Abstract
现有的最先进的目标检测KD方法大多基于特征模仿。本文提出了一种通用且有效的预测模仿蒸馏方案,称为CrossKD,该方案将学生检测头的中间特征传递给教师的检测头,然后强制这些交叉头预测模仿教师的预测。这种方式使学生检测头免于接收来自标注和教师预测的矛盾监督信号,从而大大提高了学生检测器的性能。此外,由于模仿教师的预测是知识蒸馏的目标,CrossKD相比于特征模仿提供了更多面向任务的信息。
1 Introduction
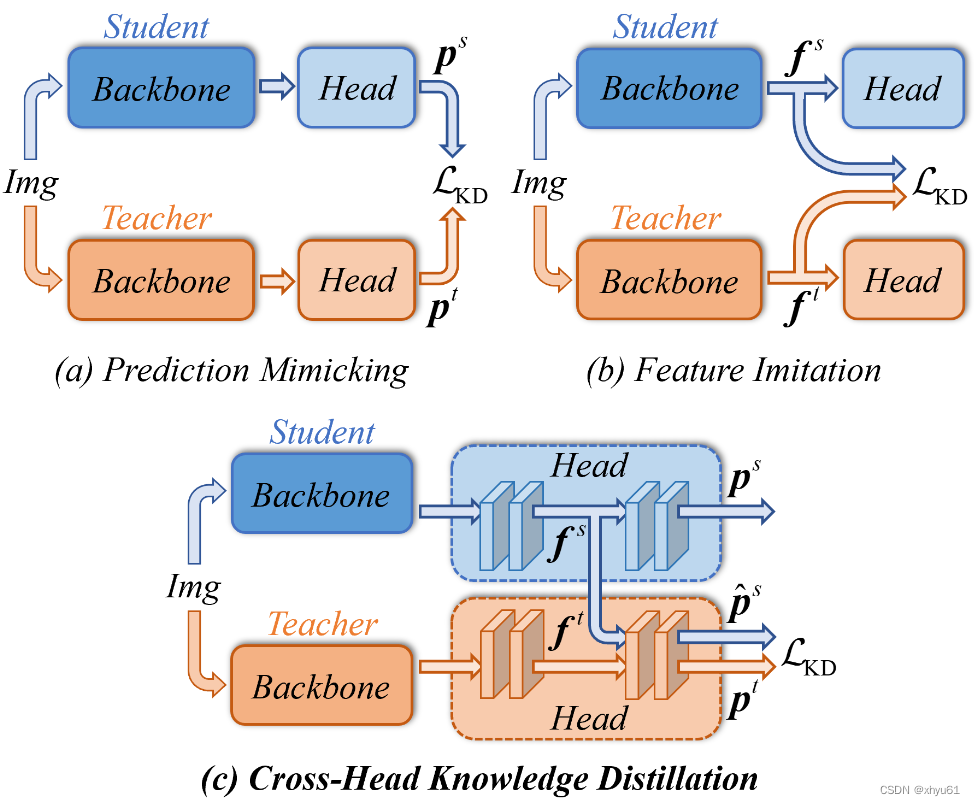
图1:传统知识蒸馏方法与我们的CrossKD的比较。CrossKD并不显式地强制教师-学生对之间的中间特征图或预测的一致性,而是隐式地建立教师-学生对之间检测头的连接,以提高蒸馏效率。
3 Methodology
3.1 Analysis of the Target Conflict Problem
目标冲突是传统预测模仿方法中常见的问题。与为每张图像分配特定类别的分类任务不同,高级检测器中的标签通常是动态分配的,并且不是确定的。通常,检测器依赖于一个人工设计的原则,即分配器,来确定每个位置的标签。在大多数情况下,检测器无法准确再现分配器的标签,这导致了知识蒸馏中教师-学生目标之间的冲突。此外,学生和教师在实际场景中分配器的一致性问题进一步加大了真实标签与蒸馏目标之间的距离。
已有方法旨在直接最小化教师和学生预测之间的差异。其目标可以描述为:
L K D = 1 ∣ S ∣ ∑ r ∈ R S ( r ) D pred ( p s ( r ) , p t ( r ) ) (1) \mathcal{L}{KD}=\frac{1}{|\mathcal{S}|}\sum{r\in\mathcal{R}}\mathcal{S}(r)\mathcal{D}_\text{pred}(p^s(r),p^t(r))\tag{1} LKD=∣S∣1r∈R∑S(r)Dpred(ps(r),pt(r))(1)
其中 p s p^s ps和 p t p^t pt分别为学生和教师检测头生成的预测向量, D pred ( ⋅ ) \mathcal{D}_\text{pred}(\cdot) Dpred(⋅)表示计算 p s p^s ps和 p t p^t pt之间差距的损失函数,如分类任务中的KL散度,回归任务的L1损失或LD, S ( ⋅ ) \mathcal{S}(\cdot) S(⋅)是区域选择原则(region selection principle),在整个图像区域 R \mathcal{R} R中的每个位置 r r r上生成一个权重。
值得注意的是,函数 S ( ⋅ ) \mathcal{S}(\cdot) S(⋅)在一定程度上可以通过降低教师-学生差异较大的区域的权重来缓解目标冲突问题。然而,高度不确定的区域通常比无争议的区域包含更多对学生有利的信息。忽略这些区域可能会对预测模仿方法的有效性产生很大影响。因此,为了推进预测模仿的边界,有必要优雅地处理目标冲突问题,而不是直接降低权重。
3.2 Cross-Head Knowledge Distillation
普通蒸馏方法存在目标冲突问题。
