本实践大作业要求
本次实践大作业主要要求主要包括:
1、选择一个热点或者你感兴趣的主题作为本次爬虫实践作业要完成的任务。
2、为了完成本次任务,需要确定从网上爬取的数据对象与范围。
3、利用python及网络爬虫相关技术实现从网上爬取相应内容数据。
4、完成一篇总结报告,主要包括上述任务说明,任务实现过程、遇到的问题及解决办法、任务完成得出的结论。
5、正文不少于2000字(注意:根据实际表述需要,文章中可以出现的python程序关键代码段,但不计入正文文字);
6、文字表述通顺规范,图文并茂,整体成一篇文章;
7、如果能更进一步,可以对爬取的数据内容做相应的数据处理并进行分析和展示,则能获得更高成绩。
注意:1、报告格式排版要整洁,内容要完整;2、正式报告中,这些要求可以删除
一,引言
(介绍要爬取数据的研究背景,爬取意义,数据爬取的来源,数据的构成,本文将从哪些方面开展数据爬取)
爬取网易云音乐评论并制作热词云图是一项生趣且富有洞察力的研究。通过分析用户评论,不仅可以理解大众对特定歌曲的情感倾向,还可以发现最受欢迎的话题和观点。此类分析可以为音乐推荐、市场营销策略、乃至音乐产业的趋势预测提供有价值的见解。
*本篇正文涉及到代码的部分将统一采用截图的形式,以避免代码和注释影响到正文字数以及增强可读性
(一)研究背景
随着数字媒体的兴起,网易云音乐成为中国最受欢迎的音乐平台之一。它不仅提供了广泛的音乐库,还允许用户发表评论,分享他们对歌曲的看法和情感。这些评论成为了理解公众偏好、情感及流行文化趋势的宝贵资源。音乐平台连接起人与人之间的情感共鸣,成为网友抒发情绪的公共空间,也是反映公众情绪的一面镜子。一个"云村"评论区,其实跟当下的社会一样多元,既有失落也有快乐,情绪容易传染引发共鸣,而音乐是最能引发情绪共鸣的语言。
(二)爬取意义
通过爬取和分析这些评论,研究人员和市场分析师可以:
- 理解情感倾向:分析评论的情感倾向,区分正面与负面评价。
- 发现热词和趋势:识别评论中常出现的关键词,理解当前的热门话题,掌握流量趋势。
- 提升用户体验:为用户推荐他们可能喜欢的音乐,提升平台的个性化体验。
- 驱动决策制定:为音乐制作人和市场营销人员提供数据支持,帮助他们制定更加符合用户需求的策略。
(三)数据爬取的来源
数据将从网易云音乐的官方网站爬取,主要聚焦于歌曲页面下的用户评论区。这些评论主要包含:用户对歌曲的直接反馈、对特定演唱者或音乐风格的讨论、各种玩梗抖机灵神反转的有趣评论、讲人生感悟正能量好消息的评论以及关于爱情得失的评论等多种类型的信息。
(四)数据的构成
本次爬取的数据主要包括意以下几类:用户昵称、评论内容、评论时间、点赞数
