import RecursiveCharacterTextSplitter
# url = "https://raw.githubusercontent.com/elastic/elasticsearch-labs/main/datasets/workplace-documents.json"
# response = urlopen(url)
# workplace_docs = json.loads(response.read())
# Load data into a JSON object
with open('workplace-documents.json') as f:
workplace_docs = json.load(f)
metadata = []
content = []
for doc in workplace_docs:
content.append(doc["content"])
metadata.append(
{
"name": doc["name"],
"summary": doc["summary"],
"rolePermissions": doc["rolePermissions"],
}
)
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=512, chunk_overlap=256
)
docs = text_splitter.create_documents(content, metadatas=metadata)定义 Elasticsearch 向量存储
我们将 ElasticsearchStore 定义为具有 SparseVectorStrategy 的向量存储。SparseVectorStrategy 将每个文档转换为标记,并将其存储在数据类型为 rank_features 的向量字段中。我们将使用来自 ELSER v2 模型的文本嵌入 .elser_model_2_linux
注意:在开始索引之前,请确保您已在部署中下载并部署了 ELSER v2 模型,并且该模型正在 ml 节点中运行。
from langchain_elasticsearch import ElasticsearchStore
from langchain_elasticsearch import SparseVectorStrategy
index_name = "workplace_index_elser"
# Delete the index if it exists
if client.indices.exists(index=index_name):
client.indices.delete(index=index_name)
es_vector_store = ElasticsearchStore(
es_user = ES_USER,
es_password = ES_PASSWORD,
es_url = url,
es_connection = client,
index_name=index_name,
strategy=SparseVectorStrategy(model_id=".elser_model_2"),
)添加上面处理的文档。
文档已被分块。我们在这里不使用任何特定的嵌入函数,因为标记是在索引时和在 Elasticsearch 内查询时推断出来的。这要求在 Elasticsearch 中加载并运行 ELSER v2 模型。
es_vector_store.add_documents(documents=docs)
LLM 配置
这将连接到你的本地 LLM。请参阅 https://ollama.com/library/llama3 了解在本地运行 Llama3 的步骤详情。
如果你有足够的资源(至少 >64 GB 的 RAM 和 GPU 可用),那么你可以尝试 70B 参数版本的 Llama3
from langchain_community.llms import Ollama
llm = Ollama(model="llama3")使用 Elasticsearch ELSER v2 和 Llama3 进行语义搜索
我们将使用 ELSER v2 作为模型对查询进行语义搜索。然后将上下文相关的答案与用户原始查询一起组合成模板。
然后我们使用 Llama3 回答你的问题,并使用检索器从 Elasticsearch 中获取的上下文相关数据。
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
retriever = es_vector_store.as_retriever()
template = """Answer the question based only on the following context:\n
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
a = chain.invoke("What are the organizations sales goals?")
print(a)
最终的所有代码可以在地址进行下载:elasticsearch-labs/notebooks/integrations/llama3/rag-elastic-llama3-elser.ipynb at main · liu-xiao-guo/elasticsearch-labs · GitHub