本节提出了一种新的交叉头知识蒸馏(CrossKD)方法。整体框架如图4所示。与许多以前的预测模仿方法类似,我们的CrossKD在预测上进行蒸馏。不同的是,CrossKD将学生的中间特征传递给教师的检测头,并生成交叉头预测来进行蒸馏。
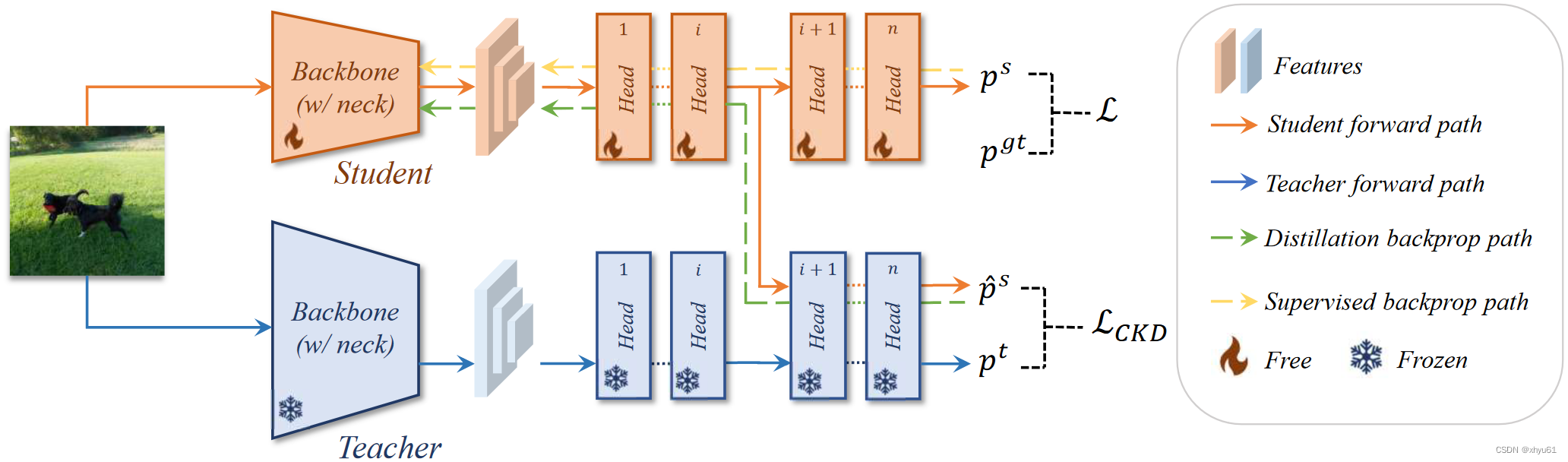
图4:所提出的CrossKD的整体框架。对于给定的教师-学生对,CrossKD首先将学生的中间特征传递到教师层中,并生成交叉头预测 p ^ s \hat{p}^s p^s。然后,在教师的原始预测和学生的交叉头预测之间计算蒸馏损失。在反向传播中,检测损失的梯度通常通过学生的检测头传递 ,而蒸馏梯度则通过冻结的教师层传播。
给定一个稠密检测器(dense detector),如RetinaNet,每个探测头都包含一些卷积层,用 { C i } \{C_i\} {Ci}表示。为了简化,令每个探测头有 n n n个卷积层(例如,RetinaNet中, n = 5 n=5 n=5,包含4个隐藏层和1个预测层)。使用 f i , i ∈ { 1 , 2 , ⋯ , n − 1 } f_i,i\in\{1,2,\cdots,n-1\} fi,i∈{1,2,⋯,n−1}来表示由 C i C_i Ci表示的特征图, f 0 f_0 f0为 C 1 C_1 C1输入的特征。预测结果 p p p由最后一个卷积核 C n C_n Cn产生。 对于给定的教师-学生对,教师和学生的预测的结果分别为 p t p^t pt和 p s p^s ps。
CrossKD将学生的中间特征 f i s , i ∈ { 1 , 2 , ⋯ , n − 1 } f_i^s,i\in\{1,2,\cdots,n-1\} fis,i∈{1,2,⋯,n−1}提供给 C i + 1 t C_{i+1}^t Ci+1t(教师模型探测头的第 i + 1 i+1 i+1个卷积层),得到交叉结果 p ^ s \hat{p}^s p^s。使用KD损失计算 p ^ s \hat{p}^s p^s和 p t p^t pt之间的距离:
L CrossKD = 1 ∣ S ∣ ∑ r ∈ R S ( r ) D pred ( p ^ s ( r ) , p t ( r ) ) (2) \mathcal{L}\text{CrossKD}=\frac{1}{|\mathcal{S}|}\sum{r\in\mathcal{R}}\mathcal{S}(r)\mathcal{D}_\text{pred}(\hat{p}^s(r),p^t(r))\tag{2} LCrossKD=∣S∣1r∈R∑S(r)Dpred(p^s(r),pt(r))(2)
其中 S ( ⋅ ) \mathcal{S}(\cdot) S(⋅)和 ∣ S ∣ |\mathcal{S}| ∣S∣是区域选择原则和标准化因子。CrossKD中 S ( ⋅ ) = 1 \mathcal{S}(\cdot)=1 S(⋅)=1。
使用CrossKD成功将蒸馏损失和预测损失分配到了不同的分支上。预测损失的梯度经过了整个学生模型的探测头,蒸馏损失的梯度从被冻结的教师模型探测器传递到学生模型的潜在特征,启发性地增加了教师和学生之间的一致性。