这些数据将被作为分析的基础,用于生成热词云图。
(五)数据爬取的开展
数据爬取将从以下几个方面开展------
****使用Requests模块访问网页:****利用Python的Requests库发送http请求,通过特定的url访问网易云音乐官方网站的api接口地址,获取歌曲评论页面的html内容。
****解析网页内容:****使用如json、xlwt库等工具解析html,提取出评论相关的数据。
****数据清洗和预处理:****对爬取到的数据进行清洗,包括去除无关字符、标准化日期格式(使用time库)等,以便于分析。
****构建热词云图:****借助WordCloud库,根据评论内容生成反映用户评论热点的词云图。
****分析和解释:****根据生成的热词云图和其他分析结果,提供对目前音乐市场和用户偏好的见解。
通过以上步骤,探索网易云音乐评论中蕴含的用户偏好及市场趋势,为音乐产业提供宝贵的数据支持和洞察。
二,数据爬取方法介绍
(结合使用的所要爬取数据的特征,数据源有可能采用的反爬限制介绍本文使用到的数技术方法和相关工具,注意引用参考文献)
下面我将解释爬取URL的各个组成部分:
https://music.163.com: 这是网易云音乐的基础域名,所有访问网易云音乐服务的请求都以此为起点。
/api/v1/resource/comments: 这个路径指向网易云音乐的API中的一个特定端点,用于获取资源(在这个情况下是歌曲)的评论。api表示这是一个API接口;v1表示API的版本号,通常用于版本控制;resource/comments指的是针对于歌曲评论的具体服务。
/R_SO_4_musicId: 这一部分是对特定资源的标识。R_SO_4是一个前缀,其后面的数字musicId是一串数字id,是一首歌曲的唯一标识,这个id可以在官方歌曲页面的url中轻松找到。
综上,通过访问https://music.163.com/api/v1/resource/comments/R_SO_4_musicId,即可获取到指定歌曲的所有评论。
以歌曲《悬溺》为例,在网易云官网的歌曲页面的url中,获取到歌曲id。
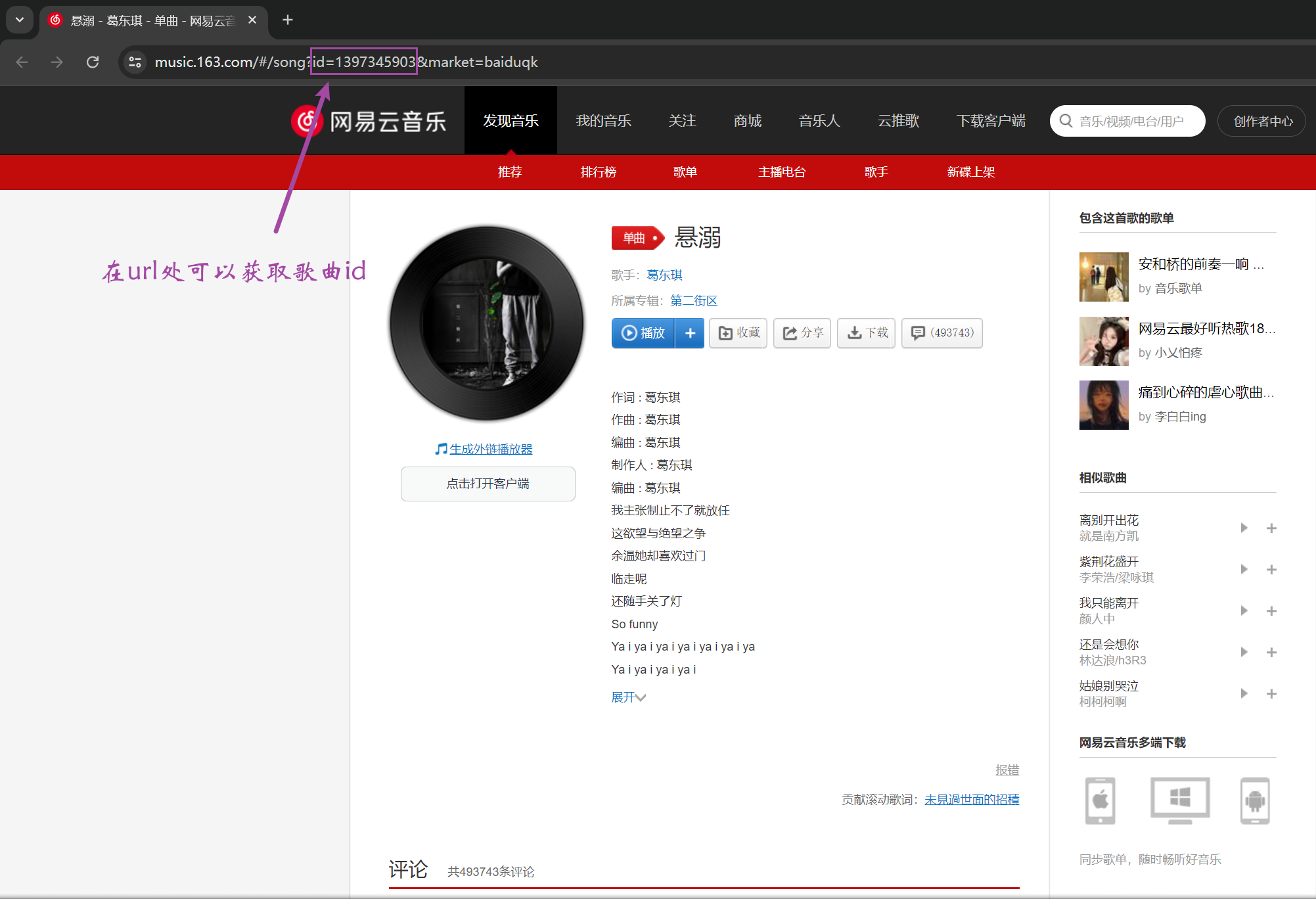 图 1从url中获取歌曲id
图 1从url中获取歌曲id
得到id,去访问https://music.163.com/api/v1/resource/comments/R_SO_4_1397345903,可以得到以下内容(下图左),拿访问到的内容和歌曲页面下面的评论(下图右),对比后不难发现,该页面确实是评论页面的数据集合------nickname标签对应着用户昵称,content标签对应着用户评论,time标签对应着评论发布时间的时间戳(精确到毫秒级的十三位),likedCount标签对应着评论被点赞的次数。
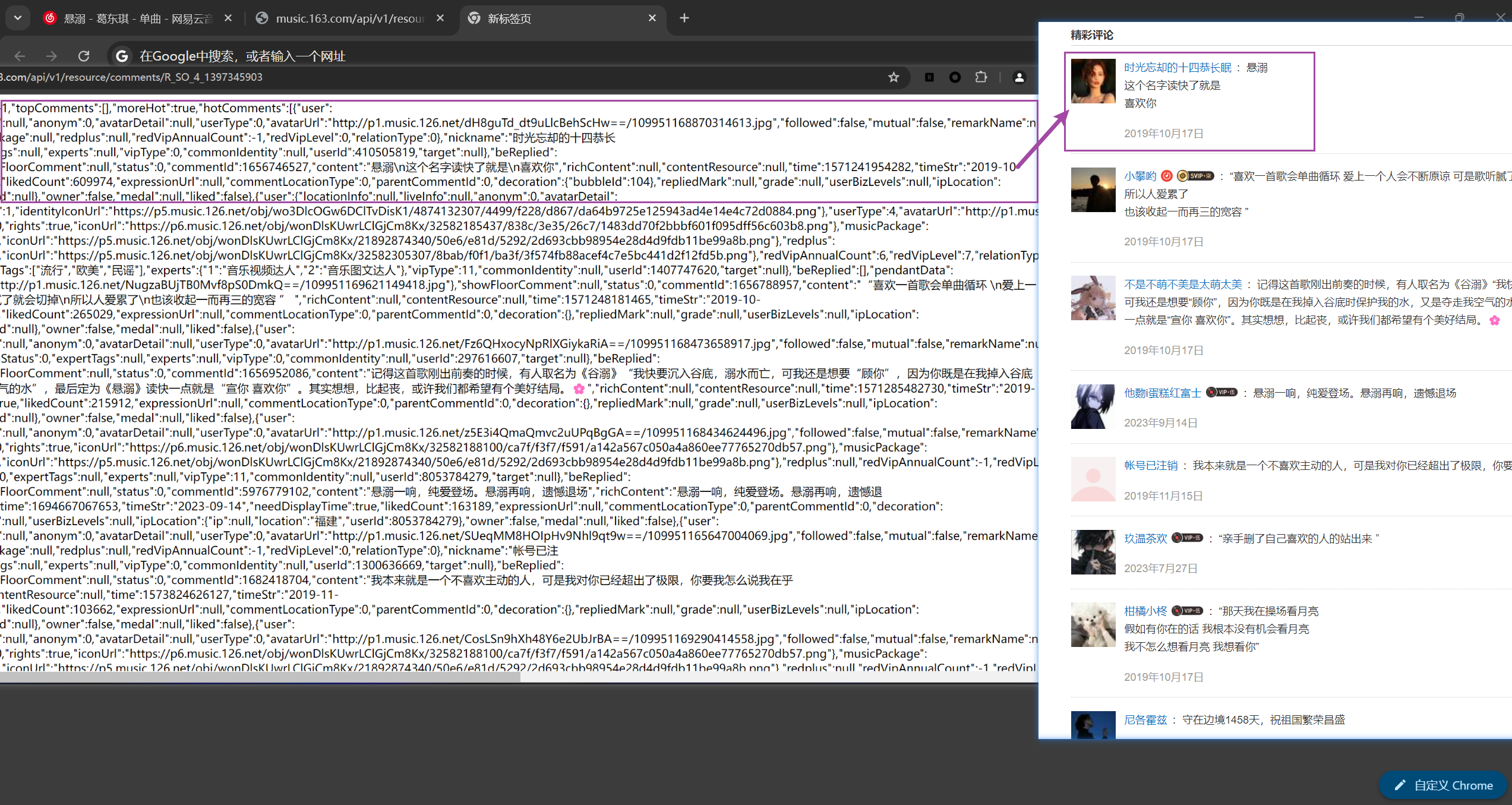 图 2url访问内容(左)和歌曲页面下面评论(右)
图 2url访问内容(左)和歌曲页面下面评论(右)
因此,我们可以通过requests模块发送http请求,将返回的Json格式的文本处理成Python易处理的数据容器格式(例如字典),具体代码如下图所示,后续再通过Python的其它工具进行进一步处理,即可提取出关键数据。
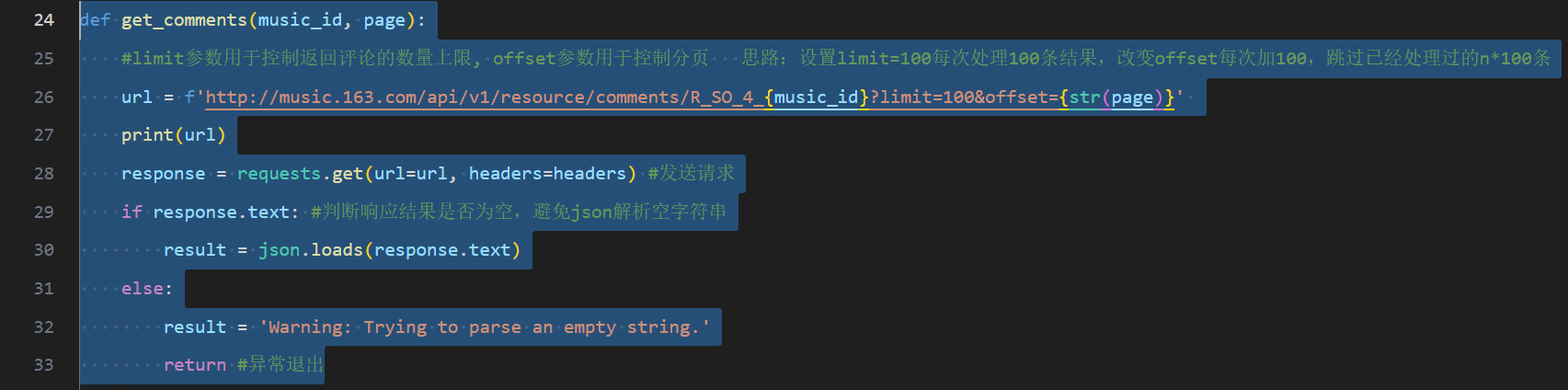 图 3代码段-获取Json文本并转换为Python对象
图 3代码段-获取Json文本并转换为Python对象
三,数据爬取过程分析
(介绍要爬取的数据爬取过程,包括关键代码截图和代码运行后结果截图等,并说明每个截图所表达的信息,如果有数据爬取后的处理、分析并作可视化结果,可获得另外加分势)
(一)爬虫预设项
在爬虫脚本中,首先需要设置3个关键参数:
- music_id:设置歌曲的id,id是歌曲的唯一标识符,指定id以爬取指定歌曲的评论
- xlsfile_name:设置xls文件名,请按给定格式修改
- max_cnt:设置爬取的评论数
 图 4代码段-爬虫预设项
图 4代码段-爬虫预设项
(二)创建空工作表
因为需要将爬取到的记录保存在xls表格中,因此需要创建一个工作表,设置表的字符集为utf-8,将4类要爬取内容的字段写入表头。
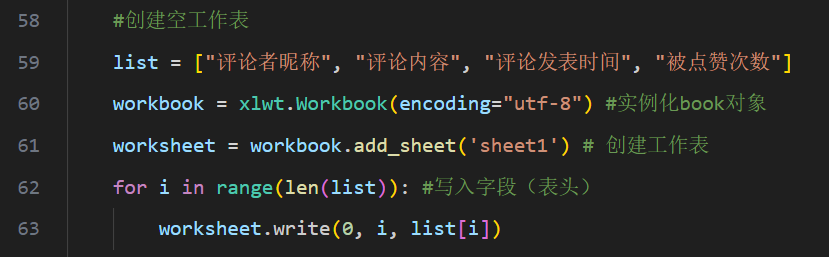 图 5代码段-创建空工作表
图 5代码段-创建空工作表
(三)正式爬取
为了增强代码可读性和可维护性,因此将爬虫的主要工作部分编写成函数get_comments(),如图7所示。
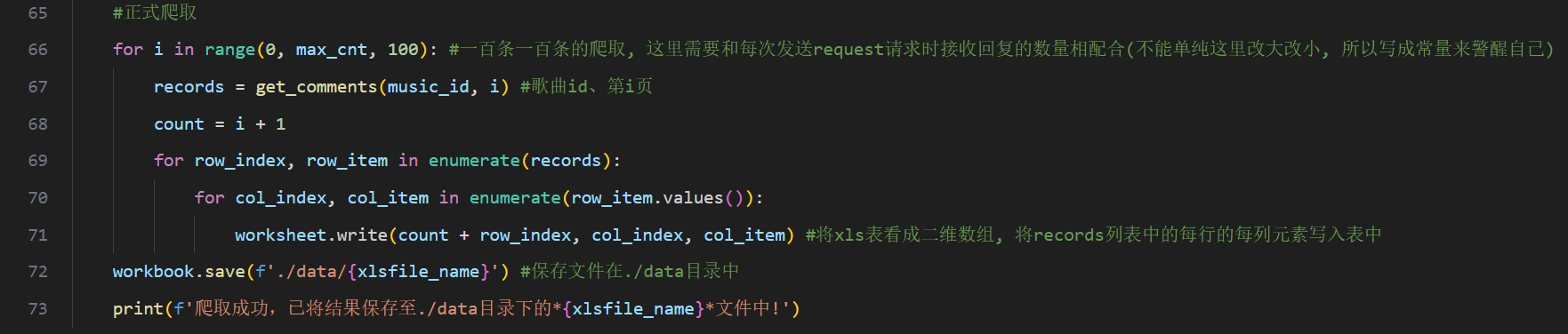 图 6代码段-正式爬取
图 6代码段-正式爬取 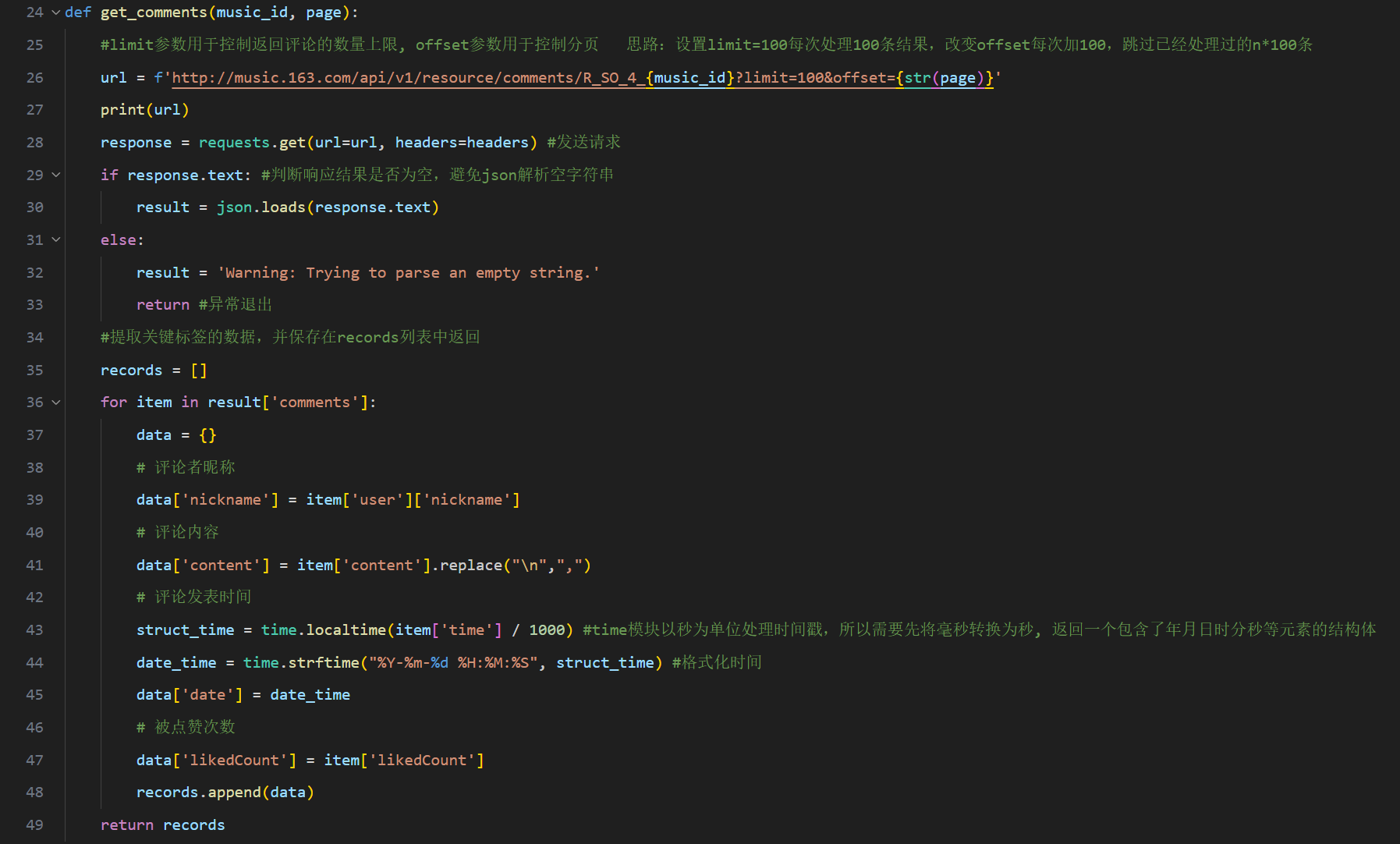 图 7代码段-爬取函数
图 7代码段-爬取函数
脚本循环逻辑:
每次循环向网易云音乐官方网站的api接口地址请求100条结果(uri的get参数limit=100),从返回的结果中提取4类关键标签的内容(通过key值访问value),每一组(即一位用户)的数据构成一个集合data,作为元素添加到records列表中,需要处理的主要有content标签(即评论,去除其中的换行符又逗号替代),time标签(即评论发布时间,因为该标签以十三位时间戳的形式存储,因此使用特定的函数将其进行时间格式化,此处精确到秒)。
