1、为啥使用缓存?
- 在程序内部使用缓存,将经常使用的数据存储在缓存中,可以减少对数据库的频繁访问,从而提高系统的响应速度和性能。缓存可以将数据保存在内存中,读取速度更快,能够大大缩短数据访问的时间,提升用户体验。
- 缓存不仅可以提高系统的性能和吞吐量,还可以提高系统的可靠性和稳定性。还可以减少网络传输的负载,特别是在分布式系统中。能够节省网络带宽和服务器的资源消耗。
- 使用缓存可以优化系统的性能、提高响应速度、降低数据库负载、节省网络传输和服务器资源,从而提升用户体验和系统的可靠性
- 其实就是以空间换时间
2、名词解析
| 词语解析 | 说明 | redis中是否存在 | 数据库中是否存在 |
|---|---|---|---|
| 缓存穿透 | 查询一个不存在的数据,缓存中没有数据直接穿透缓存,查询数据库,造成数据库的压力。 | 不存在 | 不存在 |
| 缓存击穿 | 缓存中的某个热点数据过期,大量的并发请求访问这个数据。导致请求在瞬间直接请求数据库,数据库压力过大甚至崩溃。 | 不存在 | 存在 |
| 缓存雪崩 | 指在同一时段大量的缓存失效,导致数据查询直接打到数据库,可能会使数据库崩溃 | 不存在 | 存在 |
3、原因分析
| 词语解析 | 可能的原因 |
|---|---|
| 缓存穿透 | 被攻击。小可爱通过构造恶意请求,使得缓存层无法命中任何数据 |
| 缓存击穿 | 缓存中的热点数据设置了过期时间,数据失效了 |
| 缓存雪崩 | 大量的数据在同一时间失效 |
4、缓存穿透
4.1、缓存穿透示意图
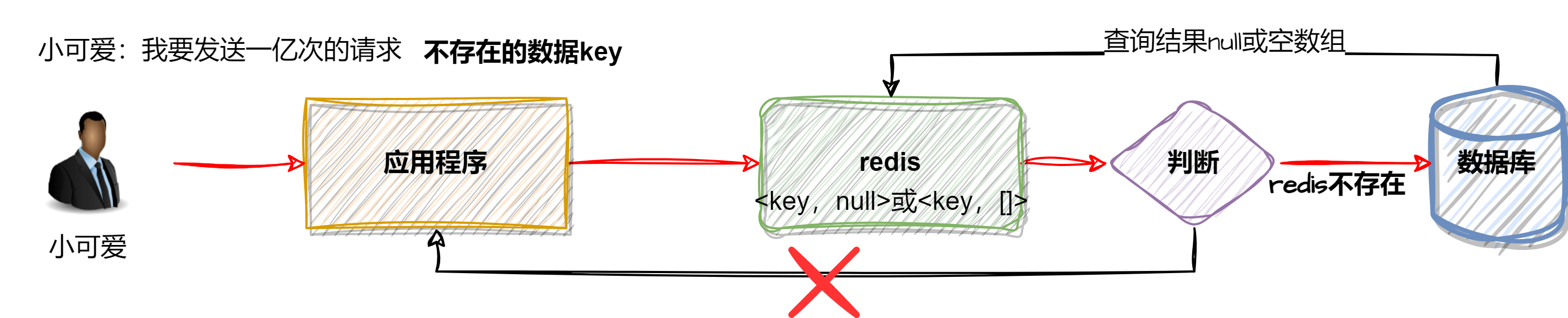
如上图,小可爱发送一个亿的请求,因为数据本身不存在,如果逻辑没有处理好。一亿的请求都会命中数据库。那该怎么解决嘞?