CrossKD允许学生检测头的一部分仅与检测损失相关,从而能够更好地优化真实目标。
3.3 Optimization Objectives
训练的整体损失被定义为预测损失和蒸馏损失的加权和。
L = L c l s ( p cls s , p cls g t ) + L reg ( p reg s , p reg g t ) + L CrossKD cls ( p ^ cls s , p cls t ) + L CrossKD reg ( p ^ reg s , p reg t ) \begin{align} \mathcal{L}&=\mathcal{L}{cls}(p\text{cls}^s,p_\text{cls}^{gt})+\mathcal{L}\text{reg}(p\text{reg}^s,p_\text{reg}^{gt}) \\ &+\mathcal{L}\text{CrossKD}^\text{cls}(\hat{p}\text{cls}^s,p_\text{cls}^t)+\mathcal{L}\text{CrossKD}^\text{reg}(\hat{p}\text{reg}^s,p_\text{reg}^t)\tag{3} \end{align} L=Lcls(pclss,pclsgt)+Lreg(pregs,preggt)+LCrossKDcls(p^clss,pclst)+LCrossKDreg(p^regs,pregt)(3)
其中 L cls \mathcal{L}\text{cls} Lcls和 L reg \mathcal{L}\text{reg} Lreg是学生预测的 p cls s p_\text{cls}^s pclss、 p reg s p_\text{reg}^s pregs和对应真实值目标 p cls g t p_\text{cls}^{gt} pclsgt、 p reg g t p_\text{reg}^{gt} preggt。额外的CrossKD的损失记为 L CrossKD reg \mathcal{L}\text{CrossKD}^\text{reg} LCrossKDreg,是交叉预测 p ^ cls s \hat{p}\text{cls}^s p^clss、 p ^ reg s \hat{p}\text{reg}^s p^regs和教师模型预测 p cls t p\text{cls}^t pclst、 p reg t p_\text{reg}^t pregt。
在不同分支中应用不同的距离函数 D pred \mathcal{D}_\text{pred} Dpred来传递特定任务的信息。
- 在分类分支中,我们将教师预测的分类得分视为软标签,并直接使用GFL中提出的质量焦点损失(Quality Focal Loss, QFL)来缩小教师和学生之间的距离。
- 至于回归,在密集检测器中主要有两种回归形式。第一种回归形式直接从锚框或点回归边界框。在这种情况下,直接使用GIoU作为 D pred \mathcal{D}_\text{pred} Dpred。在另一种情况下,回归形式预测一个向量来表示边框位置的分布,这比边界框表示的狄拉克分布包含更丰富的信息。为了高效地蒸馏位置分布的知识,使用KL散度来传递定位知识。