get_comments()函数每处理完100条结果,就将records列表返回,在__main__模块中的两层嵌套循环按顺序将数据写入到已经创建好的xls表格中(具体是采用了enumerate()函数处理列表和集合容器以访问其中元素,相较于索引的方式会更方便)。
将100条结果写入xls表中后,最外层的循环(range语句)步长为100,这是因为在get_comments()函数第26行设置的url末尾的get参数offset=100,其含义代表跳过前100条已经处理过的评论。
*图8形象地展示了此爬虫的循环逻辑
*关于limit参数和offset参数的作用见图9
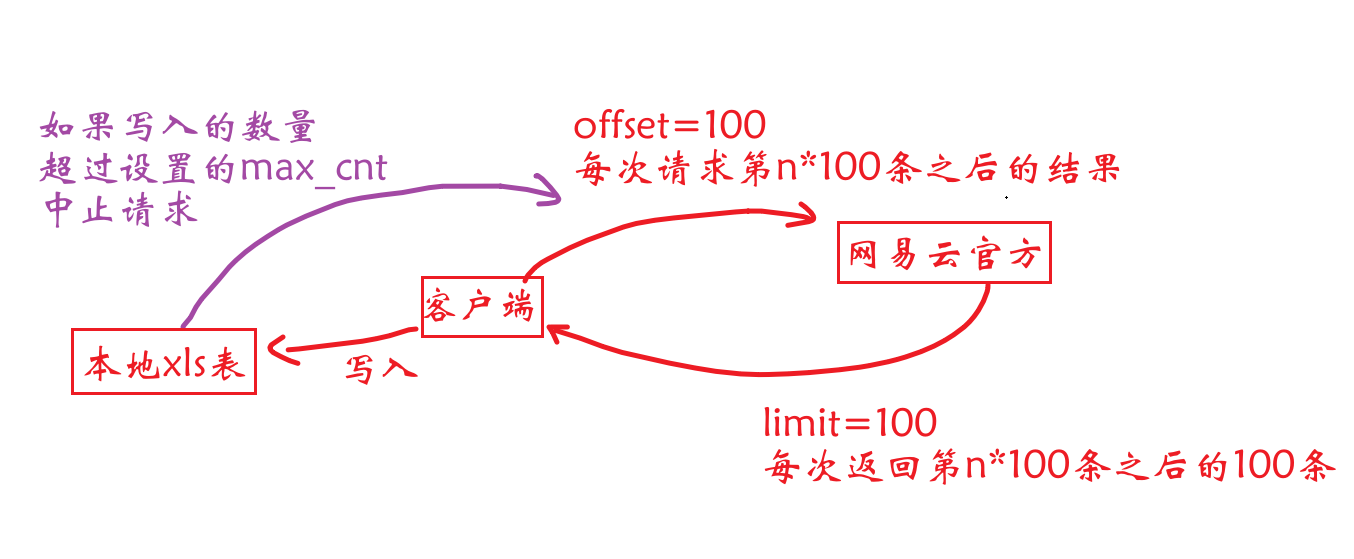 图 8脚本循环逻辑
图 8脚本循环逻辑
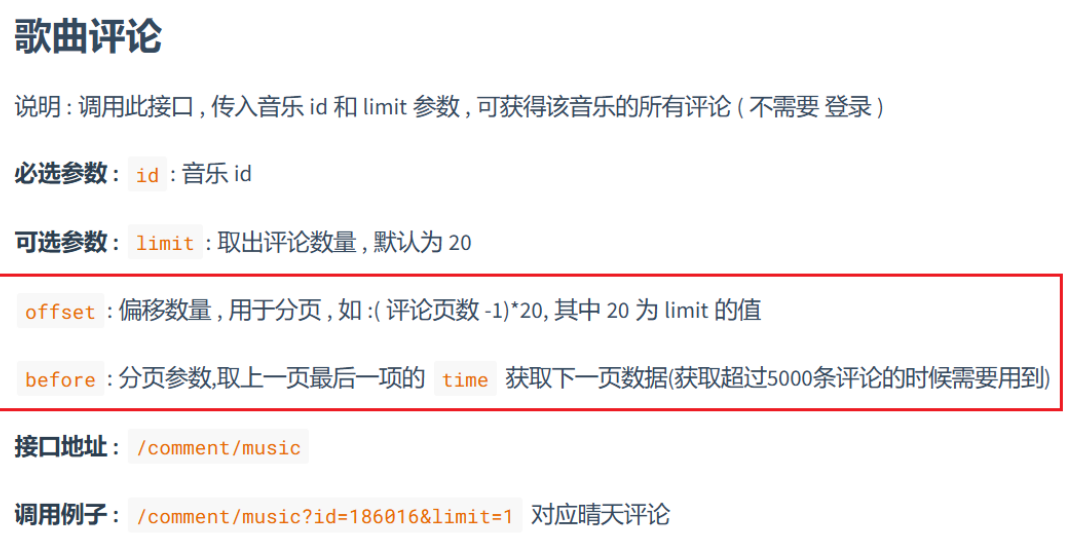 图 9网易云音乐官方网站api参数说明
图 9网易云音乐官方网站api参数说明
(四)爬取结果展示
下面将展示脚本运行后,爬取到的结果
首先修改爬虫的预设项,设置id、xls表名、爬取1000条
 图 10代码段-爬虫预设项
图 10代码段-爬虫预设项
运行后,在终端得到对应输出提示,在设定的目录中也出现了我们要的表格
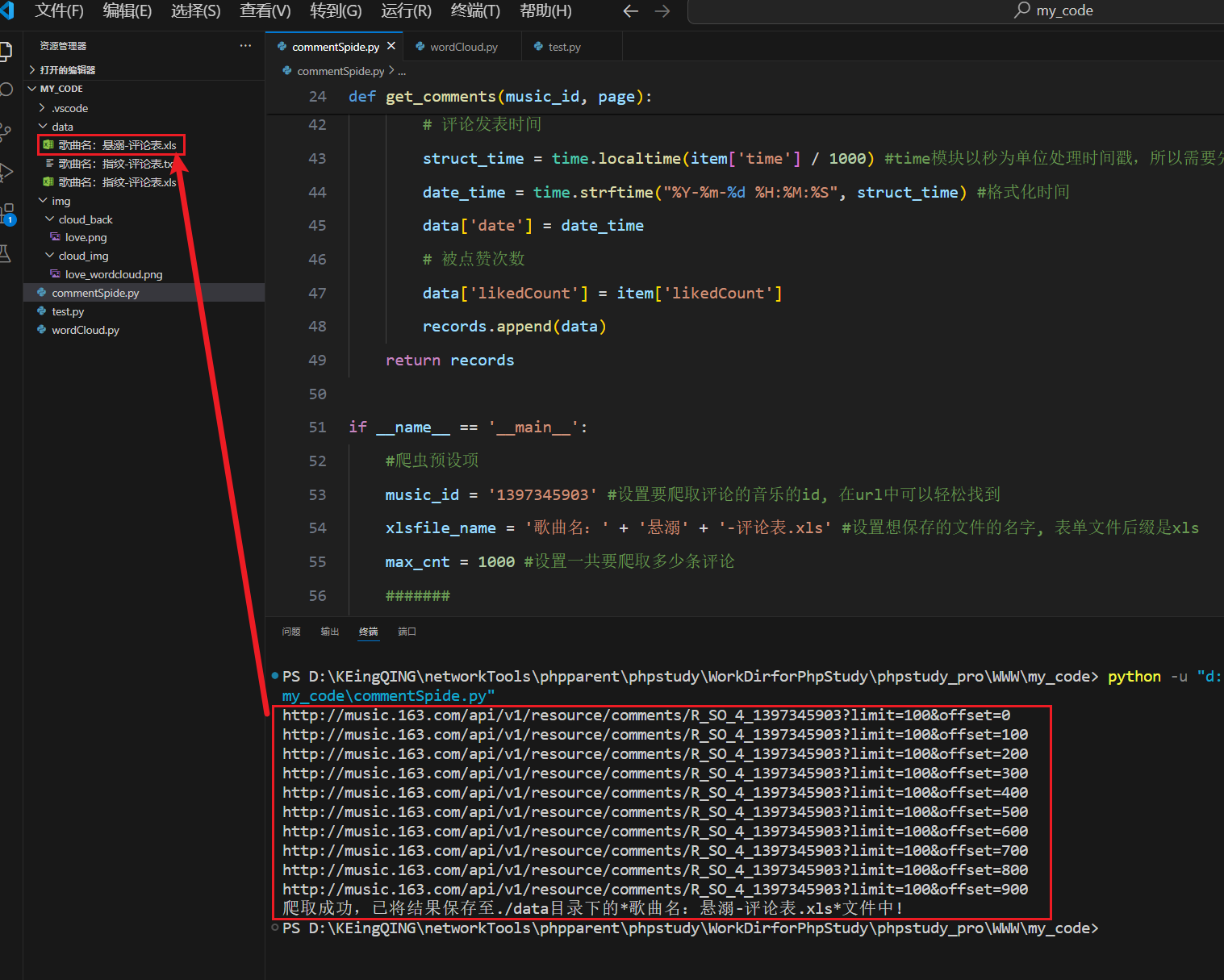 图 11爬虫脚本运行结果
图 11爬虫脚本运行结果
在资源管理器中打开表格,和网易云音乐官方页面进行对比,确认评论的正确性
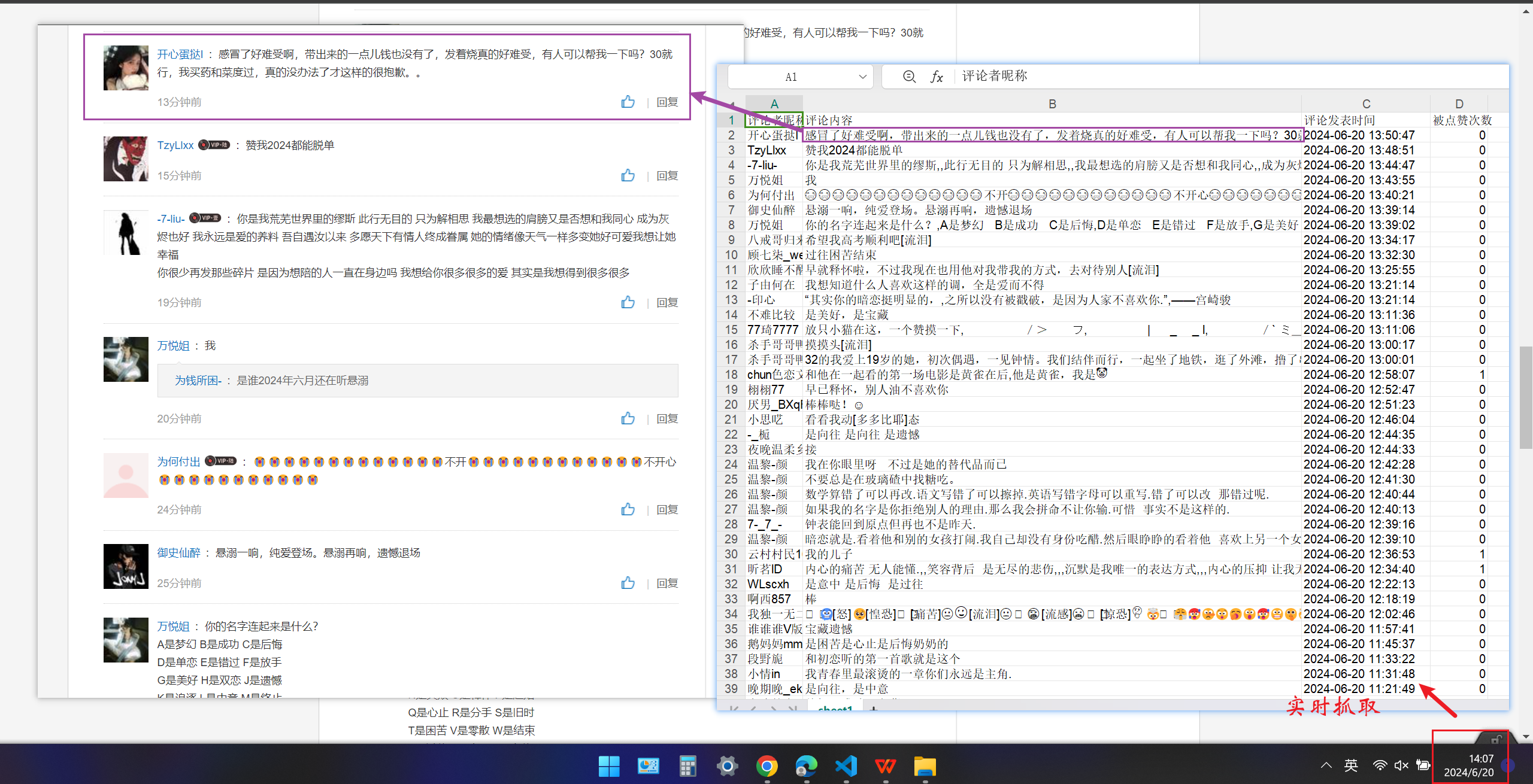 图 12确认爬取结果
图 12确认爬取结果
(五)分析爬取评论热词,制作词云,数据可视化
利用jieba、wordcloud、imageio、xlrd库等工具将已经保存在本地的xls表中的评论提取到同名的txt文件中(具体代码见图13所示的touch_txtfile()函数)
然后提取txt文件中的文本并转换为Python易处理的string对象,接着再用jieba库的lcut函数对字符串进行词汇分割并保存在列表中,最后由wordcloud库的generate()函数产生词云(具体代码见图14所示的work()函数), PIL库的show()函数会将生成出的词云图自动打开。
*考虑到程序的完整性,脚本进行了很多文件存在性的判断与自动创建文件机制,只改动爬虫预设项即可完成一条龙制作
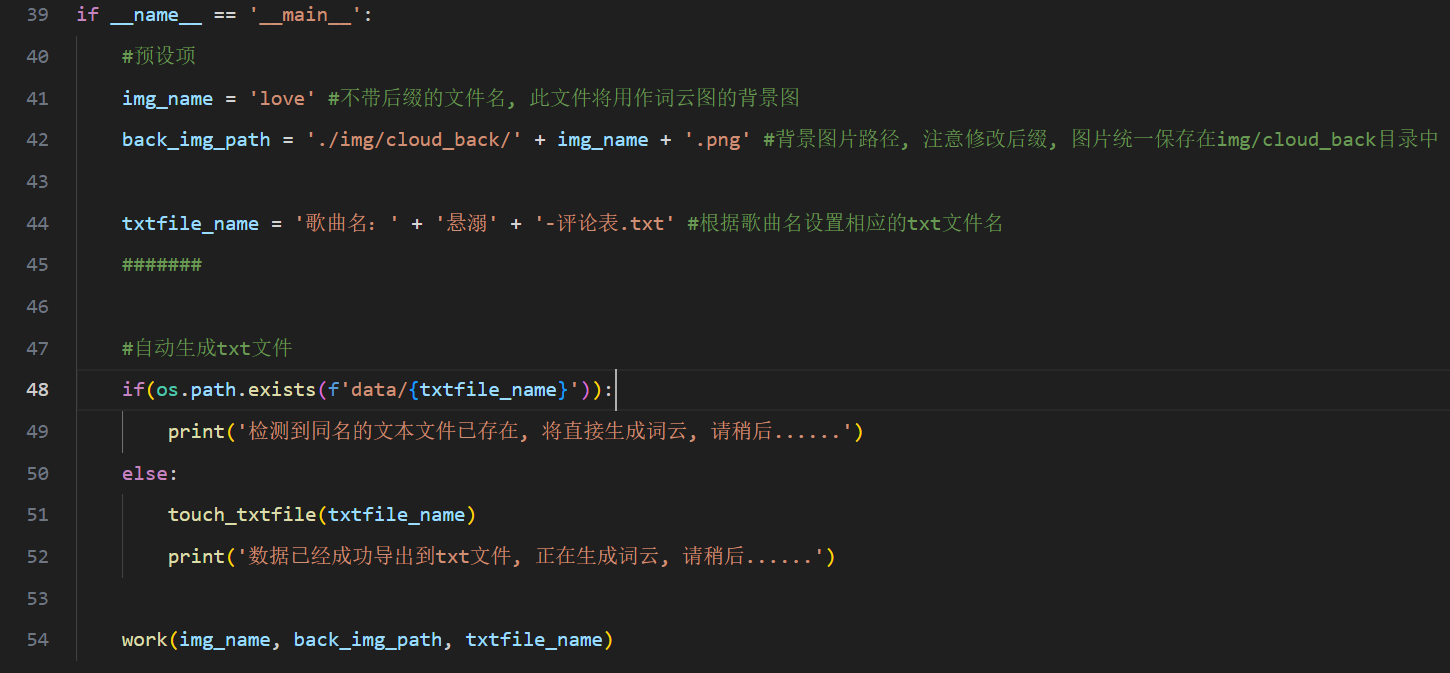 图 13代码段-词云制作预设项
