原创文章第570篇,专注"AI量化投资、世界运行的规律、个人成长与财富自由"。
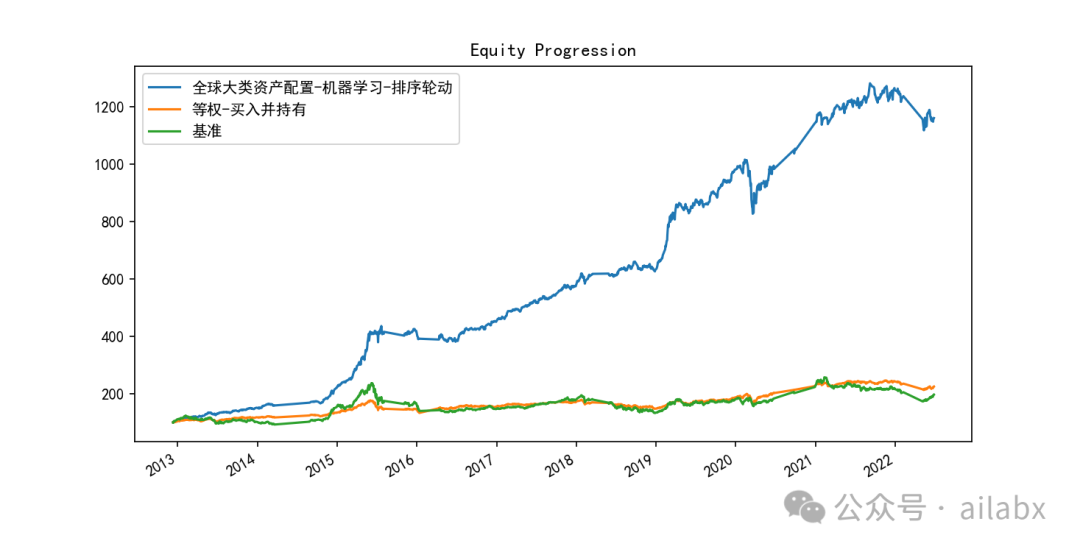
研报复现继续:【研报复现】年化27.1%,人工智能多因子大类资产配置策略之benchmark
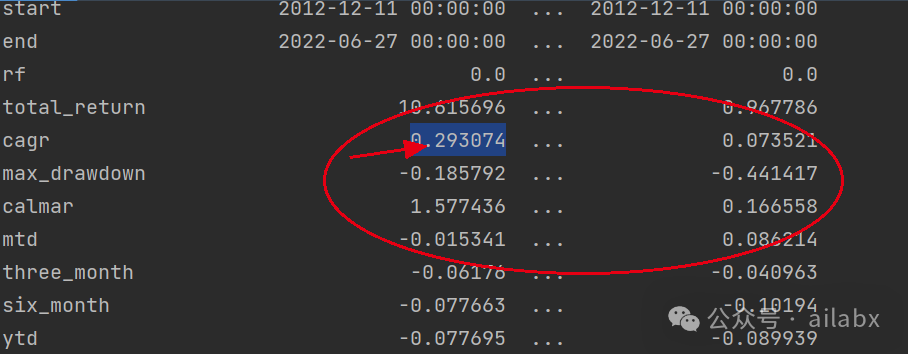
昨天调了一版参数,主要是lambda_l1, lambda_l2,防止过拟合的,有明显的效果:年化29.3%,最大回撤18.5%,还有继续优化的空间。
def train(df_train, df_val, feature_cols, label_col='label'):
model = LGBMRegressor(boosting='gbdt', # gbdt \ dart
n_estimators=600, # 迭代次数
learning_rate=0.1, # 步长
max_depth=10, # 树的最大深度
seed=42, # 指定随机种子,为了复现结果
num_leaves=250,
# min_split_gain=0.01,
lambda_l1=2,
lambda_l2=2000
)目前使用的是GridCV网格参数搜索:
ef adj_params(X_train, y_train):
"""模型调参"""
params = {
# 'n_estimators': [100, 200, 300, 400,500,600,700,800],
# 'learning_rate': [0.01, 0.03, 0.05, 0.1],
'max_depth': range(10, 64, 2),
# 'lambda_l1': range(0,3),
# 'lambda_l2':[200,400,800,1000,1200,1400,1600,2000]
}
other_params = {'learning_rate': 0.1, 'seed': 42, 'lambda_l1': 2, 'lambda_l2': 2000}
model_adj = LGBMRegressor(**other_params)
# sklearn提供的调参工具,训练集k折交叉验证(消除数据切分产生数据分布不均匀的影响)
optimized_param = GridSearchCV(estimator=model_adj, param_grid=params, scoring='r2', cv=5, verbose=1)
# 模型训练
optimized_param.fit(X_train, y_train)
# 对应参数的k折交叉验证平均得分
means = optimized_param.cv_results_['mean_test_score']
params = optimized_param.cv_results_['params']
for mean, param in zip(means, params):
print("mean_score: %f, params: %r" % (mean, param))
# 最佳模型参数
print('参数的最佳取值:{0}'.format(optimized_param.best_params_))
# 最佳参数模型得分
print('最佳模型得分:{0}'.format(optimized_param.best_score_))后续考虑使用hyperopt以及gluon来调参:
ModelTrainer:基于AutoGluon的多因子合成AI量化通用流程
代码与数据均在星球更新:
吾日三省吾身
昨天有同学留言说,现在这后半段有点鸡汤了。
我向来反感和警惕鸡汤,因此,我仔细反思了一下。
当下的大环境,大家越发渴望确定性,希望快速成功,赚钱,获得安全感。
但如果想听真话的话------这个世界没有"速成"之说。
成功也没有秘籍------没有武侠小说里,那种猴子肚子里掏出一本书,然后几天内达到别人30年的功力,然后年纪轻轻就独步天下------没有。
所谓心得,其实都是显学。
理财------多多储蓄,坚持长期投资,保持耐心。------没有了。
无论你想不想慢慢变富,你都会慢慢变老。区别在于,你是又老且富,还是又老且穷。
你说有没有财富自由快车道,------有,也是按3-7年往前看的。
有谁见过,花1000块钱不到,买一个策略或系统,然后赚1000万的?------谁这么跟你说,一定对你别有所图。
美好的东西都是需要时间这个变量来孵化。
它可能很慢,尤其在前期,慢到很多人没有耐心等到它发生。量化过程很慢,但越到后期才指数级复利加速。
如何度过这个孵化期------信念、系统。
种一棵树,最好的时间是十年前,其次是现在。
历史文章: