import torch
import torch.nn as nn
假设有一个大小为 10x3 的 Embedding 层,其中有 10 个单词,每个单词用一个长度为 3 的向量表示
num_words = 10
embedding_dim = 3
创建 Embedding 层
embedding_layer = nn.Embedding(num_words, embedding_dim)
print(embedding_layer.weight)
embedded_vectors = embedding_layer(torch.LongTensor(4))
print(embedded_vectors)
embedded_vectors = embedding_layer(torch.LongTensor(5))
print(embedded_vectors)
embedded_vectors = embedding_layer(torch.LongTensor(6))
print(embedded_vectors)
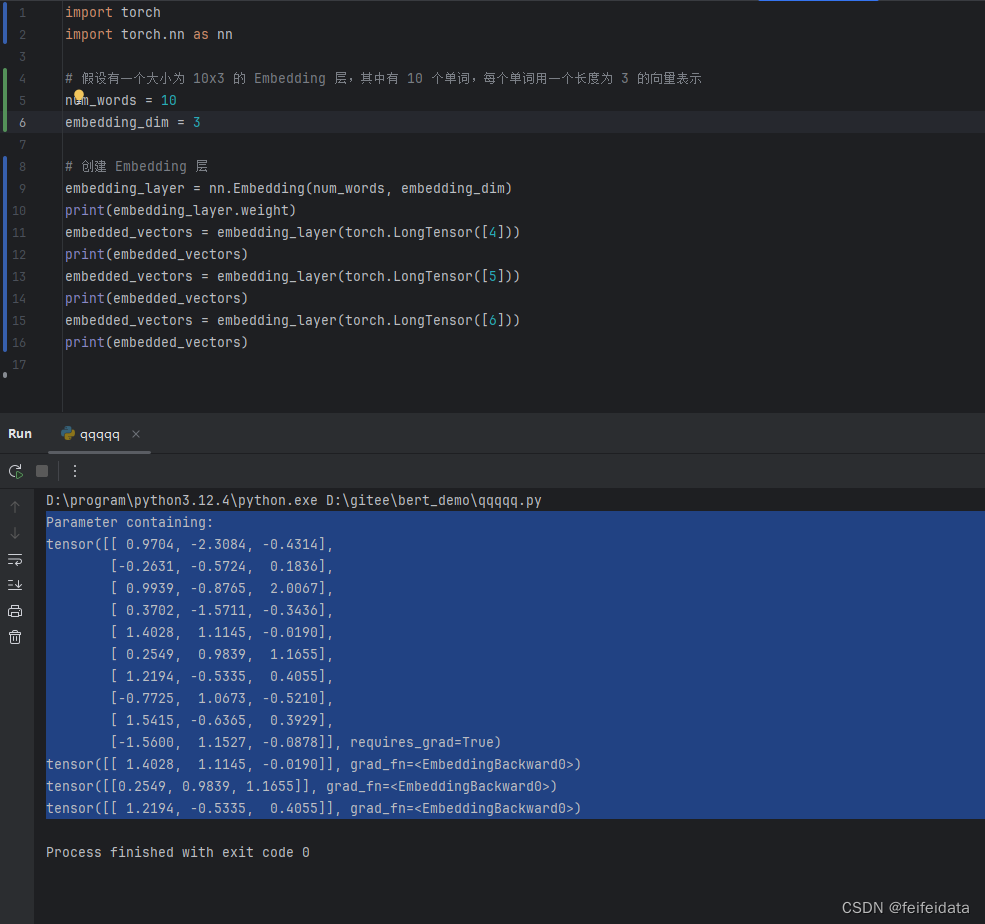
nn.Embedding层单词转向量实测
1.nn.Embedding创建对象embedding_layer
2.可以看到embedding_layer创建完成,其属性weight已经有值了
3.embedding_layer方法传入分别torch.LongTensor(4),torch.LongTensor(5),(torch.LongTensor(6)生成的结果就是根据索引值去weight里取值。
打破猜测:
1.原以为embedding_layer里进行的一个乘法,传参*随机权重,如embedded_vectors =torch.LongTensor(4)*W,实际不是,没有乘法
2.实际是nn.Embedding(num_words, embedding_dim)根据参数已经随机生成了所有的向量,之后仅需根据索引取值
原始猜测:
1.由于程序每次重启embedding_layer.weight生成的参数随机,为供断点续训和预测用,这些参数不能每次都随机生成,所以这些应该是要保存在模型中。即断点续训或预测时,embedding层的向量不应是随机生成了,而是读取模型文件中存储的模型参数。
2.embedding_layer.weight参与梯度更新,一开始以为此处没有
3.一开始根据各种信息判断nn.Embedding的内部机制是,或许有一个随机参数,乘以输入单词索引,得到嵌入向量,并且这个参数不参加更新,潜意识是参数不保存。
1.为什么有或许有一个随机参数,乘以输入单词索引,得到嵌入向量这样的理解?
因为看着是传入了索引,得到了一个随机向量,合理猜测应该是有个随即参数与传参相乘。
所以这里第一步的猜测就错了。
首先这个参数的确是有的,机制的实际是随机生成所有的可能的索引的向量,供直接取用。这里参数即嵌入向量
2.这个参数不参加更新?
这种不参与更新的参数,模型会保存吗?猜测应该不会,如果不会,那每次重启的得到的嵌入向量都变了,怎么供续训和预测用?对于transformer/bert,网络上的确对nn.Embedding这一步骤的机制讲解不够清晰,不知道嵌入向量是怎么得出的,不知道其中是否有需要训练的参数。
嵌入参数不参加更新这说法主要是来自李宏毅讲的注意力机制那块的误解,说是除了wq,wk,wv参数参与训练,没有别的参数了。这就和续训预测产生了极强的的矛盾,难以判断。
当你创建 nn.Embedding 层时,PyTorch 会随机初始化权重。这些权重在训练过程中会通过反向传播进行更新,以拟合模型的输入和输出数据,确保模型能够更好地进行预测或分类任务。