图 13代码段-词云制作预设项
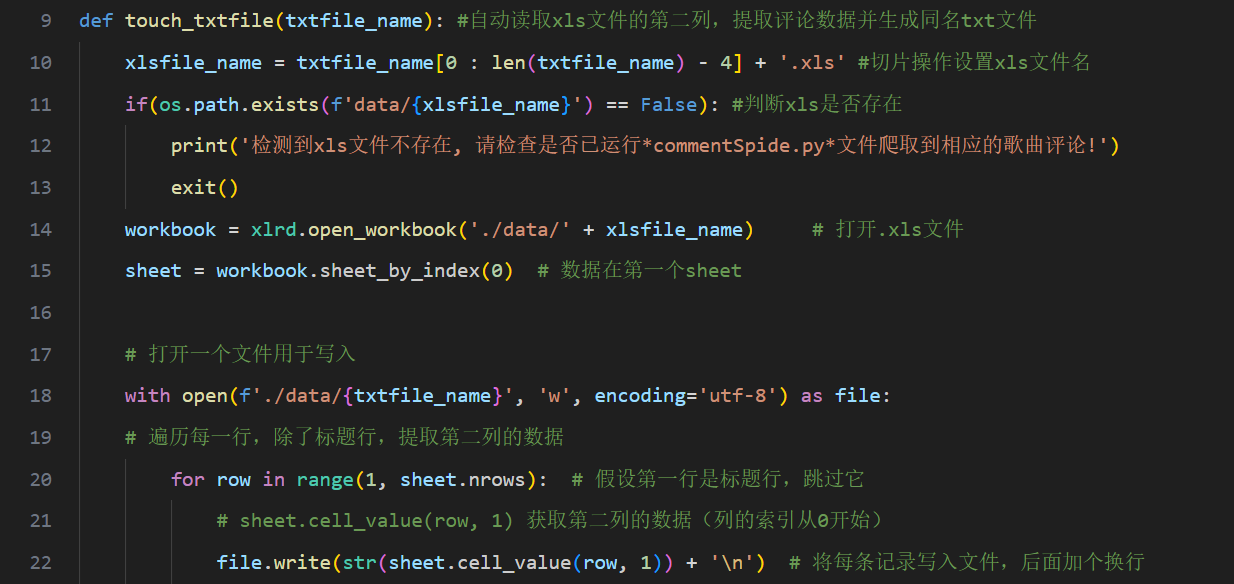 图 14代码段-检测/自动创建txt文件
图 14代码段-检测/自动创建txt文件
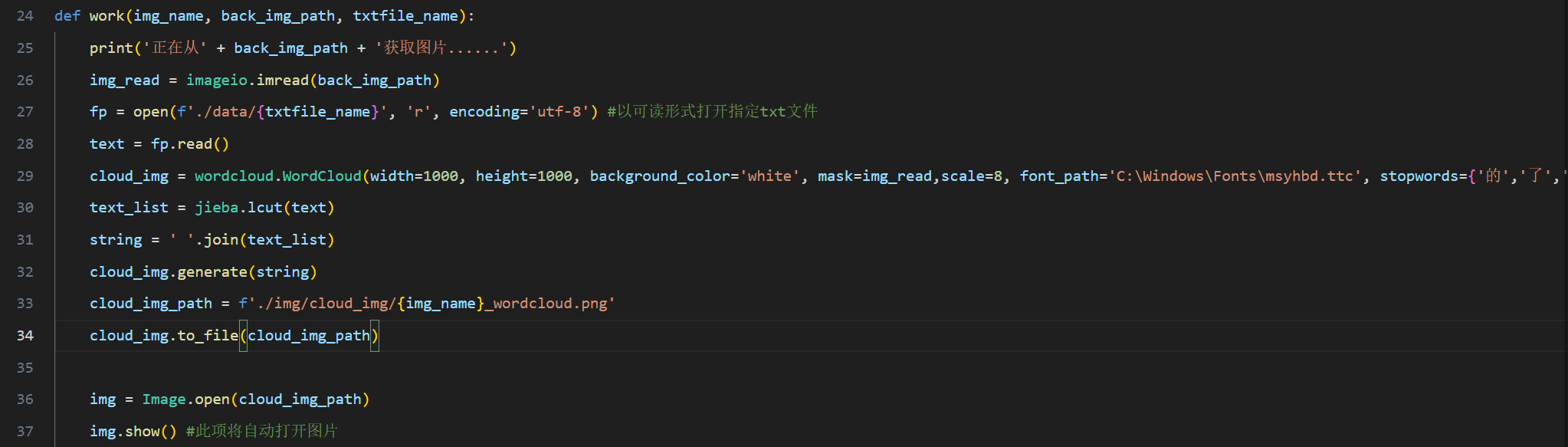 图 15代码段-制作词云
图 15代码段-制作词云
(六)词云制作展示
首先设置预设项,img_name是想以哪张图片为背景来制作词云,如图14所示(需要注意修改其后缀),然后是前面已经爬取并保存在本地的xls文件的名字(见图10&11)。
 图 16制作词云预设项
图 16制作词云预设项
 图 17词云背景图
图 17词云背景图
运行直接获得结果,图片会被脚本自动打开。
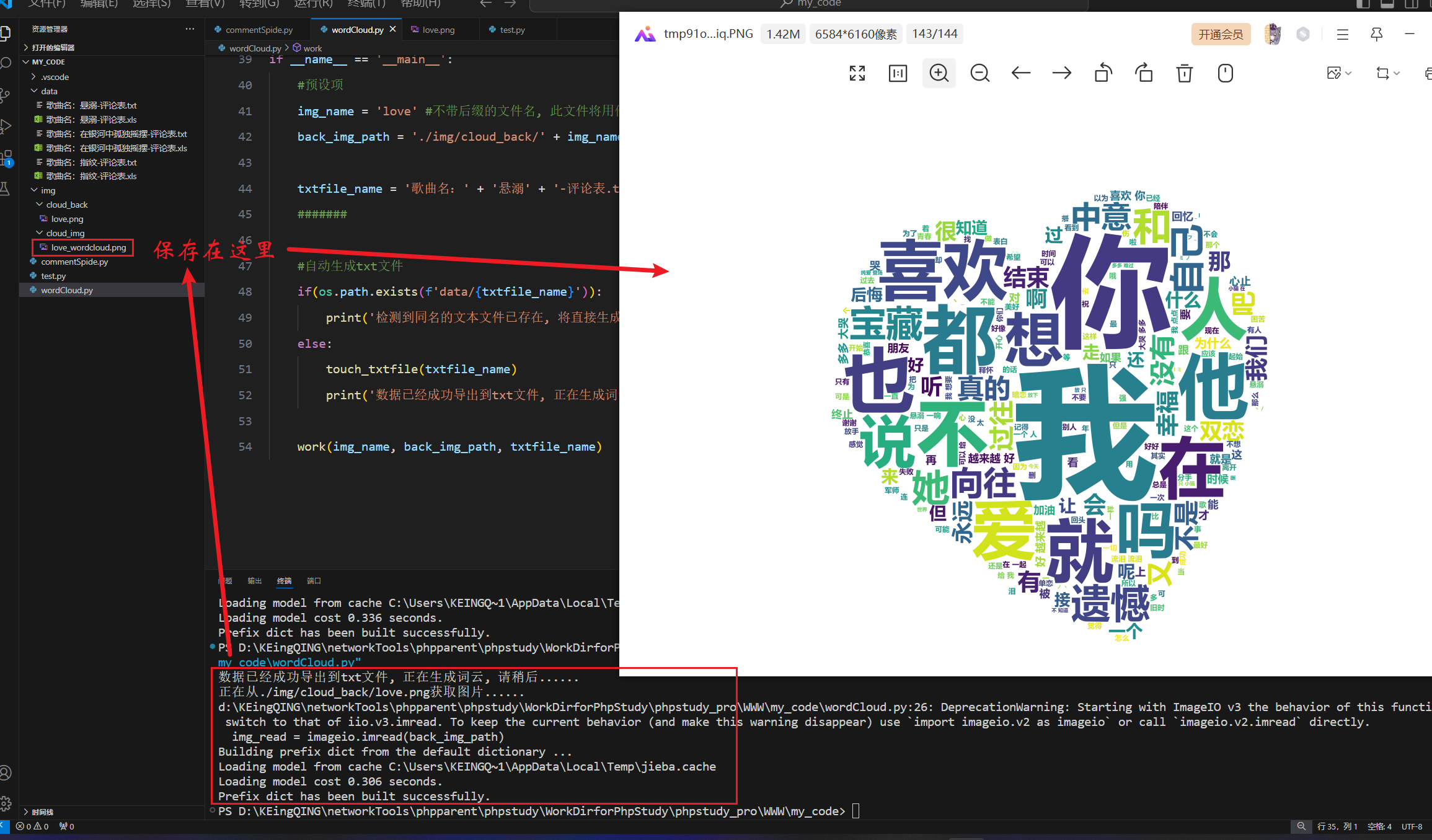 图 18词云脚本运行结果
图 18词云脚本运行结果
四,总结及下一步工作
(介绍爬取结果,并进行总结,例如本文采用了什么方法,得到的结果如何,以及过程中遇到的技术难题及解决办法和感想等等;如果有可能,介绍下一步分析工作的思路,对未来数据爬取作进一步的建议和展望)
(一)爬取结果介绍
在本次项目中,成功从网易云音乐通过其公开的api接口爬取到了特定歌曲的用户评论数据。具体来说,通过发送http的get请求,获取到了评论内容,另外还包括用户昵称、评论时间、点赞数等信息。这些原始数据随后被清洗和预处理,去除了不必要的信息,并进行了格式化,以便于后续分析。另外利用这些清洗后的数据生成了一张热词云图,直观地展示了评论中最常提及的词汇和话题。
(二)方法总结
采用的方法:requests模块发送请求:使用Python的requests模块向网易云音乐的api接口发送http get请求。
数据解析与提取:使用json模块将响应结果解析成Python字典/列表,并提取需要的字段,如用户昵称、评论内容、评论时间、点赞数等。
数据清洗和处理:对提取到的数据进行清洗,包括去除符号、去除换行符、统一数据格式等。
词云图构建:使用wordcloud库,根据清洗后的评论内容生成热词云图,直观展示频繁出现的词汇。
(三)得到的结果:
成功爬取了若干条评论数据,并提取了其中的关键元素。
生成了一张热词云图,展示了用户评论中最常提及的词汇和主题。
五,参考文献
(如果在大作业中介绍了别人的东西,要用参考文献引用方式在这里列出)
参考文章链接如下:
https://neteasecloudmusicapi.js.org/#/?id=歌曲评论 --网易云API说明(关于歌曲评论)