4.2、解决方案
4.2.1、缓存空对象
判断数据库查询结果
1、存在,将数据缓存起来key,结果
2、不存在,将空对象一般是null或者空数组\[\]缓存起来key,null或key,\[]
下面的代码,如果ID在数据库中不存在,则直接查询数据库,返回的是空数组,后续再查询的话,redis认为有数据,有效解决缓存穿透
java
public DictBO queryDictById(Long id) {
DictBO dictBO = redisUtil.get(String.valueOf(id));
if(!ObjectUtils.isEmpty(dictBO)){
return dictBO;
}else{
dictBO = this.getById(id);
redisUtil.setEx(String.valueOf(dictBO.getId()), dictBO, Duration.ofHours(1L));
return dictBO;
}
}4.2.1.1、优点
实现简单
4.2.1.2、缺点
内存消耗(一亿的数据量还是挺大的),因此要设置过期时间TTL
4.2.2、布隆过滤器
4.2.2.1、布隆过滤器示例代码
java
package com.toto.redis.filter;
import java.util.BitSet;
/**
* @Description: MyBloomFilter
* @Package: com.toto.redis.filter
* @Author gufanbiao
* @CreateTime 2024-06-21 21:06
*/
public class MyBloomFilter {
/** 一个长度为10 亿的比特位 */
private static final int DEFAULT_SIZE = 256 << 22;
/** 为了降低错误率,使用加法hash算法,所以定义一个8个元素的质数数组 */
private static final int[] seeds = {3, 5, 7, 11, 13, 31, 37, 61};
/** 相当于构建 8 个不同的hash算法 */
private static HashFunction[] functions = new HashFunction[seeds.length];
/** 初始化布隆过滤器的 bitmap */
private static BitSet bitset = new BitSet(DEFAULT_SIZE);
/**
* 添加数据
* @param value 需要加入的值
*/
public static void add(String value) {
if (value != null) {
for (HashFunction f : functions) {
//计算 hash 值并修改 bitmap 中相应位置为 true
bitset.set(f.hash(value), true);
}
}
}
/**
* 判断相应元素是否存在