https://blog.csdn.net/zhouz92/article/details/106789137 --xlwt库的使用, 创建xls表并写入记录
https://blog.csdn.net/weixin_42221654/article/details/131477857 --区分十位时间戳(精确到秒)和十三位时间戳(精确到毫秒)
https://blog.csdn.net/Liang_ming_/article/details/106664126 --时间戳转换为格式化时间
https://blog.csdn.net/FMC_WBL/article/details/136143734 --json解析异常分析
https://www.runoob.com/python/att-time-strftime.html --strftime()格式化时间函数
https://blog.csdn.net/qq_44350242/article/details/102991574 --python绘制词云图wordcloud
https://blog.csdn.net/NeverLate_gogogo/article/details/109333970 --os库控制文件
https://blog.csdn.net/qq_45779334/article/details/112172895 --xlrd库控制xls文件
六,附录
(将本次大作业代码附在此;其他你认为必要的内容也可附于此)
(一)项目结构
如图19所示是本项目结构,MY_CODE文件夹是该项目的最高父级,其中存放data文件夹用于存放爬取后自动保存的xls表格文件以及制作词云前自动生成是txt文本文件,img文件夹中存放两类图片资源(cloud_back文件夹中是词云背景图,cloud_img文件夹中存放运行脚本2后产生的词云图),除此之外便是两个关键的脚本,看脚本名称也明白它们的作用了。
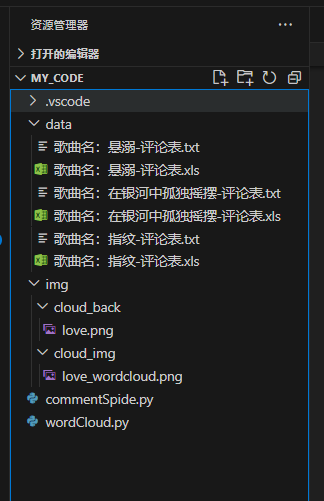 图 19项目结构
图 19项目结构
(二)开发日志
"""开发日志
#错误解决1: 十三位时间戳精确到毫秒而不是秒, 但python的time模块以秒为单位来处理时间数据, 需要/1000来转换为秒(主要在这之前我并不清楚时间戳原来还有十位和十三位之分......)
#错误解决2: json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0):指的是json.loads()函数解析数据时遇到了空字符导致的错误,加上判空条件使代码更加健壮
#错误解决3: 爬取时有时爬到一半突然中断, 原因是网络不稳定导致请求包返回的数据为空, 从而导致json解析空字符串而报错中止程序
#错误解决4: 对于保存记录的xls表, 其命名不能包含一些英文符号(半角符号, 例如:), 否则会导致文件命名和预期不符(脚本自动创建出的文件名不全, 且无xls文件后缀)
#错误解决5: 为了完善程序,项目添加了许多自动机制如自动创建文件、自动打开文件, 但在运行脚本时曾报错, 后续添加os库的exists()函数严格判断文件的存在性, 增强了代码的健壮性
#错误解决6: 运行词云制作脚本时碰上了编码问题, 通过规定从xls文件向txt文件写入文本时的字符集为utf-8后解决此问题
"""
(三)脚本源码1:爬虫部分
python
#参考文章链接
#https://neteasecloudmusicapi.js.org/#/?id=%e6%ad%8c%e6%9b%b2%e8%af%84%e8%ae%ba --网易云API说明(关于歌曲评论)
#https://blog.csdn.net/zhouz92/article/details/106789137 --xlwt库的使用, 创建xls表并写入记录
#https://blog.csdn.net/weixin_42221654/article/details/131477857 --区分十位时间戳(精确到秒)和十三位时间戳(精确到毫秒)
#https://blog.csdn.net/Liang_ming_/article/details/106664126 --时间戳转换为格式化时间
#https://blog.csdn.net/FMC_WBL/article/details/136143734 --json解析异常分析
#https://www.runoob.com/python/att-time-strftime.html --strftime()格式化时间函数
#https://blog.csdn.net/qq_44350242/article/details/102991574 --python绘制词云图wordcloud
#https://blog.csdn.net/NeverLate_gogogo/article/details/109333970 --os库控制文件
#https://blog.csdn.net/qq_45779334/article/details/112172895 --xlrd库控制xls文件
"""开发日志
#错误解决1: 十三位时间戳精确到毫秒而不是秒, 但python的time模块以秒为单位来处理时间数据, 需要/1000来转换为秒(主要在这之前我并不清楚时间戳原来还有十位和十三位之分......)