* @param value 需要判断的元素
* @return 结果
*/
public static boolean contains(String value) {
if (value == null) {
return false;
}
boolean ret = true;
for (HashFunction f : functions) {
ret = bitset.get(f.hash(value));
//一个 hash 函数返回 false 则跳出循环
if (!ret) {
break;
}
}
return ret;
}
public static void main(String[] args) {
for (int i = 0; i < seeds.length; i++) {
functions[i] = new HashFunction(DEFAULT_SIZE, seeds[i]);
}
// 添加1亿数据
for (int i = 0; i < 100000000; i++) {
add(String.valueOf(i));
}
String id = "123456789";
add(id);
System.out.println(contains(id)); // true
System.out.println("" + contains("234567890")); //false
}
}
class HashFunction {
private int size;
private int seed;
public HashFunction(int size, int seed) {
this.size = size;
this.seed = seed;
}
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
int r = (size - 1) & result;
return (size - 1) & result;
}
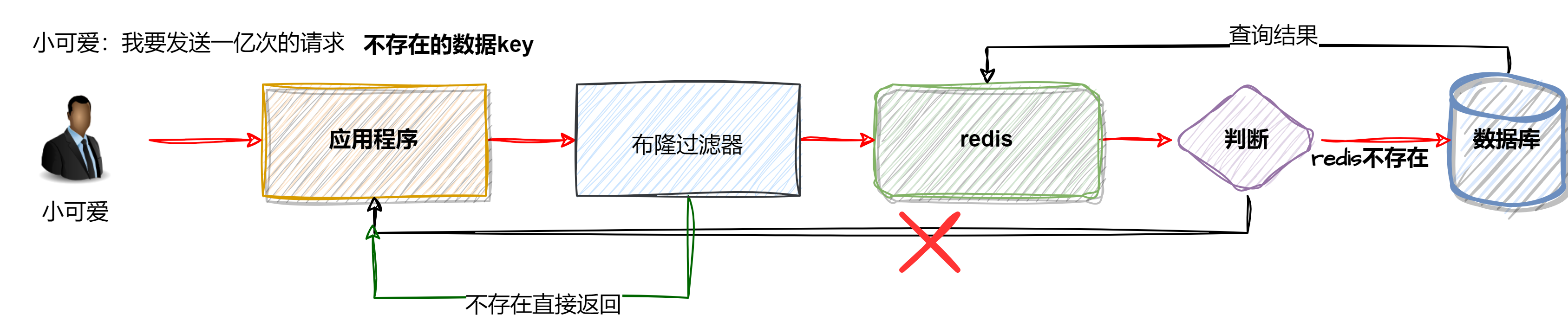
}4.2.2.2、布隆过滤器示例代码使用
相当于是在redis前加了一层过滤
java
public DictBO queryDictById(Long id) {
// 使用布隆过滤器
boolean contains = MyBloomFilter.contains(String.valueOf(id));
if(!contains){
return null;
}
DictBO dictBO = redisUtil.get(String.valueOf(id));
if(!ObjectUtils.isEmpty(dictBO)){
return dictBO;
}else{
dictBO = this.getById(id);
redisUtil.setEx(String.valueOf(dictBO.getId()), dictBO, Duration.ofHours(1L));