#错误解决2: json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0):指的是json.loads()函数解析数据时遇到了空字符导致的错误,加上判空条件使代码更加健壮
#错误解决3: 爬取时有时爬到一半突然中断, 原因是网络不稳定导致请求包返回的数据为空, 从而导致json解析空字符串而报错中止程序
#错误解决4: 对于保存记录的xls表, 其命名不能包含一些英文符号(半角符号, 例如:), 否则会导致文件命名和预期不符(脚本自动创建出的文件名不全, 且无xls文件后缀)
#错误解决5: 为了完善程序,项目添加了许多自动机制如自动创建文件、自动打开文件, 但在运行脚本时曾报错, 后续添加os库的exists()函数严格判断文件的存在性, 增强了代码的健壮性
#错误解决6: 运行词云制作脚本时碰上了编码问题, 通过规定从xls文件向txt文件写入文本时的字符集为utf-8后解决此问题
"""
import requests
import time #处理时间
import json #处理json文件
import xlwt #处理xls表格
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'
}
def get_comments(music_id, page):
#limit参数用于控制返回评论的数量上限, offset参数用于控制分页 思路:设置limit=100每次处理100条结果,改变offset每次加100,跳过已经处理过的n*100条
url = f'http://music.163.com/api/v1/resource/comments/R_SO_4_{music_id}?limit=100&offset={str(page)}'
print(url)
response = requests.get(url=url, headers=headers) #发送请求
if response.text: #判断响应结果是否为空,避免json解析空字符串
result = json.loads(response.text)
else:
result = 'Warning: Trying to parse an empty string.'
return #异常退出
#提取关键标签的数据,并保存在records列表中返回
records = []
for item in result['comments']:
data = {}
# 评论者昵称
data['nickname'] = item['user']['nickname']
# 评论内容
data['content'] = item['content'].replace("\n",",")
# 评论发表时间
struct_time = time.localtime(item['time'] / 1000) #time模块以秒为单位处理时间戳,所以需要先将毫秒转换为秒, 返回一个包含了年月日时分秒等元素的结构体
date_time = time.strftime("%Y-%m-%d %H:%M:%S", struct_time) #格式化时间
data['date'] = date_time
# 被点赞次数
data['likedCount'] = item['likedCount']
records.append(data)
return records
if __name__ == '__main__':
#爬虫预设项
music_id = '1397345903' #设置要爬取评论的音乐的id, 在url中可以轻松找到 --2155423467 --1397345903
xlsfile_name = '歌曲名:' + '悬溺' + '-评论表.xls' #设置想保存的文件的名字, 表单文件后缀是xls
max_cnt = 1000 #设置一共要爬取多少条评论
#######
#创建空工作表
list = ["评论者昵称", "评论内容", "评论发表时间", "被点赞次数"]
workbook = xlwt.Workbook(encoding="utf-16") #实例化book对象
worksheet = workbook.add_sheet('sheet1') # 创建工作表
for i in range(len(list)): #写入字段(表头)
worksheet.write(0, i, list[i])
#正式爬取
for i in range(0, max_cnt, 100): #一百条一百条的爬取, 这里需要和每次发送request请求时接收回复的数量相配合(不能单纯这里改大改小, 所以写成常量来警醒自己)
records = get_comments(music_id, i) #歌曲id、第i页
count = i + 1
for row_index, row_item in enumerate(records):
for col_index, col_item in enumerate(row_item.values()):
worksheet.write(count + row_index, col_index, col_item) #将xls表看成二维数组, 将records列表中的每行的每列元素写入表中
workbook.save(f'./data/{xlsfile_name}') #保存文件在./data目录中
print(f'爬取成功,已将结果保存至./data目录下的*{xlsfile_name}*文件中!')
#爬取示例(存储在records列表中)
"""
[{'nickname': '没感情欧豪', 'content': '14年了[蛋仔吹口哨]', 'date': '2024-06-19 19:17:39', 'likedCount': 0},
{'nickname': 'Dallas233', 'content': '12年了', 'date': '2024-06-19 16:42:00', 'likedCount': 1},
{'nickname': '极南观海-', 'content': '13年了[西西惊讶]', 'date': '2024-06-19 12:19:51', 'likedCount': 0},
...
"""(四)脚本源码2:制作词云
python
import jieba
import wordcloud
import imageio
import os
import xlrd #读取xls文件
from PIL import Image #单纯用来打开图片
def touch_txtfile(txtfile_name): #自动读取xls文件的第二列,提取评论数据并生成同名txt文件
xlsfile_name = txtfile_name[0 : len(txtfile_name) - 4] + '.xls' #切片操作设置xls文件名
if(os.path.exists(f'data/{xlsfile_name}') == False): #判断xls是否存在
print('检测到xls文件不存在, 请检查是否已运行*commentSpide.py*文件爬取到相应的歌曲评论!')
exit()
workbook = xlrd.open_workbook('./data/' + xlsfile_name) # 打开.xls文件
sheet = workbook.sheet_by_index(0) # 数据在第一个sheet
# 打开一个文件用于写入
with open(f'./data/{txtfile_name}', 'w', encoding='utf-8') as file:
# 遍历每一行,除了标题行,提取第二列的数据
for row in range(1, sheet.nrows): # 假设第一行是标题行,跳过它
# sheet.cell_value(row, 1) 获取第二列的数据(列的索引从0开始)
file.write(str(sheet.cell_value(row, 1)) + '\n') # 将每条记录写入文件,后面加个换行
def work(img_name, back_img_path, txtfile_name):
print('正在从' + back_img_path + '获取图片......')
img_read = imageio.imread(back_img_path)
fp = open(f'./data/{txtfile_name}', 'r', encoding='utf-8') #以可读形式打开指定txt文件
text = fp.read()
cloud_img = wordcloud.WordCloud(width=1000, height=1000, background_color='white', mask=img_read,scale=8, font_path='C:\Windows\Fonts\msyhbd.ttc', stopwords={'的','了','是'})
text_list = jieba.lcut(text)
string = ' '.join(text_list)
cloud_img.generate(string)
cloud_img_path = f'./img/cloud_img/{img_name}_wordcloud.png'
cloud_img.to_file(cloud_img_path)
img = Image.open(cloud_img_path)
img.show() #此项将自动打开图片
if __name__ == '__main__':
#预设项
img_name = 'love' #不带后缀的文件名, 此文件将用作词云图的背景图
back_img_path = './img/cloud_back/' + img_name + '.png' #背景图片路径, 注意修改后缀, 图片统一保存在img/cloud_back目录中
txtfile_name = '歌曲名:' + '悬溺' + '-评论表.txt' #根据歌曲名设置相应的txt文件名
#######
#自动生成txt文件
if(os.path.exists(f'data/{txtfile_name}')):
print('检测到同名的文本文件已存在, 将直接生成词云, 请稍后......')
else:
touch_txtfile(txtfile_name)
print('数据已经成功导出到txt文件, 正在生成词云, 请稍后......')
work(img_name, back_img_path, txtfile_name)