return dictBO;
}
}4.2.2.3、优点
1、使用布隆过滤器技术来过滤掉无效的请求,将可能不存在的数据快速过滤掉,
2、内存占用少
4.2.2.4、缺点
1、需要提前将数据库数据预热到布隆过滤器中
2、由于数据结构和算法导致无法删除热键,只能新增;
4.2.2.5、其它增强
增强 id 的复杂度、加强用户权限校验,做好热点参数的限流
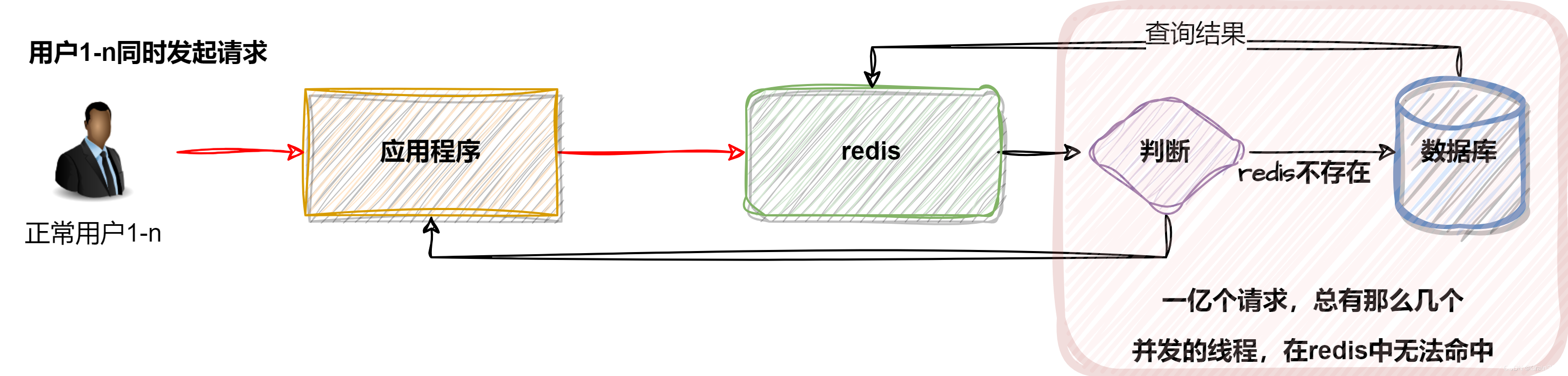
5、缓存击穿
缓存击穿是某一个热点key同时失效,恰巧这一瞬间无数的请求同时到服务器,多个线程查询redis且redis无数据,这时这些请求会同时去查询数据库,影响数据库的性能。
5.1、缓存击穿示意图
5.2、解决方案
5.2.1、热点数据设置"永不过期"
这种解决方式,设置TTL的时间为-1,或者设置了时间,在过期前主动更新时间,其实热点数据可能也会发生变化,将变化的数据在非高并发时间段更新缓存也可以。
网上也有"逻辑过期",其实是将过期时间放在了key对应的value中,在代码中加逻辑判断就可以。
5.2.2、加锁(分布式锁)或者使用队列控制
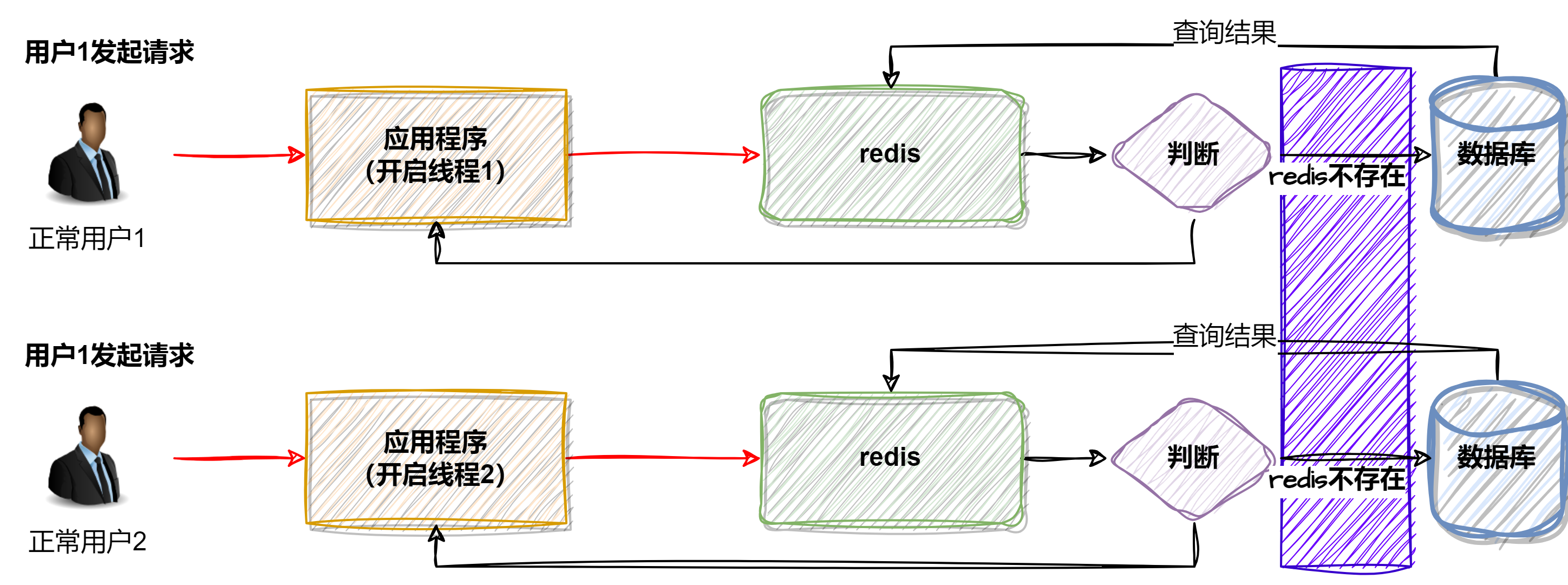
在紫色区域,用户1和用户2同时访问程序,在java中会开启两个线程执行程序,假设线程1先执行判断逻辑,不存在就对key进行加锁处理,线程2执行时获取锁失败后,使用线程等待,进行重试即可。
这里不再贴出代码,后面章节会对锁进行详细的说明,或者百度。
5.2.2.1、优点
保证一致性
5.2.2.2、缺点
1、线程需要等待,影响性能
2、程序处理逻辑若有漏洞,会造成死锁
5.2.3、限流和熔断
必要时实现服务限流和熔断机制,防止因为某个服务不可用而影响整个系统。现在在使用互联网应用时,熔断和限流的体验是有,但不多。不到万不得已,不太建议使用。
6、缓存雪崩
缓存雪崩和缓存击穿在概念上的区别在于:缓存击穿是部分key过期 导致的严重后果,而缓存雪崩则是因为大量key同时过期所导致的问题。你给了我一击,为什么还要一次又一次的暴击。
当然造成雪崩的现象还有另外一种原因:redis服务挂了。
6.1、如何防止缓存雪崩?
1、设置合理的缓存失效时间,避免大量缓存同时失效。
2、实现缓存数据的分布式锁,确保同时只有一个客户端去数据库中查询数据,其他客户端等待。
3、利用Redis集群或者一致性哈希,分散key的分布,避免热点数据集中失效。
4、如果缓存数据设置了过期时间,可以在失效前主动更新缓存数据。
期**所导致的问题。你给了我一击,为什么还要一次又一次的暴击。
当然造成雪崩的现象还有另外一种原因:redis服务挂了。
6.1、如何防止缓存雪崩?
1、设置合理的缓存失效时间,避免大量缓存同时失效。
2、实现缓存数据的分布式锁,确保同时只有一个客户端去数据库中查询数据,其他客户端等待。
3、利用Redis集群或者一致性哈希,分散key的分布,避免热点数据集中失效。
4、如果缓存数据设置了过期时间,可以在失效前主动更新缓存数据。